Transformers库学习-part1
文章目录
-
- C0 Setup
- C1 Transformers models
-
- Working with pipelines
-
- Zero-shot classification
- How do Transformers work?
-
- Transformers are language models
- Transformers are big models
- Transfer Learning
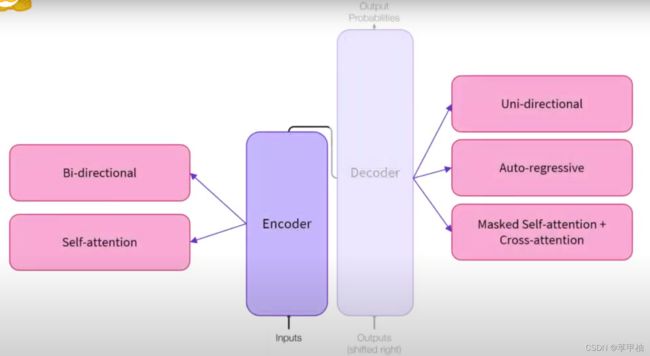
- General architecture
- Attention layers
- The original architecture
- Architectures vs. checkpoints
- Encoder models
- Decoder models
- Sequence-to-sequence models
- Bias and limitations
- Summary
C0 Setup
可以使用Google Colab notebook或者自己的虚拟环境
pip install "transformers[sentencepiece]"
C1 Transformers models
Transformers library
Model Hub
Working with pipelines
Transformers库最基本的对象是pipeline()函数,它将模型与必要的预处理和后处理步骤连接起来,允许直接输入任何文本并得到一个可理解的答案。

