进化计算(七)——MOEA/D算法详解
MOEA/D论文阅读笔记Ⅰ
- 摘要
- 引言
-
- 早期分解策略在多目标问题中的应用
- MOEA/D算法核心步骤
- MOEA/D算法特点
- 文章中用于测试的3种分解方法
-
- 加权和方法(向量投影角度理解)
- 切比雪夫聚合法(最大距离最小化角度理解)
- 边界交叉聚合方法-BI Approach(最小化最小值参考点与权重向量上的所求解之间的距离)
- PBI Approach vs. Tchebycheff approach
- MOEA/D算法框架(以Tchebycheff approach分解为例)
-
- 基本定义
- "邻居"定义
- 符号定义
- 算法步骤
-
- 输入输出
- 初始化
- 迭代循环
- 停止迭代
- 流程图
- 几个讨论
- MOEA/D的变体
- 参考文献及链接
写在前边:本文依然是自己的理解笔记,仅用作本人学习记录。写博客的时候参考了许多博主的文章,具体链接在文末。
摘要
分解是传统多目标优化算法中的基础策略,但是分解策略还未能广泛的应用于多目标进化优化算法中。该篇文章提出了一个基于分解的多目标进化算法MOEA/D:将一个多目标优化问题分解成许多单目标优化子问题,然后同时对这些子问题进行优化。由于对每一个子问题进行优化时仅使用该子问题邻近的几个子问题的相关信息,因此MOEA/D算法有较低的计算复杂度。实验结果显示了使用标准化目标函数的MOEA/D算法能够处理不同缩放程度的目标。此外,使用高级分解方法的MOEA/D算法对三目标测试问题进行优化时可以生成一系列均匀分布的解。小种群的MOEA/D算法性能以及MOEA/D算法的可拓展性和灵敏性也在文章中以实验的方式进行了展示。
引言
现实生活中的多目标优化问题需要决策者从众多Pareto最优解中选取最终适用的解。但是大部分的多目标问题存在许多甚至无限量的Pareto最优解,获取完整的解集十分消耗时间,甚至可能也无法获取完整的解集。另一方面,决策者也不愿意从大量的Pareto最优解中进行选择。因此,学者们致力于研究能够寻找可控数量的Pareto解且解在PF上均匀分布的多目标优化算法。
众所周知,多目标优化问题的Pareto最优解在某条件下可以转化成一个聚合所有目标函数的单目标优化问题的最优解。因此,求解PF的近似解就可以分解成一些单目标优化子问题。
早期分解策略在多目标问题中的应用
TPLS(two-phase local search):TPLS针对一个单目标优化问题集。其中,目标函数是待优化的多目标优化问题的目标函数的聚合。使用单目标优化算法解决同一序列中基于聚合系数的单目标优化问题。前一问题获得的解可以作为解决下一个问题的起始解(由于两个问题的聚合目标函数仅存在细微的不同之处(稍有不同slightly different))。
MOGLS(multiobjective genetic local search):同时优化由加权和方法或者切比雪夫方法构建的所有聚合函数。每一次迭代,都优化一个随机生成的聚合函数。
MOEA/D算法核心步骤
将多目标优化问题明确分解成N个单目标优化子问题。核心算法:
- 通过对种群中的解进行进化同时解决这些子问题;
- 每一次迭代,种群都由迄今为止找到的针对每个子问题的最优解组成;
- 子问题之间的“邻居关系”由它们的聚合系数向量之间的距离定义;
- 两个邻居子问题的最优解应该十分接近;
- 对每一个子问题进行优化时仅使用该子问题邻近的几个子问题的相关信息。
MOEA/D算法特点
- MOEA/D算法提供了一种简单有效的将分解方法引入多目标进化计算的方式。数学领域的分解方法可以很容易地(readily)引入MOEA/D算法框架中从而用于解决MOP。
- 相较于非分解多目标进化算法,MOEA/D算法可以很容易的解决适应度分配及多样性保持的难题。
