【论文笔记】HRFormer: High-Resolution Transformer for Dense Prediction
论文

论文题目:HRFormer: High-Resolution Transformer for Dense Prediction
收录于:NeurIPS 2021
论文地址:https://arxiv.org/abs/2110.09408
项目地址:https://github.com/HRNet/HRFormer
导言
在本文中,作者提出了一种高分辨率 Transformer(High-Resolution Transformer ,HRT),用于学习密集预测任务的高分辨率表示,而原始的视觉Transformer 只能处理低分辨率表示,并且具有较高的显存和计算成本。
HRT利用了高分辨率卷积网络(HRNet)中引入的多分辨率并行设计,并且在非重叠的局部窗口上执行自注意,提高了显存和计算效率。此外,作者在FFN中引入卷积,以便在没有连接的图像窗口之间交换信息。
通过实验,作者证明了高分辨率Transformer 在人体姿势估计和语义分割任务上的有效性,例如,HRT在COCO姿势估计上比Swin Transformer高1.3AP,参数减少50%,FLOPs减少了30%。
动机
Vision Transformer(ViT)在ImageNet分类任务中表现出了良好的性能。许多后续工作通过知识蒸馏,采用更深层次的结构,直接引入卷积运算或者重新设计输入图像token等方法来提高分类精度。此外,一些研究试图扩展Transformer以解决更广泛的视觉任务,如目标检测、语义分割、姿势估计、视频理解等。本文的重点是构建用于密集预测任务的Transformer,包括姿势估计和语义分割。
Vision Transformer将图像分割为大小为16×16的图像块序列,并提取每个图像块的特征表示。因此,Vision Transformer的输出表示失去了密集预测所必需的细粒度空间细节。Vision Transformer仅输出单尺度特征表示,因此缺乏处理多尺度变化的能力。为了减少特征粒度的损失并对多尺度变化进行建模,作者提出了包含更丰富空间信息的高分辨率Transformer(HRT),并为密集预测构造多分辨率表示。
高分辨率Transformer采用HRNet中采用的多分辨率并行设计。
- 首先,HRT在stem层和第一阶段都采用卷积,因为一些研究也表明卷积在早期阶段表现更好。
- 第二,HRT在整个过程中保持一个高分辨率流,而并行的中、低分辨率分支有助于提高高分辨率的表示。由于具有不同分辨率的特征图,因此HRT能够模拟多尺度变化。
- 第三,HRT通过与多尺度融合模块来交换多分辨率特征信息,实现了混合了近距离和远距离的Attention。
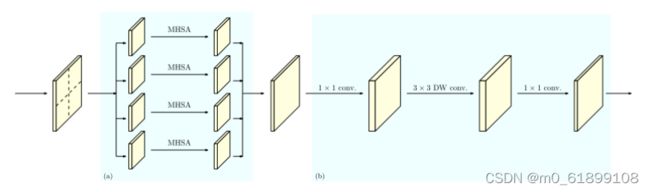
作者将特征映射划分为一组不重叠局部窗口,并在每个图像窗口中分别进行自注意。这就减少了显存,并将计算复杂性从与空间大小的二次关系降低到线性关系。作者进一步将3×3深度卷积引入到跟随局部窗口自注意的前馈网络(FFN)中,使得自注意过程中断开的图像窗口之间能够交换信息。这有助于扩大感受野,对于密集的预测任务至关重要。上图展示了HRT中Transformer块的详细结构。
方法
2.1. Multi-resolution parallel transformer
作者遵循了HRNet的设计,从一个高分辨率卷积stem层开始作为第一阶段,逐步将高分辨率到低分辨率的流逐个添加为新阶段,多分辨率流并行连接。主体结构由一系列阶段组成,在每个阶段中,每个分辨率流的特征表示分别使用多个Transformer块进行更新,并且跨分辨率的信息通过卷积多尺度融合模块进行交换。
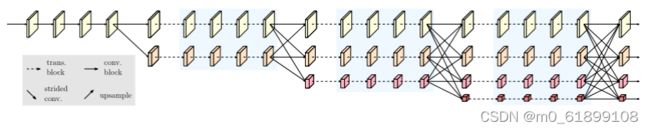
上图展示了整个HRT的结构。卷积多尺度融合模块的设计与HRNet(Deep High-Resolution Representation Learning for Human Pose Estimationhttps://arxiv.org/abs/1902.09212)相同。
Repeated multi-scale fusion(来源HRNet)
摘于HRNet论文笔记_xiaolouhan的博客-CSDN博客_hrnet论文
我们跨并行子网引入交换单元exchange units,使每个子网重复接收来自其他并行子网的信息。下面是一个展示信息交换方案的示例。我们将第三阶段{N31; N32; N33}划分为若干(3)个交换块,每个块由三个并行卷积单元组成,并在其后与一个交换单元跨并行单元进行卷积,得到:(N3:的3交换块结构)
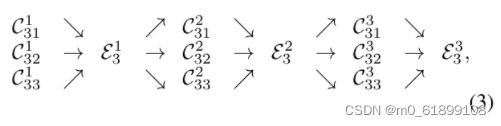
其中C^b_sr表示s阶段并行子网中第b个交换块r分辨率的卷积单元,E^b_s表示相应的交换单元;
我们将在图3中说明交换单元,并在下文中给出公式。为了便于讨论,我们去掉下标s和上标b。
输入为s个响应图:{X_1 , X_2 , . . . , X_s },输出为s个响应图:{Y_1 , Y_2 , . . . , Y_s } ,其分辨率和宽度与输入相同。每个输出都是输入映射的集合Yk=sum(a(Xi, k), i=1:s)。跨阶段的交换单元有额外的输出图Ys+1=a(Ys, s+1)。
函数a(X_i, k)从分辨率i到k对上采样或下采样组成。我们采用有跨步的3×3卷积做下采样。例如,用单个有跨步的3×3卷积使用2步长做2x下采样。两个连续的有跨步3×3的卷积使用2步长做4倍下采样。对于上采样,我们采用最简单的最近邻抽样,在调整通道的数量的1×1卷积之后。如果i = k,则a(.,.)只是一个恒等连接:a(Xi, k)=Xi。