比如下面的例子进行语义分析,得到情感标签和得分
默认情况下,该pipeline选择一个特定的预先训练的模型,该模型经过微调,用于英语情感分析。当创建分类器对象时,模型被下载并缓存。如果重新运行该命令,则将使用缓存的模型,不需要再次下载该模型。
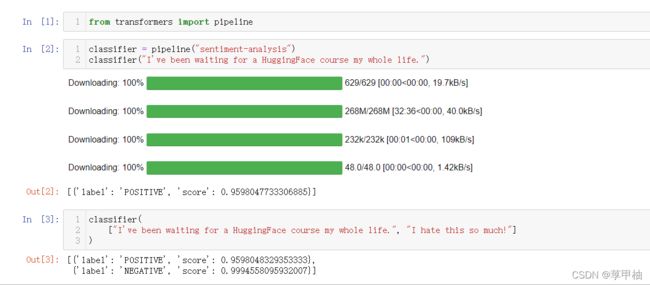
在向pipeline传递一些文本时,涉及三个主要步骤:
- 文本被预处理成模型可以理解的格式
- 预处理的输入被传递给模型
- 模型的预测是后处理的,所以您可以理解它们
目前可以用的pipeline有 available pipelines
- feature-extraction (get the vector representation of a text)
- fill-mask
- ner (named entity recognition)
- question-answering
- sentiment-analysis
- summarization
- text-generation
- translation
- zero-shot-classification
具体的使用示例在原官网有,因为下载比较慢这里就不测试了
Zero-shot classification
处理一个更有挑战性的任务,对没有被标记的文本进行分类。这是现实中的常见场景,因为注释文本通常很耗时,需要领域专业知识。
zero-shot-classification pipeline:允许指定用于分类的标签,因此不必依赖于预训练模型的标签
这个管道被称为zero-shot,因为使用它不需要对数据上的模型进行微调,可以直接返回想要的任何标签列表的概率得分
How do Transformers work?
以下是Transformer模型(较短)历史中的一些参考点
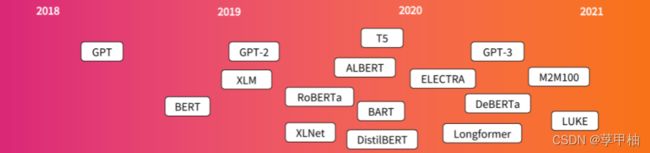
这个列表远远不够全面,只是为了突出介绍几种不同类型的Transformer模型。一般来说,它们可以分为三类:
- GPT-like (also called auto-regressive Transformer models)
- BERT-like (also called auto-encoding Transformer models)
- BART/T5-like (also called sequence-to-sequence Transformer models)
Transformers are language models
上面提到的所有Transformer模型(GPT、BERT、BART、T5等)都被训练为语言模型。这意味着他们以自我监督的方式接受了大量原始文本的训练。自我监督学习是一种训练方式,其目标是根据模型的输入自动计算出来的。这意味着不需要标签
这种类型的模型开发了对它所训练的语言的统计理解,但它对具体的实践任务不是很有用。正因为如此,一般的预训练模型会经历一个叫做迁移学习的过程。在此过程中,模型以一种监督的方式进行微调,即在给定任务上使用人类注释的标签。
一个例子是在阅读前面n个单词的基础上预测句子中的下一个单词,这被称为因果语言建模,因为输出取决于过去和现在的输入,而不是未来的输入。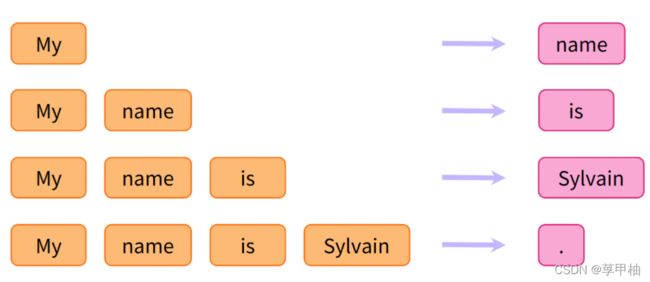
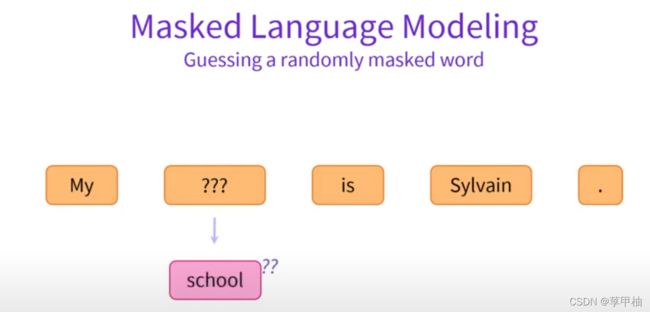
另一个例子是masked language modeling,模型预测句子中的一个被遮掩掉的词。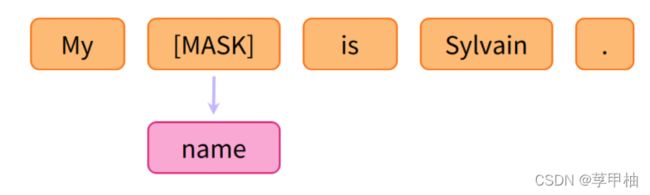
Transformers are big models
除了一些异常值(如DistilBERT)外,获得更好性能的一般策略是增加模型的大小以及它们预先训练的数据量。
但这会对环境有一定的破坏,特别是如果人人都要从头开始一个模型。
这就是为什么共享语言模型是至关重要的: 共享训练过的权重,并在已经训练过的权重之上构建,可以减少社区的总体计算成本和碳足迹。
Transfer Learning
预训练是从零开始训练一个模型的行为: 随机初始化权值,在没有任何先验知识的情况下开始训练。
