相似图片去重--余弦相似度和sift算法
----------------题目-------------------
摄影师小刘爱好摄影,有许多照片(不同格式,不同分辨率),有的是自己拍摄的,有的是朋友的相机帮忙拍到的。
但他很苦恼,因为有很多照片是类似的(比如,稍微偏了一点角度),请用程序帮他把类似的图片挑选出来。
1.准备数据(文章末尾有链接)
准备了120张图片,格式有png,jpg各占一半,且有三种大小1:1,4:3,full 均分。
2.实验设计思路
(1)统一图片格式,方便下一步的比较——300300的png格式。
(2)计算两张图片之间的距离,判定图片相似的相似度阈值
计算图片之间的距离有很多种方法,我选择了计算图片之间的余弦相似度。
相似度阈值的确定:构造一个相似的照片成对出现的样本,通过计算每一对的相似度值,选取最小且合理的值为阈值(0.86),即认为当相似度大于这个值时,就删去其中一张。
3.图片去重
根据筛选出来的结果,调整我们的阈值(0.87),再进一步得到更好的结果。
4.实验调整
整个实验做下来,运行时间过长(6小时),效果还是很好的,最后得到了36幅不同图片。现在想办法缩短一下时间,发现可以通过调整图片的比例和大小,设置了4个比例,得出下面的运行速度图(只有这4个点是可靠的)。
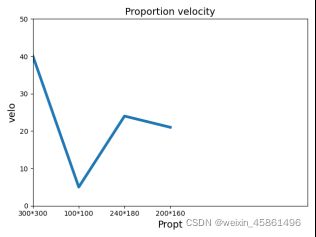
于是,我们现在使用100100的图片集来实现图片去重,最后得到35张图片,只花费了半个小时,可以说是非常值得了,还可以通过调整阈值(0.88)来弥补。
3.代码实现
(1)代码框架
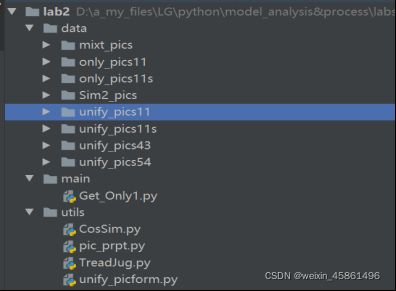 data文件夹:
data文件夹:
mixt_pics–原始图片,混合着不同格式和大小的120张图片;
Sim2_pics–构造的成对相似图片文件;
unify_picsxx:将原始图片统一格式为.png,xx可取下面表格的4个值,下同;
only_picsxx:去重后得到的图片集,xx意味着是对哪种类型的去重。
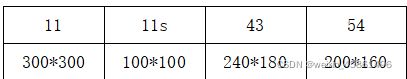
utils文件夹:
CosSim.py–计算两张图片的余弦相似度;
pic_prpt.py–画出对不同比例的处理速度曲线;
TreadJug.py–找到相似图片的合理的相似度分界点 threadholdjudge(这里的相似指的是只偏了一点角度);
unify_picform.py–统一图片的大小和格式。
(2)主要代码
unify_picform.py
#使所有照片的大小都统一为300*300,格式统一为.png unify_pics11
#使所有照片的大小都统一为240*180,格式统一为.png unify_pics43
#使所有照片的大小都统一为200*160,格式统一为.png unify_pics54
#使所有照片的大小都统一为100*100,格式统一为.png unify_pics11s
import cv2
import os
outtype = '.png' # <---------- 输出的统一格式
image_size_w = 200 # <---------- 设定长
image_size_h =160 # <---------- 设定高
source_path = "../data/mixt_pics/" # <---------- 源文件路径
target_path = "../data/unify_pics54/" # <---------- 输出目标文件路径
if not os.path.exists(target_path):
os.makedirs(target_path)
image_list = os.listdir(source_path)
# 获得文件名,这个地方的顺序乱了,正好打乱数据集,重新编号
#list(120)[''0.jpg'',''1.jpg'',....乱序]
i = 0
for file in image_list:
image_source = cv2.imread(source_path + file) # 读取图片d
print("处理中-->",file)
image = cv2.resize(image_source, (image_size_w, image_size_h), 0, 0, cv2.INTER_LINEAR)
# 修改尺寸
cv2.imwrite(target_path + str(i) + outtype, image)
# 重命名并且保存 (统一图片格式)
i = i + 1
print("批量处理完成")
CosSim.py
# 计算两张图片的余弦相似度
from numpy import average, linalg, dot
def CosSim(image1, image2):
images = [image1, image2]
vectors = []
norms = []
for image in images:
vector = []
for pixel_tuple in image.getdata():
vector.append(average(pixel_tuple))
vectors.append(vector)
norms.append(linalg.norm(vector, 2))
a, b = vectors
a_norm, b_norm = norms
res = dot(a / a_norm, b / b_norm)
return res
TreadJug.py
#找到相似图片的合理的相似度分界点 threadholdjudge(这里的相似指的是只偏了一点角度)
#先将unify_pics中所有的图片从文件夹复制到Sim2_pics文件夹中,人工筛选出成对的相似的图片
import datetime
import time
import os
from PIL import Image
from utils.CosSim import CosSim
#——————————————————————————————————————————————————————————————————————#
start_dt = datetime.datetime.now()
print("start_datetime:", start_dt)
time.sleep(2)
for i in range(10000):
i += 1
