分类任务评估1——推导sklearn分类任务评估指标
二分类问题评估指标在XGBoost中的使用
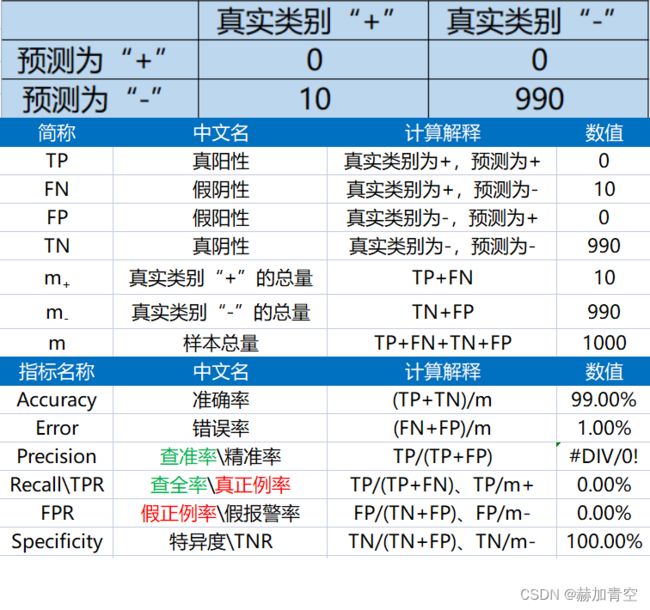
- 一.基础评估指标——准确率、精准率、召回率
-
- 1.混淆矩阵
- 2.基本计算单元
- 3.准确率、精准率、召回率、假报警率
-
- 3.1指标定义
- 3.2指标计算
- 3.3单一指标的不足
- 二.组合评估指标——G-mean值、F1值、AUC值、KS值
-
- 2.1组合指标计算及含义
- 2.2ROC曲线和AUC值的粗浅解释
-
- 2.2.1 患者检测案例
- 2.2.2 XGBoost案例数据演示
- 2.3查准率-查全率(P-R)曲线的解释
- 2.4K-S曲线和值的解释
背景介绍:
1)可先了解本人另一篇文章XGBoost模型调参、训练、评估、保存和预测,本文基于上述文章展开描述。
2)准确率、精准率、召回率、F1值、ROC曲线、AUC值这些评分标准适用于所有分类问题,不只是XGBoost,其他的分类模型同样适用(KNN、SVM、GBDT、LigthGBM等),并且多分类问题也同样适用。计算来源于y_ture和y_pred的比较,所以与使用什么样的模型无关,只与真实值和预测值有关。而回归问题(本文不做解释)应该采用其他合适的评估指标,例如最常用的MSE值、r2等。
3)二分类问题中,准确率、精准率、召回率、F1值、ROC曲线、AUC值都是基于混淆矩阵展开计算的。这里的所有计算均基于XGBoost模型调参、训练、评估、保存和预测对验证集的预测结果,0是设备正常,1是设备异常。

4)限于本文篇幅过长,ROC曲线本文只作粗浅解释,关于ROC曲线和查准率-查全率曲线的详细推导见分类任务评估2——推导ROC曲线、P-R曲线和K-S曲线
一.基础评估指标——准确率、精准率、召回率
1.混淆矩阵
通过confusion_matrix(y_test, y_pred)获取混淆矩阵。混淆矩阵绘制脚本实现如下,有 指标评估metrics_sklearn()模块的地方就可以有混淆矩阵confusion_matrix_df()。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score, precision_score, f1_score, roc_auc_score, recall_score, roc_curve, auc
from sklearn.metrics import confusion_matrix
def confusion_matrix_df(y_valid, y_pred_):
"""验证集或测试集预测结果的混淆矩阵"""
matrix = confusion_matrix(y_valid, y_pred_)
plt.matshow(matrix, cmap=plt.cm.Greens)
# 构建标签
for s in range(len(matrix)):
for t in range(len(matrix)):
plt.annotate(matrix[s, t], xy=(s, t))
# 打印结果
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
左侧为上述脚本绘制的混淆矩阵。纵轴为预测结果,横轴为真实值,0为-,1为+。结合混淆矩阵转化为常规理解的混淆矩阵

