Interactron: Embodied Adaptive Object Detection
- 论文地址:https://arxiv.org/abs/2202.00660
- 代码地址:https://github.com/allenai/interactron
0. Abstract
过去多年,物体检测(object detection)已经受到了极大地关注,特别是最近由于具有强大能力的深度神经网络的出现使得这一领域呈现爆发式增长。然而,现有的这些物体检测工作都典型地基于两个前提假设:(1)所有网络模型都是基于现有的训练集数据进行训练以及在一个预先记录好的测试集进行网络模型性能评估;(2)所有网络模型在训练阶段结束之后都要进行网络参数冷却或者说是网络参数冻结(kept frezen),从而不再进行网络参数的优化和更新。然而,这两者都会限制这些物体检测方法适用于真实世界场景。在这项工作中,作者提出了一个叫做Interactron的方法用于交互场景设置下的适应性物体检测,从而实现在不同环境下通过具身代理导航所观察到的图像的物体检测。所提出方法的思路是在网络推理依然进行网络训练并在测试时间内不进行任何明确的监督学习来进行模型适应,这是通过与环境进行交互实现的。实验表明,本文所提出的自适应物体检测模型在AP方面比DETR提高了7.2分(在AP50方面提高了12.7分),DETR是现阶段一个高性能的物体检测器。此外,结果还表明,所提出的物体检测模型能够适应具有完全不同的外观特征的环境,并在其中表现良好。
1. Introduction
在Abstract中已经提到,现有的目标检测算法都是基于两个前提假设,然而这两个前提假设都使得所训练的模型受到限制。首先是在多种应用场景中,例如自动驾驶和家庭辅助机器人,模型会连续不断地接收到来自同一环境下的不同新观察,这些新观察大概率能够帮助模型对自身进行纠正和优化。例如,当前帧中部分被遮挡的物体可能无法被置信地检测到,但在之后观察中这个物体可能会出现到一个更好的未被覆盖遮挡的视觉角度。然而在未来相似情况中模型应该能够应用该信号去提升它的置信度。另外,在模型训练之后冻结网络参数会抑制模型的进一步改进和适应的能力。我们有理由相信,在具身代理能够利用的推断阶段中通过和环境进行交互(interaction with enviroments)来适应模型将会成为一种强大的自监督信号。现在已经有很多工作通过无监督方式去适应物体检测器。但是,他们在推理过程中假设有一组预先记录的观察结果。
在本文中,所提出的方法的思路是在推理阶段继续训练模型的同时也实现与环境进行互动。作者的假设是与环境进行交互可以使具身代理(embodied agent)在推理阶段捕捉更好的观察视角,从而提升更好的适应性和模型性能。与通常的物体检测方法相比,本文工作中的模型训练阶段和推理阶段之间没有单独的边界,并且模型能够在推理阶段在无任何明确的监督信号下学会采取行动(take actions)和适应(adapt)。具体来说,就是有一个代理能够在室内环境中进行互动,并且它能够依靠一个经过完全有监督训练的物体探测器来识别物体。Interactron的目标是能够通过在推理阶段能够适应模型的同时能够依据一个被学习到的策略(a learned policy)来实现代理与环境进行交互。在推理过程中没有可用于物体检测的监督信息,但是模型可以为那些输入图片产生梯度(gradient)。因此,模型可以在推理时间内使用所产生的梯度来进行网络更新。基本上,在测试时间段内模型没有任何监督信号进行参数更新。

作者使用AI2-THOR框架来评估所提出来的适应性物体检测模型Interatron。AI2-THOR框架包括了125种不同的物体类别,它们会出现在120种不同的室内场景中。Interactron的任务是检测代理在场景中导航时观察到的所有帧中的物体。Interactron除了在常规的物体检测任务中取得了显著地性能提升之外,结果表明,在AI2-THOR中训练的自适应模型能够取得与在Habitat上完全监督训练的模型相近的性能,其中的Habitat数据集具有与AI2-THOR完全不同外观特征的场景。
2. Related Work
2.1 Object Detection
现有的物体检测方法的模型框架主要有基于CNN和Transformer的。现有的物体检测方法只能访问一个固定的图像集合已经没有机制去与环境进行交互。
2.2 Embodied adaptive mothods
具身适应性方法(embodied adaptive mothods)主要值得是在测试阶段进行模型的适应。本文中关注的研究领域与Continual learning方法具有很大的相似性。但是大多数continual learning方法关注的是non-embodied 场景。最近的工作[33]提出了一种关于导航场景的continual learning方法。
2.3 Active vision
主动视觉(active vision)通常涉及一个在环境中移动的代理,以便对所定义的任务有一个更好的感知,或者致使方法能够更有效地执行任务。本文所提出的方法与现有的主动视觉方法的主要区别是该模型能够根据自我监督的损失函数(而不是典型的手动定义的不确定性衡量)进行即时更新。[58]与我们的方法很接近,它提出了一个用于更好识别物体的策略(policy)。再者,它与本文所提出方法不同点还有它们在训练阶段结束后冻结了模型参数更新且基于完全有监督学习方式更新网络。
2.4 Embodied self-supervision
