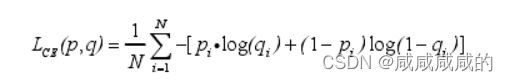基于强化空间注意力的视网膜网络(ESA-Unet)
文章里提到现有的注意力机制并没有关注到大的感受野,大的感受野在肺结节分类,超分辨率和遥感图像等任务中都体现了重要性,为了探索这个问题,本文设计了一个端到端的基于强化空间注意力视网膜血管分割网络,引入了一个新的注意力模块,其名称为强化空间注意力模块(ESA),相比较于空间注意力模块(SA),ESA能获得更大的感受野,更好的根据空间上下文内容自适应的重新分配特征,加入ESA模块可以让网络模型学习更多关于视网膜的上下文信息。
整体模型
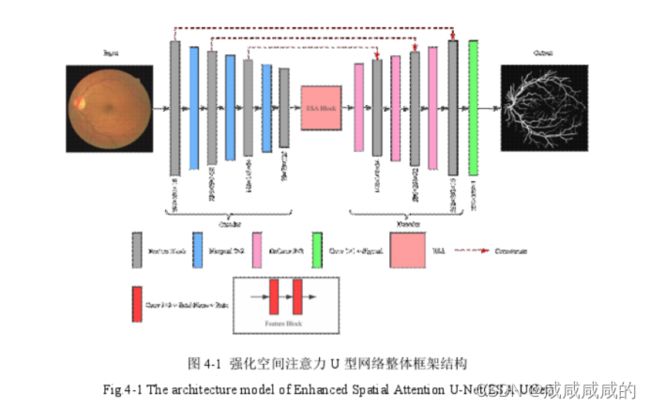
如图4-1所示,ESA-UNet网络采用U形结构,主要包括三个部分:编码器,
解码器和本章节提出的强化空间注意力模块(ESA Block)。首先,编码器提取输入
的眼底图像的特征,经过三个编码模块((Feature Block),每个编码模块都是经典的
卷积神经网络(CNN)网络格式,由两组卷积层、批归一化(BN)和Relu激活函数组
成,将特征图的通道数变为原来通道数的两倍(初始通道设置为16),增加通道数是
为了保证网络能够有效的学习高级复杂的图像特征,然后再通过一个窗口大小为
2X2的最大池化层将特征图尺寸大小变为原来的一半,其中卷积层步长为1,池化
层步长为2。其次,将编码器提取的图像特征输入强化空间注意力模块,得到具有
更加强大区域相关性的注意力特征图(attention feature map)。此外,注意力特征图
经过三个解码模块,每个解码器模块先使用一个转置卷积层(也叫反卷积,
DeConvolution)将输入特征图的尺寸变为原来的两倍,随后与之对应的编码模块提
取的特征拼接(Concatenate)在一起,然后再通过两组卷积层、批归一化和Relu激
活函数得到解码模块的输出。最后通过一层sigmoid激活函数输出与原图像大小相
同的视网膜血分割图。
强化空间注意力模块

第一步,通过一个卷积核大小为1x1的卷积层压缩通道数量(减少到原来通道
数的四分之一,即通道数为32),整个强化注意力模块可以变的非常轻量化。
第二步,为了扩大感受野,本文先使用了一个步长为2卷积层将特征图的大
小减少至原来的二分之一。
第三步,本文选择使用更大的7x7窗口和步长为3的最大池化层,在图像分
类和检测任务中,步长为2的卷积和最大池化的可以在网络前端快速降低空间维
数。然而,如图4-2(a)所示,原始的SA模块的最大池化层2x2窗口所带来的感受
野仍然非常有限,所以本文选择可以获得更大感受野的最大池化层。
第四步,本文使用卷积核大小为3x3的卷积层来学习特征图空间维度之间的
相关性。
第五步,本文使用双线性插值将特征图恢复到第一步输入特征图的尺寸大小。
第六步,将第一步获取的低通道的特征图通过一个1x1的卷积之后与第六步
获得的特征拼接起来。
第七步,本文使用一个卷积核大小为1x1的卷积层将特征图的通道数恢复为原始的通道数(channel=128) o
最后一步,通过sigmoid激活函数生成注意力掩模(mask)与输入进行点积运算
操作,生成具有较长距离依赖关系的特征图。
损失函数:
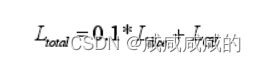
 中|A|和|B|代表血管像素和非血管像素个数,
中|A|和|B|代表血管像素和非血管像素个数,![]() 代表A和B之间的交集,
代表A和B之间的交集,