Video Visual Relation Detection 论文阅读笔记
一、引言
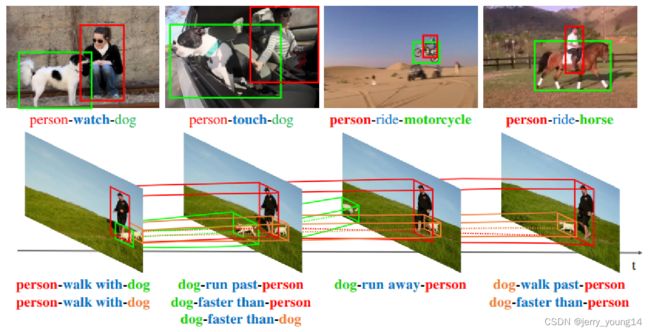
视频能够提供更加贴合实际的特征来监测物体之间的关系:
- 动作特征能够区分在静态图片上很难辨别的谓词,如walk与run;
- 有很多关系不能够再图片上检测出来,如run past, faster than等,视频提供了一种更加灵活的方式;
- 视频中的视觉关系可以是随着时间维度变化的,而图片是固定的。下图中狗和飞盘的相对位置变化造成了第2帧和第7帧不同的关系。
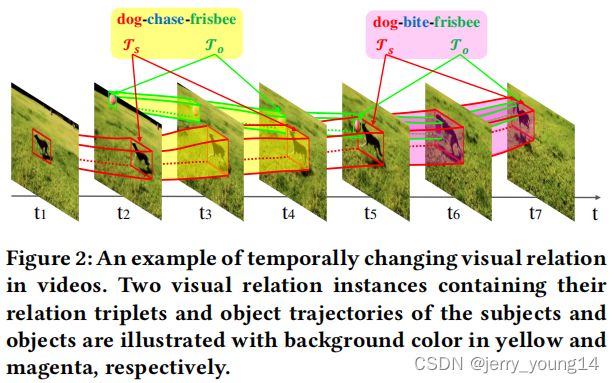
VidVRD中的视觉关系实例包括某关系在时间上的轨迹,如上图中,dog-chase-frisbee的轨迹范围为第2-4帧,dog-bite-frisbee的轨迹范围为第5-7帧。
难点:
- 不仅需要定位物体,还需要跟踪。本文对所有重叠的视频短片段都生成物体轨迹;
- 需要检测出每个关系的最大时间间隔。本文提出了一个贪婪关联算法,该算法合并相邻片段中物体重叠度较高同时预测为相同的关系的视频短片段。
- 需要预测的视觉关系类型更加多样。本文提出了可以提取多重特征(表面、动作、相对)的关系预测模型。
二、数据集
本文提出了第一个视觉关系检测的数据集VidVRD,包含35个物体类别:
所有的物体都是一个原子个体,即该数据集不存在part-of类的关系标注,如bicycle-with-wheel。作者选择了14个及物动词(e.g. ride)、3个比较类型词(e.g. faster)、11个空间形容词(e.g. above)、11个不及物动词(e.g. walk),并将它们进行组合得到132个谓词类别来作为数据集的谓词标注范围:

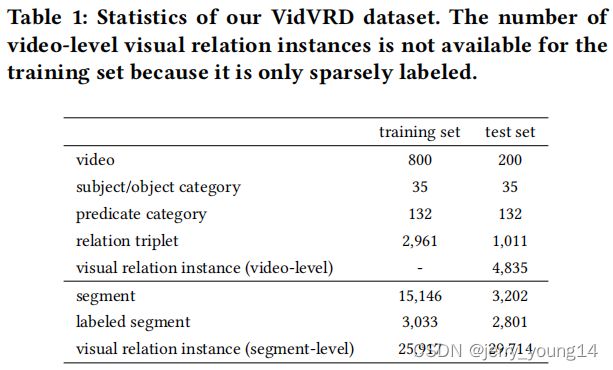
整个数据集包含3219个视觉关系类型,测试集中有258个训练集没有的关系类型。
三、视频视觉关系检测
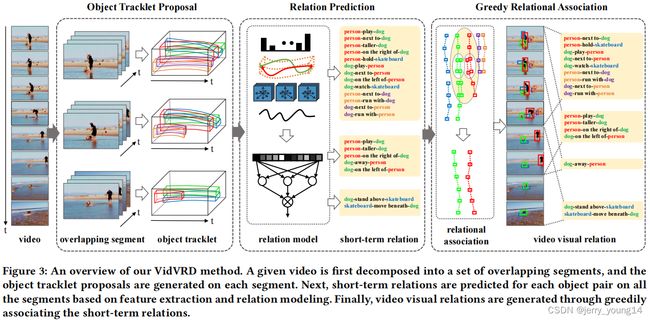
给定一个视频,将其分解成多个片段,每一个片段包含L帧(e.g. 30),片段之间的重叠帧为L/2(e.g. 15),然后在每一个片段中生成物体轨迹候选。然后对每一个片段中的物体候选对,提取它们的classeme特征(即预测概率的logits值)、iDT特征(HoG+HoF+MBH)、相对特征,并将它们进行混合,然后训练三个分类器,然后将三个分类器的输出概率值进行相乘联合进行softmax运算,得到每一个片段的预测结果。最后再使用贪婪关联算法将lont-term的动作进行合并,得到最后的结果。
Relation Prediction:
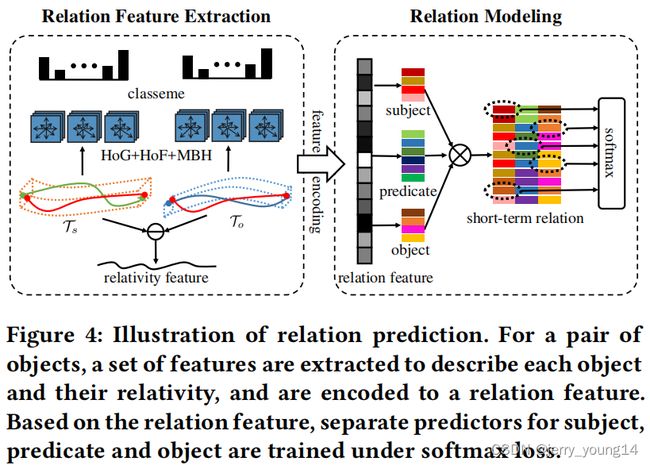
从轨迹候选 T s \mathcal{T}_{s} Ts和 T o \mathcal{T}_o To中提取物体的特征,提取的方法为iDT算法:
-
