【week1】深度学习与pytorch基础
week01 深度学习与pytorch基础练习
-
- 深度学习笔记
-
- 深度学习
- 深度学习概述
- pytorch的基础练习
-
- 螺旋数据分类
- 构建线性模型分类
- 构建两层神经网络分类
深度学习笔记
人工智能的三个层面:
- 计算智能:能存 能算
计算机具有快速计算和记忆存储的能力 - 感知智能、能听会说、能看会认
是目前人工智能的层面,类似于人的视觉、听觉、触觉 - 认知智能: 逻辑推理、认识理解、决策思考、
机器学习的定义:
- 最常用定义:计算机系统能够利用经验提高自身的性能
- 可操作定义:机器学习本是一个基于经验数据的函数估计问题
- 统计学定义:提取重要模式、趋势、并理解数据,也即是从数据中学习
机器学习与专家系统的不同:

区别:是否是有意义的问题·、问题是否有解析解?

模型:主要的分类方式
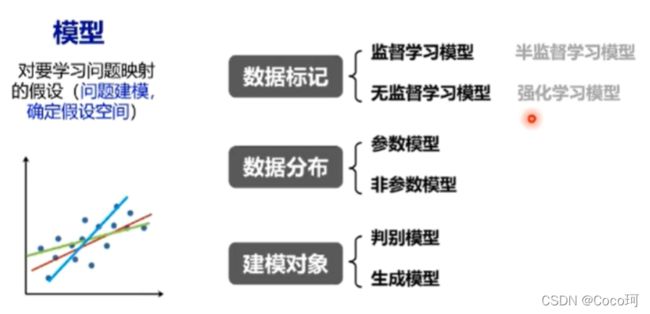
数据标记:
- 监督学习:从数据中学习标记分界面,适用于预测数据标记
- 无监督学习:从数据中学习模式,适用于描述数据
- 半监督学习:有一小部分有标注,大部分数据没有标注;标注数据成本过高,假设未标记的样本和标记样本独立同分布—>包含关于数据分布的重要信息
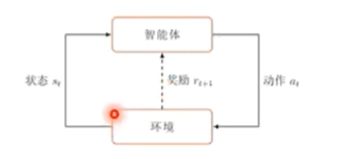
- 强化学习:使用未标记的数据,有奖励反馈—— 可以知道离目标越来越近还是越来越远,适合解决决策类问题
数据分布:参数模型和非参数模型
参数指的是数据分布的参数——而非模型的参数
参数模型指的是对数据分布可以进行假设,待求解的数据模型可以用一组参数刻画
非参数模型:不对数据分布做预测
建模对象:

深度学习
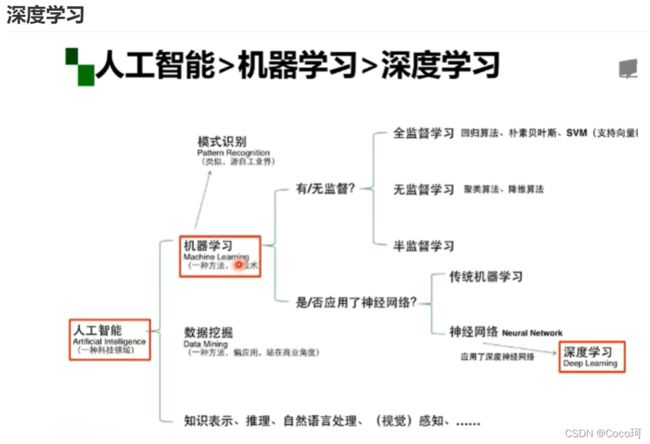
!!!深度学习只是机器学习的一种
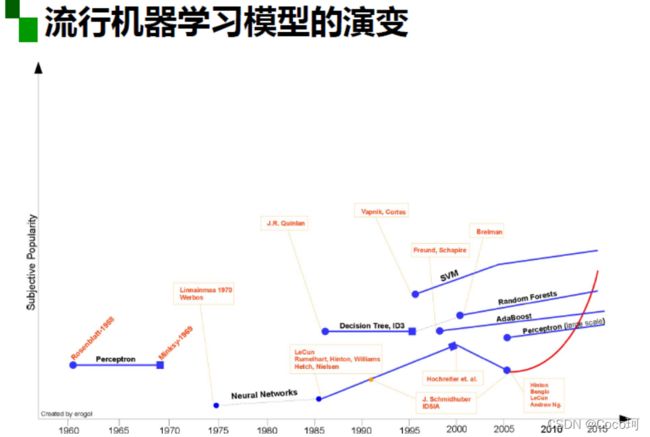
深度学习概述
深度学习应用研究:视觉+语言
- 深度学习的算法输出不稳定,容易被“攻击”
- 模型复杂度高,难以纠错和调试
- 模型层级复合程度高,参数不透明
- 端到端训练方式对数据依赖性强,模型增量性差
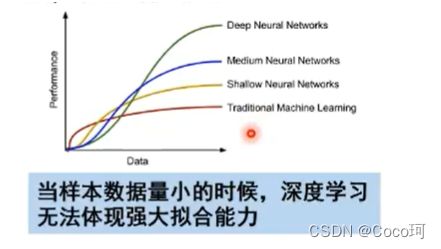
- 专注直观感知问题,对开放问题无能为力
- 人类知识无法有效引入进行监督,机器偏见难以避免
pytorch的基础练习
第一次了解到python的这个库,pytorch提供了GPU加速的张量计算和构建在反向自动求导系统上的深度神经网络这两个高级功能。下面是一些demo的代码练习和记录下的一些问题:
- 创建两个 1x4 的tensor,在Y方向上进行拼接会得到一个2x4的矩阵
import torch
x = torch.tensor(666)
m = torch.Tensor([[2, 5, 3, 7],[4, 2, 1, 9]])
v=torch.arange(1,5)
torch.linspace(3, 8, 20)
a = torch.Tensor([[1, 2, 3, 4]])
b = torch.Tensor([[5, 6, 7, 8]])
print( torch.cat((a,b), 0))

