TextRNN pytorch实现
Recurrent Neural Networks
RNN用来处理序列数据
具有记忆能力
Simple RNN
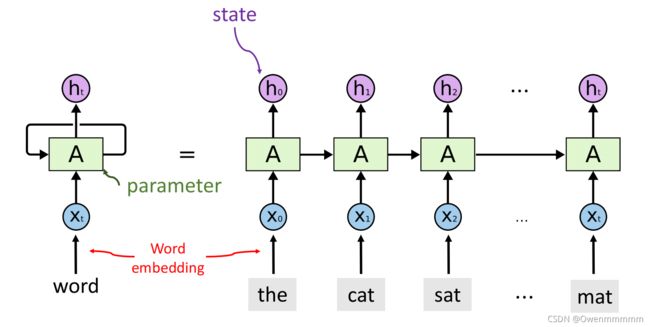
- h t h_t ht:状态矩阵,不断更新(h_0: the;h_1: the cat…)
- 只有一个参数矩阵A:随机初始化,然后用训练数据来学习A

- 为什么需要tanh激活函数:如果不激活可能会出现梯度消失或者梯度爆炸。
LSTM
- LSTM可以避免梯度消失的问题
- LSTM的记忆力要比SimpleRNN强
结构图:
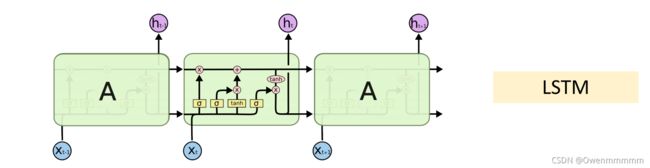
- LSTM有四个参数矩阵
- 传送带(conveyor bert):过去的信息可以直接传送到未来。
- 过去的信息直接通过 C t C_t Ct传送到下一个时刻,不会发生太大的变化(以此避免梯度消失)
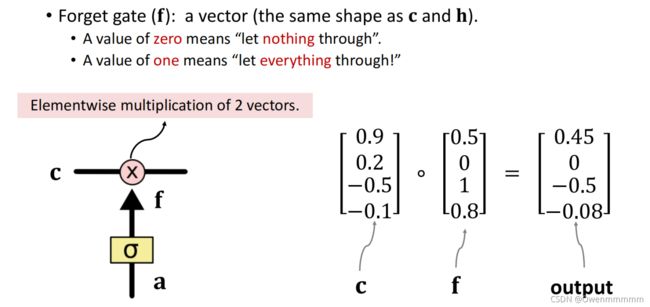
1. Forget Gate
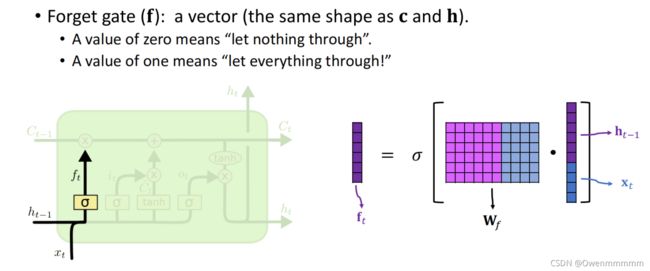
- f为遗忘门矩阵,为0就不通过
- W f W_f Wf:参数矩阵,通过反向传播从训练数据中学习
2. Input Gate
- W i W_i Wi:参数矩阵,通过反向传播从训练数据中学习
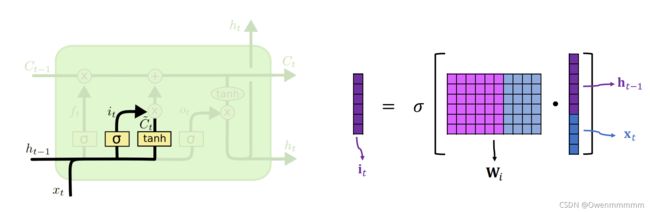
3. New Value


4. Output Gate

- Two Copies of ht:
- 一个作为输出
- 另一个传入到了下一步
改进RNN
- 多层RNN
- 双向RNN
- 预训练(预训练embedding层)
TextRNN
文本分类任务中,CNN可以用来提取句子中类似N-Gram的关键信息,适合短句子文本。TextRNN擅长捕获更长的序列信息。具体到文本分类任务中,从某种意义上可以理解为可以捕获变长、单向的N-Gram信息(Bi-LSTM可以是双向)。
一句话简介:textRNN指的是利用RNN循环神经网络解决文本分类问题,通常使用LSTM和GRU这种变形的RNN,而且使用双向,两层架构居多。
1. TextRNN简介
基本处理步骤:
- 将所有文本/序列的长度统一为n;对文本进行分词,并使用词嵌入得到每个词固定维度的向量表示。
- 对于每一个输入文本/序列,我们可以在RNN的每一个时间步长上输入文本中一个单词的向量表示,计算当前时间步长上的隐藏状态,然后用于当前时间步骤的输出以及传递给下一个时间步长并和下一个单词的词向量一起作为RNN单元输入。
- 再计算下一个时间步长上RNN的隐藏状态
- 以此重复…直到处理完输入文本中的每一个单词,由于输入文本的长度为n,所以要经历n个时间步长。
2. TextRNN网络结构
流程:embedding—>BiLSTM—>concat final output/average all output—–>softmax layer
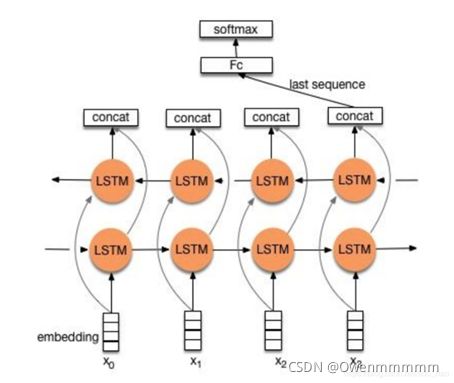
两种形式:
- 一般取前向/反向LSTM在最后一个时间步长上隐藏状态,然后进行拼接,在经过一个softmax层(输出层使用softmax激活函数)进行一个多分类;
- 取前向/反向LSTM在每一个时间步长上的隐藏状态,对每一个时间步长上的两个隐藏状态进行拼接,然后对所有时间步长上拼接后的隐藏状态取均值,再经过一个softmax层(输出层使用softmax激活函数)进行一个多分类(2分类的话使用sigmoid激活函数)。
上述结构也可以添加dropout/L2正则化或BatchNormalization 来防止过拟合以及加速模型训练。
简单代码实现
任务:输入前两个此,预测下一个词
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
dtype = torch.FloatTensor
sentences = [ "i like dog", "i love coffee", "i hate milk"]
word_list = " ".join(sentences).split()
vocab = list(set(word_list))
word2idx = {w: i for i, w in enumerate(vocab)}
idx2word = {i: w for i, w in enumerate(vocab)}
n_class = len(vocab)
# TextRNN Parameter
batch_size = 2
n_step = 2 # number of cells(= number of Step) 输入有多少个单词
n_hidden = 5 # number of hidden units in one cell
def make_data(sentences):
input_batch = []
target_batch = []
for sen in sentences:
word = sen.split()