- 每一次迭代时,MOEA/D算法的计算复杂度均低于NSGA-II和MOGLS:
- 在0-1多目标背包问题中MOEA/D较MOGLS拥有更高质量的解;
- 使用切比雪夫分解方法的MOEA/D算法与NSGA-II在连续多目标问题测试集上有相同的性能;
- 使用先进分解方法的MOEA/D算法在3目标连续测试集上拥有比NSGA-II更好的性能。
- 使用小种群的MOEA/D算法可以得到更小数量的均匀分布解。
- 可以在MOEA/D算法中引入目标函数标准化的方法解决不同量纲的目标函数。
- MOEA/D算法可以使用单目标优化方法。
文章中用于测试的3种分解方法
加权和方法(向量投影角度理解)
该方法通过一个非负权重向量将MOP转换为单目标子向量。设 λ = ( λ 1 , λ 2 , . . . λ m ) T \lambda = (\lambda_1,\lambda_2,...\lambda_m)^T λ=(λ1,λ2,...λm)T是权重向量且满足 ∑ i = 1 m λ i = 1 \sum_{i=1}^{m}\lambda_i=1 ∑i=1mλi=1(每个目标函数都有自己的权重),那么下面这个单目标优化问题的最优解(唯一)就是一个Pareto最优解。
m i n m i z e g w s ( x ∣ λ ) = ∑ i = 1 m λ i f i ( x ) ( 1 ) s . t . x ∈ Ω minmize\quad g^{ws}(x|\lambda)=\sum_{i=1}^{m}\lambda_if_i(x)\quad (1)\\s.t.\quad x\in \Omega minmizegws(x∣λ)=i=1∑mλifi(x)(1)s.t.x∈Ω

对式(1), ∑ i = 1 m λ i f i ( x ) \sum_{i=1}^{m}\lambda_if_i(x) ∑i=1mλifi(x)(即权重向量和目标函数值向量相乘)可以看做点 f i ( x ) f_i(x) fi(x)(目标函数向量即为一个Pareto最优解)在 λ \lambda λ方向上的投影。从各个最优解向 λ \lambda λ方向作垂线,从原点到垂点的距离即是投影值。上图中,A即为最短投影点。
通过设置不同的权重向量 λ \lambda λ,就可以得到所有的最短投影点,共同组成Pareto最优解集。然而,使用这种方法难以寻找非凸解(非凸解向参照向量的垂线不能与PF相切)。实际应用时可以采用 ε − c o n s t r a i n t \varepsilon-constraint ε−constraint的方法解决这种问题。
切比雪夫聚合法(最大距离最小化角度理解)
切比雪夫法中单目标优化函数的表达形式为
m i n i m i z e g t e ( x ∣ λ , z ∗ ) = m a x 1 ≤ i ≤ m { λ i ( f i ( x ) − z i ∗ ) } ( 2 ) s . t . x ∈ Ω minimize\quad g^{te}(x|\lambda,z^*)= \underset{1\le i\le m}{max}\left\{\lambda_i(f_i(x)-z_i^*)\right\}\quad (2)\\s.t.\quad x\in \Omega minimizegte(x∣λ,z∗)=1≤i≤mmax{λi(fi(x)−zi∗)}(2)s.t.x∈Ω