#——————————————————————————————————————————————————————————————————————#
Sim2_pics_path = "../data/Sim2_pics/"
Sim2_image_list = os.listdir(Sim2_pics_path)
Sim2_image_list.sort(key=lambda x:int(x[:-4]))
#给Sim2_pics里面的图片排好序
Sims = []
for i in range(0,len(Sim2_image_list),2):
img0 = Image.open(Sim2_pics_path+Sim2_image_list[i])
img1 = Image.open(Sim2_pics_path+Sim2_image_list[i+1])
sim = CosSim(img0,img1)
Sims.append(sim)
print(Sims)
#看到结果会发现有一些样本并不相似,眼花看错了,这种直接成对删除即可
#[0.9619623054567803, 0.9616339735852711, 0.9096149655317833, 0.9668034186000998, 0.9763342316609243, 0.8898721390144304, 0.9794886082631756, 0.8855574201574012, 0.8608441002718709, 0.9635481853715363, 0.903659455613319, 0.9006432345661939, 0.8732949568357835, 0.9629020059033538, 0.9170403900886609, 0.8702003480765763, 0.874373609783053, 0.9537583041067714, 0.8669105262204524, 0.9890501169546155, 0.9603054463979213, 0.9010165189044402, 0.9164895782283211, 0.951835633174128, 0.928385154992327, 0.9794886082631756]
print(min(Sims))
#0.8608441002718709
#即最后我们认为相似度低于0.86就是不相似的两张图片
#——————————————————————————————————————————————————————————————————————#
end_dt = datetime.datetime.now()
print("end_datetime:", end_dt)
print("time cost:", (end_dt - start_dt).seconds, "s")
#——————————————————————————————————————————————————————————————————————#
pic_prpt.py
#画出对不同比例的处理速度曲线
import datetime
import time
import matplotlib.pyplot as plt
from PIL import Image
import os
from utils.CosSim import CosSim
pics_path11 = "../data/unify_pics11/"
pics_list11 = os.listdir(pics_path11)
pics_path11s = "../data/unify_pics11s/"
pics_list11s = os.listdir(pics_path11s)
pics_path43 = "../data/unify_pics43/"
pics_list43 = os.listdir(pics_path43)
pics_path54 = "../data/unify_pics54/"
pics_list54 = os.listdir(pics_path54)
Pro_time = []
paths = [pics_path11,pics_path11s,pics_path43,pics_path54]
lists = [pics_list11,pics_list11s,pics_list43,pics_list54]
for i in range(len(paths)):
start_t = datetime.datetime.now()
#通过运行20次 CosSim(img0,img1) 函数,比较对不同比例的图片的处理效果
for j in range(0,40,2):
img0 = Image.open(paths[i]+lists[i][j])
img1 = Image.open(paths[i]+lists[i][j+1])
similar = CosSim(img0,img1)
end_t = datetime.datetime.now()
Pro_time.append((end_t - start_t).seconds)
print(Pro_time)
x_name = ['300*300','100*100','240*180','200*160']
plt.plot(x_name, Pro_time, linewidth=4)
plt.title("Proportion velocity",fontsize=14)
plt.xlabel("Propt", fontsize=14)
plt.ylabel("velo", fontsize=14)
#设置刻度标记
plt.tick_params(axis='both', labelsize=10)
plt.axis([0, 6, 0, 50])
plt.show()
Get_Only1.py
# 首先将第一张图片存进only1文件夹,然后每一来一张图片就从最后一张开始比较,如果不是已有的图片就存进来。
import datetime
import time
#——————————————————————————————————————————————————————————————————————#
start_dt = datetime.datetime.now()
print("start_datetime:", start_dt)
time.sleep(2)
for i in range(10000):
