Convolution over Hierarchical Syntactic and Lexical Graphs for Aspect Level Sentiment Analysis论文阅读
来自EMNLP2020
《面向方面级情感分析的层次句法和词汇图卷积》
目录
- 0 Abstract
- 1 Introduction
- 2 Related Work
- 3 Preliminary
- 4 Proposed Model
-
- 4.1获得初始句子表示
- 4.2 细化句子表示
- 4.3 生成面向方面的表示
- 4.4 Model Training
- 5 Experiments
-
- 5.1 Datasets and Settings
- 5.2 Results and Analysis
- 5.3 Ablation Study(消融研究)
- 5.4 Case Study
- 5.5 Impacts of Layer Number
- 5.6 Analysis on Computational Cost
- 6 Conclusions
0 Abstract
方面级情感分类的最新方法利用了基于图的模型来整合句子的句法结构。(问题一)这些方法虽然有效,但忽略了语料库层面的词共现信息,反映了语言学中“nothing special”的搭配。此外,(问题二)它们没有区分不同类型的句法依赖,例如,名词性主语关系“food-was”在“food was okay”中被同等地当作形容词性补语关系“was-ok”。
为了解决上述两个限制,我们提出了一种新的架构,它在层次句法和词汇图上进行卷积。具体来说,我们使用一个全局词汇图来编码语料库级别的单词共现信息。此外,我们在句法和词汇图上建立了一个概念层次,用于区分各种类型的依赖关系或词汇词对。最后,我们设计了一个双层交互式图形卷积网络来充分利用这两个图形。在五个基准数据集上的大量实验表明,我们的方法达到了最先进的性能。
1 Introduction
方面层次的情感分类(ASC) (Hu and Liu, 2004)旨在确定句子中方面的情感极性(即积极、消极、中性)。以“great food but the service was dreadful”的评论为例。给定两个方面术语“food”和“service”,目标是推断方面术语的情感极性:food为positive,service为negative。ASC可以对用户对特定方面的意见进行细粒度的分析,并且这是许多NLP任务的基础。因此,近年来引起了广泛的研究关注。
关于ASC的早期研究(Mohammad et al., 2013; Jiang et al., 2011) 多采用机器学习算法构建情感分类器。后来针对这个任务提出了各种神经网络模型 (Dong et al., 2014; V oand Zhang, 2015; Chen et al., 2017),包括LSTM(Wang et al., 2016),CNN (Huang and Carley, 2018; Li et al., 2018),基于memory(Tang et al.,2016b)或者混合的方法(Xue and Li, 2018)。这些模型将句子表示为一个词序列,而忽略了词与词之间的句法关系,因此它们很难找到远离方面的观点词。 为了解决这个问题,近期几项研究 (Zhang et al., 2019; Huang and Carley, 2019; Sun et al., 2019)利用基于图的模型来结合句子的句法结构,并且已经显示出比不考虑句法关系的模型更好的性能。
尽管这些方法很有效,但基于句法的方法忽略了语料库层面的词汇共现信息。 此外,它们没有区分不同类型的句法依赖。我们认为两者都会导致信息损失。(1)频繁出现的共现词代表了语言学中的搭配。 例如在句子"food was okay, nothing special"中,词对"nothing special"在SemEval训练集中出现了五次,都表示负向情感。没有这样的全局信息来抵消“okay”的正极性,那么基于语法的方法会对“food”做出错误的预测。(2)每种类型的句法依赖都表示一种特定的关系。 例如,在"我喜欢汉堡包"中,"我喜欢"是一种nsubj关系,"喜欢汉堡包"是一种dobj关系。如果将这两种关系同等看待,我们无法区分“喜欢”这个动作的主语和宾语。