input = [word2idx[n] for n in word[:-1]]
target = word2idx[word[-1]]
input_batch.append(np.eye(n_class)[input]) # one-hot编码
target_batch.append(target)
return input_batch, target_batch
input_batch, target_batch = make_data(sentences)
input_batch, target_batch = torch.Tensor(input_batch), torch.LongTensor(target_batch)
dataset = Data.TensorDataset(input_batch, target_batch)
loader = Data.DataLoader(dataset, batch_size, True)
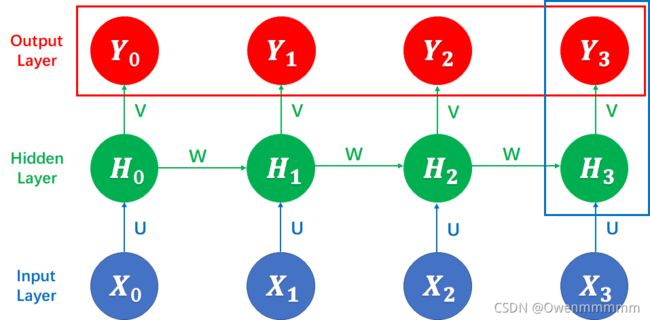
TextRNN模型:
- input_size:指的是每个单词用多少维的向量去编码
- hidden_size:指的是输出维度是多少
- 由于pytorch的rnn的要求,利用transpose(0,1)将batch_size放在第二个维度
- 我们需要的的是最后一个输出:out-1
class TextRNN(nn.Module):
def __init__(self):
super(TextRNN, self).__init__()
self.rnn = nn.RNN(input_size=n_class, hidden_size=n_hidden)
# fc
self.fc = nn.Linear(n_hidden, n_class)
def forward(self, hidden, X):
# X: [batch_size, n_step, n_class]
X = X.transpose(0, 1) # X : [n_step, batch_size, n_class]
out, hidden = self.rnn(X, hidden)
# out : [n_step, batch_size, num_directions(=1) * n_hidden]
# hidden : [num_layers(=1) * num_directions(=1), batch_size, n_hidden]
out = out[-1] # [batch_size, num_directions(=1) * n_hidden]
model = self.fc(out)
return model
model = TextRNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Training
for epoch in range(5000):
for x, y in loader:
# hidden : [num_layers * num_directions, batch, hidden_size]
hidden = torch.zeros(1, x.shape[0], n_hidden)
# x : [batch_size, n_step, n_class]
pred = model(hidden, x)
# pred : [batch_size, n_class], y : [batch_size] (LongTensor, not one-hot)
loss = criterion(pred, y)
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
input = [sen.split()[:2] for sen in sentences]
# Predict
hidden = torch.zeros(1, len(input), n_hidden)
predict = model(hidden, input_batch).data.max(1, keepdim=True)[1]
print([sen.split()[:2] for sen in sentences], '->', [idx2word[n.item()] for n in predict.squeeze()])
用TextRNN进行IMDB电影评论情感分析
1. 数据预处理
- 设置种子SEED,保证结果可复现
- 利用torchtext构建数据集
import torch
from torchtext.legacy import data
from torchtext.legacy import datasets
import random
import numpy as np
SEED = 1234
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
TEXT = data.Field(tokenize = 'spacy',
tokenizer_language = 'en_core_web_sm',
batch_first = True)