其中, z ∗ = ( z 1 ∗ , . . . , z m ∗ ) T z^*=(z_1^*,...,z_m^*)^T z∗=(z1∗,...,zm∗)T是参考点, z i ∗ = m i n { f i ( x ) ∣ x ∈ Ω } z_i^*=min\left\{f_i(x)|x\in \Omega\right\} zi∗=min{fi(x)∣x∈Ω},即 z ∗ z^* z∗是由所有目标函数最小值组成的参考向量。原文中给出的是 m a x max max,但是由于后续仿真实验中作者采用的均是 m i n i m i z a t i o n M O P minimization\text{ }MOP minimization MOP ,所以此处应为 m i n min min,也就是论文中的该处注释:
![]()
从式(2)物理意义角度理解: λ i ( f i ( x ) − z i ∗ ) \lambda_i(f_i(x)-z_i^*) λi(fi(x)−zi∗)值越大,就说明在这个目标函数上离理想点(最小值点)越远。假设 λ a ( f a ( x ) − z a ∗ ) \lambda_a(f_a(x)-z_a^*) λa(fa(x)−za∗)是所有 λ i ( f i ( x ) − z i ∗ ) \lambda_i(f_i(x)-z_i^*) λi(fi(x)−zi∗)中的最大值,逐渐改变 x x x使得该值减小(靠近理想点)直到到达PF上的对应点,即完成了最小化 g t e ( x ∣ λ , z ∗ ) g^{te}(x|\lambda,z^*) gte(x∣λ,z∗)的任务。(最大值已经最小化了,那么其他 λ i ( f i ( x ) − z i ∗ ) \lambda_i(f_i(x)-z_i^*) λi(fi(x)−zi∗)也会最小化)
从图像角度理解:令 f i ′ ( x ) = f i ( x ) − z i ∗ f_i^\prime (x)=f_i(x)-z_i^* fi′(x)=fi(x)−zi∗,并将坐标系进行平移变换。在该坐标系中,公式变为 m i n g t e ( x ∣ λ , z ∗ ) = m a x 1 ≤ i ≤ m { λ i f i ′ ( x ) } min\quad g^{te}(x|\lambda,z^*)= \underset{1\le i\le m}{max}\left\{\lambda_if_i^\prime (x)\right\} mingte(x∣λ,z∗)=1≤i≤mmax{λifi′(x)}。给定一个权重向量 λ ⃗ \vec{\lambda} λ。对于 λ ⃗ \vec{\lambda} λ上方的个体满足 λ 1 f 1 ′ ( x ) > λ 2 f 2 ′ ( x ) \lambda_1f_1^\prime (x)>\lambda_2f_2^\prime (x) λ1f1′(x)>λ2f2′(x),因此 λ ⃗ \vec{\lambda} λ上方的优化任务就变为了 min ( λ 1 f 1 ′ ( x ) ) \min(\lambda_1f_1^\prime (x)) min(λ1f1′(x))。同理,对于 λ ⃗ \vec{\lambda} λ下方的个体满足 λ 1 f 1 ′ ( x ) < λ 2 f 2 ′ ( x ) \lambda_1f_1^\prime (x)<\lambda_2f_2^\prime (x) λ1f1′(x)<λ2f2′(x), λ ⃗ \vec{\lambda} λ下方的优化任务就变为了 min ( λ 2 f 2 ′ ( x ) ) \min(\lambda_2f_2^\prime (x)) min(λ2f2′(x))。
