DML
Load
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
create table dept(
deptno int,
dname string,
location string
) row format delimited fields terminated by '\t';
LOAD DATA LOCAL INPATH '/home/hadoop/data/dept.txt' OVERWRITE INTO TABLE dept;
Overwrite 会删除原数据(覆盖),不加的话会add数据到table(添加);
Insert
INSERT OVERWRITE [LOCAL] DIRECTORY directory1
[ROW FORMAT row_format] [STORED AS file_format] (Note: Only available starting with Hive 0.11.0)
SELECT ... FROM ...
INSERT OVERWRITE LOCAL DIRECTORY '/home/hadoop/data/d6/emptmp'
row format delimited fields terminated by ','
SELECT empno,ename FROM emp;
create table xxx as SELECT empno,ename FROM emp;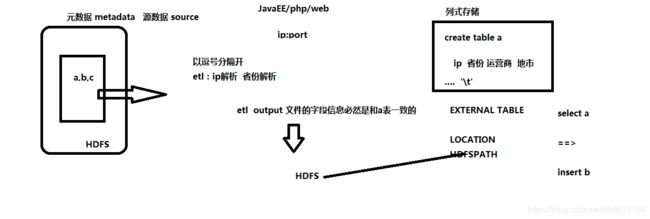
Hive里面的SQL
跟mysql一样的:
select ename, sal,
case
when sal > 1 and sal <=1000 then 'lower'
when sal > 1000 and sal <=2000 then 'middle'
when sal > 2000 and sal <=3000 then 'high'
else 'highest' end
from emp;
内置函数
upper lower
date
timestamp
desc function extended abs; 查看内置函数的具体信息

分割:

拆开:

有时候须要转义字符

hive的wordcount全过程:

行转列

select word,count(1) as c
from
(select explode(split(sentence," ")) as word from hive_wc) t
group by word
order by c desc;

1) null 0 "" ''的区别
null是空值,比如空指针
0就是int值
""是空字符串
“ ”表示有一个空格的字符串
2) 求每个部门、工作岗位的最高薪资
select deptno,job,max(sal) from emp group by deptno,job;
3) desc function extended abs; 中出现的案例是怎么来的呢
UDF函数里面有个@Description里面定义的
https://blog.csdn.net/HG_Harvey/article/details/77688735

4) 求每个月月底