2.2 Local-window self-attention


然后作者聚合了每个窗口的特征,如下所示:
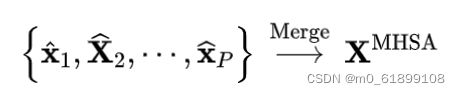

上图的左半部分说明了局部窗口的自注意是如何更新2D输入表示的,其中多头自注意在每个窗口内独立运行。
2.3 FFN with depth-wise convolution
局部窗口的自注意在非重叠窗口上分别执行自注意,而没有跨窗口的信息交换。为了解决这个问题,作者在视觉Transformer中FFN的两个MLP之间添加了3×3深度卷积: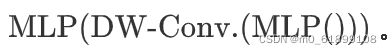 。上图的右部分显示了FFN如何使用3×3深度卷积更新2D输入表示。
。上图的右部分显示了FFN如何使用3×3深度卷积更新2D输入表示。
2.4 Representation head designs
HRT的输出由四个不同分辨率的特征图组成。不同任务的表示头设计如下所示:
-
在ImageNet分类中,作者将四分辨率特征映射送到bottleneck中,输出通道分别更改为128,256,512和1024。然后,作者用卷积对它们进行融合,并输出2048个通道的最低分辨率特征图。最后,用一个全局平均池化操作,然后是最终的分类器。
-
在姿势估计中,作者只在最高分辨率的特征图上应用回归头。
-
在语义分割中,作者将语义分割头应用于concat之后的特征表示(首先将所有低分辨率表示向上采样到最高分辨率,然后将它们concat在一起)。
2.5 实例化
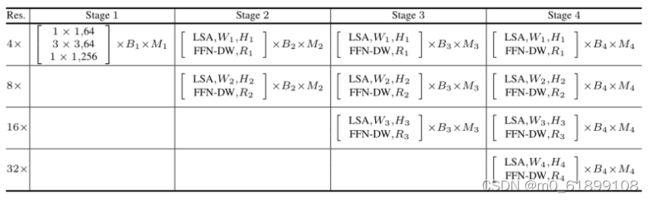
上表中展示了HRT的总体结构。使用(M1,M2,M3,M4)和(B1,B2,B3,B4)分别表示{state1,stage2,stage3,stage4}的module数和block数;使用(C1、C2、C3、C4)、(H1、H2、H3、H4)和(R1、R2、R3、R4)表示与不同分辨率相关的Transformer块中的通道数、头数和MLP扩展比。
第一阶段和HRNet的模块相同,在其他阶段应用Transformer块,每个Transformer块由一个局部窗口自注意和一个具有3×3深度卷积的FFN组成。