2.基本计算单元
如果一直没有弄明白这里的计算,请忘记之前学的,严格按照这里的“计算解释”来理解计算单元,否则无法进行后续理解。
1.Excel手工计算推导公式

2.脚本基本运算推导
y_test = [1, 0, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0]
y_pred = [0, 0, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0]
print(''.center(20, '-'))
df = pd.DataFrame(np.array([7, 0, 2, 5]).reshape(2, 2), columns=['真实类别+', '真实类别-'], index=['预测结果+', '预测结果-'])
print('混淆矩阵', '\n', df)
print(''.center(20, '-'))
TP = df.iat[0, 0]
FN = df.iat[1, 0]
FP = df.iat[0, 1]
TN = df.iat[1, 1]
print('真阳性 TP:', TP)
print('假阴性 FN:', FN)
print('假阳性 FP:', FP)
print('真阴性 TN:', TN)
print('真是类别为+的数量 m+:', TP + FN)
print('真是类别为-的数量 m-:', FP + TN)
print('总数据量 m:', TP + FP + TN + FN)

3.准确率、精准率、召回率、假报警率
3.1指标定义
Accuracy:准确率,所有预测正确的样本占总样本的比例,与Error相加为1;
Precision:查准率,预测为“+”真实类别为“+”的样本 占 预测为“+” 的样本 的 比例;
Recall \ TPR:查全率、召回率、灵敏度、反馈度、真正利率(True Positive Rate),预测为“+”真实类别为“+”的样本 占 真实类别为“+”的样本 的 比例,即真实类别“+”的准确率;
FPR:假正例率、假报警率,0是正常,1是异常,真实类别为“-”预测为“+”的样本 占 真实类别为“-”样本 的 比例,即正常设备判断为异常设备的数量 占 真实总异常设备数量 的 比例;
TNR:特异度、预测为“-”真实类别为“-”的样本 占 真实类别为“-”的样本 的 比例,即真实类别“-”的准确率。
3.2指标计算
1.Excel手工计算推导公式

2.脚本基本运算推导
# 准确率
Accuracy = (TP + TN) / (TP + FP + TN + FN)
print('Accuracy: %.2f%%' % (Accuracy * 100))
# 错误率
Error = (FN + FP) / (TP + FP + TN + FN)
print('Error: %.2f%%' % (Error * 100))
# 精准率
Precision = TP / (TP + FP)
print('Precision: %.2f%%' % (Precision * 100))
# 查全率/召回率
Recall = TP / (TP + FN)
print('Recall: %.2f%%' % (Recall * 100))
# 假报警率
FPR = FP / (FP + TN)
print('FPR: %.2f%%' % (FPR * 100))
# 特异度
TNR = TN / (FP + TN)
print('TNR: %.2f%%' % (TNR * 100))

3.3单一指标的不足
对于正负类别不均衡的情况,学习性能的评估应该更加关注小类的影响,准确率和错误率不适合用于类别不均衡的学习评估。为了便于理解,此处换一个场景一组数据来进行说明。
场景:1000个人去医院做检测,有10个癌症患者,990个正常。目标自然是不漏查一个患者,也不误判一个正常人。患者为+,正常为-。
最佳状态:准确率100%,查准率100%,查全率100%,假报警率0%

检测情况1:
准确率评估毫无意义——所有人均判断为正常,准确率99%,但这个检测等于没做,查全率为0,无查准率;
检测情况2:
查全率评估毫无意义——所有人均判断为患者,召回率100%,但这个检测依然等于没做,查准率为1%,假报警率100%;

检测情况3:
查准率评估毫无意义——仅一个患者被检查出来,且无正常人被误判,查准率100%,但这个检测漏掉了9个患者,也不能被接受,查全率为10%,假报警率0%;