为了解决上述限制,我们提出了一种新颖的体系结构,它在层次句法和词汇图上进行卷积。我们首先使用一个全局词汇图来编码语料库级别的单词共现信息,其中节点是单词,边缘表示训练语料库中两个单词节点之间的频率。然后,我们在每个句法和词汇图上建立一个概念层次结构,以区分不同类型的依存关系或词共现关系。例如,acomp关系“was-nothing”和amod关系“nothing-special”组合成一种形容词关系类型,而nsubj关系“food-was”将形成另一种名词关系类型。举例来说,我们在图1中展示了一个样例句子,以及它的依存关系树,以及我们和其他工作中相应的词汇和句法图(Zhang et al., 2019; Huang and Carley, 2019; Sun et al., 2019)。

从图1 (b)中可以清楚地看出,现有的语法集成方法没有区分各种类型的依赖关系,因为边简单地表示两个节点之间存在关系。相比之下,我们的语法图(图1 c)中的每条边都附有一个标签,表示关系类型。此外,我们构建了一个词汇图(图1 d),它也有一个概念层次来捕捉各种单词的共现关系。最后,为了让句法图和词汇图相互协作,我们设计了一个双层交互式图形卷积网络来充分利用这两个图形。最后,为了让句法图和词汇图相互协作,我们设计了一个双层交互式图形卷积网络来充分利用这两个图。
我们在五个SemEval数据集上进行了广泛的实验。结果表明,我们的模型实现了最先进的性能。
2 Related Work
方面级情感分类的最新进展集中于构建各种类型的深度学习模型。我们在不考虑语法的情况下简要回顾了神经模型,然后转到基于语法的模型。
不考虑语法模型的神经模型可以主要分为几种类型:LSTM based, CNN based, memory based , and other hybrid methods 。例如, Zhang et al. (2016) 张等人(2016)使用门控神经网络结构来建模上下文和目标之间的相互作用。Li et al. (2018)使用CNN代替注意力来从变换的单词表示中提取重要特征。Xue and Li (2018) 结合CNN和门控结构从上下文中提取特定于方面的信息。
句法信息使得依赖信息能够被保存在长句中,并且有助于缩短方面和观点词之间的距离。长期以来,人们一直在研究将句法信息纳入文档级情感分类 (Matsumoto et al., 2005; Ng et al., 2006; Nakagawa et al., 2010)。后来, Dong et al. (2014); Nguyen and Shirai (2015); He et al. (2018); Salwa et al. (2018)也要考虑句子的语法结构和/或词性标签,以便进行基于方面的情感分析。但是,如果没有正确利用沿句法路径的依存关系,就不能充分利用句法结构的效果。
最近,若干研究 (Sun et al., 2019; Huang and Carley, 2019; Zhang et al., 2019)采用基于图的模型来整合句法结构。基本思想是将依存树转化为图,然后加入图卷积网络(GCN)或图注意网络(GA T) 将信息从句法邻域意见词传播到方面词。(Tay et al., 2018; Y ao et al.,2019)尝试在利用词共现信息进行情感分析。
与所有上述方法不同,我们的模型利用句法和词汇图来捕捉句子中的依存关系和训练语料库中的词共现关系。此外,我们为每个图构造概念层次,它可以将具有相似用途或意义的关系组合在一起,并减少噪声。正如我们将在实验中展示的那样,层次结构的引入极大地提高了性能。
3 Preliminary
问题定义(ASC) 给定一个评论句子 S = [ w 1 , w a + 1 , . . . , w a + m , w n ] S= [w_{1}, w_{a+1},...,w_{a+m},w_{n} ] S=[w1,wa+1,...,wa+m,wn],由n个字和从 ( a + 1 ) t h (a+1)^{th} (a+1)th 位置开始的相应m长度方面组成,方面级情感分类任务旨在识别句子中给定方面 ( s ) (s) (s)的情感极性。