LABEL = data.LabelField(dtype = torch.float)
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
train_data, valid_data = train_data.split(random_state = random.seed(SEED))
- 构建vocab,加载预训练词嵌入:
MAX_VOCAB_SIZE = 25_000
TEXT.build_vocab(train_data,
max_size = MAX_VOCAB_SIZE,
vectors = "glove.6B.100d",
unk_init = torch.Tensor.normal_)
LABEL.build_vocab(train_data)
- 创建迭代器:
BATCH_SIZE = 64
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device)
2. 构建模型
- LSTM: ( h t , c t ) = L S T M ( x t , h t , c t ) (h_t,c_t)=LSTM(x_t,h_t,c_t) (ht,ct)=LSTM(xt,ht,ct)
- 双向RNN:增加了一个反向处理的RNN层;然后拼接各个时刻两个RNN层的hidden state,将其作为最后的隐藏状态向量。
- 多层RNN:多加基层RNN;第一层的输出hidden state为上面一层的输入。
- 正则化:这里用了dropout,即对神经元进行随机失活。(关于为什么dropout有效的一种理论是,参数dropout的模型可以被视为“weaker”(参数较少)的模型。因此,最终的模型可以被认为是所有这些weaker模型的集合,这些模型都没有过度参数化,因此降低了过拟合的可能性。)
代码关键点:
- 由于是双向LSTM,在全连接层的维度为hidden_dim*2,output_dim
- 在将embeddings(词向量)输入RNN前,我们需要借助
nn.utils.rnn.packed_padded_sequence将它们‘打包’,以此来保证RNN只会处理不是pad的token。我们得到的输出包括packed_output(a packed sequence)以及hidden sate和cell state。如果没有进行‘打包’操作,那么输出的hidden state和cell state大概率是来自句子的pad token。如果使用packed padded sentences,输出的就会是最后一个非padded元素的hidden state和cell state。- 之后我们借助
nn.utils.rnn.pad_packed_sequence将输出的句子‘解压’转换成一个tensor张量。需要注意的是来自padding tokens的输出是零张量,通常情况下,我们只有在后续的模型中使用输出时才需要‘解压’。虽然在本案例中下不需要,这里只是为展示其步骤。
维度变换
- text:[sen_len, batch_size]
- embedded: [sen_len,batch_size, embed_dim](上面那个简单代码没有embedding这一步)
- hidden: [num layers*num directions, batch_size, hidden_dim]
- hidden:[batch_size, hidden_dim*num directions]
import torch.nn as nn
class RNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers,
bidirectional, dropout, pad_idx):
super().__init__()
# embedding嵌入层(词向量)
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx = pad_idx)
# RNN变体——双向LSTM
self.rnn = nn.LSTM(embedding_dim, # input_size
hidden_dim, #output_size
num_layers=n_layers, # 层数
bidirectional=bidirectional, #是否双向
dropout=dropout) #随机去除神经元
# 线性连接层
self.fc = nn.Linear(hidden_dim * 2, output_dim) # 因为前向传播+后向传播有两个hidden sate,且合并在一起,所以乘以2
# 随机去除神经元
self.dropout = nn.Dropout(dropout)
def forward(self, text, text_lengths):
#text 的形状 [sent len, batch size]
embedded = self.dropout(self.embedding(text))
#embedded 的形状 [sent len, batch size, emb dim]