HoG(Histogram of Gradient):
-
转化为灰度图,然后直方图均衡化,增加图像的对比度;
-
计算图像的的梯度,首先计算像素点(x,y)在x方向和y方向的梯度,其次计算梯度幅值和梯度方向,在实际实现中可以分别用1*3的梯度算子[-1, 0, 1]卷积实现:
G x ( x , y ) = H ( x + 1 , y ) − H ( x − 1 , y ) G y ( x , y ) = H ( x , y + 1 ) − H ( x , y − 1 ) G ( x , y ) = G x ( x , y ) 2 + G y ( x , y ) 2 α ( x , y ) = t a n − 1 ( G y ( x , y ) G x ( x , y ) ) G_{x}(x, y)=H(x+1, y)-H(x-1, y)\\ G_{y}(x, y)=H(x, y+1)-H(x, y-1)\\ G(x, y)=\sqrt{G_{x}(x, y)^2+G_{y}(x, y)^2}\\ \alpha (x, y)=tan^{-1}(\frac{G_{y}(x, y)}{G_{x}(x, y)}) Gx(x,y)=H(x+1,y)−H(x−1,y)Gy(x,y)=H(x,y+1)−H(x,y−1)G(x,y)=Gx(x,y)2+Gy(x,y)2α(x,y)=tan−1(Gx(x,y)Gy(x,y)) -
将图像分为若干个单元格cell(e.g. 6*6),根据设定的直方图bin的数量(e.g. 9),然后以梯度方向进行分类,按照梯度大小进行加权计算得到每一个cell的梯度方向直方图,得到bin维向量;
-
把细胞单元组成更大的块block,块内归一化梯度直方图,并简单将块中所构成的每一个cell的梯度方向直方图的bin维向量拼接,得到该块的特征向量;
-
以块为单位,设定步长在图像上按照滑动窗口方式扫描,将每一个块的特征向量拼接得到属于该图片的HoG特征。
-
-
HoF(Histogram of Flow):HoF是对光流方向进行加权统计,得到光流方向信息直方图。
-
对每帧图像计算对应的光流场;
-
统计直方图,根据角度将其投影到对应的直方图bin中, 并根据该光流的幅值进行加权:
v = [ x , y ] T θ = t a n − 1 ( y x ) 当 角 度 落 在 范 围 − π 2 + π b − 1 B ≤ θ < − π 2 + π b B 时 , 其 幅 值 x 2 + y 2 作 用 到 直 方 图 第 b 个 b i n 中 v=[x, y]^{T}\quad \theta=tan^{-1}(\frac{y}{x})\\当角度落在范围-\frac{\pi}{2}+\pi\frac{b-1}{B}\leq\theta<-\frac{\pi}{2}+\pi\frac{b}{B}时,\\其幅值\sqrt{x^{2}+y^{2}}作用到直方图第b个bin中 v=[x,y]Tθ=tan−1(xy)当角度落在范围−2π+πBb−1≤θ<−2π+πBb时,其幅值x2+y2作用到直方图第b个bin中 -
