自监督预训练(一) 语义部分
pre-training技术在NLP领域得到了很好的应用,比如最近几年比较火的谷歌的BERT模型、OpenAI的GPT模型,在NLP各种类型的任务中都取得了很大的突破,大幅刷新了公开数据集的SOTA结果,由于最近在做语音预训练的一些工作,所以最近简单梳理了一下NLP领域pre-training技术的发展脉络。
NLP领域的预训练技术主要有两大方向:
- 第一个是基于feature的方法,这个是比较早期的一个做法,代表技术是ELMo技术
- 第二个是基于finetune的方法,这个是最近几年大家都在用的方法,也是这里重点介绍的方法,他的发展脉络可以表示为GPT->BERT->BART->UNILM
| 模型 | 网络结构 | 目标函数 |
|---|---|---|
| GPT | 单向transformer | LM |
| BERT | 双向transformer | masked LM和NSP |
| BART | encoder是双向transformer,decoder是单向transformer | 同BERT |
| UNILM | 上面三种网络共享参数,mask函数不同 | 上面三种的联合训练 |
ELMo
Embeddings from Language Models,基本思想是首先预训练语言模型,然后使用该语言模型抽取更高层次的特征,作为下游任务的输入。由于语言模型的预训练会考虑到当前词在整个句子中的context依赖关系,所以预训练网络抽取出来的特征可以包含更多的信息,从而有助于提升下游任务的效果。
在使用ELMo抽取特征的时候,网络不同层的输出表示不同维度的特征信息,将这些输出整合到一起作为最终的特征,
GPT系列模型
GPT是Generative Pre-Training的缩写,表示生成式预训练,是openAI团队的系列工作。
GPT[1]
GPT的基本思想包括两步:
- 无监督pretrain部分
使用大量的无标注的文本数据,使用语言模型的loss,网络结构使用transformer decoder部分,即masked-transformer - 有监督finetune部分
在pretrain的网络的基础上,增加一层线性变换,结合不同任务的loss进行finetune

finetune的过程有几个trick: - finetune的时候除了使用给定任务的loss,同时结合预训练的loss会有帮助
- 根据任务的不同,需要对输入做一些input transformation以方便跟预训练网络进行集合,比如声纹的triplet loss任务可以借鉴这个方法
- 使用transformer网络结构要比lstm好不少,因为transformer可以捕捉到更长的历史依赖。
GPT-2[2]
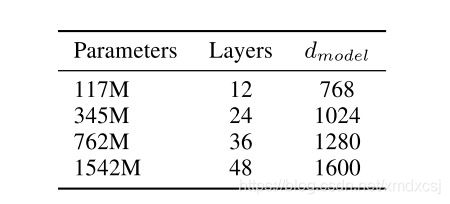
GPT-2的优势是预训练网络使用更大的网络结构,从而在多个任务进一步刷新了SOTA。
GPT-3[3]

GPT-3使用了更大的网络,同时讨论LM在few-shot learning任务的作用:
- fine-tuning
需要较多的监督数据,训练过程更新预训练网络的梯度 - zero-shot
不更新预训练网络的梯度,没有训练数据,只给task description - one-shot
在zero-shot的基础上给一个训练样本 - few-shot
在zero-shot的基础上给少量训练样本
BERT系列模型
Bidirectional Encoder Representations from Transformers
motivation
GPT系列的预训练方法由于使用的是LM的loss,导致了它只能使用单向的网络结构,BERT的训练loss使用的masked LM的loss,方便引入了双向的网络结构,相比GPT取得了更大的提升。
网络结构
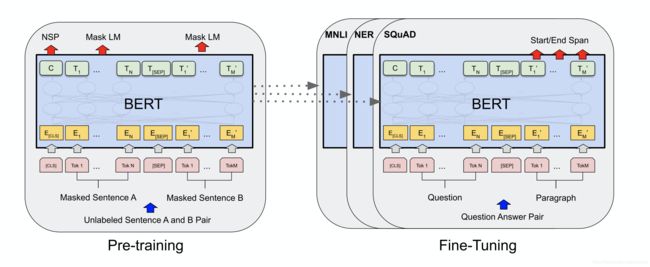
输入是一句话或者拼接两句话,包含三部分:
- token embedding(wordpiece)
- segment embedding(哪句话)
- position embedding(在句子中的位置)
loss
loss包括两部分:
- masked LM
每次15%的做mask,为了跟下游任务更好的匹配(finetune任务的输入没有mask),每个选中的mask点会有80%的几率使用[MASK],10%的几率使用其他词,10%的几率保持不变。 - Next sentence prediction(NSP)
语义有一些下游任务需要理解两个句子之间的关系,所以在预训练的时候会把两个句子A和B拼接到一起作为输入,其中50%的时间A和B是准确的上下句关系,50%的时间不是。
实验结果
- 对比了masked LM和left-to-right LM的区别,masked LM在有些任务优势明显
- 经过预训练的大模型,即使在小数据任务上面,也可以相比小模型获得明显的性能提升
- 使用BERT不做finetune,直接来做特征提取,也可以取得很好的效果。
BART[5]

BART是指Bidirectional and Auto-Regressive Transformers,应用于seq2seq架构,其中encoder部分对应Bidirectional Transformers,decoder部分对应Auto-Regressive Transformers。它和GPT、BERT的关系如上图所示。

这种预训练架构的意义在于它可以丰富输入序列的干扰方法,不再像BERT一样只局限于mask这种操作,BART的可用的干扰方法如上图所示。
UNILM[6-7]

UNILM将三种预训练的目标函数进行联合训练,其中第一种对应BERT模型,第二种对应GPT模型,第三种对应BART。通过联合训练,可以达到一下目的:
- 使用一个预训练模型来替代原来的三个模型
- 多个任务的参数共享有助于提升模型的泛化能力
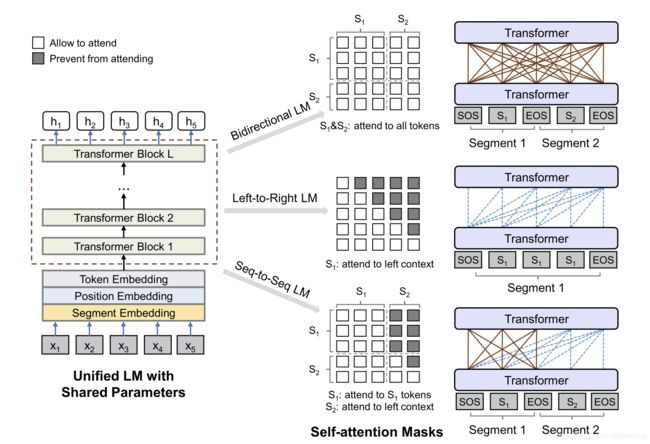
实际训练过程中,所有的网络参数共享,通过attention的mask操作来实现不同的预训练任务。训练的时候一个batch,1/3的时间使用bert,1/3的时间使用bart,left-to-right GPT和right-to-left GPT各1/6。
参考文献
[0].Deep contextualized word representations
[1].Improving Language Understanding by Generative Pre-Training
[2].Language Models are Unsupervised Multitask Learners
[3].Language Models are Few-Shot Learners
[4].BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[5].BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
[6].Unified Language Model Pre-training for Natural Language Understanding and Generation
[7].UNILMv2: Pseudo-Masked Language Models for Unified Language Model Pre-Training
微信公众号有最新技术分享,【欢迎扫码关注交流】