层次句法图构造 句法图 ( S G ) (SG) (SG)有一个节点集 V s V_s Vs和一个边集 E s E_s Es。 V s V_s Vs中每一个节点 v v v都是句子中的一个词, E s E_s Es中两个单词之间的每个边 e e e表示它们是句法相关的。
ASC的现有语法集成方法(Sun et al., 2019; Huang and Carley, 2019; Zhang et al., 2019)没有利用各种类型的依存关系,并且如图1 (b)所示的它们的句法图中的边简单地表示两个单词之间存在依存关系。正如我们在引言中指出的,每个依存关系代表一个单词在句子中发挥的特定语法功能,应该以自己的方式使用。然而,由于在被解析的树中有大量的关系,直接使用一个依赖关系作为图中的一种边可能会引起像解析错误这样的噪声。
为了解决这个问题,为了解决这个问题,我们在依赖关系上增加了一个句法概念层次结构 R s R_s Rs。具体来说,我们将36种依存关系分为5种关系类型,包括“名词”、“动词”、“副词”、“形容词”和“其他”,表示为 s 1 . . s 5 s_1.. s_5 s1..s5分别为 R s R_s Rs。
特别是,由于大多数方面和意见词分别是名词和形容词,它们成为两种主要类型。动词不定式表示动作、事件或状态,副词修饰动词和形容词,因此它们也成为两种类型。剩下的是其他类型。
然后,我们基于句法概念层次结构构建一个层次句法图 H S G HSG HSG。具体来说, H S G HSG HSG被表示为 V s , E s , R s {V_s,E_s,R_s} Vs,Es,Rs,其中 V s V_s Vs, E s E_s Es和 R s R_s Rs分别是节点集,边集和句法关系类型集。请注意, E s E_s Es中的每条边现在都附有一个标签,表示 R s R_s Rs中的依赖关系类型。
分层词汇图构建 全局词汇图 L G T LG^T LGT有一个节点集 V T V^T VT和一个边集 E T E^T ET。 v t v_t vt中的每个节点 v v v代表一个单词, e t e_t et中的每个边 e e e代表词汇量为 n n n的训练语料中两个单词的共现频率。
然后,我们为每个句子构建一个局部词汇图 L G d LG^d LGd,其中每个节点代表句子中的一个单词,每个边代表两个单词在句子中共同出现。然而,在 L G T LG^T LGT,边缘与两个相同单词之间的边缘具有相同的权重。其基本原理是将 L G T LG^T LGT中的全局单词分布信息转移到本地词汇图 L G d LG^d LGd中。
词在语料库中的共现频率是高度偏斜的,大部分词对出现一两次,少数出现频率较大。显然,频繁出现的词与罕见出现的词应该区别对待。因此我们在词的共现关系上增加了一个词汇概念层次。为此,我们根据对数正态分布对词对的频率进行分组(Bhagat et al., 2018)。具体来说,我们用 d 1 d_1 d1和 d 2 d_2 d2表示频率为 2 0 2^0 20和 2 1 2^1 21的词对关系,而 d 3 , . . . , d 7 d^3,...,d^7 d3,...,d7表示频率在 [ 2 k + 1 , 2 k + 1 ] ( 1 ≤ k ≤ 5 ) [2^k + 1,2^k + 1](1≤ k≤5) [2k+1,2k+1](1≤k≤5)。最后一个 D 8 D_8 D8表示频率大于 2 6 2^6 26的所有词对的词汇关系。
最后我们可以基于词汇概念层次结构构建一个层次化的全局词汇图,表示为 { V d T , E d T , R d } \lbrace V_d^T, E_d^T, R_d \rbrace {VdT,EdT,Rd}, V d T , E d T , R d V_d^T, E_d^T, R_d VdT,EdT,Rd分别表示一个节点集,一个边集,词汇关系类型集。同样,我们有一个层次化的局部词汇图 H L G d = { V d d , E d d , R d } HLG^d =\lbrace V_d^d, E_d^d, R_d \rbrace HLGd={Vdd,Edd,Rd} ,其中 V d d V_d^d Vdd与 V s V_s Vs不相同。