现在有很多方法都通过具身交互(embodied interaction)来学习一个自监督表示。本文工作的目标与它们不同的是这项工作能够以自监督的方式学习一个损失函数来改变新的环境中的目标检测器的权重以便能够使得模型适应该环境。[6] 提出了一种依赖于姿势传感器、深度照片和3D一致性来解决目标检测中的自监督学习问题。相反,本文的工作只使用RGB图像而不依赖任何良好的姿势假设。
3 Embodied Adaptive Learning
在这个章节中,作者提出了自己的方法Interactron,它在推断阶段将具身的自适应学习应用于目标检测任务。主要的方法是在模型训练之后并没有冻结网络模型的参数,反之当一个具身代理(embodied agent)在探索环境的同时让网络在推断阶段无任何明显监督信息的状态下使网络模型进行适应。
3.1 Task deifinition
作者在本项工作种引入了一种新的目标检测任务,它适应于交互式环境(如AI2-THOR或Habitat)。这个任务主要是用来预测一个为具体代理的以自我为中心的RBC图像帧种每个物体的边界框(bounding box)和类别标签(category class label)。一般来所,该任务会给定一个场景(scene) S ∈ S S\in\bf{S} S∈S和一个位置(position) p p p,并要求对每个物体 o ∈ O S , p o\in{\bf{O}}_{S,p} o∈OS,p进行预测。当中的 O S , p {\bf{O}}_{S,p} OS,p表示场景 S S S位置 p p p的以自我为中心的RGB图像帧 f S , p f_{S,p} fS,p中可以见到的所有物体的集合。另外,一个代理(agent)也会被允许依据一些策略(policy) P \mathcal{P} P在行为集(action set) A \mathbf{A} A中采取 n n n个行为(action),并记录该代理所看到的 n n n个额外的RGB图像帧。我们把这 n n n个图像帧序列叫做 F \mathbf{F} F。我们然后使用一些以 F \mathbf{F} F作为输入的模型 M \mathcal{M} M来预测 O S , p {\bf{O}}_{S,p} OS,p中的每一个物体的边界框和对于的类别标签。【注意】作者只在每一个原始图像帧(initial frame)进行目标检测,否则,该代理会通过简单地移动到一个只有少量简单且可检测的物体的区域来“欺骗”模型训练。
对于每一个场景(scene) S ∈ S S\in\bf{S} S∈S的每一个位置(position) p p p,由于每一个代理可能会去探索不同的轨迹,这会造成多个不同的图像帧序列(many possible sequences of frames ) F \mathbf{F} F。作者把这些图像帧序列称为rollouts (滚动?),并且将一个给定的场景(scene) S ∈ S S\in\bf{S} S∈S中的位置(position) p p p所对应的所有rollout构成的集合定义为 R S , p {\bf{R}}_{S,p} RS,p。最终,因为有多个场景和每个场景有多个位置(它们中的每一个都是多个roullouts的开始位置点),因此作者将所有场景中的所有位置中的所有可能的rollout集合定义为 R all {\bf{R}}_{\textbf{\text{all}}} Rall,由此可得 F ∈ R S , p ⊂ R all \textbf{F}\in{\bf{R}}_{S,p}\subset{\bf{R}}_{\textbf{\text{all}}} F∈RS,p⊂Rall。总得来说,一个交互式目标检测任务 T \mathcal{T} T的每一个实例都包含了一个场景(scene) S ∈ S S\in\bf{S} S∈S以及一个开始位置(starting position) p p p,并且是从给定的一组场景的所有任务实例的某个分布 d ( T , S ) d(\mathcal{T}, \mathbf{S}) d(T,S)抽取的。
3.2 Standard approaches
解决这个问题最简单直接的方法是使用一个现有的目标检测器 M e x i s t \mathcal{M}_{exist} Mexist去简单地在原始图像帧 f S , p f_{S,p} fS,p执行目标检测。这里所使用的策略policy P n o − o p P_{no-op} Pno−op完全不采取任何行动。作者提出使用现有的来自于同一个领域内的数据来预训练该目标检测器作为一个交互环境使用从而提升网络模型的性能。
一个更加强大有效的方法是使用要给随机策略(random policy)去移动代理来围绕原始图像帧的起始位置 p p p收集多张图像帧,然后用他们作为输入去训练一个多帧模型multi-frame model M m f \mathcal{M}_{mf} Mmf从而在原始图像帧上做物体检测。用这些序列训练的模型可以学会利用由代理的围绕移动了收集起来的物体多视角去提升物体检测的性能。
3.3 Adaptive learning
直观地说,在一个环境的一个特定局部区域(无论是房间、建筑还是场景)训练物体检测器,可以提高该局部区域中其他附近帧的物体检测器的性能,因为这些环境(实际上是自然界)是连续的。作者通过实验验证了这一点。所以,作者提出将该任务表述为一个元学习(meta learning)的问题以适应该任务,当中的每个交互式物体检测任务 T \mathcal{T} T的每一个实例可以代表一个新的任务。