2. 如果在X方向拼接,得到一个1x8的矩阵
import torch
x = torch.tensor(666)
m = torch.Tensor([[2, 5, 3, 7],[4, 2, 1, 9]])
v=torch.arange(1,5)
torch.linspace(3, 8, 20)
a = torch.Tensor([[1, 2, 3, 4]])
b = torch.Tensor([[5, 6, 7, 8]])
print( torch.cat((a,b), 1))
![]()
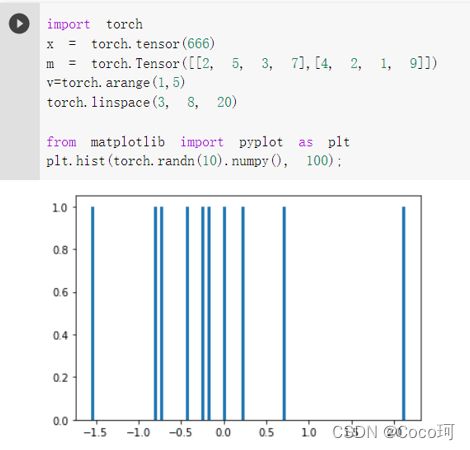
3. 是生成 1000 个随机数,并按照 100 个 bin 统计直方图
import torch
x = torch.tensor(666)
m = torch.Tensor([[2, 5, 3, 7],[4, 2, 1, 9]])
v=torch.arange(1,5)
torch.linspace(3, 8, 20)
from matplotlib import pyplot as plt
plt.hist(torch.randn(1000).numpy(), 100);
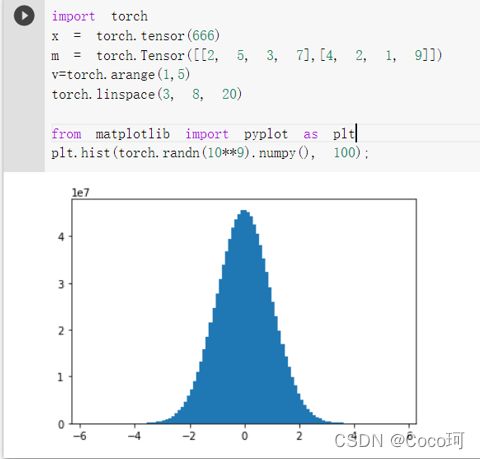
我们可以改变随机数的值,发现10^9次方个随机数更接近正态分布

小结:在进行pytorch的基础语法的学习时,运行矩阵点积代码出现了报错:
import torch
m = torch.Tensor([[2,5,3,7], [4,2,1,9]])
v = torch.arange(1, 5)
print(m @ v)
RuntimeError: expected scalar type Float but found Long
查阅资料发现 @ 不能直接运算,因为tensor的数据类型不匹配。
torch.Tensor()是Python类,是默认张量类型torch.FloatTensor()的别名,生成单精度浮点类型的张量。
而torch.tensor()仅仅是Python的函数,根据原始数据类型生成相应的torch.LongTensor
所以在运算前,需要使用dtype进行类型的统一设置。