归一化直方图。
-
-
MBH(Motion Boundary Histograms):MBH就是将x方向和y方向上的光流图视作两张灰度图像,然后提取这些灰度图像的梯度直方图,即HoG特征。MBH特征可以很好的提取运动物体的边界信息。
-
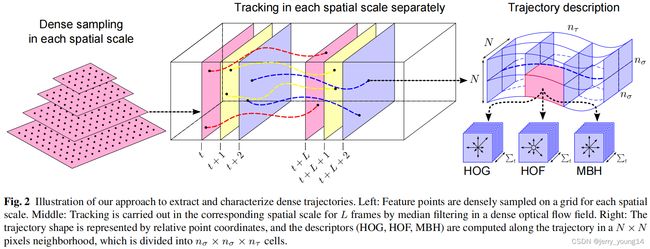
DT(Dense Trajectory):
- 在多个空间尺度上密集采样特征点;
- 利用光流场获取视频序列中的轨迹;
- 沿着轨迹提取4种特征:轨迹形状特征、HoG特征、HoF特征、MBH特征;
- 利用BoF(Bag of Features)方法对特征进行编码;
- 基于编码结果训练SVM分类器。
-
iDT(improved Dense Trajectory):iDT算法的基本框架与DT算法相同,主要改进点为:
- 优化光流图像,估计相机运动;
- 改进特征正则化方式,L2改为L1;
- 改进特征编码方式,使用Fisher Vector编码。
之后提取两个轨迹之间的相对特征:将物体轨迹候选 T s \mathcal{T}_s Ts的第t帧的中心点和大小表示为 C s t = ( x s t , y s t ) , S s t = ( w s t , h s t ) C_{s}^{t}=(x_{s}^{t}, y_{s}^{t}), S_{s}^{t}=(w_{s}^{t}, h_{s}^{t}) Cst=(xst,yst),Sst=(wst,hst)。我们计算三类特征,包括相对位置 Δ C \Delta C ΔC、相对尺寸 Δ S \Delta S ΔS、相对动作 Δ M \Delta M ΔM:
Δ C = ( C s 1 − C o 1 , . . . , C s L − C o L ) Δ S = ( S s 1 − S o 1 , . . . , S s L − S o L ) Δ M = ( Δ C 2 − Δ C 1 , . . . , Δ C L − Δ C L − 1 ) \Delta C = (C_{s}^{1} - C_{o}^{1}, ..., C_{s}^{L} - C_{o}^{L})\\ \Delta S = (S_{s}^{1} - S_{o}^{1}, ..., S_{s}^{L} - S_{o}^{L})\\ \Delta M = (\Delta C^{2} - \Delta C^{1}, ..., \Delta C^{L} - \Delta C^{L-1}) ΔC=(Cs1−Co1,...,CsL−CoL)ΔS=(Ss1−So1,...,SsL−SoL)ΔM=(ΔC2−ΔC1,...,ΔCL−ΔCL−1)
将物体轨迹特征、物体预测的classeme特征、相对特征融合得到一对物体轨迹的特征。最后进行训练:
L = ∑ ⟨ s i , p j , o k ⟩ − log s o f t m a x R ( P s ( f , s i ) ⋅ P p ( f , p j ) ⋅ P o ( f , o k ) ) L=\sum_{\big\langle s_{i}, p_{j}, o_{k} \big\rangle} -\log softmax_{\mathcal{R}}(P^{s}(f, s_{i})\cdot P^{p}(f, p_{j}) \cdot P^{o}(f, o_{k})) L=⟨si,pj,ok⟩∑−logsoftmaxR(Ps(f,si)⋅Pp(f,pj)⋅Po(f,ok))
Greedy Relational Association:
上一步是对每一个segment的关系预测,然而有些关系可能存在时间很长,连续多个segment都存在该关系,因此需要对他们进行拼接。该部分的目的就是合并相同的轨迹动作块 ( c t , ⟨ s , p , o ⟩ , ( T s t , T o t ) ) t ( t = m , . . . , n ) {(c^{t}, \big\langle s, p, o \big\rangle, (\mathcal{T}_{s}^{t}, \mathcal{T}_{o}^{t}))}_{t}\quad (t=m, ...,n) (ct,⟨s,p,o⟩,(Tst,Tot))t(t=m,...,n),并得出合并后 ( c ^ , ⟨ s , p , o ⟩ , ( T s ^ , T o ^ ) ) (\hat{c}, \big\langle s, p, o \big\rangle, (\hat{\mathcal{T}_{s}}, \hat{\mathcal{T}_{o}})) (c^,⟨s,p,o⟩,(Ts^,To^))的置信分数:
c ^ = 1 n − m + 1 ∑ t = m n c t \hat{c}=\frac{1}{n-m+1}\sum_{t=m}^{n}c^{t} c^=n−m+11t=m∑nct
算法流程如下:

四、实验
评价指标:
- visual relation detection: mAP,Recall@K;
- visual relation tagging: Precision@K。
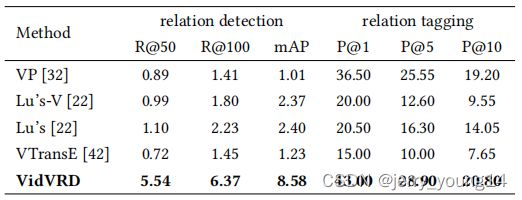
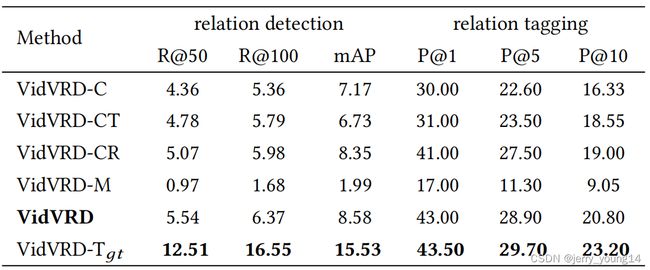
首先验证了特征提取中三类特征(classeme(C), iDT(T), relativity(R))的有效性,其次验证了联合主体-谓词-关系训练的有效性(独立训练为M)。最后作者关注了视频场景定位任务目标效果不好,因此考虑用groundtruth代替( T g t T_{gt} Tgt),发现在detection上效果提升很明显,由于tagging任务不需要物体定位,因此提升有限。
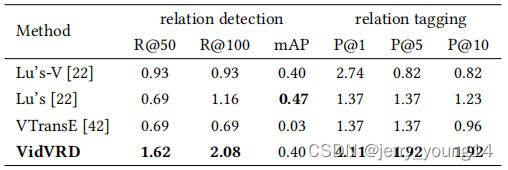
此外,作者比较了以往imgVRD的方法,由于任务不同,代替方法为使用该实验的初始特征代替这些方法的初始特征,得到结果如下(下图为zero-shot的结果):