在训练时间中,这是成立的,因为 F \textbf{F} F中的每一个图像帧和它们对应的的真实标签可以看作是一个任务样本(task example),然后应用到MAML算法的其中一个版本上。这样就可以得到一个被 θ \theta θ参数化的物体检测器 M m e t a θ \mathcal{M}_{meta}^{\theta} Mmetaθ。通过在 F \textbf{F} F中的所有图像帧上做一个前向传导(forward pass)以及通过使用真实标签以及一个目标检测损失 L d e t \textbf{L}_{det} Ldet计算后向传导(backward)就可以训练这个模型了。然后,采取梯度步骤(gradient step)去更新网络模型的参数就可以得到 θ ′ = θ − α ∇ θ L d e t ( θ , F ) \theta^{\prime}=\theta-\alpha\nabla_{\theta}\mathcal{L}_{det}(\theta, \bf{F}) θ′=θ−α∇θLdet(θ,F)。在这通过最小化检测损失 L d e t \mathcal{L}_{det} Ldet就可以优化该模型了。上述过程需要在多个从 d ( T , S t r a i n ) d(\mathcal{T}, \mathbf{S}_{train}) d(T,Strain)抽取的任务中重复多次。 S t r a i n \mathbf{S}_{train} Strain是训练场景(training scene)的一个集合。
然而,在测试时间段内这个方法是不可行的,因为没有给定任何一个图像帧的真实标签。作者通过增加另外一个不基于标签而基于 F \bf{F} F中图像帧的损失函数来克服这一点。这个损失函数可以是手工设计的也可以是通过学习方式获取的。作者从[56][59]中获得启发并提出通过学习的方式来获取该损失函数(a learned loss function)。在该情景下,作者使用了一个由模型产生的以 F \bf{F} F中所以图像帧作为输入的被称为适应性损失(the adaptive loss)或者被 ϕ \phi ϕ参数化的 L a d a ϕ \mathcal{L}_{ada}^{\phi} Ladaϕ的被学习到的损失函数以及模型预测 M m e t a θ ( F ) \mathcal{M}_{meta}^{\theta}(\bf{F}) Mmetaθ(F)去产生用于动态自适应(dynamic adaptation)的梯度。对于所学到的损失,没有明确的目标函数。相反,我们只是鼓励最小化这一损失,以提高我们模型的检测能力。因此,这个模型的学习目标是
min θ , ϕ ∑ F ∈ R a l l L d e t ( θ − α ∇ θ L a d a ϕ ( θ , F ) , F ) \min_{\theta,\phi} \sum_{{\bf{F}}\in{{\bf{R}}_{\bf{all}}}} \mathcal{L}_{det}(\theta-\alpha\nabla_{\theta}\mathcal{L}_{ada}^{\phi}(\theta,\bf{F}), \bf{F}) θ,ϕminF∈Rall∑Ldet(θ−α∇θLadaϕ(θ,F),F)
正如上面所提到的, L d e t \mathcal{L}_{det} Ldet在测试时间内是不可用的,所以 L a d a ϕ \mathcal{L}_{ada}^{\phi} Ladaϕ的参数是要被冻结的,只有 M m e t a θ \mathcal{M}_{meta}^{\theta} Mmetaθ可以根据 L a d a ϕ \mathcal{L}_{ada}^{\phi} Ladaϕ进行训练。通过使用获取自随机策略random policy P r a n d P_{rand} Prand的 F \bf{F} F中的图像帧中所包含的信息,这个方法让我们可以动态地使本文所提出的物体检测器适应它自身的局部环境。
3.4 Interactive adaptive learning
在标准的自适应和元学习应用中,通常基于这样一个假设来进行操作:每一个任务的数据样本的分布应该是固定的,且无法被影响到。在交互式情境下,这就不成立了,因为用于自适应的样本是通过代理(agent)来收集的。通常情况下,在每一个时间步骤中,代理会依据一个使用它先前看到的图像帧作为输入的策略policy P \mathcal{P} P(注意, P \mathcal{P} P用于表示通过学习方式获得的policy,而 P P P则是用来表示预先定义的policy)来执行action a a a。依据不是所有样本都提供同样数量和质量的信息的直觉,作者提出一个可学习的方式获得的策略 P i n t \mathcal{P}_{int} Pint,这是一个以ρ为参数的神经网络,并通过对其进行优化,以引导代理agent沿着图像帧 F \bf{F} F的序列前进使 M m e t a \mathcal{M}_{meta} Mmeta更容易适应新任务。
