Vit 中的 Token 改进版本:Token Mreging: Your Vit But Faster 论文阅读笔记
Vit 中的 Token 改进版本:Token Mreging: Your Vit But Faster 论文阅读笔记
- 一、Abstract
- 二、引言
- 三、相关工作
-
- 3.1 有效的 Transformer
- 3.2 Token 的减少
- 3.3 Token 的联合
- 四、Token 融合
-
- 4.1 策略
- 4.2 Token 相似性
- 4.3 双边软匹配
- 4.4 追踪 Token 的尺寸
- 4.5 采用融合操作的训练
- 五、图像实验
-
- 5.1 设计的选项
- 5.2 模型间的比较
- 5.3 与其他方法的比较
- 5.4 可视化的结果
- 六、视频实验
- 七、音频实验
- 八、结论
写在前面
都快一个月没写博客了,事情太多,又有拖延症,得改啊 (>﹏<)
- 论文题目:TOKEN MERGING: YOUR VIT BUT FASTER
- 代码地址:https://github.com/facebookresearch/ToMe
- 预计提交于 ICCV 2023
一、Abstract
本文引入一种 Token 融合的方法(Token Merging — ToMe),在无需额外训练的情况下增强现有 ViT 的性能。具体来说在 transformer 中使用一个通用且轻量化的匹配算法来逐步融合相似的 tokens。在图像、视频、音频上的性能绝佳。
二、引言
Transformer 的应用很广,效果也很好,就是训练速度太慢。最近提出的一些方法在修剪 tokens,然而有一些缺点:减少的 tokens 可能会使得信息丢失;可能需要重新训练才能让模型更有效;大部分方法不能用于加快模型的训练;根据输入的内容来修剪 tokens,会使得批量推理存在麻烦。
本文提出了 ToMe 来结合 tokens,而不是裁减掉这些。同时本文采用自定义的匹配算法,相对于剪枝来说更快且精度更高。此外,本文提出的方法需要或者不需要训练都可,在应用于大模型时只是会造成轻微的精度下降。在训练时如果使用 ToMe,时间会缩短,甚至在某些情况下训练时间减半。应用 ToMe 到图像、视频、音频上时能够达到 Sota 的效果。
三、相关工作
3.1 有效的 Transformer
改进整个 Transformer 模块,改进注意力机制,剪枝注意力头的特征,注入特定域模块。本文通过融合现有ViT模型中的 tokens 来匹配特定域的模型,从而加快速度,一些时候甚至无需训练。