4 Proposed Model
在这一节中,我们介绍我们提出的BiGCN模型。我们首先在图2中展示它的架构。从图2 (a)可以看出,BiGCN以全局词法图和单词序列作为输入,得到初始句子表示。然后,它引入了一个HiarAgg模块,在这个模块中,局部词法图和句法图相互作用以细化句子表示。最后,BiGCN通过Mask和门控机制获得面向方面的表示,以更好地预测句子中特定方面的情感极性。

4.1获得初始句子表示
设 E w ∈ R ∣ V o ∣ × d a E_w∈ R^{|V_o|×d_a} Ew∈R∣Vo∣×da为预训练的单词嵌入,其中 ∣ V o ∣ |V_o| ∣Vo∣为词汇量大小, d a d_a da为单词嵌入维数。 E w E_w Ew用于将具有n个单词的评论序列S映射到单词向量 [ e 1 , . . . , e a + 1 , . . . , e a + m , . . . , e n ] ∈ R n × d a [e_1,...,e_{a+1},...,e_{a+m},...,e_n]∈R^{n\times da} [e1,...,ea+1,...,ea+m,...,en]∈Rn×da。然后,我们提出了两种类型的文本表示来改进句子嵌入。一个是基于我们的全局词汇图的GCN嵌入。另一种是基于双向LSTM的Bi-LSTM嵌入。
GCN Embedding 首先,我们希望将语料库特有的词汇信息编码到评论表征中。为此,我们首先建立一个嵌入矩阵 E w t ∈ R N × d a E_{wt}∈ R^{N\times da} Ewt∈RN×da作为训练语料库的特征矩阵,其中N是训练语料库的词汇量。然后我们在层次化全局词法图 H L G T HLG^T HLGT上执行一个标准的GCN (Kipf and Welling, 2017),得到一个新的嵌入矩阵 E g c n ∈ R N × d x E_{gcn}∈ R^{N×dx} Egcn∈RN×dx。然后使用 E g c n E_{gcn} Egcn形成评论序列 S S S的 G C N GCN GCN嵌入,即 [ x 1 , . . . , x a + 1 , . . . , x a + m , . . . , x n ] ∈ R n × d x [x_1,...,x_{a+1},...,x_{a+m},...,x_n]∈ R^{n\times dx} [x1,...,xa+1,...,xa+m,...,xn]∈Rn×dx通过查找表,在图 2 ( a ) 2 (a) 2(a)中表示为 x x x。
Bi-LSTM Embedding 其次,我们遵循大多数以前的研究,将顺序信息编码到评论表示中 (Wang et al., 2016; Sun et al., 2019; Zhang et al., 2019)。此外,由于更接近方面可能在判断体的情感方面贡献更大 (Gu et al., 2018),我们计算每个上下文单词 w t w_t wt到相应体的绝对距离,并获得 s s s的位置序列。让 E p ∈ R n × d p E_p∈ R^{n×dp} Ep∈Rn×dp为随机初始化的位置嵌入查找表,位置查找层将位置序列映射为位置嵌入列表 [ p 1 , . . . , p a + 1 , . . . , p a + m , . . . , p n ] [p_1,...,p_{a+1},...,p_{a+m},..., p_n] [p1,...,pa+1,...,pa+m,...,pn]。
对于S中的每一个单词 w t w_t wt,它的嵌入计算为 e t p = e t ⊕ p t ∈ R d a + d p e_t^p = e_t ⊕ p_t ∈R^{da+dp} etp=et⊕pt∈Rda+dp, ⊕ ⊕ ⊕ 表示 串联, e t e_t et和 p t p_t pt表示预先训练的单词嵌入和单词在s中的 t t h t^{th} tth位置嵌入。具有上述表示的句子被发送到双LSTM层。由于空间限制,我们省略了细节。然后s被转换成一个BiLSTM嵌入 [ y 1 , . . . , y a + 1 , . . . , y a + m , . . . , y n ] ∈ R n × d y [y_1,...,y_{a+1},...,y_{a+m},...,y_n] ∈ R^{n×dy} [y1,...,ya+1,...,ya+m,...,yn]∈Rn×dy,在图 2 ( a ) 2 (a) 2(a)中表示为 y y y。