为了学习 P i n t \mathcal{P}_{int} Pint,作者提出必须首先找到一个方法去为获得到的actions中的每一个rollout F \bf{F} F匹配一个值。作者通过衡量产生于基于有标签样本计算得到的检测损失detection loss L d e t \mathcal{L}_{det} Ldet的关于 θ \theta θ的梯度与the learned loss L a d a ϕ \mathcal{L}_{ada}^{\phi} Ladaϕ所产生梯度的相似性的方式来实现上述目标。更具体地说,作者衡量了 L d e t \mathcal{L}_{det} Ldet使用第一帧的真相标签所产生的梯度和 L a d a \mathcal{L}_{ada} Lada针对于使用代理收集的图像帧序列所产生的梯度之间的 ℓ 1 \ell_1 ℓ1距离。通过这种方式,作者促使代理agent去收集图像帧以能够帮助the learned loss去模仿接近真实标签所提供的损失信息。为此,这种方式称为Initial Frame Gradient Alignment (缩写为 I F G A IFGA IFGA ),它的具体定义如下:
I F G A ( F ) = ∑ ∣ ∇ θ L a d a ϕ ( θ , F ) − ∇ θ L d e t ( θ , [ f S , p ] ) ∣ IFGA(\mathbf{F})={\sum} |\nabla_{\theta}\mathcal{L}_{ada}^{\phi}(\theta, \mathbf{F})-{\nabla}_{{\theta}}{\mathcal{L}}_{{det}}(\theta, [{f}_{{S,p}}])| IFGA(F)=∑∣∇θLadaϕ(θ,F)−∇θLdet(θ,[fS,p])∣
为此, I F G A IFGA IFGA 能够促使the learned loss获取到另外的非常有用的训练信号。注意,由于the lerarned loss的评估器只使用了 n + 1 n+1 n+1个图像帧 (原始图像帧加上 n n n个被代理agent收集到的图像帧)作为输入去计算the adaptive loss,因此在这里也只是计算了 n + 1 n+1 n+1长度的完整序列的 I F G A IFGA IFGA。
然后,作者定义了一个完整的开放策略(full expoitation policy) P e x p \mathcal{P}_{exp} Pexp。在给定任何不完整的图像帧序列 F i n c \mathbf{F}_{inc} Finc ( ∣ F i n c ∣ < n |\mathbf{F}_{inc}|
L p o l ( P i n t ρ , F ) = − P e x p ( F ) T log P i n t ρ ( F ) \mathcal{L}_{pol}(\mathcal{P}_{int}^{\rho}, \mathbf{F})=-P_{exp}(\mathbf{F})^{T}\text{log}\mathcal{P}_{int}^{\rho}( \mathbf{F}) Lpol(Pintρ,F)=−Pexp(F)TlogPintρ(F)
对于一个代理在环境中被允许采取 n n n个步骤的任务,作者定义了adaptive gradient步骤的学习率为 α \alpha α,而检测器,the learned loss以及policy的学习率分别定义为 β 1 \beta_{1} β1, β 2 \beta_{2} β2和 β 3 \beta_{3} β3。
Interactron算法的伪代码如下表

正如Algorithm 1所示,除了策略不是 P r a n d P_{rand} Prand而是 P i n t \mathcal{P}_{int} Pint之外,在adaptive interactive learning的推断过程与 Adaptive learning 段落中的是一致的。通过这种方法,这不仅利用了作者所提出模型适应场景局部区域的能力,而且还利用了这样一个事实,即可以为所提出模型提供良好训练示例的图像帧也往往包含有用的信息。
4 Models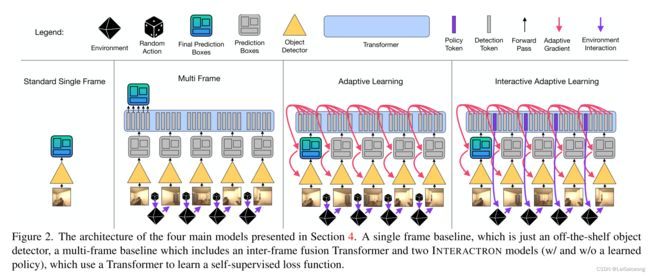
4.1 INTERACTRON model
本文的框架主要包括两个模型:Detector和Supervisor。Detector用于处理目标检测的任务,并且在测试阶段自适应局部环境。Supervisor则包含了the learned loss L a d a \mathcal{L}_{ada} Lada和the learned policy P i n t \mathcal{P}_{int} Pint,并且在测试阶段要求被冻结的。
The Detector
Detector可以是任何现成的物体检测模型,在本文中作者使用了DEtection TRAnsformer (DETR) 进行实验。 它在架构上很简单,但功能非常强大。 它利用生成图像特征的 ResNet 主干网络和处理所有特征以生成对象检测嵌入的 Transformer 模型。 然后每个object detection embedding会通过一个MLP层来提取边界框(bounding box)坐标和所需要预测的对象的类别标签。 尽管作者在模型的其他地方使用了 Transformer,但使用基于 Transformer 的对象检测器并不是该架构的要求。 作者也在Appendix中提供了FasterRCNN 的结果。
The Supervisor
