SiamFC代码讲解,训练过程讲解
siamfc论文:Fully-Convolutional Siamese Networks for Object Tracking
gitHub代码:https://github.com/huanglianghua/siamfc-pytorch
论文模型架构:
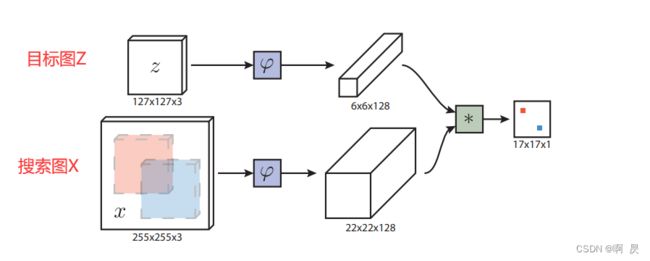
上一篇文章:SiamFC代码讲解,推理测试讲解
此篇是: 训练过程代码讲解
###训练大致流程:
|—train.py
|——GOT10K类
|——TranckerSiamFC类
|——train_over函数
|———预处理(transformer)
|———自定义dataset(Pair)
|———构造dataloader
|———loss=train_step
|————获取z,x图像;通过siamfc获得响应图response
|————获取label并与response计算loss;反向传播
|———输出loss结果
|———模型结果保存
(需要有个映像,siamfc中不会用到groundtruth来计算loss,而是固定生成label,与response进行loss计算。因为每次裁剪的图片,物体就在图片中间)
代码流程
train.py:
看到GOT10K类(train.py–Line11)
crtl+左键点进去,进入到got10k.py中
代码详解(注释)
过程简述:
- 继承Object类
- 保存训练要用的img和annotation的路径
返回train.py
看到trackerSiamFC类(train.py --Line13)
crtl+左键点进去,进入到siamfc.py中
(PS:这里和推理过程是一样的)
TrackerSiamFC类中init函数:
代码详解(注释)
过程简述:
- 超参初始化
- 创建siamfc架构;
- 模型加载;
- 定义损失函数;
- SGD优化器;
- 获得指数衰减学习率因子函数:ExponentialLR
返回train.py
看到train_over函数
进入到siamfc.py中
siamfc.py下train_over函数:
代码详解(注释)
过程简述:
|—1. 预处理(transformer)
|—2. 自定义dataset类(Pair)
|—3. 创建dataloader
|—4. 遍历epoch
|——4.1 lr变化
|——4.2 遍历batch
|———4.2.1 loss=训练(图像)
|———4.2.2 输出训练时信息
|——4.3 保存模型
以下是最主要代码
loss = self.train_step(batch, backward=True)
进入train_step函数中
siamfc.py下train_step函数:
代码详解(注释)
过程简述:
- 获取z,x图像
- 获得响应图response
- 获取label并与response计算loss
- 反向传播
- 返回loss
————————————————————————————————————
代码解析
GOT10K类
class GOT10k(object):
def __init__(self, root_dir, subset='test', return_meta=False):
super(GOT10k, self).__init__()
assert subset in ['train', 'val', 'test'], 'Unknown subset.'