螺旋数据分类
-
首先下载绘图函数到本地
-
初始化参数
!!!注意的是在 python 中,在调用 zeros 类似的函数中的第一个参数是 y方向的,即矩阵的行;第二个参数是 才是x方向的,即矩阵的列。 -
开始初始化3000个样本
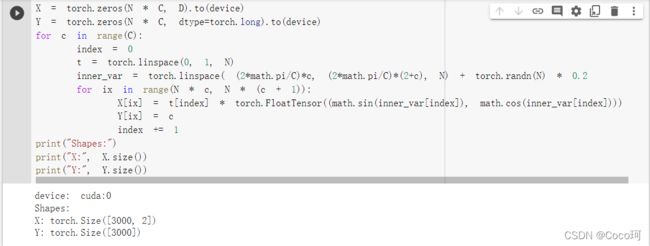
-
画图
记得要打开浏览器的cookies

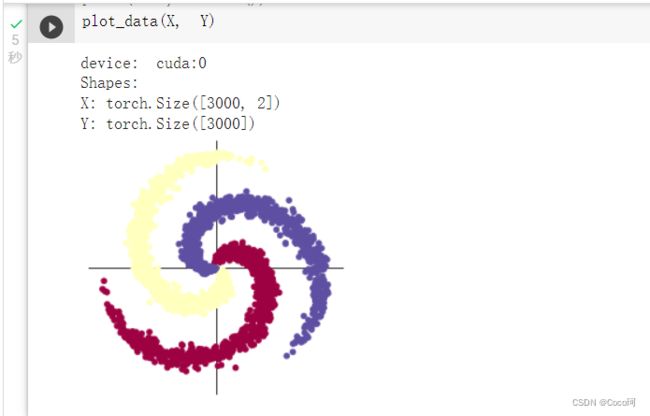
-
增加了 焦点写作模式、预览模式、简洁写作模式、左右区域同步滚轮设置 等功能,功能按钮位于编辑区域与预览区域中间;
-
增加了 检查列表 功能。
构建线性模型分类
代码如下:
learning_rate = 1e-3
lambda_l2 = 1e-5
model = nn.Sequential(
nn.Linear(D, H),
nn.Linear(H, C)
)
model.to(device) # 把模型放到GPU上
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=lambda_l2)
for t in range(1000):
y_pred = model(X)
loss = criterion(y_pred, Y)
score, predicted = torch.max(y_pred, 1)
acc = (Y == predicted).sum().float() / len(Y)
print('[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f' % (t, loss.item(), acc))
display.clear_output(wait=True)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(y_pred.shape)
print(y_pred[10, :])
print(score[10])
print(predicted[10])
print(model)
plot_model(X, Y, model)
其中的nn.Sequential是一个有序的容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行,同时以神经网络模块为元素的有序字典也可以作为传入参数。
打印出的model如下,可以看到分类是线性的,而且效果很不好。一个复杂的数据分布,用线性模型难以实现准确分类,准确率也只有50%

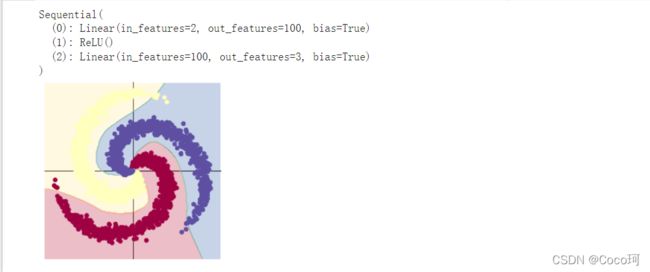
构建两层神经网络分类
在原先的线性模型中进行一些改动,主要是在model中加入一个激活函数ReLU,使其变成一个两层的神经网络
learning_rate = 1e-3
lambda_l2 = 1e-5
# 这里可以看到,和上面模型不同的是,在两层之间加入了一个 ReLU 激活函数
model = nn.Sequential(
nn.Linear(D, H),
nn.ReLU(),
nn.Linear(H, C)
)
model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=lambda_l2) # built-in L2
for t in range(1000):
y_pred = model(X)
loss = criterion(y_pred, Y)
score, predicted = torch.max(y_pred, 1)
acc = ((Y == predicted).sum().float() / len(Y))
print("[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f" % (t, loss.item(), acc))
display.clear_output(wait=True)
# zero the gradients before running the backward pass.
optimizer.zero_grad()
# Backward pass to compute the gradient
loss.backward()
# Update params
optimizer.step()
print(model)
plot_model(X, Y, model)
通过使用激活函数,可以增加一些非线性因素,可以看到准确率已经达到85%左右,对数据的分类也更加的准确了。