用 Keras/TensorFlow 2.8 创建 YOLOv4-CSP 模型
用 Keras/TensorFlow 2.8 创建 YOLOv4-CSP 模型
- 前言
- 1. YOLOv4-CSP 的整体结构图。
- 2. 脊柱部分 backbone。
- 3. 颈部 neck。
- 4. 头部 head。
- 5. 使用方法。
- 6. TF 2.8 和环境配置。
- 7. 参考博客。
- 8. 下载地址。
前言
YOLOv4 的原作团队,把 YOLOv4 升级到了 Scaled-YOLOv4,用 COCO 数据集训练,最高能够实现 55.5% AP。
2021 年的第二版 Scaled-YOLOv4 论文地址链接
Scaled-YOLOv4 包括了 3 种类型,分别是 YOLOv4-large, YOLOv4-CSP 和 YOLOv4-tiny。
其中 YOLOv4-large 适用于高端的 GPU 集群(YOLOv4-large 包括了 YOLOv4-P5, YOLOv4-P6, YOLOv4-P7),YOLOv4-tiny 适用于低端的 GPU,如嵌入式系统等。而 YOLOv4-CSP 则适用于普通的台式机 GPU。
相较于 YOLOv4,Scaled-YOLOv4 的特点在于采用了大量的 CSP (Cross Stage Partial network 论文地址)结构,CSP 的主要作用是在保证模型性能的前提下,减少模型参数和计算量。此外,Scaled-YOLOv4 不再使用 LeakyReLU 激活函数,全面采用 mish 激活函数。
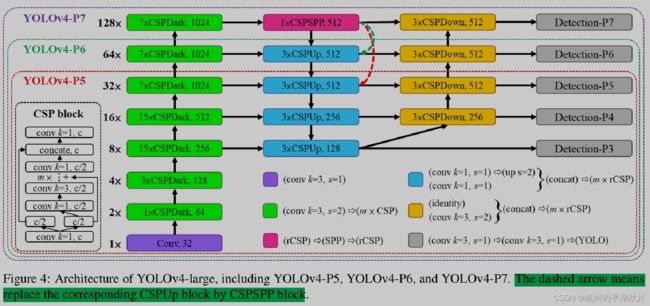
论文中给出了 YOLOv4-large 的整体结构,如上图。
要创建 YOLOv4-CSP ,则需要进一步画出结构图,并给出一些具体的结构参数,具体内容如下。
1. YOLOv4-CSP 的整体结构图。
YOLOv4-CSP 的整体结构如下图。下图模型是以 608x608 大小的图片为输入,给出了各部分的张量形状。
YOLOv4-CSP 主要由 3 部分组成,脊柱 backbone 是 CSP-Darknet53,颈部 neck 是 PANet 结构,最后加上 3 个输出头部。
Backbone 部分,residual 数量分别为 1, 2, 8, 8, 4 。(图中 m 就是 residual 数量)
backbone 部分第一个 residual 的数量为 1, 并且使用的是 YOLOv3 的普通 Darknet53 residual。后续几个 residual 数量为 2, 8, 8, 4 的 residual 模块,则是 CSP 形式的 residual 模块。

Neck 部分,使用了 PANet 结构。该结构把大的特征图信息(76x76) 和小的特征图(19x19)信息进行混合,使得模型的 3 个输出 head,都能更好地学到大的整体信息和小的细节信息。就如同是喝果汁饮料时,喝前摇一摇,混合均匀后会更好喝。
确定了整体的结构,在 Keras 中实现模型的上层架构也会比较简单。代码如下:
def yolo_v4_csp(inputs, training=None):
"""YOLO-v4-CSP module。
Arguments:
inputs:一个 4D 图片张量,形状为 (batch_size, 608, 608, 3),数据类型为
tf.float32。可以用全局变量 MODEL_IMAGE_SIZE 设置不同大小的图片输入。
training: 一个布尔值,用于设置模型是处在训练模式或是推理 inference 模式。
在预测时,如果不使用 predict 方法,而是直接调用模型的个体,则必须设置参
数 training=False,比如 model(x, training=False)。因为这样才能让模
型的 dropout 层和 BatchNormalization 层以 inference 模式运行。而如
果是使用 predict 方法,则不需要设置该 training 参数。
Returns:
head_outputs: 一个元祖,包含 3 个 tf.float32 类型的张量,张量形状为
(batch_size, 19, 19, 255), (batch_size, 38, 38, 255),
(batch_size, 76, 76, 255)。最后 1 个维度大小为 255,可以转换为 (3, 85),
表示有 3 个预测框,每个预测结果是一个长度为 85 的向量。
在这个长度为 85 的向量中,第 0 位是置信度,第 1 位到第 81 位,代表 80 个
类别的 one-hot 编码,最后 4 位,则是预测框的位置和坐标,格式为
(x, y, height, width),其中 x,y 是预测框的中心点坐标,height, width
是预测框的高度和宽度。对于一个训练好的模型,这 4 个数值的范围都应该在
[0, 608] 之间。
"""
backbone_outputs = csp_darknet53(inputs=inputs, training=training)
neck_outputs = panet(inputs=backbone_outputs, training=training)
head_outputs = heads(inputs=neck_outputs, training=training)
return head_outputs
深度学习借鉴了很多医学名词,比如神经网络等。而深度学习的模型,也借鉴了医学上的人体结构名词,比如脊柱 backbone,颈部 neck 和 头部 head,都是人体自下而上的结构。如下图的人体结构示意。

