论文那些事—Towards Evaluating the Robustnessof Neural Networks
Towards Evaluating the Robustness of Neural Networks(神经网络鲁棒性评价)
1、摘要及背景
2016年提出一中蒸馏网络的防御方法(梯度屏蔽),蒸馏网络的作者声称防御蒸馏能够击败现有的攻击算法,并且将他们的攻击成功率从95%降低到5%。这种防御方法通常用于任何前馈神经网络,只需要一个单独的训练步骤,就能够防御当前所存在的对抗样本。本文作者对防御性的蒸馏网络提出了挑战,设计出了一种基于优化的对抗攻击方法C&W。
蒸馏网络(Distillation,本质是一种压缩模型):“蝴蝶以毛毛虫的形式吃树叶积攒能量逐渐成长,最后变换成蝴蝶这一终极形态来完成繁殖。”比如毛毛虫的形态是为了更方便的吃树叶,积攒能量,但是为了增大活动范围提高繁殖几率,毛毛虫要变成蝴蝶来完成这样的繁殖任务。蒸馏神经网络,其本质上就是要完成一个从毛毛虫到蝴蝶的转变。
因为在使用神经网络时,训练时候的模型和实际应用的模型往往是相同的,就好像一直是一个毛毛虫,既做了吃树叶积累能量的事情,又去做繁殖这项任务,既臃肿又效率低下。
所以使用同样形态的模型,一方面会导致模型不能针对特定性的任务来快速学习,另一方面实际应用中如果也是用训练时非常庞大的模型会造成使用开销负担过重。
Softmax-T函数
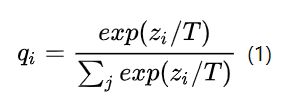
我们都知道softmax是啥,这个softmax-T的T意思是Temperature,就是一个在softmax操作前需要统一除以的小参数,这个小参数有这样的属性:
-
如果将T取1,这个公式就是softmax,根据logit输出各个类别的概率
-
如果T接近于0,则最大的值会越近1,其它值会接近0,近似于onehot编码
-
如果T越大,则输出的结果的分布越平缓,相当于平滑的一个作用,起到保留相似信息的作用
本论文主要内容有三:
- 作者针对
 ,
, 和
和  三种距离度量引入到CW的攻击方式中,这三种度量方式的引入使得在较小的扰动下能够有较高的攻击准确率。
三种距离度量引入到CW的攻击方式中,这三种度量方式的引入使得在较小的扰动下能够有较高的攻击准确率。 -
模型蒸馏是对抗样本的有效的防御手段,CW攻击可以攻破防御性蒸馏中模型,高置信度的使模型出现误分类。
-
作者一共提出了7个优化目标,并系统地评估了目标函数的选择,目标函数的选择可以显著地影响攻击的效果,实验显示论文中的优化目标函数 f(6) 是所有优化目标中效果最好的
2、C&W攻击算法
核心思想:CW是一种基于优化的攻击方式,它同时兼顾高攻击准去率和低对抗扰动的两个方面。首先对抗样本需要用优化的参数来表示,其次在优化的过程中,需要达到两个目标,目标一是对抗样本和对应的干净样本应该差距越小越好;目标二是对抗样本应该使得模型分类错,且错的那一类的概率越高越好。
原始公式:
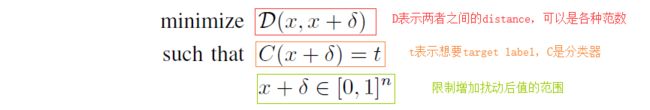
目标函数:
上述的优化问题是无法直接求解的,因此需要定义关于分类的损失函数F,使得当且仅当F ( x +  ) ≤ 0 F时,C ( x + ) = t 成立,从而联立D与F,形成可解的优化函数形式。其中 F 函数文中给了七种选择,:
) ≤ 0 F时,C ( x + ) = t 成立,从而联立D与F,形成可解的优化函数形式。其中 F 函数文中给了七种选择,:

最终将优化问题转化为:

其中 C>0 , 是一个适当选择的常数。公式中的第一项为距离表示可以换成范数的形式为:

盒约束:
关于像素值的上下界,原文将之命名为"box constraint",之所以存在上下界,是因为数字图像能表示的像素值范围是有限的,在经过归一化之后,像素值应该在[0,1]的范围内,即满足0 ≤ x + δ ≤ 1 。如果在攻击生成之后,直接把像素值裁剪到[0,1]的范围内,那显而易见,会破坏形成的攻击效果。那么如何在优化的过程中优雅地引入这个限制,又能保障攻击的效果呢?作者在这里共讨论了三种方式(I-FGSM中有个clip函数起截断作用,但CW是优化的方法,将像素值映射再次映射到[0,1]区间内以代替截断,第一次映射是图片的归一化处理,这就是盒约束):
(1)Projected gradient descent
该方法在每次实施梯度下降迭代,都将结果限制在box内。该方法的缺陷在于对于真实数据进行了剪裁,导致每次传入下一步的结果都不是真实值。
(2)Clipped gradient descent
用f( min ( max ( x + δ , 0 ),1 ) )代替原目标函数 f ( x+ δ ),该方法并没有剪裁x + δ,而是将限制加入到函数当中。缺点是有可能卡在一个平坦区域而此时 x + δ已经超过了最大值, 这样就会产生梯度为0的结果,以至于x即使减少也不会被探测到。
(3)Change of variable
该方法对δ进行替换:

由于tan函数取值性质,从而保证x + δ符合盒约束。
基于三种度量方式的攻击方法
attack:

这部分理解不到位,贴一个大牛的思想。

attack:
攻击是指改动的像素个数最小的攻击。L0不可导,于是作者的方法是:一步步的找到那些对分类结果影响很小的像素点,然后固定这些像素点(因为改了它们也没有什么作用),直到无法再找到这样无影响的像素点了。
假设原图是 X ,攻击找到的对抗样本是x + δ ,于是计算g = ∇ f ( x + δ ) ,求得每个像素点的偏导。随后基于梯度来找到对目标函数值影响最小的像素点,将该像素点排除在外,对其他像素进行梯度反传更新。不断迭代,直到获得一个最小的像素子集合(终止条件是的攻击方法无法再找到有效的攻击样本。
attack:
该攻击方法不是完全可微的,并且标准的梯度下降算法并不能达到非常好的效果,即采用如下策略时,会出现一个问题:无穷范数只惩罚最大的那个值。那么就可能出现这种情况:有两个像素点,分别是![]() 和
和![]() ,那么正则化就会惩罚
,那么正则化就会惩罚 点,而正则化在
点,而正则化在![]() 点处的梯度将会是0,该点即便扰动量很大也不会被惩罚。因此,在后序迭代中,
点处的梯度将会是0,该点即便扰动量很大也不会被惩罚。因此,在后序迭代中,![]() 可能会慢慢大于
可能会慢慢大于![]() ,如此反复,两个点会在
,如此反复,两个点会在![]() 附近来回波动,不会有任何有效的更新。
附近来回波动,不会有任何有效的更新。
![]()
为了解决这个问题,作者将后面正则化项更换为了一个迭代的攻击,即超过 的项都会被惩罚。
的项都会被惩罚。
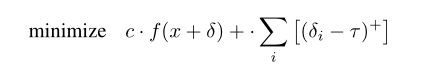
的初始值为1,在每次迭代中减少0.9,这可以防止振荡,因为该损失项会同时惩罚所有较大的值。如果所有像素的像素值均小于,那么对衰减0.9。如果所有的像素值都大于,就停止攻击样本的搜索。
3、总结
防御方法必须证明自己能够防御迁移性攻击,才能够证明防御的有效性。否则,只要在易攻破的模型上生成攻击样本,再迁移到防御模型上就可以攻击成功了。本文的作者利用迁移性攻击的方式再次攻破了防御性蒸馏,实现迁移性攻击的方式是搜索高置信度的攻击样本。其中,κ 用于标定攻击样本的置信度,κ 的值越高,生成的攻击越强。作者在MNIST数据集上进行迁移性试验,首先在未经过防御的模型上进行迁移性攻击,发现随着κ 值的升高,攻击成功率不断升高,在κ = 20 后保持在100%的成功率。这说明搜索高置信度的攻击样本有利于提高攻击成功率,作者随后对防御性蒸馏进行迁移性攻击,发现攻击依旧生效,这样就再一次攻破了防御性蒸馏。本文的作者通过对损失函数以及像素值clip方式的改进,提出了一种新的攻击方式,常称之为CW攻击,一举攻破了当时SOTA的防御方式——防御性蒸馏,推动了对抗攻防的演进。