这种预训练通常是在大量数据的基础上进行的。因此,它需要非常大的数据,而训练可能需要几周的时间。
微调是模型经过预训练后进行的训练。要进行微调,首先获取一个预先训练好的语言模型,然后使用特定于您的任务的数据集执行额外的训练。
不直接为最后的任务进行训练的原因有:
- 预处理模型
已经在与微调数据集有一些相似之处的数据集上进行了训练。因此,微调过程能够利用在预训练过程中从初始模型获得的知识(例如,对于NLP问题,预训练的模型将对您在任务中使用的语言具有某种统计理解)。 - 由于预训练模型已经在大量数据上进行了训练,因此微调
只需要很少的数据就能获得不错的结果。 - 出于同样的原因,获得好的结果所需的时间和资源要少得多。
例如,可以利用在英语语言上训练的预训练模型,然后在 arXiv 语料库上对其进行微调,从而产生基于科学/研究的模型。 微调只需要有限数量的数据:预训练模型获得的知识是“迁移”的,因此称为迁移学习。
因此,对模型进行微调可以降低时间、数据、财务和环境成本。它也更容易迭代不同的微调方案,因为训练比完整的预训练约束更少。
这个过程也会比从头开始训练得到更好的结果(除非你有大量的数据),这就是为什么你应该总是尝试利用一个预先训练的模型,一个尽可能接近你手头的任务的模型,并对它进行微调。
General architecture
该模型主要由两个模块组成:
- Encoder(左):编码器接收一个输入并构建一个它的表示(它的特征)。这意味着模型经过优化以从输入中获取理解
- 解码器(右):解码器使用编码器的表示(特征)和其他输入来生成目标序列。这意味着该模型经过优化以生成输出。
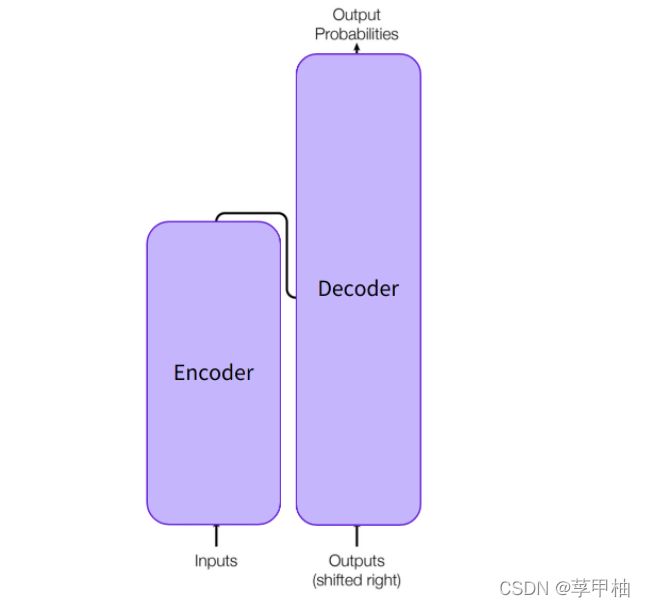
根据任务的不同,每个部分都可以独立使用:
- Encoder-only models:适用于需要理解输入的任务,如句子分类和命名实体识别。
- Decoder-only models:适合生成任务,如文本生成。
- Encoder-decoder models or sequence-to-sequence models:适合于需要输入的生成任务,如翻译或摘要。
Attention layers
Transformer模型的一个关键特性是,它们是用称为attention layers的特殊层构建的。事实上,介绍Transformer架构的论文标题是 “Attention Is All You Need”!
现在,需要知道,在处理每个单词的表示时,该层将告诉模型特别注意传递给它的句子中的某些单词(或多或少忽略其他单词)。
为了更好地理解这一点,考虑一下将文本从英语翻译成法语的任务。在输入You like this course的情况下,翻译模型还需要注意相邻的单词You,以便为单词like得到正确的翻译,因为在法语中,动词like随主语的变化而变化。然而,句子的其余部分对这个词的翻译没有用处。同样,在翻译“this”模型的时候,也需要注意单词的过程,因为它的翻译取决于关联名词是阳性还是阴性。再说一遍,句子中其他的词对翻译没有影响。对于更复杂的句子(和更复杂的语法规则),模型将需要特别注意那些可能出现在句子中较远处的单词,以便正确地翻译每个单词。
这一概念同样适用于任何与自然语言相关的任务: 单词本身有含义,但该含义深受上下文的影响,语境可以是被研究单词之前或之后的任何其他单词。
The original architecture
Transformer架构最初是为翻译而设计的。在训练过程中,编码器接收特定语言的输入(句子),而解码器接收所需目标语言的相同句子。
在编码器中,注意层可以使用句子中的所有单词(因为,正如我们刚才看到的,给定单词的翻译可以依赖于它在句子中的前后)。
然而,解码器按顺序工作,只能注意到句子中已经翻译的单词(因此,只注意当前生成的单词之前的单词)。例如,当我们预测了翻译后的目标的前三个单词时,我们将它们交给解码器,然后解码器使用编码器的所有输入来尝试预测第四个单词。
为了在训练过程中加快速度(当模型可以访问目标句子时),解码器被输入了整个目标,但不允许使用未来的单词。 例如,当试图预测第四个单词时,注意力层只能访问位置 1 到 3 的单词。
最初的Transformer架构是这样的,编码器在左边,解码器在右边。