Supervisor是一个Transformer模型,它即充当policy也充当the learned loss。检测器生成的图像特征和object detection embeddings统称为detection tokens,被传递到 Transformer。然后这些detection tokens的Transformer输出将会被传输经过一个MLP后会被缩减成一个常量一遍计算 the adaptive gradient。除此之外,对于每个代理需要采取的actions,一个learnable policy tokens也将会被输入到Transformer中,而它的输出将会被用来计算policy。
Learned Loss Training
习得性损失训练Learned loss training是通过将detection tokens的输出传递给 MLP后 并采用所有特征的 ℓ 2 \ell_2 ℓ2范数来获得作为自适应学习目标(adaptive learning objective)的标量来执行的。 ℓ 2 \ell_2 ℓ2范数是一种将 Supervisor Transformer 生成的向量序列组合成单个标量损失的技巧。正如Eq. 1所示的网络模型目标所示,Supervisor ϕ \phi ϕ 的参数被优化使得 Supervisor ∇ θ L a d a ϕ \nabla_{\theta}\mathcal{L}_{ada}^{\phi} ∇θLadaϕ所产生的梯度让检测器的训练损失减少。在训练阶段中,关于真实标签的损失从目标注释(object annotations)中计算得到的,并且它其中的预测结果predictions则由已被适应的检测器Detector构造的。用于调整检测器参数(Detector parameters)的梯度由 Supervisor 生成。我们可以通过自适应梯度(adaptive gradients)反向传播来更新 Supervisor 的参数,从而产生更好的自适应梯度(元训练meta-training)。
Policy Training
Policy training可以通过将该问题看作是一个序列预测任务(sequence prediction task)来解决。作者提出学习 n n n个不同的embeddings来产生 n n n个不同的Policy Tokens。通过将Policy Tokens的Transformer输出传递到一个MLP来产生一个动作概率预测分布(action probability distribution)。这样将会探索出一个长度为 n n n的针对所有可能性的运动轨迹,并然后该policy将会被优化以选择导致最低IFGA值的一个完备rollout F \textbf{F} F。当 n n n很小的时候,可以对每一条轨迹都进行探索,但是当 n n n很大的时候,随机探索或者强化学习的方法更可取。作者在本文中选择探索前者。因此,之后Detection Token会一次以一个图像帧的频度输入到Transformer中,然后经过Policy Token后输出用于预测代理agent应该采取的下一个动作(action)。在决定接下来要采取哪个行动(action)的时候,网络模型可以访问所有的先前图像帧。需要注意的是,自适应梯度(adaptive gradients)仅在执行完所有 n n n个步骤后才通过计算获得。
Figure 4
提供了更多的模型实现细节,如下图所示:

4.2 Ablation models
INTERACTRON-Rand
该模型本质上与上述交互式自适应学习模型相同,只是它不向Transformer 提供Policy Tokens,而是利用随机策略 P r a n d P_{rand} Prand。
The Multi-Frame Baseline
The Multi-Frame Baseline在架构上与自适应学习模型(Adaptive Learning Model)相同,但它不是将 Transformer 用作学习损失函数 L a d a \mathcal{L}_{ada} Lada,而是将其用作融合层,结合序列中所有图像帧的detector输出以产生关于第一个图像帧的检测结果。 此架构对应于Section 3.2中描述的模型 M m f \mathcal{M}_{mf} Mmf。
The Single Frame Baseline
Single Frame Baseline只是一个独立的检测器框架(也就是DETR),它已经在一些数据上进行了预训练,包括来自交互式环境中的所提供的图像,而这对应于 M e x i s t \mathcal{M}_{exist} Mexist。
5. Experiments
作者在所提供的最新版本的论文中提到, 本节的结果与 CVPR 2022 版本中的结果不同但趋势仍然相同。从两篇工作的结果可以观察到所提出方法的性能与基线之间存在巨大差距,差异是由于作者的评估代码中的错误导致的,该错误选择了测试集上的最佳检查点。
作者做了一系列实验来展示 INTERACTRON 模型的优势。 作者将所提出的方法与各种基线进行比较:non-adaptive baseline、跨多个帧聚合信息的non-adaptive baseline,以及随机探索场景的自适应基线(adaptive baseline)。 作者还在与用于训练的环境不同的额外的环境中进行实验验证,并评估所提出模型的适应性的优越性。 作者还进行了一组消融实验(ablation experiments)以更好地分析所提出的模型的性能。
Implementation details.
