目标检测数据集MSCOCO详解
1. 前言
介绍一下目标检测领域另外一个比较有名的数据集 MS COCO (Microsoft COCO: Common Objects in Context) .
MSCOCO 数据集是微软构建的一个数据集,其包含 detection, segmentation, keypoints等任务。
MSCOCO主要是为了解决detecting non-iconic views of objects(对应常说的detection), contextual reasoning between objects and the precise 2D localization of objects(对应常说的分割问题) 这三种场景下的问题。
下面是iconic 图片和 non-iconic 图片之间的对比:

与PASCAL COCO数据集相比,COCO中的图片包含了自然图片以及生活中常见的目标图片,背景比较复杂,目标数量比较多,目标尺寸更小,因此COCO数据集上的任务更难,对于检测任务来说,现在衡量一个模型好坏的标准更加倾向于使用COCO数据集上的检测结果。
2. COCO数据集分类
Image Classification:分类需要二进制的标签来确定目标是否在图像中。早期数据集主要是位于空白背景下的单一目标,如MNIST手写数据库,COIL household objects。在机器学习领域的著名数据集有CIFAR-10 and CIFAR-100,在32*32影像上分别提供10和100类。最近最著名的分类数据集即ImageNet,22,000类,每类500-1000影像。
Object Detection:经典的情况下通过bounding box确定目标位置,期初主要用于人脸检测与行人检测,数据集如Caltech Pedestrian Dataset包含350,000个bounding box标签。PASCAL VOC数据包括20个目标超过11,000图像,超过27,000目标bounding box。最近还有ImageNet数据下获取的detection数据集,200类,400,000张图像,350,000个bounding box。由于一些目标之间有着强烈的关系而非独立存在,在特定场景下检测某种目标是是否有意义的,因此精确的位置信息比bounding box更加重要。
Semantic scene labeling:这类问题需要pixel级别的标签,其中个别目标很难定义,如街道和草地。数据集主要包括室内场景和室外场景的,一些数据集包括深度信息。其中,SUN dataset包括908个场景类,3,819个常规目标类(person, chair, car)和语义场景类(wall, sky, floor),每类的数目具有较大的差别(这点COCO数据进行改进,保证每一类数据足够)。
Other vision datasets:一些数据集如Middlebury datasets,包含立体相对,多视角立体像对和光流;同时还有Berkeley Segmentation Data Set (BSDS500),可以评价segmentation和edge detection算法。
3. COCO数据集格式
COCO有5种类型的标注,分别是:物体检测、关键点检测、实例分割、全景分割、图片标注,都是对应一个json文件。json是一个大字典,都包含如下的关键字:
{
"info" : info,
"images" : [image],
"annotations" : [annotation],
"licenses" : [license],
}
其中info对应的内容如下:
info{
"year" : int,
"version" : str,
"description" : str,
"contributor" : str,
"url" : str,
"date_created" : datetime,
}
其中images对应的是一个list,对应了多张图片。list的每一个元素是一个字典,对应一张图片。格式如下:
info{
"id" : int,
"width" : int,
"height" : int,
"file_name" : str,
"license" : int,
"flickr_url" : str,
"coco_url" : str,
"date_captured" : datetime,
}
license的内容如下:
license{
"id" : int,
"name" : str,
"url" : str,
}
虽然每个json文件都有"info", “images” , “annotations”, "licenses"关键字,但不同的任务对应的json文件中annotation的形式不同,分别如下:
3.1 目标检测
每个对象实例注释都包含一系列字段,包括对象的类别id和分段掩码。分割格式取决于实例是表示单个对象(使用多边形的情况下iscrowd=0)还是表示对象的集合(使用RLE的情况下iscrowd=1)。注意,单个对象(iscrowd=0)可能需要多个多边形,例如遮挡时。Crowd注释(iscrowd=1)用于标记大量对象(例如一群人)。此外,还为每个对象提供了一个包围框(框坐标从图像左上角开始测量,并以0为索引)。最后,注释结构的categories字段存储类别id到类别和超类别名称的映射。请参见检测任务。
annotation{
"id" : int,
"image_id" : int,
"category_id" : int,
"segmentation" : RLE or [polygon],
"area" : float,
"bbox" : [x,y,width,height],
"iscrowd" : 0 or 1,
}
categories[{
"id" : int,
"name" : str,
"supercategory" : str,
}]
3.2 关键点检测
一个关键点注释包含对象注释的所有数据(包括id、bbox等)和两个附加字段。首先,keypoints是一个长度为3k的数组,其中k是为该类别定义的关键点的总数。每个关键点都有一个0索引的位置x,y和一个可见性标志v,定义为v=0:未标记(在这种情况下x=y=0), v=1:标记但不可见,v=2:标记且可见。一个关键点被认为是可见的,如果它落在对象段内。num_keypoints表示一个给定对象(许多对象,例如人群和小对象,将有num_keypoints=0)标记的关键点的数量(v>0)。最后,对于每个类别,categories结构有两个额外的字段:keypoints,这是一个长度为k的关键点名称数组,以及skeleton,它通过一个关键点边缘对列表定义连接性,并用于可视化。目前,关键点仅被标记为person类别(对于大多数中型/大型非人群的person实例)。参见关键任务。
annotation{
"keypoints" : [x1,y1,v1,...],
"num_keypoints" : int,
"[cloned]" : ...,
}
categories[{
"keypoints" : [str],
"skeleton" : [edge],
"[cloned]" : ...,
}]
"[cloned]": denotes fields copied from object detection annotations defined above.