在实现中,默认情况下,四个分辨率流上的窗口大小设置为(7,7,7)。上表说明了三种不同HRT实例的配置细节,这些实例的复杂性不断增加,其中MLP扩展比(R1、R2、R3、R4)在所有模型中均设置为(4,4,4,4)。
2.6 分析
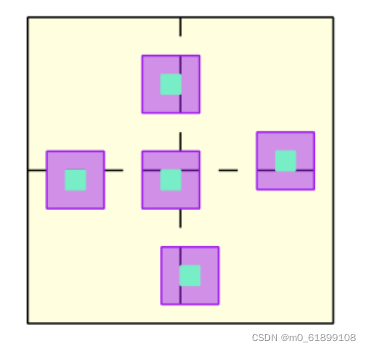
3×3深度卷积的好处有两个:一个是增强局部性,另一个是支持跨窗口的交互。如上图所示,具有深度卷积的FFN能够充分建模非重叠的局部窗口。因此,基于局部窗口自注意和具有3×3深度卷积的FFN的组合,作者构建了HRT的Transformer块,从而显著提高显存和计算的效率。
实验
3.1 Human Pose Estimation
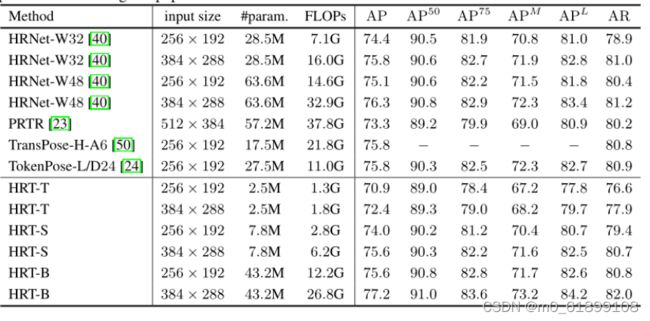
上表展示了 COCO val set上人体姿态估计任务的实验结果。
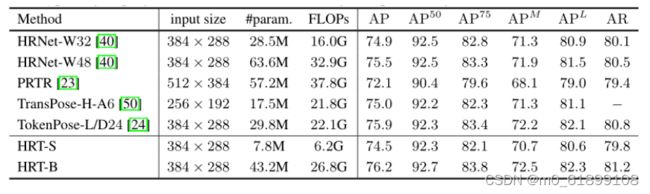
上表展示了 COCO test-dev set上人体姿态估计任务的实验结果。

上图展示了COCO上人体姿态估计的一些定性实验结果。
3.2 Semantic Segmentation

上表展示了不同数据集上,本文方法和其他方法进行语义分割的实验结果。

上图展示了不同数据集上,本文方法进行语义分割的定性实验结果。
3.3 ImageNet Classification
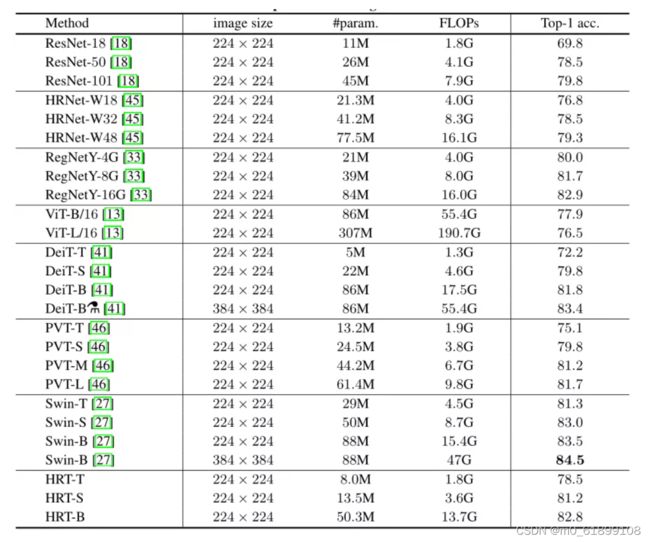
上表展示了分类任务上,本文方法的实验结果。
3.4 Ablation Experiments
Influence of 3×3depth-wise convolution within FFN

上表展示了FFN中3x3卷积的必要性。
Influence of shifted window scheme & 3×3 depth-wise convolution within FFN based on Swin-T

上表展示了Swin Transformer中,FFN中3x3卷积的必要性。
Comparison to ViT, DeiT & Swin on pose estimation

上表展示了其他Transformer网络在姿态估计上的实验结果。
Comparison to HRNet
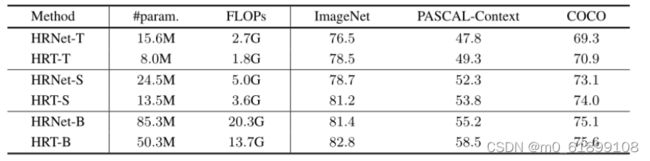
上表展示了HRNet和HRT的实验结果对比,可以看出HRT的性能比HRNet还要好。
总结
在本文中,作者提出了高分辨率Transformer(HRT),这是一种简单但有效的Transformer架构,用于密集的预测任务,包括姿势估计和语义分割。该网络设计的关键是HRT transformer块,它将局部窗口自注意和带深度卷积的FFN相结合,以提高显存和计算效率。此外,HRT的优异性能还得益于在早期阶段采用卷积,并将短程和远程注意力与多尺度融合的方案相结合。
转载
NeurIPS2021 HRFormer:HRNet又出续作啦!国科大&北大&MSRA提出高分辨率Transformer,开源!
推荐
知乎/公众号:FightingCV
ICCV、CVPR、NeurIPS、ICML论文解析汇总:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading
面向小白的Attention、重参数、MLP、卷积核心代码学习:https://github.com/xmu-xiaoma666/External-Attention-pytorch