hive(一)hive的安装与基本配置
目录
一、前提:
二、安装步骤:
1、上传jar包至/usr/local/soft
2、解压并重命名
3、配置环境变量
三、配置HIVE文件
1、配置hive-env.sh
2、配置hive-site.xml
3、配置日志
4、修改默认配置文件
5、上传MySQL连接jar包
四、修改MySQL编码
1、 编辑配置文件
2、加入以下内容:
3、 重启mysql
五、初始化HIVE
六、进入hive
七、后续配置
八、测试hive
hive中的几种存储格式
TextFile格式:文本格式
RCFile:
ORCFile:
Parquet:
其他格式:
九、配置JDBC连接
报错:
连接到JDBC
一、前提:
安装hive所需要的虚拟机环境为虚拟机安装有Hadoop并且集群成功,同时Hadoop需要在启动状态下,同时需要安装有mysql。不需要有zookeeper和HA,由于HA中含有大量进程,启动会占用很多资源,建议不要有HA
二、安装步骤:
1、上传jar包至/usr/local/soft
将hive-3.1.2上传到虚拟机中的/usr/local/soft目录下
2、解压并重命名
tar -zxvf apache-hive-3.1.2-bin.tar.gz
# 重命名
mv apache-hive-3.1.2-bin hive-3.1.2/
3、配置环境变量
vim /etc/profile
#增加以下内容:
# HIVE_HOME
export HIVE_HOME=/usr/local/soft/hive-3.1.2/
export PATH=$PATH:$HIVE_HOME/bin
#保存退出 source 使其生效
source /etc/profile
三、配置HIVE文件
1、配置hive-env.sh
cd $HIVE_HOME/conf
# 复制命令
cp hive-env.sh.template hive-env.sh# 编辑
vim hive-env.sh# 增加如下内容
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/usr/local/soft/hadoop-2.7.6# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/usr/local/soft/hive-3.1.2/conf
2、配置hive-site.xml
上传hive-site.xml到conf目录:
hive-site.xml文件内容:
hive.cli.print.header
true
hive.cli.print.current.db
true
hive.metastore.warehouse.dir
/user/hive/warehouse
javax.jdo.option.ConnectionURL
jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=GMT
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
123456
hive.server2.thrift.port
10000
hive.server2.thrift.bind.host
master
3、配置日志
# 创建日志目录
cd $HIVE_HOME
mkdir log# 设置日志配置
cd confcp hive-log4j2.properties.template hive-log4j2.properties
vim hive-log4j2.properties
# 修改以下内容:
property.hive.log.dir = /usr/local/soft/hive-3.1.2/log