3.3 实例分割
stuff注释格式与上面的对象检测格式完全相同并完全兼容(除了iscrowd没有必要并且默认设置为0)。为了方便访问,我们提供了JSON和png格式的注释,以及这两种格式之间的转换脚本。在JSON格式中,图像中的每个类别都用一个RLE注释进行编码(更多细节请参阅Mask API)。category_id表示当前物品类别的id。有关物品类别和超类别的更多细节,请参阅物品评估页面。参见stuff task。
3.4 全景分割
对于panoptic任务,每个注释结构是每个图像的注释,而不是每个对象的注释。每个图像注释有两个部分:(1)一个PNG存储与类无关的图像分割;(2)一个JSON结构存储每个图像分割的语义信息。更详细地说:要将注释与图像匹配,请使用image_id字段(也就是注释)。image_id = = image.id)。对于每个注释,每个像素的段id都存储在annotation.file_name中的单个PNG中。这些png文件在一个与JSON文件同名的文件夹中,例如:annotations/name. JSON对应的annotations/name. JSON。每个段(无论是东西段还是东西段)都被分配一个唯一的id。未标记的像素(void)被分配0的值。请注意,当你加载PNG作为RGB图像,你将需要通过ids=R+G256+B256^2计算id。对于每个注释,每个段信息都存储在annotation.segments_info中。segment_info。id存储段的唯一id,用于从PNG (ids==segment_info.id)中检索相应的掩码。category_id给出语义类别,iscrowd表示该段包含一组对象(仅与事物类别相关)。bbox和area字段提供了关于段的额外信息。COCO panoptic任务具有与检测任务相同的事物类别,而物品类别与stuff任务不同(详情请参见panoptic评估页面)。最后,每个类别结构都有两个额外的字段:区分事物和事物类别的isthing和有助于一致可视化的颜色。
annotation{
"image_id" : int,
"file_name" : str,
"segments_info" : [segment_info],
}
segment_info{
"id" : int,
"category_id" : int,
"area" : int,
"bbox" : [x,y,width,height],
"iscrowd" : 0 or 1,
}
categories[{
"id" : int,
"name" : str,
"supercategory" : str,
"isthing" : 0 or 1,
"color" : [R,G,B],
}]
3.5 图像标注
这些注释用于存储图像说明。每个标题描述指定的图像,每个图像至少有5个标题(有些图像有更多)。请参阅标题任务。
annotation{
"id" : int,
"image_id" : int,
"caption" : str,
}
4. 统计信息
MSCOCO总共包含91个类别,每个类别的图片数量如下:

图中也标出了PASCAL VOC的统计数据作为对比。
下图展示的是几个不同数据集的总类别数量,以及每个类别的总实例数量,一个实例就是图片上的一个目标,主要关注一下 PASCAL 和 ImageNet。
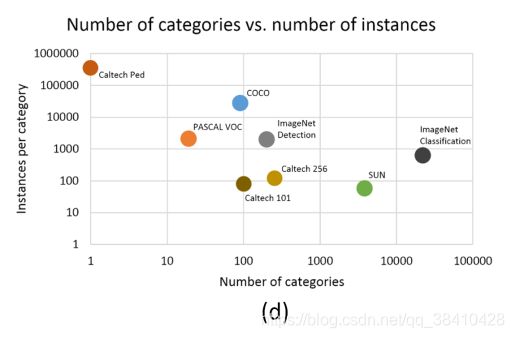
COCO数据集的类别总数虽然没有 ImageNet 中用于detection的类别总数多,但是每个类别的实例目标总数要比PASCAL和ImageNet都要多。
下图是每张图片上的类别数量或者实例数量的分布,括号中为平均值:
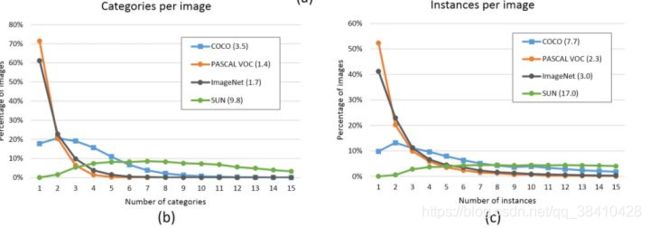
- PASCAL和ImageNet中,每张图片上的类别或者实例数量普遍都很少。
