深度学习之 TensorFlow模型优化和调优实例
近几年深度学习作为一种技术发展迅猛,越来越多的人工智能解决方案将深度学习作为其基本技术,然而构建深度学习模型并不是一件容易的事,为了获得满意的准确性和效率,通常需要数周的时间优化模型。
模型的优化通常包括网络结构本身和训练参数两个层级,网络结构主要包括层数、节点、权重以及激活函数等,训练参数包括epoch、batch size、learning rate, cost functions, normalization和regularization以及optimization。
深度学习是机器学习的一个子集,深度学习主要是神经网络模型的构建和使用,神经网络通常有三层及以上层,神经网络模拟人大脑的数据处理和决策过程,深度学习在自然语言处理(语言识别和合成)、图像识别、自动驾驶等领域获得了商业应用。
在针对深度学习要处理的问题时,训练过程一般如下:
1 根据处理问题对象构建好标记过的训练数据集(输入和输出一一对应);
2. 根据经验(基于paper或者基于直觉等均可)构建神经网络(TensorFlow,Keras等均可以);
3. 构建好的网络各节点的权重和偏移(weights和bias)使用随机值初始化;
4. 根据标记好的输出输入关系,最小化模型预测误差
5. 根据预测误差,调节神经网络各节点的权重和偏移值;
6. 调节模型参数,包括layer、node以及其它训练参数优化模型;
7. 保存训练好的模型,建立部署推理
模型优化可以从推理(前向计算)结果和训练目标两个方面来做,推理的目标是用尽量小的计算代价获得尽可能高的准确性,训练过程的优化包括训练时间(少的迭代次数)、避免训练缺陷(梯度消失和梯度爆炸)以及过拟合。
深度学习调优过程
调优前的准备工作
调优的开始应先设立合理的目标(准确性和效率),然后整理合适的训练数据集,这里的合适指的是针对目标问题各种样例相对均衡的数据,并且该数据集能够最大限度的涵盖目标场景,制作目标场景的测试集。
调参过程
可调参数包括如下两大类,
- 网络模型架构,层数及其级联关系、节点类型、权重以及激活函数等
- 训练参数,包括epochs和batches,归一化和正则化,优化器
在调优的过程中,一次从两大类中选择一个参数调节,根据自己的理解和经验对该参数选择一组合适的可选集合,如针对batch size,可以将batch size选择32,64,128以及256作为一组对比,再比如对于激活函数,可以选择sigmoid、tanh、relu、elu、softmax等作为一组对比,然后使用相同数据集和验证集训练模型,然后使用测试集,比较不同参数选择对结果的影响,然后将单个步骤中对准确性和性能影响大的参数作为研究对象,类似于单个参数,根据经验同时调节上一步中影响大的多个参数以评估对模型结果的影响,最后使用不同测试集测试结果,并选择效果最好的那组调优参数集得到的模型。
模型基本框架
TensorFlow官网建议在搭建模型时,先从简单的入手,逐渐增加模型复杂度,这有助于快速迭代模型。这里以Mnist为例展示训练优化的过程,虽然keras官网给出的是基于卷积网络的模型例子,官网的例子在迭代到12个epoch时,训练集上的准确性是:
Epoch 12/15
237/422 [===============>..............] - ETA: 7s - loss: 0.0398 - accuracy: 0.9877
这是官网上给的原始结果,不同训练过程会略有小差异。