# pack sequence
# lengths need to be on CPU!
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, text_lengths.to('cpu'))
packed_output, (hidden, cell) = self.rnn(packed_embedded)
#unpack sequence
output, output_lengths = nn.utils.rnn.pad_packed_sequence(packed_output)
#output的形状[sent len, batch size, hid dim * num directions]
#output中的 padding tokens是数值为0的张量
#hidden 的形状 [num layers * num directions, batch size, hid dim]
#cell 的形状 [num layers * num directions, batch size, hid dim]
#concat the final forward (hidden[-2,:,:]) and backward (hidden[-1,:,:]) hidden layers
#and apply dropout
hidden = self.dropout(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim = 1))
#hidden 的形状 [batch size, hid dim * num directions]
return self.fc(hidden)
- 实例化模型、传入参数
- 为了保证pre-trained 词向量可以加载到模型中,EMBEDDING_DIM 必须等于预训练的GloVe词向量的大小。
INPUT_DIM = len(TEXT.vocab) # 250002: 之前设置的只取25000个最频繁的词,加上pad_token和unknown token
EMBEDDING_DIM = 100
HIDDEN_DIM = 256
OUTPUT_DIM = 1
N_LAYERS = 2
BIDIRECTIONAL = True
DROPOUT = 0.5
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token] #指定参数,定义pad_token的index索引值,让模型不管pad token
model = RNN(INPUT_DIM,
EMBEDDING_DIM,
HIDDEN_DIM,
OUTPUT_DIM,
N_LAYERS,
BIDIRECTIONAL,
DROPOUT,
PAD_IDX)
- 查看参数量
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
- 检查pretrained embedding
pretrained_embeddings = TEXT.vocab.vectors
# 检查词向量形状 [vocab size, embedding acdim]
print(pretrained_embeddings.shape)
#将unknown 和padding token设置为0
UNK_IDX = TEXT.vocab.stoi[TEXT.unk_token]
model.embedding.weight.data[UNK_IDX] = torch.zeros(EMBEDDING_DIM)
model.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_DIM)
print(model.embedding.weight.data)
3. 训练模型
- 初始化优化器、损失函数
import torch.optim as optim
optimizer = optim.Adam(model.parameters())
criterion = nn.BCEWithLogitsLoss()
model = model.to(device)
criterion = criterion.to(device)
- 计算精度的函数
def binary_accuracy(preds, y):
"""
Returns accuracy per batch, i.e. if you get 8/10 right, this returns 0.8, NOT 8
"""
#round predictions to the closest integer
rounded_preds = torch.round(torch.sigmoid(preds))
correct = (rounded_preds == y).float() #convert into float for division
acc = correct.sum() / len(correct)
return acc
-
Traning
正如我们设置的“include_length=True”,我们的“batch.text”现在是一个元组,第一个元素是数字张量,第二个元素是每个序列的实际长度。在将它们传递给模型之前,我们将它们分成各自的变量“text”和“text_length”。
注意:因为现在使用的是dropout,我们必须记住使用
model.train()以确保在训练时开启 dropout。
def train(model, iterator, optimizer, criterion):
epoch_loss = 0
epoch_acc = 0
model.train()
for batch in iterator:
optimizer.zero_grad() # 梯度清零
text, text_lengths = batch.text # batch.text返回的是一个元组(数字化的张量,每个句子的长度)
predictions = model(text, text_lengths).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
- Testing
注意:因为现在使用的是dropout,我们必须记住使用
model.eval()以确保在评估时关闭 dropout。
def evaluate(model, iterator, criterion):
epoch_loss = 0
epoch_acc = 0
model.eval()
with torch.no_grad():
for batch in iterator:
text, text_lengths = batch.text #batch.text返回的是一个元组(数字化的张量,每个句子的长度)
predictions = model(text, text_lengths).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
import time
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
- 正式训练
N_EPOCHS = 5
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
valid_loss, valid_acc = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
# 保留最好的训练结果的那个模型参数,之后加载这个进行预测
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut2-model.pt')
print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc*100:.2f}%')
- 测试结果
model.load_state_dict(torch.load('tut2-model.pt'))
test_loss, test_acc = evaluate(model, test_iterator, criterion)
print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}%')
4. 模型验证
import spacy
nlp = spacy.load('en_core_web_sm')
def predict_sentiment(model, sentence):
model.eval()
tokenized = [tok.text for tok in nlp.tokenizer(sentence)]
indexed = [TEXT.vocab.stoi[t] for t in tokenized]
length = [len(indexed)]
tensor = torch.LongTensor(indexed).to(device)
tensor = tensor.unsqueeze(1)
length_tensor = torch.LongTensor(length)
prediction = torch.sigmoid(model(tensor, length_tensor))
return prediction.item()
- 输入需要评测的句子
predict_sentiment(model, "This film is terrible")
predict_sentiment(model, "This film is great")
参考文献
tensorflow文本分类实战(二)——TextRNN
YouTube王树森教程
TextRNN的pytorch实现
DataWhale
NLP-08 textRNN