据此可以判断,准确率、精准率、召回率、假报警率任何一个单一指标作为判断均有失偏颇,所以需要有新的、可以全面判断的指标来完成判断。
二.组合评估指标——G-mean值、F1值、AUC值、KS值
2.1组合指标计算及含义
说回XGBoost模型二分类任务中,单一指标无法准确评估模型效果,因此引入G-mean值,F1值和AUC值,以及ROC曲线、查准率-查全率曲线等指标和概念来做更公正标准的评估。

G-mean:TPR和TNR的几何平均值,也是每个类别准确率的几何平均值;
F1:查准率和查全率的调和平均数;
# F1的脚本计算
F1 = 1 / (0.5 / Precision + 0.5 / Recall)
print('F1: %.2f%%' % (F1 * 100))
# 返回结果:F1: 87.50%
AUC:TPR和FPR构成的ROC曲线下面积,即查全率和假报警率构成的曲线下面积 \ 真正例率和假正例率构成的曲线下面积。
2.2ROC曲线和AUC值的粗浅解释
G-mean和F1不难理解,此处对AUC值做简单说明。
2.2.1 患者检测案例
为了方便,先采用癌症患者检测的场景来说明。上文3.2中已经说明了三种情况:最佳状态、全部预测为患者和全部预测为正常。并已经做了基础值和单一指标的计算。
其中:
点1——最佳状态:查全率100%,假报警率0%;
点2——全部预测为正常:查全率0%,假报警率0%;
点3——全部预测为患者:查全率100%,假报警率100%;
据此,可绘制下图
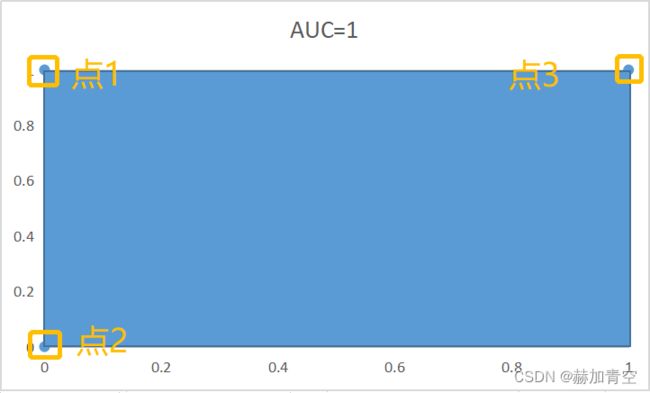
点2和点3不会改变,我们追求的是查全率越高越好,假报警率越小越好,即X轴越小越好,Y轴值越大越好。预测结果达到点1时为最好状态,预测结果越趋近于(0,1)阴影面积越大,所以3个点构成的阴影面积越大越好(曲线下面积Area Under Curve),即AUC值越大越好。
2.2.2 XGBoost案例数据演示
1.用roc_curve生成fpr、tpr、thresholds(阈值),用来理解ROC和AUC
thresholds:预测结果为类别时,此值为类别总数+1个数值,这里二分类问题因此有3个值,如返回打印结果所示[2, 1, 0];
预测结果为概率时 见本节——3.预测结果为概率,绘制ROC曲线;
fpr:假报警率,每个值对应thresholds阈值下的fpr;
tpr:查全率,每个值对应thresholds阈值下的tpr。
a)thresholds=2时,取类别结果>=2的标签预测为真,否则为预测为假,此处为fpr=0,tpr=0(所有类别均预测为0,等同于把到医院检测的人均判断为正常的情况)
b)thresholds=1时,取类别结果>=1的标签预测为真,否则为预测为假,此处为fpr=0,tpr=0.7778(9个真实为“+”的样本中预测出了7个,且0个真实为“-”的样本预测为“+”)
c)thresholds=0时,取类别结果>=0的标签预测为真,否则为预测为假,此处为fpr=1,tpr=1(所有类别均预测为1,等同于把到医院检测的人均判断为患者的情况)
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
AUC = auc(fpr, tpr) * 100
print('fpr:', list(fpr))
print('tpr:', list(tpr))
print('thresholds:', list(thresholds))
print('AUC: %.2f%%' % AUC)