这里以官网建议的全连接网络为起始模型,为了训练代码的简单化,将通用的代码作为一个独立的python函数,将调优放在不同的函数中实现。
代码采用框架设计思想,核心模型相关代码见Base_model,测试不同参数都是for循环设置实现,该代码框架有助于建立清晰结构化的思维方式。下载地址见:
本博客源码源码下载链接
超参数调优
Epoch and Batch Sizes
from Base_model import *
#--------------------------------------
#Epoch and batch size comparision
#--------------------------------------
accuracy_measures = {}
for batch_size in range(16, 128, 16):
# Load default configuration
model_config = base_model_config()
# Acquire and process input data
X_train, Y_train, X_test, Y_test = get_data()
# set epoch to 20
model_config["EPOCHS"] = 12
# Set batch size to experiment value
model_config["BATCH_SIZE"] = batch_size
model_name = "Batch-Size-" + str(batch_size)
history = create_and_run_model(model_config, X_train, Y_train, model_name)
accuracy_measures[model_name] = history.history["accuracy"]
plot_graph(accuracy_measures, "Compare Batch Size and Epoch")
本博客源码源码下载链接
12个epoch测试结果如下
| batch size | accuracy(12epoch) |
|---|---|
| 16 | 0.9785208106040955 |
| 32 | 0.9809791445732117 |
| 48 | 0.9815000295639038 |
| 64 | 0.981166660785675 |
| 80 | 0.979812502861023 |
| 96 | 0.9786666631698608 |
| 112 | 0.9773333072662354 |
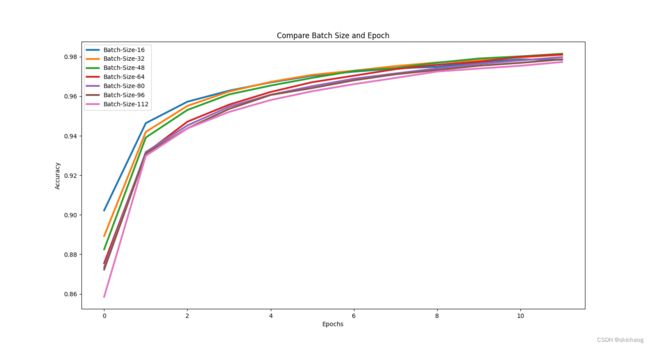 |
|
| 从表格和图都可以看出batch size等于48在epoch 10以上获得准确性最高。 |
layers数量调优
| layers number | accuracy(12epoch) |
|---|---|
| 2(no-hidden layer) | 0.9753124713897705 |
| 3 | 0.9770416617393494 |
| 4 | 0.9742291569709778 |
| 5 | 0.968708336353302 |
| 6 | 0.9672499895095825 |
 |
|
| 通过这可以看到在层数相同或者比上一节还多的情况下,准确性没有上一小节测试的高,此外层数也不是越多越好,这也是为什么官网建议先从简单的模型开始的原因,当然也可以针对已有论文去复现处理目标问题。 |