4.2 细化句子表示
以GCN嵌入 x x x和Bi-LSTM嵌入 y y y作为初始句子表示,我们进一步利用局部词汇图和句法图来获得更好的句子表示。基本思想是让这两个图形在精心设计的HierAgg模块中相互作用。简而言之,HierAgg是一个多层结构,其中每一层包括一个交叉网络来融合GCN和Bi-LSTM嵌入,以及一个双层次GCN来在层次句法和词汇图上进行卷积。多层结构确保了不同类型的信息在不同级别上的协作。本节给出了HierAgg中一层的细节,如图2 (b)所示。
交叉网络 为了深入融合GCN嵌入 x x x和Bi-LSTM嵌入 y y y,我们采用了交叉网络结构(Wang et al., 2017),该结构简单而有效。特别地,我们首先连接 x x x和 y y y以形成固定的组合 f 0 ∈ R d h , i . e . , f 0 = x ⊕ y f^0∈ R^{dh}, i.e., f^0= x ⊕ y f0∈Rdh,i.e.,f0=x⊕y。然后在交叉网络的每一层,我们用下面的公式更新融合后的嵌入。

其中l表示层数 ( l = 1 , 2 , . . . , ∣ L ∣ ) , w l , b l ∈ r d h (l=1,2,...,|L|), w^l,b^l∈r^{dh} (l=1,2,...,∣L∣),wl,bl∈rdh共享权重和偏差参数。然后将第 l l l层中的融合嵌入 f l f^l fl从原始串联位置分离为 x l x^l xl和 y l y^l yl,这将用作Bi-GCN中两个图的输入节点表示。
Bi-level GCN 由于我们的句法图和词法图包含概念层次结构,因此普通GCN无法在带有标记边的图上进行卷积。为了解决这个问题,我们提出了一个Bi-GCN来聚合不同的关系类型。给定一个带有两个图的句子,我们将使用两个聚合运算来执行双层卷积。
第一次聚合(低级):它将具有相同关系类型的节点聚合成一个虚拟节点,然后使用普通GCN (Kipf and Welling,2017) 中相同的归一化隐藏特征和作为聚合函数来获得虚拟节点的嵌入。因此,每个关系类型 r r r都有一个表示 h ~ t l , r \tilde{h}_t^{l,r} h~tl,r,其中l是层数,t是聚合的目标节点。例如,在图 1 ( c ) 1 (c) 1(c)中,“ok”和“nothing”具有相同的标签,因此聚合成目标节点“was”的虚拟节点“ s 4 s_4 s4”。类似地,“食物”本身被聚合成“was”的虚拟节点“ s 1 s_1 s1”。
第二次聚合(高级):它将所有虚拟节点及其特定关系聚集在一起。使用不同关系类型(虚拟节点)上的平均聚合函数来更新目标单词t的表示:
 ⊕ r ⊕_r ⊕r表示不同关系类型表示的连接, W l W_l Wl是第 l l l层中的权重矩阵。
⊕ r ⊕_r ⊕r表示不同关系类型表示的连接, W l W_l Wl是第 l l l层中的权重矩阵。
然后我们得到精炼的句子表示 x ′ l = [ h 1 l , d , . . . , h a + 1 l , d , . . . , h a + m l , d , . . . , h n l , d ] x^{'l} = [h_1^{l,d},...,h_{a+1}^{l,d},...,h_{a+m}^{l,d},...,h_n^{l,d}] x′l=[h1l,d,...,ha+1l,d,...,ha+ml,d,...,hnl,d] 和 y ′ l = [ h 1 l , s , . . . , h a + 1 l , s , . . . , h a + m l , s , . . . , h n l , s ] y^{'l} = [h_1^{l,s},...,h_{a+1}^{l,s},...,h_{a+m}^{l,s},...,h_n^{l,s}] y′l=[h1l,s,...,ha+1l,s,...,ha+ml,s,...,hnl,s]分别在词法图和句法图的第一次和第二次聚合之后,将作为下一层的输入。请注意,在HierAgg模块的最后一层,我们将 x ′ L x^{'L} x′L和 y ′ L y^{'L} y′L组合起来形成一个聚合嵌入 h L = x ′ L ⊕ y ′ L h^L = x^{'L} ⊕ y^{'L} hL=x′L⊕y′L。