3.2 Token 的减少
由于 transformer 能够使用任意数量的 token,因此一些方法在尝试剪枝的工作,然而需要训练。同时大量剪枝采用动态 token 数量的方式,但是不太实用,因为推理时没法用啊。因此为了改为动态方式,很多方法应用一个 mask 来训练而不是直接去除 token,但是这种方法又会让剪枝的作用失效。本文提出的方法可以直接应用于推理和训练,能够实现实时速度。
3.3 Token 的联合
只有少量的方法剪枝到单个 token,但是他们的精度普遍在无训练时掉点很多。
四、Token 融合
通过融合冗余的 tokens,不管在训练还是无训练的情况下,能够增加模型的效率。
4.1 策略
在每一个 Transformer 的每一个块中,每一层来融合 r r r 个 tokens。因此对于 L L L 块来说,需要融合 r L rL rL 个 tokens。更多的 r L rL rL 意味着准确度更低,但是速度收益更大。此外, r L rL rL 和图像内容无关。
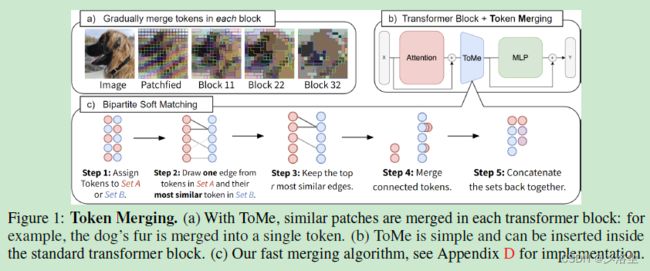
如上图所示,在每一个 Transformer 块中的注意力和 MLP 模块间加上 ToMe 模块(这里有个 ToMe 模块放置位置的消融实验)。
4.2 Token 相似性
之前的方法:衡量特征之间的距离,但这并不是最优的,因为中间的特征可能包含大量不太重要的噪声。而 Transformer 本身的特性通过 QKV 自注意力机制就解决了这个问题,因为 K 使用点乘的方式总结了每一个 token 的信息。因此借鉴这种方法,本文也采用点乘相似度矩阵来决定包含相似性信息的 token。
4.3 双边软匹配
之前聚类的方法用不了,太慢了。因此需要提出一种更有效的方案,其设计原则如有:避免任何不能进行并行化的迭代操作;逐步地进行融合操作以代替 Mask。另外一个没有用聚类方法的原因:因为聚类的效果太狠了,无脑去融合 tokens 到一个聚类中心,这可能会影响整个网络的性能,而匹配的方法则是使得大部分 tokens 留下。
算法流程如下:
- 将 tokens 划分为两个大致数量差不多的集合 A \mathbb{A} A、 B \mathbb{B} B
- 在集合 A \mathbb{A} A 中画一条边连接到 B \mathbb{B} B 中最相似的那个 token
- 保留下 r r r 个最相似的边
- 融合那些仍然相连接的边
- 拼接这两个集合