作者在 AI2-iTHOR [27] 交互式环境中进行了大部分实验,因为它提供了许多大小差异不大的场景、快速的渲染,以及执行域随机化的能力。 对于作者的主要任务,作者在实验中考虑 了5种图像帧(初始图像帧加上代理agent与环境交互过程种收集而来的 4 个图像帧)。 另外,作者使用了包括 MoveForward、MoveBackward、RotateLeft、RotateRight在内的动作集(action set)和 30 度旋转角度。 作者使用 300 × 300 300\times300 300×300大小的图像进行评估,以更高分辨率的图像进行物体检测可以显着提高模型的性能。 尽管如此,它还是带来了显着增加的计算复杂性,因此作者将探索不同的解决方案留待未来的工作。
对于主要实验,作者使用训练集 d ( T , S t r a i n ) d(\mathcal{T}, \textbf{S}_{train}) d(T,Strain)来训练INTERACTRON 网络模型并在 d ( T , S t e s t ) d(\mathcal{T}, \textbf{S}_{test}) d(T,Stest)上对其进行测试。 作者在训练集上训练所提出的模型 2,000个training epochs,并使用 SGD优化器推进元训练(meta-training)步骤,并使用 Adam 优化器训练习得性损失the learned loss和策略模型policy models。(有关训练的详细信息可以参阅作者所提出的附录)作者还确保在整个训练过程中探索所有可能的轨迹。 Single Frame Baseline只是预训练的目标检测器,而多帧基线是使用 Adam 优化器在 d ( T , S t r a i n ) d(\mathcal{T}, \textbf{S}_{train}) d(T,Strain)上训练了1000 轮。 这篇工作使用了标准的 COCO 评价指标来获取最终的评价结果。
**Dataset.**作者收集了两个数据集包括 d ( T , S t r a i n ) d(\mathcal{T}, \textbf{S}_{train}) d(T,Strain)和 d ( T , S t e s t ) d(\mathcal{T}, \textbf{S}_{test}) d(T,Stest),其中 S t r a i n \textbf{S}_{train} Strain由 AI2-iTHOR的training scenes和validation scenes(总共 100 个场景scenes)组成, S t e s t \textbf{S}_{test} Stest则由AI2-iTHOR的测试场景test scenes(20 个场景)组成。 数据集由场景ID S S S、代理agent的起始位置agent starting positions p p p以及从起始位置starting positions O S , p \textbf{O}_{S,p} OS,p可见的每个对象的标签组成。 起始位置(由位置和旋转坐标positional and rotational coordinates组成)是从给定场景的所有可用位置中随机采样的。 每次采样后,给定场景中所有对象的位置都是随机的。 作者从训练和验证场景中统一抽取总共 1000 对 S , p {S,p} S,p,从测试场景中抽取 100 对 S , p {S,p} S,p。 请注意,代理agent 可以根据策略探索不同的轨迹,所以只有测试集中的初始帧是固定的。
作者还从带有对象检测注释的训练场景中收集了包含10K 个图像帧的预训练数据集pre-training dataset以训练基础对象检测器the base object detector。 作者采用与上述相同的抽样方法。另外,作者也创建了一组新的检测类别detection classes,它们是LVIS 和 AI2-iTHOR 的所有对象类别object categories的并集。 因此,总共有1,235 个object categories和一个“背景”类别“background” category。 对于作者的 AI2-iTHOR 评估,作者仅使用 125 个 iTHOR 对象类,而其他类则直接被忽略。
Pre-training the model.
作者使用 DETR 代码库对来自 AI2-iTHOR 预训练数据集的 124K LVIS 图像和 10K 图像数据集进行模型预训练,所使用的是标准的 500 epoch training schedule。
5.1. INTERACTRON Results Table

5.2. Transfer Results

这项工作的主要目标之一是使作者的模型适应新环境。 为了评估 INTERACTRON 模型的跨环境适应性能力(the cross-environment adaptability performance),作者在具有完全不同外观特征(自然图像与合成 AI2-iTHOR 图像)的 Habitat环境中对其进行评估。 在 AI2-iTHOR 环境中训练了INTERACTRON 模型之后,作者在 Habitat 环境中执行自适应推理(adaptive inference)的测试。 作者在 Habitat 任务实例的数据集上测试作者的模型,这些实例的生成类似于作者的 AI2-iTHOR 任务实例(参详见附录C)。 对于这组任务,作者只使用了训练模型所用到的 iTHOR 类别以及Habitat类别(它总共包含了22 个object categories)的交集。 Table 2 显示了在 AI2-iTHOR 图像上训练的 INTERACTRON 模型几乎能够与在 Habitat 中接受全面监督的预训练检测器表现出相当的性能。 这表明本文所提出的方法允许模型适应新环境而无需访问来自该环境的训练数据或标签,以及模型可以访问该环境中的标记数据。 有趣的是,对于小物体,INTERACTRON 优于基线方法(参阅 Table 2中的 A P S AP_S APS 列), 这表明INTERACTRON 实际上可以利用后面获得的图像帧中的信号来更新其对通常难以检测的小物体或部分可见物体的belief。
5.3. Ablations

No Training at test.
为了评估本文所提出的习得性损失函数 L a d a \mathcal{L}_{ada} Lada的性能贡献,作者评估了INTERACTRON模型在没有该项损失函数的情况下在测试集上的性能。详细地,作者根据 P i n t \mathcal{P}_{int} Pint展开轨迹探索,然后根据 L a d a \mathcal{L}_{ada} Lada简单地阻止梯度更新。 Table 3 显示了经过元训练的模型,在没有进行测试训练梯度更新的情况下,其性能明显低于本文中所提出的完整模型,这展示了该模型在测试时进行训练的贡献。 事实上,如果没有在测试时间进行网络模型的自适应,该模型比现成的检测器基线(the off-the-shelf detector baseline)表现地更差。

Varying number of frames.
由于作者已经证明从 5 个图像帧(frame)中收集的信息比仅依赖单个图像帧更有用,因此自然会询问添加更多图像帧是否有助于进一步改进作者的模型。 作者为了进行对比实验测试,他们分别使用图像帧长度(图像帧数)为 7 和 9 的 rollouts 中训练 INTERACTRON 模型。 在训练这些时,作者放慢了训练的进程(training schedule)并增加了网络的迭代次数training epochs,因为这些序列长度将会增加更多可以被探索的轨迹(详见附录E)。 通过Table 4,可以发现通过添加更多图像帧获得的任何改进都在作者模型的训练噪声范围内。

Multiple copies of the same frame.