4.3 生成面向方面的表示
为了更好地预测一个方面的情感极性,我们建议使用门控机制(Dauphin et al., 2017) 来控制情绪信息向给定方面的流动:
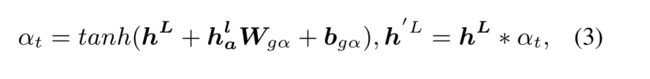
其中 H a l H_a^l Hal是 h L h^L hL的方面, W g α , b g α W_{g \alpha}, b_{g\alpha} Wgα,bgα分别是权重和偏差, ∗ \ast ∗是点积。然后我们在门控嵌入 h ′ L h^{'L} h′L中mask非方面的词并且保存方面词,随后我们获得zero-masked 嵌入 [ 0 , . . . , h a 1 l ′ , . . . , h a m l ′ , . . . , 0 ] ∈ R d h [0,...,h_{a_1}^{l'},...,h_{a_m}^{l'},...,0]∈R^{dh} [0,...,ha1l′,...,haml′,...,0]∈Rdh
最后,我们检索与方面词语义相关的重要特征,并为每个上下文词设置基于检索的注意权重 (Zhang et al.,2019) 。该句子的最终表示z被表述为:

这里 y t ∈ R d y y_t∈R^{dy} yt∈Rdy 是Bi_LSTM嵌入, h i l ′ ′ h_i^{l^{''}} hil′′ 是从zero-masked嵌入 h i l ′ h_i^{l^{'}} hil′中通过全连通层转化而来的,以保持与 y t y_t yt相同的维数。
4.4 Model Training
在获得面向方面的表示 z z z之后,我们将其输入到一个全连接的层和一个softmax层中,以将其投影到预测空间中:

这里u是预测的概率分布, W u W_u Wu和 b u b_u bu分别是权重矩阵和偏差。则最高概率的标签被设置为最终预测值 u ^ \hat{u} u^
通过最小化所有训练样本的交叉熵损失,用标准梯度下降算法训练模型:

这里 J J J是训练样本的数量, u i u_i ui和 u ^ i \hat{u}_i u^i分别是真实标签和预测标签, Θ \Theta Θ代表所有可训练参数, λ \lambda λ是L2正则化的系数
5 Experiments
5.1 Datasets and Settings
Datasets 我们在五个基准数据集上评估了我们提出的模型。(我们移除了极性冲突的样本和句子中没有明确方面的样本。五个数据集的统计数据如表1所示。)
- Twitter dataset by Dong et al. (2014)
- The other four datasets (Lap14,
Rest14, Rest15, Rest16) are all from SemEval tasks(包含笔记本电脑和餐厅的评论)

Settings 我们使用由Pennington et al. (2014)提供的300维GloVe向量初始化单词嵌入。常用的标准设置Huang and Carley (2019); Zhang et al. (2019); Sun et al. (2019)。此外,由于我们使用位置信息,因此我们使用与Sun et al. (2019)中相同的维度30来进行位置嵌入,以进行公平的比较。我们使用spaCy工具包来获取依赖关系。
我们使用Adam作为优化器,学习率为0.001。L2正则化系数 λ \lambda λ为 1 0 5 10^5 105,batch为32。此外,我们的BiGCN模块中的层数设置为2,我们稍后将检测其影响。实验结果是通过随机初始化平均三次运行获得的,其中Accuracy和 Macro-F1 用作评估度量。(实验代码https://github.com/NLPWM-WHU/BiGCN)