这个做法相当于建立了一个双边图,而在 A \mathbb{A} A 中的每个 token 仅有一条边,因此不需要计算每个 token 的相似度。实验表明这种双边软匹配的方法尽可能和随机扔掉 tokens 一样快。
4.4 追踪 Token 的尺寸
一旦具有相同 key 的 tokens 被融合了,那么融合后的 token 可能会对 softmax 有影响,因此采用一种比例注意力的方式来弥补这一变化:
A = softmax ( Q K ⊤ d + log s ) A=\operatorname{softmax}\left(\frac{Q K^{\top}}{\sqrt{d}}+\log s\right) A=softmax(dQK⊤+logs)
其中 s s s 为包含每个 token 尺寸(token 表示的 patch 数量)的行向量。
4.5 采用融合操作的训练
训练不是必须,但是训练可能会阻止梯度降低以及加快模型的训练。为了训练 ToMe,将 token 的融合视为池化操作并通过反向传播回传梯度。因此 ToMe 是个可以临时增加训练速度的替代方法。
五、图像实验
在 ImageNet-1K 数据集上,使用 AugReg、MAE、SWAG、DeiT 这四种方式。所有的模型要么采用 ToMe 离线训练,要么在 MAE 和 DeiT 上应用 ToMe 训练。推理在单张 V100上进行。
5.1 设计的选项
ViT-L/16 模型,24层。
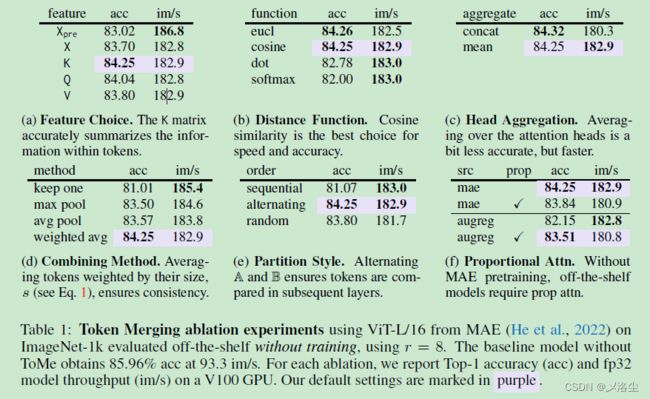
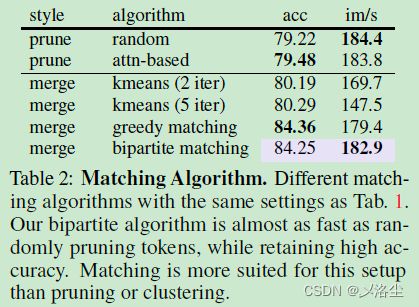
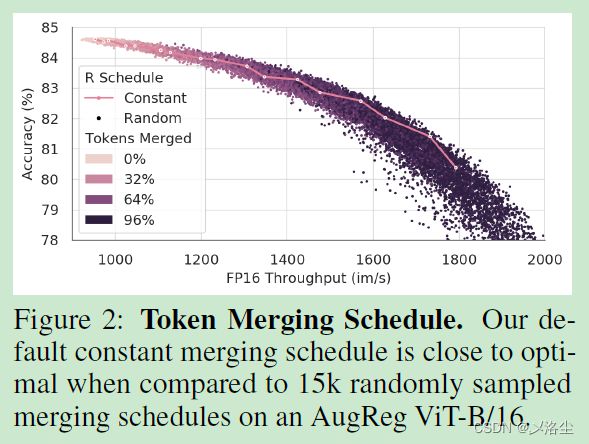
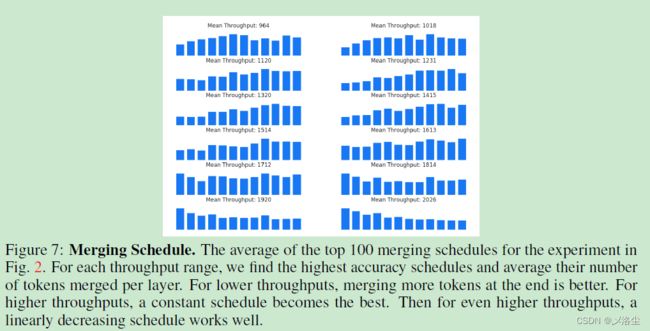
5.2 模型间的比较
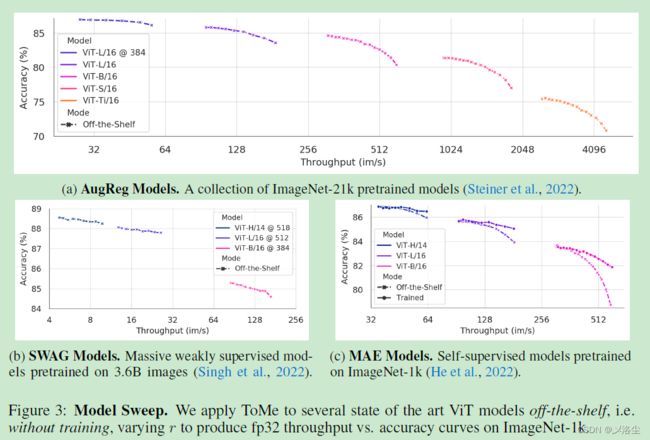
5.3 与其他方法的比较
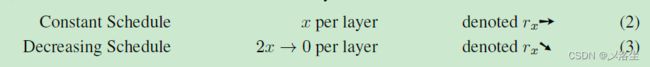
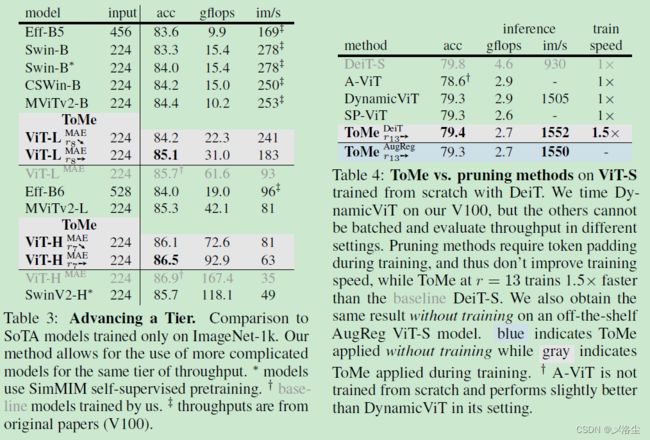
5.4 可视化的结果

六、视频实验
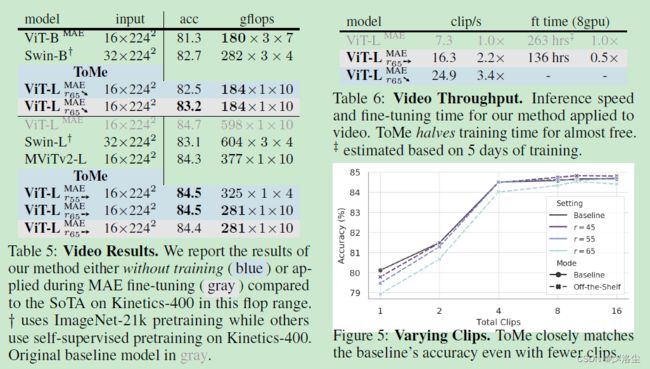

七、音频实验
上表 7。
八、结论
本文提出 ToMe,通过逐步融合 tokens 来增加 ViT 模型的速度,在图像、视频、声音模态上效果很好。能够和其他模型结合,可以用在大模型中。
写在后面
文章方法部分写的简洁凝练,实验做的特别多,工作量巨大。也需要一定的资本投入才能实现。剩下的附录部分等回家再给补上。溜了溜了~
青青草原,我来了~