本文作者也额外探索了在训练模型时用原始图像帧(five repetitions of the first frame)的五次重复来代替五个单个的图像帧(five unique frames)。 在附带policy training的完整INTERACTRON模型上做这些探究实验是没有意义的,所以作者只使用 INTERACTRON-Rand模型。 Table 5 显示了结果。 经过训练只查看第一图像帧的模型比现成的 DETR 模型表现更好,但比查看 5 个不同图像帧的模型差。 这种改进可以归因于Supervisor Transformer 的额外的学习能力。 这验证了作者的自适应方法实际上受益于从被探索的轨迹中的所有图像帧中提取的信息以使模型适应当前环境。
Variance analysis.
作者重复 AI2-iTHOR 训练来计算运行之间的性能差异。 作者发现四次不同训练的 AP50 之间的标准差为 0.01。
5.4. Qualitative Results
Figure 3 显示了由INTERACTRON制作的一系列图示,他们都来自于边界框的预测置信度分数大于 0.5 的检测结果。
第一行展示了 INTERACTRON模型所擅长情况的示例。 原始的DETR未能够检测到放置在代理视野边缘的杯子cup,但 INTERACTRON由于会调整代理agent的位置,从而它获得多个更好的杯子视野。 同样,另外的多个抽屉drawer也被 INTERACTRON 检测到了。
第二行显示了INTERACTRON模型的成功案例和失败案例。 DETR只看到沙发扶手the arm of the sofa,并且将其错误地归类为扶手椅armchair,,而从其他角度看,INTERACTRON发现它是沙发sofa。 它还能够正确检测出雕像statue。 另一方面,DETR 可以检测到INTERACTRON模型所遗漏的报纸the newspaper,并且 INTERACTRON 将壁炉fireplace错误地标记为笔记本电脑laptop,这是它稍后在展示中看到的一个物体,并且错误地将壁炉fireplace与第一张图像中的位置相关联。
第三行显示了INTERACTRON在Habitat environment中的迁移效果(transfer results)示例。 代理开始时靠近沙发sofa,因此很难被识别出。 DETR 没有检测到它,而 INTERACTRON 向后退了几步,然后能够正确地将它标记为沙发sofa。 请注意,INTERACTRON 在训练期间从未见过Habitat数据集图像。
Appendix 附录
A. Pseudo Labels
作者使用多帧模型Multi-frame model和简单的伪标签方法研究了使用伪标签代替习得性损失的可行性。 这采用了一个经过预训练的多帧模型,并在评估期间使用检测器的输出结果作为伪标签来计算梯度从而进行模型更新,并通过检测器的预测结果的置信度进行加权。 结果表明,这种操作能够提供大约 2 个点的小性能改进(AP50值为 0.538)。 虽然最终模型结合了本文所提出的习得性损失函数的结果仍然优于当前改进的模型,但这种消融表明伪标签方法在该问题的设置中也可行。
B. Model Details 模型细节
作者将 DETR 模型与 ResNet50 主干用于作者的检测器。 作者冻结了 backbone 和 Transformer 编码器,只对 DETR 的解码器部分进行元训练。 作者使用基于 DETR 论文中描述的匈牙利匹配算法的损失函数作为作者的地面真值检测损失 Ldet。 作者为每个图像帧设置最多 50 个检测。
对于监测器Supervisor来说,作者使用了基于 GPT 架构中的4-Layer-8-Head Transformer(内部的维度为 512)。另外,该Supervisor还包含两个独立的嵌入层embedding layer,分别作用于图像特征Image Features和目标检测特征Object Detection Features。 Object Detection Features在 DETR 论文中被描述为查询标记的输出嵌入(the output embaddings of the query tokens),并且序列中的每个token都会习得性获得一个位置嵌入positional embedding。 该Supervisor还包含两个解码器decoders,每个解码器decoder由三个连续的线性全连接层组成,隐层维度为 512,并之后由 GeLU 非线性分隔。 其中一个解码器decoder使用the detection tokens的输出并用于计算习得性损失the learned loss,而另一个解码器decoder则用于解码Policy tokens的输出并生成相应的策略policy。 习得性损失the learned loss是通过采用通过解码器decoder的所有的detection tokens的输出的 ℓ 2 \ell_2 ℓ2范数来计算获得的。
C. Data Collection Details 数据收集细节
C.1. iTHOR Data Collection Details iTHOR数据收集详情
对于所有关于iTHOR 数据集的一切,所有物体都会被标记为 1235 个物体类别之一,这些类包括了所有的LVIS和iTHOR中的所有对象类别object categoy的并集。
The iTHOR Pre-Training Dataset
iTHOR 预训练数据集是从 train split和 val split中的 100 个场景(场景scenes 0-25、200-225、300-325、400-425)中收集来的,然后从这些场景中统一采样帧以收集总共 10,000 个图像帧及其注释(annotations)。 在收集每个样本之前,场景中每个对象的放置将会被随机洗牌。 如果图像帧中可见的对象少于 3 个,则拒绝该帧并为其绘制新的样本。 注释以 LVIS 格式存储。 最后,将收集好的数据添加到LVIS数据集中,这将共同构成iTHOR+LVIS预训练数据集。