i += 1
#——————————————————————————————————————————————————————————————————————#
from PIL import Image
import os
from utils.CosSim import CosSim
import cv2
from tqdm import tqdm
import shutil
# pics_path = "../data/unify_pics11/".
# picsonly_path = "../data/only_pics11/"
pics_path = "../data/unify_pics11s/"
picsonly_path = "../data/only_pics11s/"
pics_list = os.listdir(pics_path)
pics_list.sort(key=lambda x:int(x[:-4]))
#按照名称把图片顺序排好
threshold = 0.87 #为0.86时,效果并不好,并且有一些并不相似的图片被判定为相似,于是提高相似度
piconly_names = [pics_list[0]]
outtype = ".png"
if not os.path.exists(picsonly_path):
os.makedirs(picsonly_path)
shutil.rmtree(picsonly_path)
os.mkdir(picsonly_path)
##注意使用CosSim函数时的输入
for i in tqdm(range(1,len(pics_list))):
img0 = Image.open(pics_path+pics_list[i])
flag = 1
for j in range(len(piconly_names)-1,-1,-1):
img1 = Image.open(pics_path+piconly_names[j])
print("\n正在比较原始第{}张图片和去重后的第{}张图片".format(i,j))
similar = CosSim(img0,img1)
if CosSim(img0,img1) >= threshold:
flag = 0
break
if flag:
piconly_names.append(pics_list[i])
for _ in range(len(piconly_names)):
pico = cv2.imread(pics_path + piconly_names[_])
cv2.imwrite(picsonly_path + str(_) + outtype, pico)
#——————————————————————————————————————————————————————————————————————#
end_dt = datetime.datetime.now()
print("end_datetime:", end_dt)
print("time cost:", (end_dt - start_dt).seconds, "s")
#——————————————————————————————————————————————————————————————————————#
4.实现效果
(1)原始数据集(查看部分)


(2)运行时间对比
处理300300时,运行了4356s。
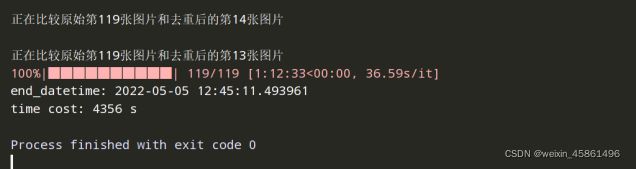
处理100100时,运行了962s。

(3)去重后图片集(前者是通过300300得到的36张,后者是通过100100得到的35张)


在最终的结果中,我们基本上达到了去重(去掉只偏了一些角度的图片)的目标,还可以看见有一些旋转角度较大的图片(24.png,25.png)没有被去重,认识到一种方法–SIFT算法可以找到旋转以及尺度不变的特征点,我尝试了一下,处理效果如下(函数在main下debig_shift.py):

# 对那些旋转较大角度的图片去重
import cv2
import numpy as np
#获取图片关键点和特征向量
def detectAndDescribe(image):
# 将彩色图片转成灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# SIFT生成器
destriptor = cv2.SIFT_create()
kps, features = destriptor.detectAndCompute(gray, None)
# 结果转成numpy数组
kps = np.float32([kp.pt for kp in kps])
return (kps, features)
#特征匹配
def matchKeyPoints(kpsA, kpsB, featuresA, featuresB, ratio=0.75, reprojThresh=4.0):