下面展开看各个部分更详细的结构。
2. 脊柱部分 backbone。
2.1 脊柱部分的第一个卷积块(对应整体结构图中 m=1 的黄色块),使用的是普通的 Darknet53 卷积,也就是没有使用 CSP 的分支结构。
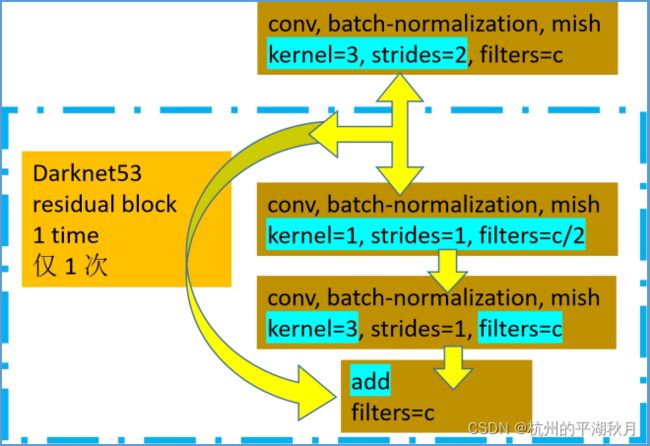
2.2 脊柱部分的其它绿色卷积块,使用的是 CSP 形式的卷积模块。

需要指出的是,论文中的配图 Figure-4,CSP-block 有不正确的地方。第一个卷积应该是 3x3,而非 1x1 卷积。如下图。可以从 YOLOv4 官方的 github,下载 cfg 文件,验证这个问题。

3. 颈部 neck。
3.1 reversed CSP 模块(rCSP)。
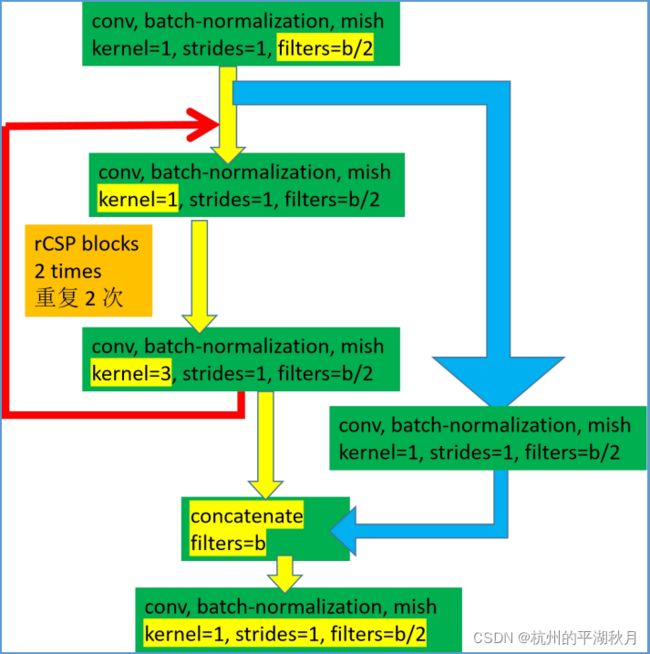
3.2 Reversed CSP SPP 模块,只在 P5 部分使用。对应上面整体结构图的紫红色框。

3.3 CSPUp 模块。对应整体结构图的蓝色框。

3.4 CSPDown 模块。对应整体结构图的土黄色框。

4. 头部 head。

头部结构相对简单,只需注意一点。论文中虽然写的最后一个卷积是 3x3,但实际应该是 1x1。如下图。

5. 使用方法。
使用时,可以使用默认的 608x608 大小的图片。如果想设置使用更小的输入图片,只需要在 yolo_v4_csp.py 文件中设置 FEATURE_MAP_P5 的特征图大小即可。如下图。

使用 yolo_v4_csp.py 文件中的 create_model 函数即可创建模型。如下图,是在 Jupyter Lab 创建模型,并画出模型结构的示意。
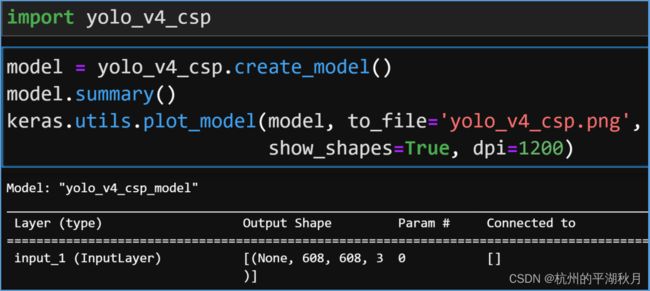
用 keras.utils.plot_model 画出的局部模型结构如下图所示。

6. TF 2.8 和环境配置。
推荐在 TensorFlow 2.8 版本中使用该模型。因为 TF 2.8 可以对该模型使用混合精度训练,使得训练速度更快。
如果用更低版本的 TF 2.4 ,将无法对该模型使用混合精度加速,只能按正常速度运行。具体原因是因为 YOLOv4-CSP 的损失函数要用到 tf.math.atan,而 TF 2.4 还没有实现在 float16 格式下计算 tf.math.atan 函数,所以TF 2.4 无法对该模型使用混合精度加速。
其它的环境设置为:
Python: 3.9
Cuda:11.2.0
Cudnn:8.1.1
其它: Win10, Anaconda。
7. 参考博客。
YOLOv4-CSP 很多地方都和 YOLOv4 是一样的。对于 YOLOv4 的一些细节,可以参考下面江大白和 Bubbliiiing 的两篇博客。
江大白 博客
Bubbliiiing 博客
8. 下载地址。
我把模型放在了 github 上,可以点下面的链接下载。
github 上的下载地址