易判断, f 1 ′ ( x ) f_1^\prime (x) f1′(x)的等高线垂直于纵轴平行于横轴, f 2 ′ ( x ) f_2^\prime (x) f2′(x)的等高线垂直于横轴平行于纵轴,因此每一个解的等高线就由两条垂线构成。收敛过程如下:对于 λ ⃗ \vec{\lambda} λ上方的个体,若存在新解的 f 1 ′ ( x ) f_1^\prime (x) f1′(x)小于当前等高线值,那么等高线向下移动;对于 λ ⃗ \vec{\lambda} λ下方的个体,若存在新解的 f 2 ′ ( x ) f_2^\prime (x) f2′(x)小于当前等高线值,那么等高线向左移动(两部分收敛时都是两条等高线同时移动)。由此,直到搜索到Pareto前沿。同理,通过设置不同的权重向量 λ \lambda λ,就可以得到所有的收敛点,共同组成Pareto最优解集。
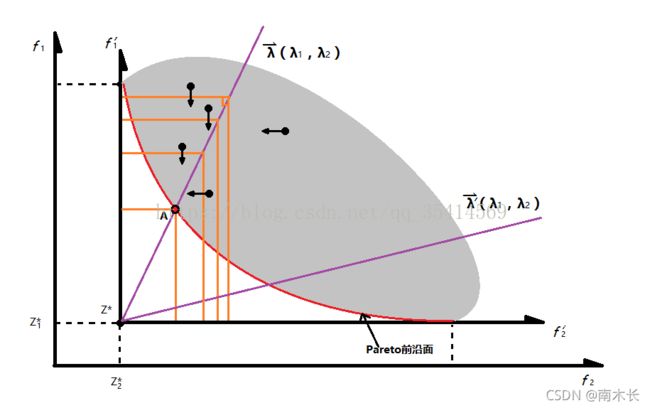
小缺点:该种方法的聚合函数对于连续MOP问题来说不够平滑。但是仍适用于文中的算法框架。(文中算法不需要对聚合函数求导)
边界交叉聚合方法-BI Approach(最小化最小值参考点与权重向量上的所求解之间的距离)
边界交叉方法适用于连续MOP问题。通常情况下,最大化连续MOP问题的PF前沿会是目标函数集的右上部分(最小化MOP的PF前沿是左下部分)。从几何学角度上理解,BI Approach是为了寻找边界处与一组线的交点。如果这组线在某种意义上均匀分布,那么所得到的交点就可以很好的代表PF 的近似前沿。这种方法可以用于求解非凸集。论文中采用由参考点发散出的一组线求解交点。单目标优化函数形式可以表示为
m i n g b i ( x ∣ λ , z ∗ ) = d ( 3 ) s . t . z ∗ − F ( x ) = d λ , x ∈ Ω min\quad g^{bi}(x|\lambda,z^*)=d\quad (3)\\s.t.\quad z^*-F(x)=d\lambda,\\x\in \Omega mingbi(x∣λ,z∗)=d(3)s.t.z∗−F(x)=dλ,x∈Ω
其中, λ \lambda λ和 z ∗ z^* z∗与上文中的定义相同, F ( x ) F(x) F(x)目标空间的一个解。如下图所示, z ∗ − F ( x ) = d λ z^*-F(x)=d\lambda z∗−F(x)=dλ是为了确保 F ( x ) F(x) F(x)与 z ∗ z^* z∗共线于直线L(直线L朝 λ \lambda λ方向且经过参考点)。该问题的求解目标就是尽可能地使 F ( x ) F(x) F(x)高( d d d尽可能小)直到到达PF。
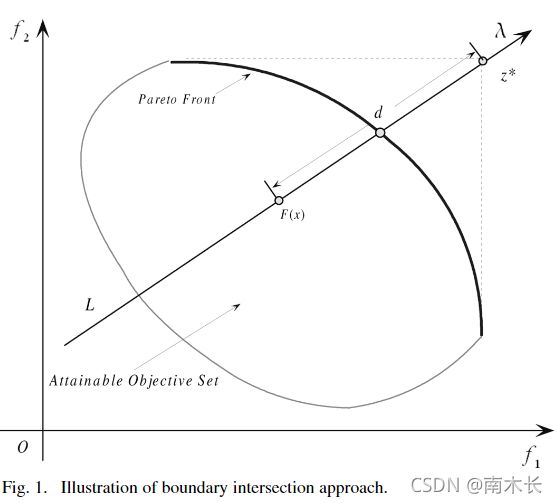
但上述问题不易满足等式约束条件。论文中引入惩罚方法处理约束条件,作者称这种方法为PBI approach。单目标约束问题就变为了
m i n g b i p ( x ∣ λ , z ∗ ) = d 1 + θ d 2 ( 4 ) s . t . x ∈ Ω min\quad g^{bip}(x|\lambda,z^*)=d_1+\theta d_2\quad (4)\\s.t.\quad x\in \Omega mingbip(x∣λ,z∗)=d1+θd2(4)s.t.x∈Ω
其中, θ > 0 \theta>0 θ>0是惩罚参数。
上式中, d 1 = ∥ ( z ∗ − F ( x ) ) T λ ∥ ∥ λ ∥ d 2 = ∥ F ( x ) − ( z ∗ − d 1 λ ) ∥ d_1=\frac{\left \| (z^*-F(x))^T\lambda\right\|}{\left\|\lambda\right\|}\\d_2=\left\|F(x)-(z^*-d_1\lambda)\right\| d1=∥λ∥∥∥(z∗−F(x))Tλ∥∥d2=∥F(x)−(z∗−d1λ)∥
