ssd.pytorch指南(三)——训练模型
本章节既是指南如何训练测试模型,同时也是检验上一章所提的平台搭建是否成功。
目录
- ssd.pytorch指南(一)——序言
- ssd.pytorch指南(二)——平台搭建
- ssd.pytorch指南(三)——训练模型
- ssd.pytorch指南(四)——制作PASCAL VOC2007数据集
- ssd.pytorch指南(五)——训练自己的数据集
一、下载预训练模型
1、在ssd_pytorch文件夹下新建weights文件夹
cd ..
mkdir weights
cd weights
2、下载预训练模型
wget https://s3.amazonaws.com/amdegroot-models/vgg16_reducedfc.pth
上面这个官方的下载指令下载速度巨慢,我用了整整一个半小时才下载下来,嫌慢的小伙伴可以用下面的链接下载。
CSDN链接:https://download.csdn.net/download/qq_34374211/10712378
网盘链接:https://pan.baidu.com/s/1WzKPph3Xf0K6G3Tqc_o0fQ
提取码:gvh6
二、修改multibox_loss.py代码
原本的train.py直接运行会报错,所以需要进行修改。
0、可能出现的问题(我遇到的)
RuntimeError: The shape of the mask [2, 8732] at index 0 does not match the shape of the indexed tensor [17464, 1] at index 0
RuntimeError: Expected object of type torch.cuda.FloatTensor but found type torch.cuda.LongTensor for argument #3 'other’
(更多错误与解决方法,参考:ssd.pytorch源码迁移实现(pytorch版本从0.2迁移到0.4(1.0)))
为解决上述两个问题,需依次对ssd_pytorch/layers/modules/multibox_loss.py进行修改
1、找到代码的第97行

交换两行代码的顺序就可以解决第一个error

2、找到代码的最后一部分
原本是
N = num_pos.data.sum()
loss_l /= N
loss_c /= N
return loss_l, loss_c
中间加上一句,改为
N = num_pos.data.sum()
N=N.type(torch.cuda.FloatTensor)
loss_l /= N
loss_c /= N
return loss_l, loss_c
就可以解决第二个error
三、修改迭代次数
本章节主要是为了指导如何搭建平台,代码能否成功运行为判断依据,因此需要降低训练用时。
打开ssd_pytorch/data/config.py找到第17行,将迭代次数(max_iter)从120000改为200(建议迭代次数不要太小,太小会查不出Stoplteration异常我用的是batch_size=32,max_iter=200的组合)。
# SSD300 CONFIGS
voc = {
'num_classes': 21,
'lr_steps': (80000, 100000, 120000),
'max_iter': 120000, #迭代次数
'feature_maps': [38, 19, 10, 5, 3, 1],
'min_dim': 300,
'steps': [8, 16, 32, 64, 100, 300],
'min_sizes': [30, 60, 111, 162, 213, 264],
'max_sizes': [60, 111, 162, 213, 264, 315],
'aspect_ratios': [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
'variance': [0.1, 0.2],
'clip': True,
'name': 'VOC',
}
四、修改train.py代码
这一步骤,按照个人情况自行选择是否操作。
1、指定GPU
在train.py代码头部加一行指令(注:加在import os之后),“1”代表选择了1号GPU
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
2、修改batch_size
官方默认的batch_size为32,如果GPU空间不够可以调小,在train.py代码的第32行进行修改
parser.add_argument('--batch_size', default=4, type=int,
help='Batch size for training')
3、在迭代过程中,每次执行batch张图片,通过images, targets = next(batch_iterator)读取图片时,如果next()中没有数据后会触发Stoplteration异常,使用下面语句替换 images, targets = next(batch_iterator)将解决这种异常问题。
while True:
try:
# 获得下一个值:
images, targets = next(batch_iterator)
except StopIteration:
# 遇到StopIteration就退出循环
break
五、训练数据集
cd ..
python train.py
六、修改eval.py代码
1、指定GPU
在eval.py代码头部加一行指令(注:加在import os之后),“1”代表选择了1号GPU
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
(注:这一小步可不做)
2、原始代码中默认的是读取官方的训练模型(注:无法下载),而前一步中,我们已经生成了自己的VOC.pth模型,因此需要将其修改。
找到代码的低38行,将ssd300_mAP_77.43_v2.pth改为VOC.pth
parser.add_argument('--trained_model',
default='weights/ssd300_mAP_77.43_v2.pth', type=str,
help='Trained state_dict file path to open')
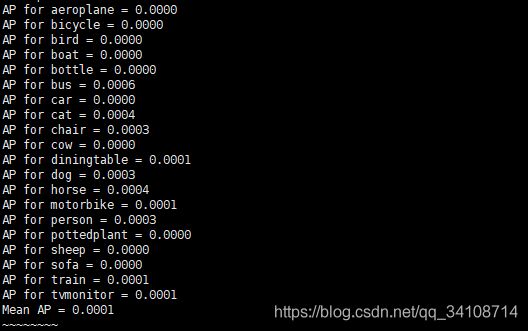
七、测试效果
1、直接运行代码。
python eval.py
2、因为我只训练了200次,所以效果很差。不过运行成功还是说明了平台搭建没有问题。