Baselines 我们将我们的模型与以下八个Baselines进行比较。
- ATAE-LSTM (Wang et al., 2016) 是一个经典的基于的模型,该模型以注意为基础探索句子的一个方面和内容之间的联系。
- GCAE(Xue and Li, 2018)是基于CNN的模型,具有两个卷积层,其输出由门控单元组合。
- MemNet (Tang et al., 2016b)是一种基于记忆的方法,将神经注意模型与外部记忆相结合,以计算每个上下文单词对一个方面的重要性。
- RAM(Chen et al., 2017) 使用注意层的多跳,并将输出与RNN结合用于句子表示。
- AF-LSTM(Tay et al., 2018)是一个方面融合LSTM模型,学习句子单词和方面之间的关联关系。
- TD-GAT(Huang and Carley, 2019) 提出了一个图注意力网络来明确利用词之间的依赖关系。
- ASGCN (Zhang et al., 2019)使用依赖树上的GCN来利用句法信息和单词依赖。
- CDT(Sun et al., 2019)使用GCN通过依存关系树来模拟句子结构。它还利用位置信息。
在baselines中,前四种方法是具有典型神经结构(如注意力)的经典模型, LSTM, CNN, memory, and RNN。中间一个(AF-LSTM)利用了这个词的共现信息。最下面的三种方法是基于图的方法和语法集成的方法。我们没有将TextGCN(Yao et al., 2019) 作为基线,因为它是为文本或文档级别的情感分类而开发的。
如果作者提供了源代码,我们会重新生成基线的结果。对于没有发布代码的三种方法(TD-GA T, AF-LSTM, and GCAE),我们使用他们论文中报告的最佳超参数设置自己实现它们。由于我们没有使用验证集,因此TD-GAT的结果高于Huang and Carley (2019)的结果。CDT(Sun et al.,2019) 的结果低于原始论文中的结果。CDT报告一定数量(100)轮次中的最佳结果。在我们的实验中,由于我们在随机初始化的情况下报告了三次运行的结果,所以当F1分数在一次运行中没有增加一定数量(5)轮时,我们停止训练。该停止标准用于所有方法,以进行公平比较。
5.2 Results and Analysis
所有方法的比较结果如表2所示。从这些结果中,我们得出以下观察。
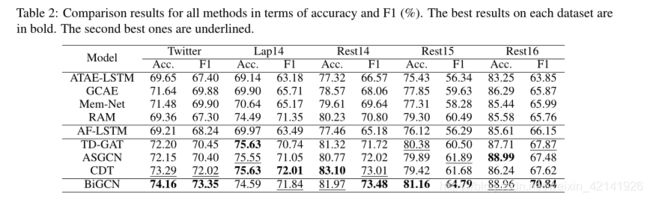
- 我们提出的BiGCN模型在所有数据集上取得了最好的macro-F1成绩。特别是,它的F1成绩比Rest16、Rest15和Twitter数据集上的第二好成绩分别提高了3.12、2.77和1.36,它的准确率也是名列前茅的,只比Lap14和Rest14上的基线差一点点,两者差别很小,分别为0.15和0.06。
- 基于图和语法的集成方法(TD-GA T, ASGCN, and CDT) 比不考虑语法的前五种方法好得多,表明依赖关系有利于识别情感极性。这与以前的研究是一致的 (Huang and Carley, 2019; Zhang et al., 2019; Sun et al., 2019)。但是,它们比我们提出的BiGCN模型更差。这证明了我们BiGCN中的词法图也有助于提高性能。
- AF-LSTM方法通过计算方面和上下文之间的循环相关性或循环卷积,然后将它们输入到关注层,来利用它们之间的单词共现。然而,它的性能并不总是比其他经典方法有所提高。这意味着通过关注层直接整合单词关联信息不足以利用词汇关系。
5.3 Ablation Study(消融研究)
为了检查BiGCN模型中每个组件的影响,我们进行了一项消融研究,结果如表3所示。
我们首先研究了层次词汇(M1)和句法图(M2)的影响。与完整的BiGCN相比,M1和M2的性能都有所下降,表明一个图不如两个交互图好。我们还发现M1和M2有竞争优势,表明他们在词汇和句法方面有自己的贡献。