The iTHOR Training Set
iTHOR 训练集是从 train 和 val splits 的 100 个场景中收集的。 作者从这些场景中统一采样起始位置,以收集总共 1,000 个起始位置帧。 在收集每个样本之前执行场景中对象放置的随机洗牌。 如果帧中可见的对象少于 3 个,则拒绝该帧并为其绘制新的样本。 除此之外,还会收集代理agent可以从任何采样起始位置获取的每条可能轨迹中的每一帧。 这个实现细节允许预缓存代理可以采取的每一个可能的轨迹来提高训练效率。
The iTHOR Test Set
iTHOR 测试集是则从test split中的 20 个场景(场景 25-30、225-230、325-330、425-430)中收集的。 作者从这些场景中统一采样起始位置,以收集总共 100 个起始位置帧。 如果帧中可见的对象少于 3 个,则拒绝该帧并为其绘制新的样本。除此之外,还会收集代理agent可以从任何采样起始位置获取的每条可能轨迹中的每一帧。 这个实现细节允许预缓存代理可以采取的每一个可能的轨迹来提高训练效率。
C.2. Habitat Data Collection Details Habitat数据收集详情
对于所有关于Habitat 数据集的一切,所有物体都会被标记为 1255 个物体类别之一,这些类包括了所有的LVIS、iTHOR和Habitat 中的所有对象类别object categoy的并集。
The Habitat Pre-Training Dataset.
Habitat 预训练数据集是从 MP3D train split的 56 个场景中收集的。 作者从这些场景中统一采样图像帧以收集总共 10,000 帧及其注释。 每个场景都有相同数量的样本,无论其大小如何。 如果帧中可见的对象少于 3 个,则拒绝该帧并为其绘制新的样本。 注释(annotations)以 LVIS 格式进行存储。 将数据添加到iTHOR+LVIS预训练数据集中,共同构成Habitat+iTHOR+LVIS数据集。
The Habitat Test Dataset.
Habitat测试数据集是从 MP3D val spilt中的 11 个场景收集的。 作者从这些场景中统一采样起始位置,以收集总共 100 个起始位置帧。 每个场景都有相同数量的样本,无论其大小如何。 如果帧中可见的对象少于 3 个,则拒绝该帧并为其绘制新的样本。 除此之外,还会收集代理agent可以从任何采样起始位置获取的每条可能轨迹中的每一帧。 这个实现细节允许预缓存代理可以采取的每一个可能的轨迹来提高训练效率。
D. DETR Pre-Training Details DETR 预训练细节
作者使用DETR的官方代码库对DETR的物体检测器(object detector)进行预训练,并修改为接受文中所需数据集的格式。 作者使用与原始 DETR 论文中提出的相同训练参数,在 iTHOR+LVIS 预训练数据集上训练一个检测器detector,而在 Habitat+iTHOR+LVIS 数据集上则训练了另一个检测器detector。文中还提到实验中所有预训练图像都被缩放了,使使得维度保持为300。
E. Training Details 训练细节
E.1. Interactron Training
INTERACTRON 模型使用 Adam 优化器训练了 2,000 个迭代周期(即training epochs),当中使用的初始学习率为1e−4以及线性的退火计划(linearly annealing schedule)。 产生习得性学习损失(the learned loss)和the policy的Supervisor模型和检测器Detector本身都使用这些参数进行训练。 为了稳定训练,作者在最后 500 个 迭代周期中的每一个之后记录权重,并对它们进行平均以生成最终模型。 使用单个 Nvidia RTX 3090 训练整个模型大约需要 120 小时。
在训练期间,作者不遵循模型的策略(the policy of the model),而是从给定的起始位置探索代理可能采取的每条可能轨迹, 然后记录每个可能轨迹的 IFGA 值,并在重新访问相同轨迹时更新它。 另外,需要优化模型中的的policy构件从而使得模型始终追求所记录的 IFGA值最低的轨迹。
与通用命名法略有矛盾的是,一个epoch并不代表通过作者数据集中的每一图像帧,因为智能体可以从每个起始位置探索多个轨迹。 例如,对于the 5-frame(4 step)实验,作者只能保证在 256 轮训练后探索了数据集中的每个可能图像帧。
E.2. Interactron 7 Frame Training
为了训练Interactron 7 Frame模型(其中的6个步骤是由代理Agent采取的),作者使用相同的初始学习率和退火计划(annealing schedule)训练网络模型5,000 个training epochs。 通过这种方式,作者确保代理可以从每个初始图像帧中获取的每条可行轨迹至少被探索过多次。
E.3. Interactron 9 Frame Training
为了训练Interactron 9 Frame模型(其中的8个步骤是由代理Agent采取的),作者使用相同的初始学习率和退火计划(annealing schedule)训练网络模型9,000 个training epochs。 通过这种方式,作者确保代理可以从每个初始图像帧中获取的每条可行轨迹至少被探索过一次。