从式(4)物理意义来理解,算法通过引入惩罚参数以此放宽了对所求解的要求。也就是说,所求解可以不在权重向量方向上,但若不在权重向量方向上就必须要接收惩罚。所求解距离权重向量越远,受的惩罚越厉害,以此来约束算法向权重向量的方向生成解。
从几何角度理解 d 1 d_1 d1和 d 2 d_2 d2两个公式:
- d 1 d_1 d1:由点 F ( x ) F(x) F(x)指向参考点 z ∗ z^* z∗的向量在 λ \lambda λ方向上的投影。
- d 2 d_2 d2:由点 y y y指向点 F ( x ) F(x) F(x)的向量模长。【反映所求解 F ( x ) F(x) F(x)与权重向量方向的偏离程度】

PBI Approach vs. Tchebycheff approach
- 在目标函数个数大于2的情况下,使用相同均匀分布权重向量的两种方法结果显示PBI方法求出的Pareto最优解分布更均匀,尤其是在权重向量值特别大的时候;
- 如果 x x x支配 y y y,仍存在 g t e ( x ∣ λ , z ∗ ) = g t e ( y ∣ λ , z ∗ ) g^{te}(x|\lambda,z^*)=g^{te}(y|\lambda,z^*) gte(x∣λ,z∗)=gte(y∣λ,z∗)的情况。但是对于 g b i p g^{bip} gbip和其他BI聚合函数几乎不会出现这种情况;
- PBI Approach也存在一定缺陷:需要自己设定惩罚参数值。参数值过大或者过小都会破坏算法性能。
MOEA/D算法框架(以Tchebycheff approach分解为例)
基本定义
λ , z ∗ \lambda,z^* λ,z∗的定义与前文相同。求解PF近似解的MOP问题可以分解成N个单目标优化子问题,这也就意味着需要N个不同的权重向量。MOEA/D算法在一次运行过程中同时优化N个目标函数。对于第 j j j个子问题,其数学表达式为
m i n g t e ( x ∣ λ j , z ∗ ) = m a x 1 ≤ i ≤ m { λ i j ( f i ( x ) − z i ∗ ) } ( 6 ) min\quad g^{te}(x|\lambda^j,z^*)= \underset{1\le i\le m}{max}\left\{\lambda_i^j(f_i(x)-z_i^*)\right\}\quad (6) mingte(x∣λj,z∗)=1≤i≤mmax{λij(fi(x)−zi∗)}(6)
由于 g t e g^{te} gte是 λ \lambda λ的连续函数,所以如果 λ i \lambda_i λi与 λ j \lambda_j λj很接近的话, g t e ( x ∣ λ i , z ∗ ) g^{te}(x|\lambda^i,z^*) gte(x∣λi,z∗)与 g t e ( x ∣ λ j , z ∗ ) g^{te}(x|\lambda^j,z^*) gte(x∣λj,z∗)就会很接近。因此,拥有和 λ i \lambda_i λi很接近的权重向量的 g t e g^{te} gte对于优化 g t e ( x ∣ λ i , z ∗ ) g^{te}(x|\lambda^i,z^*) gte(x∣λi,z∗)就会很有帮助。这是MOEA/D算法很重要的机制之一。
"邻居"定义
在MOEA/D算法中,权重向量 λ i \lambda_i λi的邻居定义为 { λ 1 , . . . , λ N } \left\{\lambda^1,...,\lambda^N\right\} {λ1,...,λN}中的一组最接近的权重向量。同理,第 i i i个子问题的邻居就由 λ i \lambda_i λi的邻居所确定的子问题组成。种群由迄今为止每个子问题找到的最优解组成,仅利用当前子问题的邻近子问题的解来优化当前子问题。