self.root_dir = root_dir
self.subset = subset
self.return_meta = False if subset == 'test' else return_meta
self._check_integrity(root_dir, subset)
list_file = os.path.join(root_dir, subset, 'list.txt')
with open(list_file, 'r') as f:
self.seq_names = f.read().strip().split('\n')
self.seq_dirs = [os.path.join(root_dir, subset, s)
for s in self.seq_names]
## e.g. root_dir / train / GOT-10k_train_000001
self.anno_files = [os.path.join(d, 'groundtruth.txt')
for d in self.seq_dirs]
## e.g. root_dir / train / GOT-10k_train_000001/groundtruth.txt
TrackerSiamFC类init函数
与推理,测试的对应代码一致
siamfc.py下train_over函数
额外补充:
图像预处理(transformer)
自定义dataset(Pair)
def train_over(self, seqs, val_seqs=None,
save_dir='pretrained'):
# set to train mode
self.net.train()
# create save_dir folder
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# setup dataset
transforms = SiamFCTransforms( ##预处理
exemplar_sz=self.cfg.exemplar_sz, ##127
instance_sz=self.cfg.instance_sz, ##255
context=self.cfg.context)
dataset = Pair( ##数据集,,Pair类继承dataset类
seqs=seqs,
transforms=transforms)
##SiamFC的输入是pair ,其中 frame_i,frame_j来自同一视频的两帧,间隔不超过T帧,大小: W,H,3
# setup dataloader
dataloader = DataLoader( ##数据集
dataset,
batch_size=self.cfg.batch_size,
shuffle=True,
num_workers=self.cfg.num_workers,
pin_memory=self.cuda,
drop_last=True)
# loop over epochs
for epoch in range(self.cfg.epoch_num):
# update lr at each epoch
self.lr_scheduler.step(epoch=epoch) ##每一个批次进行lr递减
##BalancedLoss()损失函数,具体递减公式为 lr= lr*gamma**epoch
# loop over dataloader
for it, batch in enumerate(dataloader):
##batch 即 datasets.py中Pair类下get_item函数的返回值
##batch[0] 为预处理后的z图片
##batch[1] 为预处理后的x图片
loss = self.train_step(batch, backward=True) ##关键代码
print('Epoch: {} [{}/{}] Loss: {:.5f}'.format(
epoch + 1, it + 1, len(dataloader), loss))
sys.stdout.flush()
# save checkpoint
if not os.path.exists(save_dir):
os.makedirs(save_dir)
net_path = os.path.join(
save_dir, 'siamfc_alexnet_e%d.pth' % (epoch + 1))
torch.save(self.net.state_dict(), net_path)
siamfc.py下train_step函数
额外补充:创建标签(create_labels)
loss的详细计算(BalancedLoss类)
def train_step(self, batch, backward=True):
# set network mode
self.net.train(backward)
##SiamFC的输入是pair ,其中 frame_i,frame_j来自同一视频的两帧,间隔不超过T帧,大小: W,H,3
# parse batch data
z = batch[0].to(self.device, non_blocking=self.cuda)
##Z.shape (B,C,127,127)
x = batch[1].to(self.device, non_blocking=self.cuda)
##X.shape (B,C,239,239)
with torch.set_grad_enabled(backward):
# inference
responses = self.net(z, x) ##响应图
"""
response.shape==(B,1,15,15),注意这里与论文中有点出入
原因是::论文中,z.shape==B,C,127,127 得到的feature_z==B,128,6,6
x.shape==B,C,255,255 最后得到的feature_x.shape==B,128,22,22
而训练时的预处理后,x.shape==B,C,239,239 ,最后得到的feature_x.shape==B,128,20,20
因此在代码中,得到response.shape==(B,1,15,15)
"""
# calculate loss
labels = self._create_labels(responses.size())
loss = self.criterion(responses, labels) ##BalancedLoss类 在siamfc.py的初始化中提到
if backward:
# back propagation
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
return loss.item()
————————————————————————————————————
额外补充:
transformer.py下SiamFCTransformer类
class SiamFCTransforms(object):
def __init__(self, exemplar_sz=127, instance_sz=255, context=0.5):
self.exemplar_sz = exemplar_sz
self.instance_sz = instance_sz
self.context = context
self.transforms_z = Compose([
RandomStretch(),
CenterCrop(instance_sz - 8),
RandomCrop(instance_sz - 2 * 8),
CenterCrop(exemplar_sz),###127
ToTensor()])
##目标图 会进行:随机拉伸;中心裁剪;随即裁剪;中心裁剪
##最后的shape应该是 B,C, 127,127