2.预测结果为类别,粗浅理解ROC和AUC(Area under curve)
# 绘制查全率和假报警率围成的图形
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(6, 6))
plt.plot(fpr, tpr, color='r', label='AUC = %.2f%%' % AUC)
plt.plot([0, 1], [0, 1], '--')
plt.xlim([-0.002, 1])
plt.ylim([-0.002, 1])
plt.xlabel('假报警率')
plt.ylabel('查全率')
plt.title('查全率与假报警率——ROC曲线')
plt.legend(loc="lower right")
plt.show()
真实看到的ROC曲线都已概率预测来绘制,这里只是为了简单理解,用类别绘制一个简单线。具体ROC曲线绘制见3.预测结果为概率绘制ROC曲线

上述综述可得出,与患者检测案例相同的结论,AUC值越大越好
3.预测结果为概率,绘制ROC曲线
# 输入每一份样本预测类别为1的概率y_pred_proba(详见《XGBoost模型调参、训练、保存、评估和预测》3.1模型训练、验证、评估及特征重要性提取)
y_pred_proba = [0.2704021632671356, 0.0351046547293663, 0.8921366333961487, 0.046649616211652756, 0.17434531450271606,
0.21389029920101166, 0.6692600846290588, 0.8160045742988586, 0.8550902605056763, 0.9786821007728577,
0.9571514129638672, 0.10502149909734726, 0.5201050043106079, 0.032392870634794235]
# 假报警率、查全率、阈值
fpr2, tpr2, thresholds2 = roc_curve(y_test, y_pred_proba)
print('fpr:', list(fpr2))
print('tpr:', list(tpr2))
print('thresholds:', list(thresholds2))
结果可以看出,thresholds值由大到小排列,随着阈值的缩小,TPR增大时,FPR不变或提升。

通过不同阈值来区分不同类别,就能得到一系列的(FPR,TPR)点,当数据量足够时,thresholds阈值的划分会更加详细,便可形成一个近似平滑的曲线。
# ROC曲线绘制
plt.figure(figsize=(6, 6))
plt.plot(fpr2, tpr2, marker='p', color='r', label='AUC = %.2f%%' % AUC)
plt.plot([0, 1], [0, 1], '--')
plt.xlim([-0.002, 1])
plt.ylim([-0.002, 1.005])
plt.xlabel('假报警率')
plt.ylabel('查全率')
plt.title('查全率与假报警率——ROC曲线')
plt.legend(loc="lower right")
plt.show()

综上所述,关于ROC和AUC可以得出以下结论:
1.通过不同阈值来区分不同类别,就能得到一系列的(FPR,TPR)点;
2.随着阈值的缩小,TPR增大时,FPR不变或提升;
3.曲线下面积AUC越大越好,最小值为蓝色虚线下面积0.5,值的变化范围在蓝色虚线和红色实线围成的面积0-0.5之间。
关于ROC曲线基于pandas的推导见分类任务评估2——推导ROC曲线、P-R曲线和K-S曲线
2.3查准率-查全率(P-R)曲线的解释
P-R曲线推导过程及绘制脚本见分类任务评估2——推导ROC曲线、P-R曲线和K-S曲线

2.4K-S曲线和值的解释
sklearn中并没有直接用于ks计算的指标,而是通过roc_curve()得到fpr, tpr, thresholds三个list,K-S曲线是tpr-fpr作为纵坐标、thresholds作为横坐标构成的曲线图,如下图。其中红色线最大值的纵坐标值即为KS值(max(abs(fpr - tpr))),横坐标值为其对应阈值。

限于篇幅过长,2.3和2.4的推导过程及脚本见分类任务评估2——推导ROC曲线、P-R曲线和K-S曲线
声明:本文所载信息不保证准确性和完整性。文中所述内容和意见仅供参考,不构成实际商业建议,可收藏可转发但请勿转载,如有雷同纯属巧合。