符号定义
在第 t t t次迭代,使用切比雪夫的MOEA/D算法包括:
- N个点 x 1 , . . . . . . , x N ∈ Ω x^1,......,x^N\in \Omega x1,......,xN∈Ω组成的一个种群,其中 x i x^i xi是第 i i i个子问题的当前解;
- F V 1 , . . . . . . , F V N FV^1,......,FV^N FV1,......,FVN,其中, F V i FV^i FVi是 x i x^i xi的目标函数值向量;
- z = ( z 1 , . . . . , z m ) T z=(z_1,....,z_m)^T z=(z1,....,zm)T,其中 z i z_i zi是目标函数 f i f_i fi迄今为止找到的最优值;
- 外部种群 E P EP EP,用于存储搜索过程中找到的非支配解。
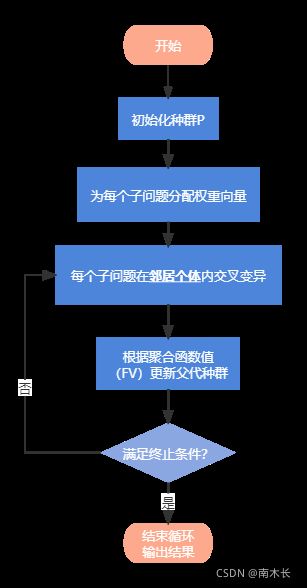
算法步骤
输入输出
输入:MOP;停止条件(迭代次数); N N N(子问题个数);均匀分布的 N N N个权重向量 λ 1 , . . . , λ N \lambda^1,...,\lambda^N λ1,...,λN;每个权重向量的邻居个数 T T T。
输出:EP。
初始化
- 设定一个空集EP;
- 计算任意两个权重向量之间的欧氏距离,然后求解出每个权重向量的 T个邻居。对 i = 1 , 2 , . . . , N i=1,2,...,N i=1,2,...,N, B ( i ) = { i 1 , . . . . , i T } B(i)=\left\{i_1,....,i_T\right\} B(i)={i1,....,iT}。其中 λ i 1 , . . . . , λ i T \lambda^{i_1},....,\lambda^{i_T} λi1,....,λiT是 λ i \lambda^i λi的 T T T个权重向量;
- 随机初始化种群,计算 F V i = F ( x i ) FV_i=F(x_i) FVi=F(xi);
- 初始化 z ⃗ = ( z 1 , . . . , z m ) T \vec{z}=(z_1,...,z_m)^T z=(z1,...,zm)T,令 z i = m i n { ( f i ( x 1 ) , . . . , f i ( x N ) } z_i=min\left\{(f_i(x^1),...,f_i(x^N)\right\} zi=min{(fi(x1),...,fi(xN)}。【由于 z ∗ z^* z∗难以计算,所以作者使用针对特定问题的方法初始化可替代 z ∗ ⃗ \vec{z^*} z∗的 z ⃗ \vec{z} z,并在迭代循环过程中更新】
迭代循环
对 i = 1 , . . . , N i=1,...,N i=1,...,N
- 基因重组:从 B ( i ) B(i) B(i)中随机选取两个索引 k , l k,l k,l(第 i i i个子问题邻居问题的当前最优解),然后使用遗传算子由 x k , x l x^k,x^l xk,xl生成新解 y y y;
- 改善:对 y y y运用特定方法(切比雪夫或者加权和等)进行改善,生成 y ′ y^\prime y′(以防 y y y不满足约束条件);
- 更新 z z z:对 j = 1 , 2 , . . . , m j=1,2,...,m j=1,2,...,m,如果 z j < f j ( y ′ ) z_j