解码器块中的第一个注意力层关注解码器的所有(过去)输入,但第二个注意力层使用编码器的输出。 因此,它可以访问整个输入句子以最好地预测当前单词。 这非常有用,因为不同的语言可以有将单词按不同顺序排列的语法规则,或者句子后面提供的某些上下文可能有助于确定给定单词的最佳翻译。
注意attention mask还可以用于编码器/解码器中,以防止模型注意一些特殊的单词,例如,当批量处理句子时,用于使所有输入保持相同长度的特殊填充单词。
Architectures vs. checkpoints
它们三个具有不同的内容,具体如下:
Architecture: 是模型的框架——模型中发生的每个层和每个操作的定义Checkpoints: 是将在给定架构中加载的权重Model: 这是一个总称,不像“架构”或“检查点”那样精确:它可以同时表示两者。 本课程将在需要减少歧义时指定Architecture或Checkpoints
For example,
BERTis an architecture whilebert-base-cased, a set of weights trained by the Google team for the first release of BERT, is a checkpoint. However, one can say “the BERT model” and “the bert-base-cased model.”
Encoder models
编码器模型是仅使用 Transformer 模型的编码器。 在每个阶段,注意力层都可以访问初始句子中的所有单词。 这些模型通常具有双向注意力的特征,通常称为自动编码模型(auto-encoding models)。
这些模型的预训练通常围绕着以某种方式破坏给定的句子(例如,通过屏蔽其中的随机单词)并让模型找到或重建初始句子。
编码器模型最适合于需要理解完整句子的任务,例如句子分类、命名实体识别(以及更一般的单词分类)和提取问题回答。
这类模型的代表包括:
- ALBERT
- BERT
- DistilBERT
- ELECTRA
- RoBERTa
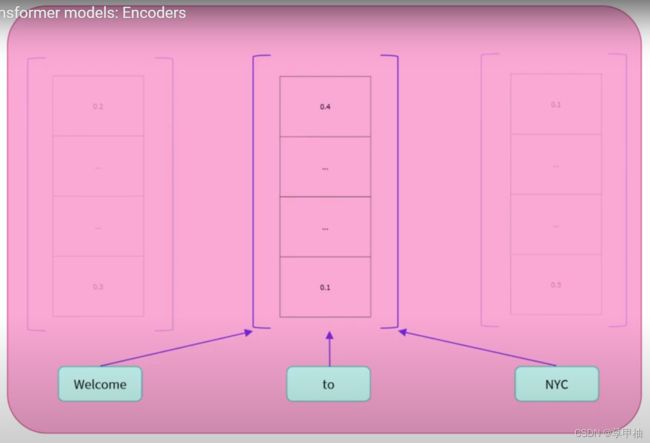
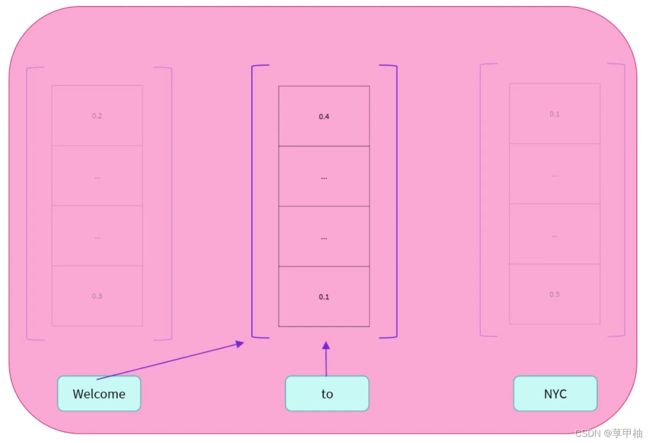
编码器的输出是每个输入词的数值表示,可以算作它们的特征向量。