# 建立暴力匹配器
matcher = cv2.BFMatcher()
# KNN检测来自两张图片的SIFT特征匹配对
rawMatches = matcher.knnMatch(featuresA, featuresB, 2)
#元组类型,924对
matches = []
for m in rawMatches:
# 当最近距离跟次近距离的比值小于ratio时,保留此配对
# (, ) 表示对于featuresA中每个观测点,得到的最近的来自B中的两个关键点向量
if len(m) == 2 and m[0].distance < m[1].distance * ratio:
# 存储两个点在featuresA, featuresB中的索引值
matches.append([m[0].trainIdx, m[0].queryIdx])
# 这里怎么感觉只用了m[0]也就是最近的那个向量啊,应该没用到次向量
# 这个m[0].trainIdx表示的时该向量在B中的索引位置, m[0].queryIdx表示的时A中的当前关键点的向量索引
# 当筛选后的匹配对大于4时,可以拿来计算视角变换矩阵
if len(matches) > 4:
# 获取匹配对的点坐标
#主要逻辑是从图片B中给图片A中的关键点拿最近的K个匹配向量,然后基于规则筛选,
# 保存好匹配好的关键点的两个索引值,通过索引值取到匹配点的坐标值,
# 有了多于4对的坐标值,就能得到透视变换矩阵。 这里返回的主要就是那个变换矩阵。
ptsA = np.float32([kpsA[i] for (_, i) in matches])
ptsB = np.float32([kpsB[i] for (i, _) in matches])
# 计算视角变换矩阵 这里就是采样,然后解方程得到变换矩阵的过程
(H, status) = cv2.findHomography(ptsA, ptsB, cv2.RANSAC, reprojThresh)
return (matches, H, status)
# 匹配结果小于4时,返回None
return None
def drawMatches(imageA, imageB, kpsA, kpsB, matches, status):
# 初始化可视化图片,将A、B图左右连接到一起
(hA, wA) = imageA.shape[:2]
(hB, wB) = imageB.shape[:2]
vis = np.zeros((max(hA, hB), wA + wB, 3), dtype="uint8")
vis[0:hA, 0:wA] = imageA
vis[0:hB, wA:] = imageB
# 联合遍历,画出匹配对
for ((trainIdx, queryIdx), s) in zip(matches, status):
# 当点对匹配成功时,画到可视化图上
if s == 1:
# 画出匹配对
ptA = (int(kpsA[queryIdx][0]), int(kpsA[queryIdx][1]))
ptB = (int(kpsB[trainIdx][0]) + wA, int(kpsB[trainIdx][1]))
cv2.line(vis, ptA, ptB, (0, 255, 0), 1)
# 返回可视化结果
return vis
#读取两张有很大旋转的相似图片
image1 = cv2.imread('../data/only_pics11/24.png')
image2 = cv2.imread('../data/only_pics11/25.png')
# 检测A, B图片的SIFT特征关键点,得到关键点的表示向量
(kps_img1, features_img1) = detectAndDescribe(image1)
# kpsA (关键点个数, 坐标) features(关键点个数,向量)
#kps_img1 (924, 2) features_img1 (924, 128)
(kps_img2, features_img2) = detectAndDescribe(image2)
# 匹配两张图片的所有特征点,返回匹配结果 注意,这里是变换right这张图像,所以应该是从left找与right中匹配的点,然后去计算right的变换矩阵
M = matchKeyPoints(kps_img1, kps_img2, features_img1, features_img2)
if M:
# 提取匹配结果
(matches, H, status) = M
print('888888')
vis = drawMatches(image1, image2, kps_img1, kps_img2, matches, status)
cv2.imshow("vis",vis)
cv2.waitKey()
cv2.destroyAllWindows()
数据
链接:https://pan.baidu.com/s/1-d1UMFzCKLkEjdkKQYAlUA
提取码:2933