- 以PASCAL为例:有多于70%的图片上都只有一个类别,而多于50%的图片上只有一个实例或者目标。PASCAL数据集平均每张图片包含1.4个类别和2.3个实例目标,ImageNet也仅有1.7和3.0个。
- COCO数据集平均每张图片包含 3.5个类别和 7.7 个实例目标,仅有不到20%的图片只包含一个类别,仅有10%的图片包含一个实例目标。
- COCO数据集不仅数据量大,种类和实例数量也多。从这角度来说 SUN 数据集这两个指标更高一点,但是这个数据集在目标检测里面并不常用。
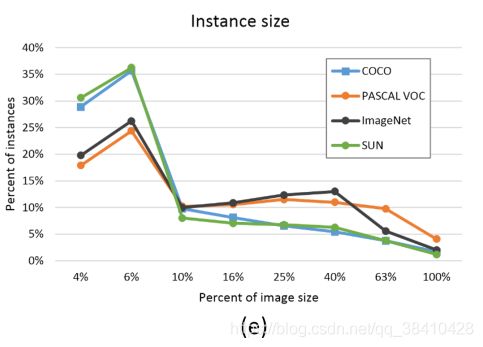
实例目标的分布(COCO数据集中的小目标数量占比更多):
关于数据集的划分,COCO的论文里是这么说的:The 2014 release contains 82,783 training, 40,504 validation, and 40,775 testing images (approximately 1/2 train, 1/4 val, and /4 test). There are nearly 270k segmented people and a total of 886k segmented object instances in the 2014 train+val data alone. The cumulative 2015 release will contain a total of 165,482 train, 81,208 val, and 81,434 test images.
2014年的数据在官网是可以下载的,但是2015年只有test部分,train和val部分的数据没有。另外2017年的数据并没有什么新的图片,只是将数据重新划分,train的数据更多了,如下:

5. 评估标准
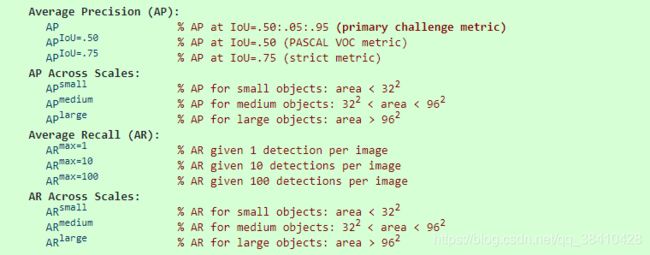
COCO的测试标准比PASCAL VOC更严格:
-
PASCAL 中在测试mAP时,是在IOU=0.5时测的。
-
COCO中的AP 是指在 10个IOU层面 以及 80个类别层面 的平均值。
-
COCO的主要评价指标是AP,指 IOU从0.5到0.95 每变化 0.05 就测试一次 AP,然后求这10次测量结果的平均值作为最终的 AP。
[email protected] 跟PASCAL VOC中的mAP是相同的含义。
[email protected] 跟PASCAL VOC中的mAP也相同,只是IOU阈值提高到了0.75,显然这个层面更严格,精度也会更低。
IOU越高,AP就越低,所以最终的平均之后的AP要比 [email protected] 小很多,这也就是为什么COCO的AP 超过 50%的只有寥寥几个而已,因为超过50%太难了。而且由于COCO数据集本身数据的复杂性,所以目前的 [email protected] 最高也只有 73% 。 -
COCO数据集还针对 三种不同大小(small,medium,large) 的图片提出了测量标准,COCO中包含大约 41% 的小目标 (area<32×32), 34% 的中等目标 (32×32
-
除了AP之外,还提出了 AR 的测量标准 跟AP是类似的。
COCO提供了一些代码,方便对数据集的使用和模型评估 :cocodataset/cocoapi
6. 总结
为什么COCO的检测任务那么难?
- 图片大多数来源于生活中,背景更复杂
- 每张图片上的实例目标个数多,平均每张图片7.7个
- 小目标更多
- 评估标准更严格
所以现在大家更倾向于使用COCO来评估模型的质量。
参考文献
- 目标检测数据集MSCOCO简介:https://arleyzhang.github.io/articles/e5b86f16/
- MS COCO数据集详解:https://blog.csdn.net/u013832707/article/details/93710810