初始句子中的每个词都影响着任意词的表示,这也称为上下文,比如to就受其左右两边的单词的影响。
自注意力机制

Decoder models
解码器模型仅使用Transformer模型的解码器。在每个阶段,对于一个给定的单词,注意层只能访问位于句子中它前面的单词。这些模型通常被称为自回归模型(auto-regressive models)。
解码器模型的预训练通常围绕着预测句子中的下一个单词。
这些模型最适合于涉及文本生成的任务。
这类模型的代表包括:
- CTRL
- GPT
- GPT-2
- Transformer XL
models的详细链接

每个初始单词也会得到一个数字表示,也称为特征向量

masked self-attention,只能学习到一侧的上下文信息

Sequence-to-sequence models
编码器-解码器模型(也称为序列到序列模型)使用了Transformer体系结构的两个部分。在每个阶段,编码器的注意层可以访问初始句子中的所有单词,而解码器的注意层只能访问输入中给定单词之前的单词。
这些模型的预训练可以使用编码器或解码器模型的目标来完成,但通常涉及一些更复杂的东西。例如,通过用单个掩码特殊单词替换随机的文本(可能包含几个单词)来对T5进行预处理,然后目标是预测该掩码单词替换的文本。
序列到序列模型最适合围绕根据给定输入生成新句子的任务,例如摘要、翻译或生成问题回答。
这类模型的代表包括:
- BART
- mBART
- Marian
- T5

解码器接收一个开始的输入,然后预测出第一个词,之后第一个词又被输入到解码器用于预测第二个词,以此循环
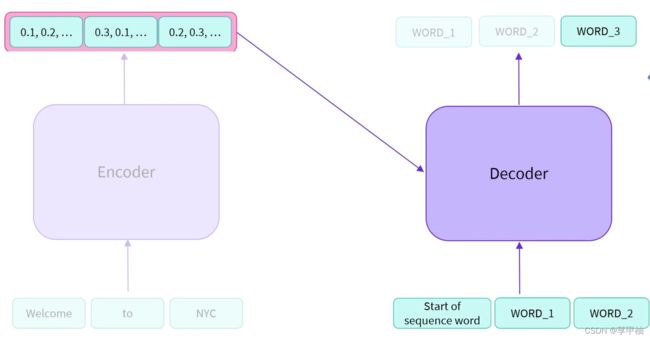
编码器:解析并理解信息,将其转换为特征向量
解码器:解析特征向量并输出
两者之间并不交换权重


Bias and limitations
如果打算在生产中使用经过训练的模型或经过微调的版本,请注意,尽管这些模型是强大的工具,但它们也有局限性。其中最大的问题是,为了能够对大量数据进行预训练,研究人员经常搜集他们能找到的所有内容,从互联网上获取最好的和最坏的内容。
为了给出一个快速的说明,让我们回到使用BERT模型的fill-mask pipeline 的例子

当被要求填写这两个句子中缺失的单词时,模型只给出了一个无性别的答案(服务员/服务员)。其他的职业通常与一个特定的性别有关,prostitute在模特将女人和工作联系在一起的前5个可能的职业中。尽管BERT是一种罕见的Transformer模型,但它并不是通过从互联网上抓取数据来构建的,而是使用明显的中立数据(它是在英语维基百科和BookCorpus数据集上训练的)。
因此,当你使用这些工具时,你需要记住,你使用的原始模型很容易生成性别歧视、种族歧视或恐同内容。对数据的模型进行微调不会使这种固有偏差消失。
Summary
- high-level pipeline() function
- how to search for and use models in the Hub
- how to use the Inference API to test the models directly in your browser

这章是在一个较高的层次讲解,下面会更底层讲解。