4、修改默认配置文件
cp hive-default.xml.template hive-default.xml
5、上传MySQL连接jar包
上传 mysql-connector-java-5.1.37.jar 至 /usr/local/soft/hive/lib目录中
四、修改MySQL编码
修改mysql编码为UTF-8:
1、 编辑配置文件
vim /etc/my.cnf
2、加入以下内容:
[client]
default-character-set = utf8mb4
[mysqld]
character-set-server = utf8mb4
collation-server = utf8mb4_general_ci
3、 重启mysql
systemctl restart mysqld
五、初始化HIVE
schematool -dbType mysql -initSchema
六、进入hive
输入命令:hive
七、后续配置
修改mysql元数据库hive,让其hive支持utf-8编码以支持中文
登录mysql:
mysql -u root -p123456
切换到hive数据库:
use hive;
1).修改字段注释字符集
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
2).修改表注释字符集
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
3).修改分区表参数,以支持分区键能够用中文表示
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
4).修改索引注解(可选)
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
5).修改库注释字符集
alter table DBS modify column DESC varchar(4000) character set utf8;
八、测试hive
启动hive,直接输入命令:hive
在hive中创建filetest数据库
命令: create database filetest;
切换filetest数据库:use filetest;
hive中的几种存储格式
TextFile格式:文本格式
以TextFile格式创建students表:
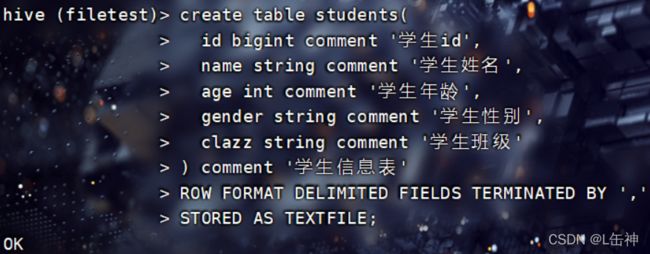
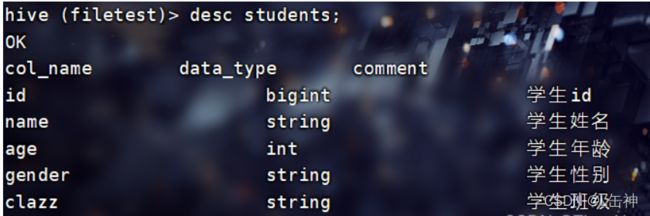
使用命令:desc students查看students表的各个字段:
在hive根目录下创建一个文件夹data用于存放本地文件,将本地中的一个文本文件上传到hive根目录下的data中
向表中插入数据:
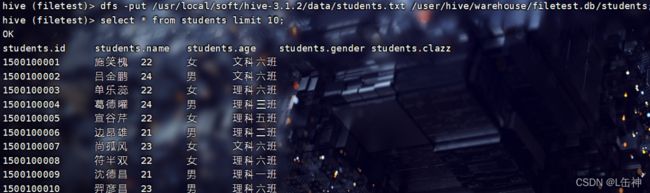
1、通过input命令将该data中的文本文件上传到hdfs中所创建的该表中,实现向该表中插入数据
在hive中可以使用hdfs中的命令:
查询结果:
2、通过普通的格式对表中进行插入数据
创建一个新的表stduents2,使用普通格式进行插入数据:
load data local inpath "/usr/local/soft/hive-3.1.2/data/students.txt" into table students2;
结果:
![]()
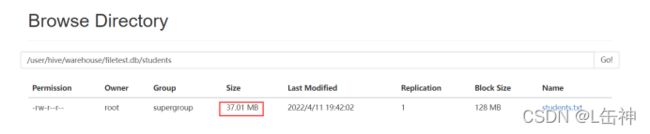
进入到hdfs中查看:发现两种插入方式对数据大小没有变化,都是37M:
RCFile:
Hadoop中第一个列文件格式
RCFile通常写操作较慢,具有很好的压缩和快速查询功能。
创建RCFile格式的表:

插入数据:
使用命令:
insert into table students_rcFile select * from students;

插入完成后,查看数据大小:为26.44M
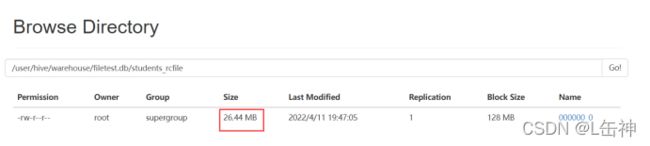
ORCFile:
Hadoop0.11版本就存在的格式,不仅是一个列文件格式,而且有着很高的压缩比
创建ORCFile格式的表:

向表中插入数据:
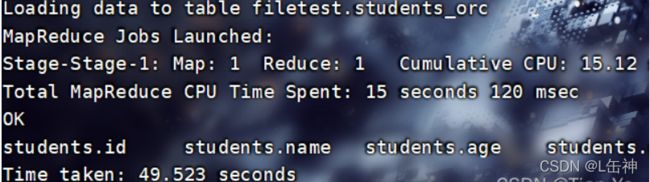
查看数据大小:被压缩为220.38KB

同时观察插入数据所用时间,ORCFile格式与RCFile格式插入数据相差时间不大
Parquet:
这是一种嵌套结构的存储格式,他与语言、平台无关
创建Parquet格式的表:
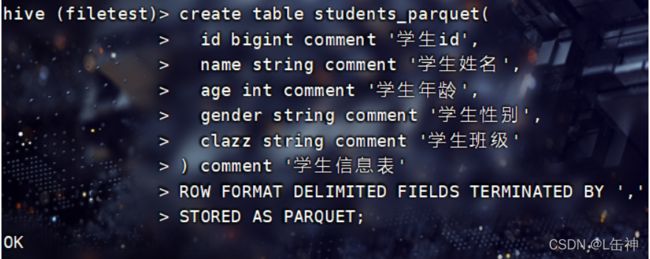
向表中插入数据:
insert into table students_parquet select * from students;
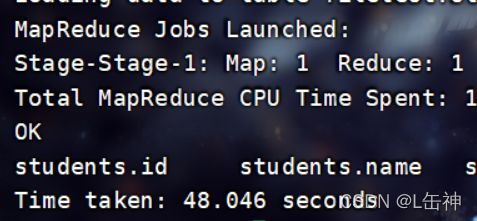
查看数据大小:为3M
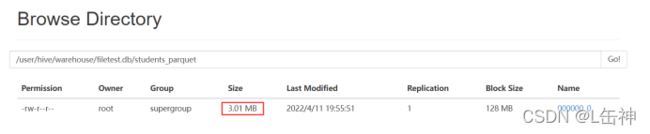
同时发现该格式在插入数据时所花费的时间比ORC格式所花费的时间更少。
其他格式:
SEQUENCEFILE格式:这是一个Hadoop API提供的一种二进制文件格式,实际生产中不使用
AVRO:是一种支持数据密集型的二进制文件格式,他的格式更为紧凑
九、配置JDBC连接
Hive中有两种命令模式:CLi模式和JDBC模式
Cli模式就是Shell命令行
JDBC模式就是Hive中的Java,与使用传统数据库JDBC的方式类似
开启JDBC连接:
进入到/usr/local/soft/hive-3.1.2/bin目录下,在bin目录下有一个hiveserver2文件,通过该文件开启JDBC连接:
输入命令:hive --service hiveserver2开启JDBC连接
一般情况下当出现四个Hive Session时就说明JDBC连接被开启了,也可以通过命令查看是否开启:
进入到 /usr/local/soft/hive-3.1.2/bin目录下:
输入:netstat -nplt | grep 10000
该输入的端口号为hive-site.xml中的hiveserver2服务的端口号![]()
报错:
若输入该命令报错:
Error: Could not open client transport with JDBC Uri: jdbc:hive2://master:10000:
Failed to open new session: java.lang.RuntimeException:
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException):
User: root is not allowed to impersonate root (state=08S01,code=0)
解决办法:
先关闭Hadoop集群:stop-all.sh
再进入到Hadoop 中的core-site.xml中添加如下内容:
fs.trash.interval
1440
#以下是添加的内容:
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
注意:这些内容需要添在加
重新启动集群:start-all.sh
再次启动hiveserver2
hive --service hiveserver2
该过程较慢,需要等待
连接到JDBC
当启动JDBC连接后,会开启一个进程RunJar,使用jps命令就可查看
Hive 将元数据存储在数据库中(metastore),目前只支持 mysql、derby
连接到JDBC命令:
进入到 /usr/local/soft/hive-3.1.2/bin下,输入命令:
beeline -u jdbc:hive2://master:10000 -n root连接JDBC:
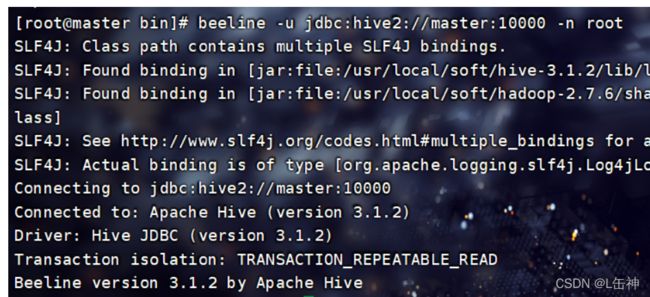
在JDBC中输入命令可以查看当前hive中的数据库:show databases;

可以发现他与hive的区别在于他使用了一个表格式将databases显示出来
Hive中metastore是hive元数据的集中存放地,这里使用的是MySQL