self.transforms_x = Compose([
RandomStretch(),
CenterCrop(instance_sz - 8),
RandomCrop(instance_sz - 2 * 8), ###255-2*8==239
ToTensor()])
##搜索图会进行:随机拉伸;中心裁剪;随即裁剪;
##最后的shape应该是 B,C,239,239
def __call__(self, z, x, box_z, box_x):
## e.g. box_x = anno[rand_x] 为groundtruth的框大小
z = self._crop(z, box_z, self.instance_sz)##统一resize到255大小
x = self._crop(x, box_x, self.instance_sz)
##进行transformer
z = self.transforms_z(z)
x = self.transforms_x(x)
return z, x
datasets.py下Pair类
class Pair(Dataset):
def __getitem__(self, index): ##会在dataloader中调用这个函数
index = self.indices[index % len(self.indices)]
##随机的打乱图片的索引顺序
# get filename lists and annotations
if self.return_meta:
img_files, anno, meta = self.seqs[index]
vis_ratios = meta.get('cover', None)
else:
img_files, anno = self.seqs[index][:2]
vis_ratios = None
# filter out noisy frames
val_indices = self._filter(
cv2.imread(img_files[0], cv2.IMREAD_COLOR),
anno, vis_ratios)
if len(val_indices) < 2:
index = np.random.choice(len(self))
return self.__getitem__(index)
# sample a frame pair
rand_z, rand_x = self._sample_pair(val_indices)
##随机z下标和x下标
z = cv2.imread(img_files[rand_z], cv2.IMREAD_COLOR)
x = cv2.imread(img_files[rand_x], cv2.IMREAD_COLOR)
z = cv2.cvtColor(z, cv2.COLOR_BGR2RGB)
x = cv2.cvtColor(x, cv2.COLOR_BGR2RGB)
box_z = anno[rand_z]
box_x = anno[rand_x]
item = (z, x, box_z, box_x)
if self.transforms is not None:
item = self.transforms(*item)
##对应transformer.py下SiamFCTransformer类的call函数
##len(item) ==2 item[0]为预处理后的z图像,shape==B,C,127,127
return item
siamfc.py下train_step中create_labels函数
额外补充:meshgrid函数
def _create_labels(self, size):
# skip if same sized labels already created
if hasattr(self, 'labels') and self.labels.size() == size:
return self.labels
def logistic_labels(x, y, r_pos, r_neg):
dist = np.abs(x) + np.abs(y) # block distance
labels = np.where(dist <= r_pos, ##不等式1
np.ones_like(x), ##如果满足不等式1则是这个值
np.where(dist < r_neg, ##如果不满足等式 1 则是这个值 ;; 嵌套进行不等式2
np.ones_like(x) * 0.5, ####如果满足不等式2则是这个值
np.zeros_like(x))) ##如果不满足等式 2 则是这个值
## 即:距离<=r_pos(=2) 则是1 , 否则则是 0
return labels
# distances along x- and y-axis
n, c, h, w = size ##batch ,1, 15, 15
x = np.arange(w) - (w - 1) / 2 ## -w/2 ,-w/2+1 ...0, 1,2, ...w/2
y = np.arange(h) - (h - 1) / 2 ## -h/2 ,-h/2+1 ...0, 1,2, ...h/2
x, y = np.meshgrid(x, y)
# create logistic labels
r_pos = self.cfg.r_pos / self.cfg.total_stride
## sekf.cfg.r_pos ==16;;self.cfg.total_stride=8 --->r_pos=16/8==2
r_neg = self.cfg.r_neg / self.cfg.total_stride
## sekf.cfg.r_neg ==0 --->r_neg=0/8==0
labels = logistic_labels(x, y, r_pos, r_neg)
##Labels: 中心区域的 像素为1 ,其余为0 ;; 因为在裁剪的时候会尽量让物体在中心区域
# repeat to size
labels = labels.reshape((1, 1, h, w))
labels = np.tile(labels, (n, c, 1, 1)) ##以复制方式,堆叠
##label.shape: 1,1,15,15--->8,1,15,15 堆叠,便于运算
# convert to tensors
self.labels = torch.from_numpy(labels).to(self.device).float()
return self.labels
其中,label结果应该是
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 1. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 1. 1. 1. 1. 1. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 1. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
meshgrid函数
import numpy as np
x= np.array([1,2,3,4,5,6])
y= np.array([-7,-8,-9])
x,y=np.meshgrid(x,y)
print(x)
print(y)
>>>
x: [[1 2 3 4 5 6]
[1 2 3 4 5 6]
[1 2 3 4 5 6]]
y:[[-7 -7 -7 -7 -7 -7]
[-8 -8 -8 -8 -8 -8]
[-9 -9 -9 -9 -9 -9]]
欢迎指正
因为本文主要是本人用来做的笔记,顺便进行知识巩固。如果本文对你有所帮助,那么本博客的目的就已经超额完成了。
本人英语水平、阅读论文能力、读写代码能力较为有限。有错误,恳请大佬指正,感谢。
欢迎交流
邮箱:[email protected]