- 更新邻居解:对每一个 j ∈ B ( i ) j\in B(i) j∈B(i),如果 g t e ( y ′ ∣ λ j , z ) ≤ g t e ( x j ∣ λ j , z ) g^{te}(y^\prime|\lambda^j,z)\le g^{te}(x^j|\lambda^j,z) gte(y′∣λj,z)≤gte(xj∣λj,z),令 x j = y ′ x^j=y\prime xj=y′且 F V j = F ( y ′ ) FV^j=F(y^\prime) FVj=F(y′);
- 更新EP:从EP中移除 F ( y ′ ) F(y^\prime) F(y′)的支配向量;如果EP中不存在支配 F ( y ′ ) F(y^\prime) F(y′)的向量就将 F ( y ′ ) F(y^\prime) F(y′)加入EP。
停止迭代
满足停止条件后,停止迭代。否则,重新进入迭代循环步骤。
流程图
几个讨论
- 为什么子问题只有有限个:MOEA/D预先生成N个权重向量,构成N个子问题,针对每个子问题的计算复杂度基本相同。而MOGLS为了力求优化所有可能的聚合函数,在每次迭代时随机生成权重向量。实际上,决策者通常只需要有限个均匀分布的Pareto解。因此,为了减少计算资源的浪费,选取有限的子问题是合适且有必要的。
- MOEA/D采用什么方法保留种群多样性:针对非分解优化算法是在选择机制中使用拥挤距离等算法保留种群多样性,但是这种算法不易生成均匀分布的Pareto最优解。在MOEA/D算法中,当前种群的不同解与不同子问题相关,显而易见的,子问题的多样性会影响种群多样性。因此,只要正确选择分解方法和权重向量生成合适的子问题,MOEA/D算法就会在【各个子问题都能被较好优化的情况下】生成一组在PF上均匀分布的最优解。
- 交配限制和 T T T(邻居个数)的选择:
交配限制:MOEA/D算法中,只使用当前子问题的 T T T个邻居子问题来优化当前解。也就是说,只有两个解属于两个邻居子问题,它们才有可能交配。
T T T的选择: T T T太小,子代解和父代解会十分接近,从而使得算法缺乏探索其他搜索区域的能力; T T T太大,生成算子的两个输入解性能会很差,从而导致子代解性能也很差,影响算法的搜索能力。此外,T太大也会在更新邻居解步骤时产生较大的计算复杂度。
MOEA/D的变体
- MOEA/D算法可以使用任意的分解方法。使用加权和算法时不需要参考向量 z z z。
- y y y改善成 y ′ y^\prime y′这一步骤可以使用 g t e g^{te} gte或者 g w s g^{ws} gws作为目标函数进行启发式优化。如果通过基因重组就能生成可行解,也可以省略改善这一步。
- 是否使用外部种群EP也是可选的。如果没有EP存储非支配解,也可以返回最后的内部种群作为PF的近似解。其他较为复杂的更新EP的策略也可以很容易地引入MOEA/D算法框架。
- cMOGA也可以看作是基于分解的进化算法。本质上,它也是使用邻居关系来约束交配。和MOEA/D算法的不同点在于为生成算子选择解以及更新内部种群这两个步骤。在cMOGA算法中,为了处理非凸PF,需要在每一代将EP中的解插入到内部种群中(因为cMOGA算法使用加权和分解方法且它没有在内部种群中保存迄今为止每个子问题的最优解的机制)。
参考文献及链接
[1]Qingfu Zhang, Hui Li.MOEA/D: A Multiobjective Evolutionary Algorithm Based on Decomposition[J].IEEE TRANSACTIONS ON EVOLUTIONARY COMPUTATION,2007(6):712-731
[2]链接:【多目标优化】3. 基于分解的多目标进化算法 —(MOEA/D)
[3]链接:多目标优化_学习笔记(三)MOEA/D
[4]链接:多目标优化–MOEAD算法笔记
[5]链接:多目标优化问题中常见分解方法的理解