A DIRT-T APPROACH TO UNSUPERVISED DOMAIN ADAPTATION
这篇是一篇领域自适应(domain adaption,迁移学习的一种)方面的文章,因为我本身的研究方向不是这个,只是老师推荐看的所以我就随便做点笔记,就当做整理一下自己的思路吧。说实话,这里肯定有很多专业术语上面的问题或者其他方面的问题,麻烦大家多多包涵啦。
基本问题和动机:
领域自适应(Domain adaptation)是指利用源域(source domain)中的标记数据来学习一个可以应用于无标签(或标签稀少或标签不可用)目标域(target domain)分类问题的精确模型。
2015年Ganin & Lempitsky通过领域对抗训练(domain adversarial training,DAT)的方法尝试诱导一个特征特区器来匹配某些特征空间中的源域和目标域的特征分布以寻找到源域和目标域的共同表示(这里我理解的可能有些问题,所以就直接翻译了,我的理解是通过DAT方法将源域和目标域的特征分别映射到同一个特征空间或者是两个可进行比较的特征空间)。然而这种方法有两种缺陷,
1)如果特征提取函数具有高容量性(high-capacity),那么特征分布匹配就是一种弱约束,造成源域和目标域不相交。
2)在non-conservative domain(也就是说单分类器无法同时在源域和目标域表现得很好)中,如果训练分类器使其在源域表现得过好,那么就可能会影响目标域的分类性能。
针对上面两种缺陷,作者提出两种方法以解决问题:
第一种是提出Virtual Adver- sarial Domain Adaptation(VADA)模型,这种模型结合了DAT和一个对违反cluster assumption进行惩罚的惩罚项,进一步约束假设空间。(cluster assumption表示的是输入的分布中包含了几个聚类cluster而在同一个聚类中的数据点又是属于同一类,即标签相同)
第二种是Decision-boundary Iterative Refinement Training with a Teacher(DIRT-T)模型,这种模型是训练好了的VADA模型作为初始化模型基础之上进行目标域数据的无监督训练以进一步减小cluster assumption violation,通过使用自然梯度(nature gradient)进一步调整VADA模型的输出,使其更加关注到目标域。
解决思路:
(1)VADA模型

在介绍VADA模型之前先介绍一下DAT,他的损失函数是
![]()

式(5)是DAT的损失函数,由式(3)和式(4)组成。D是领域判别器(domain discriminator),式(3)是交叉熵损失,用于源域的分类。式(4)的作用是使源域和目标域的输出的Jensen-Shannon divergence变小(即使源域和目标域输出的分布尽可能地接近,将源域数据和目标数据映射到一个共同特征空间之后尽量保证两者分布趋近,类似于两者的距离)。
在DAT基础之上,VADA模型就诞生了。
![]()
![]()
![]()
式(8)即为VADA模型的损失函数,由源域交叉熵损失、式(4)、式(7)和式(6)组成,其中式(7)是虚拟对抗训练(DAT),分别用于源域和目标域数据。
对于式(6),如果cluster assumption成立的话,那么最优决策边界将会远离输入特征空间中数据分布密集的区域,因此根据Grandvalet & Bengio (2005)文献,可以最小化无标签目标域数据的条件熵(conditional entropy)来迫使分类器的决策边界远离目标域数据。
Grandvalet & Bengio (2005) 中还提出,如果分类器的不是locally-Lipschitz的,那么上述条件熵的作用将会变得不起作用,因此作者又引入了额外的虚拟对抗训练的损失函数式(7)以保证优化时分类器是满足locally-Lipschitz约束。
(2)DIRT-T模型
前面说到,在non-conservative domain中,如果训练分类器使其在源域表现得过好,那么就可能会影响目标域的分类性能。为了解决这个问题,作者在VADA模型基础之上提出了DIRT-T模型。

从上图中可以很清晰地看出,由于non-conservative domain的存在,经过VADA模型训练之后,决策边界能够很好地将源域数据的类别分开(红色和蓝色),然而,对于目标域的数据决策边界却无法很好地把把它们的类别分开,因此,作者就在VADA模型基础之上使用DIRT-T模型进行目标域无监督训练,使得决策边界微调到更有利于目标域的分类。
DIRT-T目标函数,

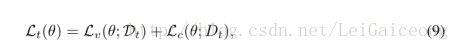
从目标函数中可以看到,作者是希望对VADA模型损失中的目标域虚拟对抗训练和条件熵进行优化,从而优化模型的决策边界。从公式(14)中可以看出,作者通过KL-divergence的思想构造一个约束,把hθn-1作为一个Teacher model,hθn作为一个Student model,让后者向前者学习,从而使决策边界向对目标域分类有利的方向微调。
上诉的优化问题可以解释为“弱监督学习”。在每一个优化问题中,Teacher model可以给带有噪声标签的目标样本赋予伪标签。相较于在带有噪声的标签上对Student model进行训练,额外的training signals能够使得Student model将决策边界从数据中进一步调优。如果cluster assumption成立,并且初始的noisy labels与真正的标签非常相似,那么条件熵的最小化可以调整决策边界。
实验
本论文中作者做了三个实验来验证VADA模型和DIRT-T模型的有效性。
(1)验证虚拟对抗训练在VADA模型和DIRT-T模型上的有效性
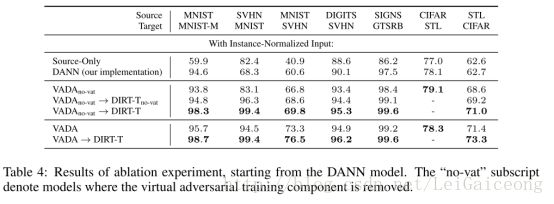
从Table4中可以看出,七个实验的六个实验中加入VAT和调条件熵能使实验结果表现得最好。从实验中可以发现,加入VAT之后能够看出locally-Lipschitz约束能够很好地让分类器的决策边界往更有利于目标域分类的方向微调。
(2)验证DIRT-T中Teacher model的作用

从先把DIRT-T的损失函数放出来,

从Figure 4中可以看出,如果beta=0,既没有KL项的时候,无论在实验还是实验都会给实验结果带来不利影响。作者认为在没有KL项约束的情况下,分类器有时会明显偏离前一分类器的邻域,因此KL项中的尖峰对应的目标域测试准确率的急剧下降。在实验中,数据的分布非常复杂且包含更不明显的clusters,直接的梯度下降会导致目标域测试准确率直接下降。
(3)模型示例的可视化

作者对实验中网络的最后一层进行了可视化。在Source-Only可以看到,蓝色的源域MNIST样本能够很好地进行聚类,而红色的目标域SVHN样本聚成一大簇,无法很好得形成每个类的聚类。在VADA模型中,红色的目标域SVHN样本能够产生了比较明显的聚类效果,经过DIRT-T模型之后,红色目标域SVHN样本的聚类效果最为明显了。
(4)探索网络层数对DAT的效果影响