不同层Nodes调优
既然nodes大小对模型准确性有影响,那么对比不同nodes就是有必要的。下表是三层情况对比
| nodes number | accuracy(12epoch) |
|---|---|
| 8 | 0.9283124804496765 |
| 16 | 0.9551041722297668 |
| 24 | 0.9686458110809326 |
| 32 | 0.9765833616256714 |
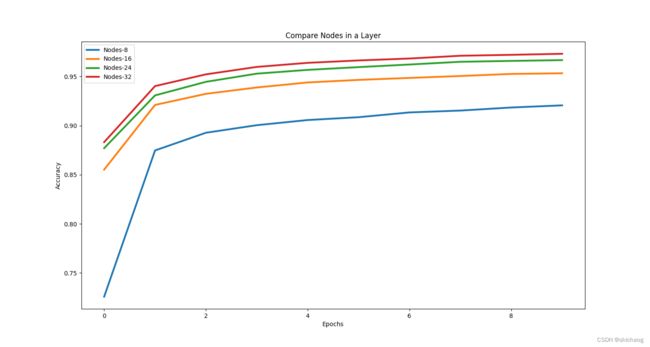
默认模型的nodes分别是32和64,而这里两层都是32,还应该扩大nodes的测试范围。
Activation 函数
常见有10种激活函数,这里为简单,只列relu、sigmoid以及tanh做对比
| activation function | accuracy |
|---|---|
| relu | 0.9792708158493042 |
| sigmoid | 0.971750020980835 |
| tanh | 0.9769999980926514 |
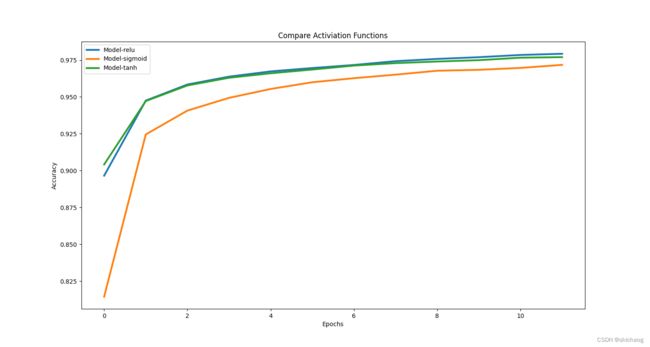 |
###Weigths初始化影响
| Weights initialization | accuracy |
|---|---|
| random normal | 0.9790416955947876 |
| zeros | 0.11395833641290665 |
| ones | 0.11437500268220901 |
| random uniform | 0.9780833125114441 |

训练梯度参数调优
batch normalization
| normalization | 12 epoch |
|---|---|
| with | 0.9826458096504211 |
| None | 0.9813958406448364 |

Optimizers 调优
optimizer同样影响反向梯度传播收敛情况,不同优化器在收敛速度和性能并不一样
| optimizer | accuracy |
|---|---|
| sgd | 0.9803333282470703 |
| rmsprop | 0.9818333387374878 |
| adam | 0.9816458225250244 |
| adagrad | 0.8760625123977661 |
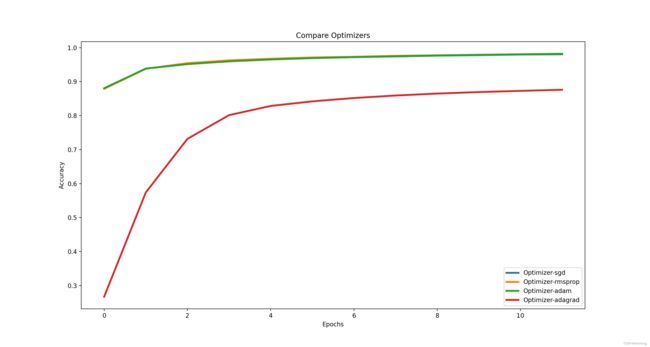
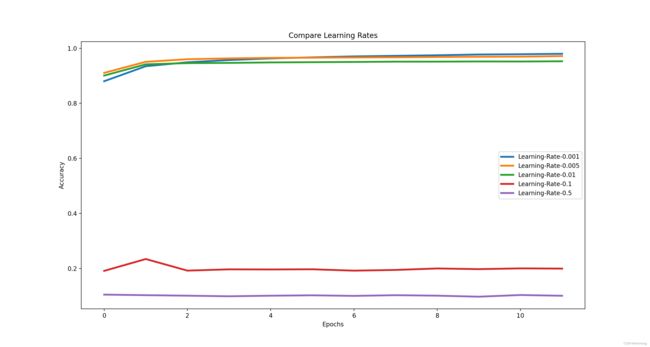
Learning rate调优
不同learning rate在收敛速度和准确性方面有差异,较大的learning rate往往在初始时具有较快的收敛速度,但是往往无法达到最优解,因而常采用动态学习率,keras里提供了LearningRateScheduler实现这一功能。
过拟合控制
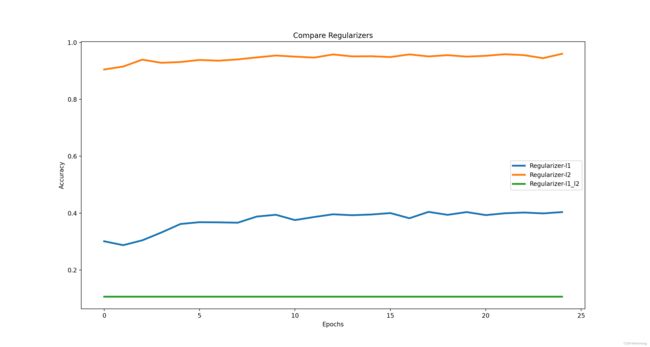
正则化
正则方法有L1,L2和L1_L2
dropout

本博客源码源码下载链接
除此以外,还有不同OP的组合(卷积,LSTM,GRU),不同网络的结构(Resnet、Densenet、mobileNet、VGG)等,还有对训练数据进行增强,shuffle等操作,以及训练中使用loss。