然后,我们通过进一步从M1和M2中移除关系类型来展示概念层次的效果,从而产生基本的词汇(M3)和句法图(M4)。我们可以看到,这些没有概念层次的基本图形的结果都比它们的对应图形(M1-M3、M2-M4)差。这清楚地揭示了我们提出的概念层次结构的积极影响。

5.4 Case Study
为了更好地理解我们的BiGCN是如何工作的,我们给出了三个测试示例的案例研究。我们可视化这些例子的注意力分数、预测和真实标签。由于空间限制,我们仅在图3中显示 RAM, AF-LSTM, TD-GA T, ASGCN, CDT, and BiGCN ,其中RAM是表现最好的经典神经模型。AF-LSTM利用了词共现信息。TD-GAT,ASGCN, and CDT 是三种考虑语法信息的基于图的模型。

由于缺乏语法信息,RAM无法对所有三个示例做出正确的决定。出于同样的原因,AF-LSTM也在第一句中做出了错误的预测。从图3 (a)可以看出,RAM和AF-LSTM强调“friendly”。我们的模型和三种语法集成方法TD-GAT、ASGCN和CDT可以识别第一句中的虚拟词“should”,从而正确预测“staff”方面的负极性。
在第二句话中,虽然AF-LSTM计算了方面和它的上下文之间的关系,但是“food”和“okay”之间的短距离导致LSTM将最大的注意力得分分配给“okay”。另一方面,由于food”和“okay”在依存关系树中紧密相连,“okay”的强正极性损害了TD-GAT,ASGCN和CDT的决策。相比之下,在全局词汇信息的帮助下,我们的BiGCN模型聚焦于“nothing specia”,正确预测了“food”的中性极性。
在第三句中,解析器的输出将“no”和“cooling pad”连接在一起。但也把“great” 和“pad”联系起来,把“needed” 和“feature”联系起来,导致了对TD-GAT、ASGCN、CDT的错误预测。我们注意到AF-LSTM可以正确预测极性。这是因为AF-LSTM在训练语料库中八次利用了“no”和“needed”之间的单词关联。同样,借助这样的词汇信息,我们的BiGCN模型也在“no”和“needed”上突出显示,将中性极性赋给“cooling pad”。注意这句话有两个方面:fan 和cooling pad。由于几乎所有的模型都能对fan做出正确的预测,所以我们只对cooling pad进行详细的分析。
5.5 Impacts of Layer Number
我们模型的关键贡献之一是句法图和词汇图可以相互作用。HierAgg模块中的层数表示两个图形之间的交互次数。在本节中,我们通过在 [ 1 , 2 , 3 , 4 , 6 , 8 , 10 ] [1,2,3,4,6,8,10] [1,2,3,4,6,8,10]中改变层数来检查层数 l l l的影响。结果如图4所示。

可以看出,我们的模型用2层或3层达到了最好的效果。如果只使用1层,两个图形之间的交互不足以产生好的结果。然而,性能并不总是随着层数的增加而提高。这是因为大的 l l l值使得模型很难训练。此外,l越大,引入的参数越多,导致模型的通用性越差。
5.6 Analysis on Computational Cost
在本节中,我们将三次运行BiGCN模型的平均训练时间与三个典型baselines的平均训练时间进行了比较,这三个baselines都是基于图的。结果如表4所示。
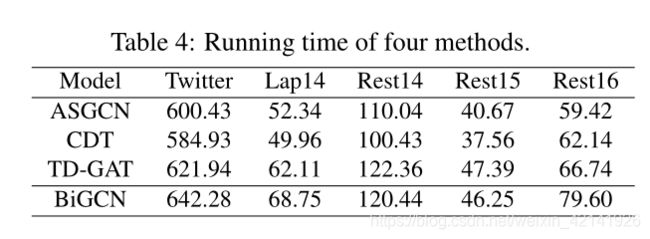
可以看出我们的模型即使使用两种类型的图,但是训练时间改变不是很大。例如,在Rest14和Rest15上,我们提出的BiGCN的计算成本小于TD-GAT,即使在最大的Twitter数据集上,我们提出的BiGCN的时间成本增加与最高效的CDT方法的比例也小于10%。
6 Conclusions
在这篇文章中,我们提出了一个新的框架BiGCN来利用基于图的方法进行方面级情感分类任务。除了普通的句法图,我们还使用词汇图来获取训练语料库中的全局词共现信息。此外,我们在每个词汇图和句法图上建立一个概念层次结构,这样图中不同功能类型的关系可以分别处理。最后,我们设计了一个HierAgg模块,让词法图和语法图以协作的方式工作。我们在五个真实数据集上进行了一系列实验。结果证明,我们的模型实现了最先进的性能。