TensorFlow计算模型--计算图
计算图的概念
TensorFlow两个重要概念:Tensor和Flow,Tensor就是张量(可以理解为多维数组),Flow就是计算相互转化的过程。TensorFlow的计算方式类似Spark的有向无环图(DAG),在创建Session之后才开始计算(类似Action算子)。
简单示例
import tensorflow as tf
a = tf.constant([1.0,2.0],name="a")
b = tf.constant([3.0,4.0],name="b")
result = a + b
sess = tf.Session()
print(sess.run(result)) # [ 4. 6.]TensorFlow数据模型--张量
张量的概念
张量可以简单理解为多维数组。 零阶张量表示标量(scalar),也就是一个数。一阶张量表示为向量(vector),也就是一维数组。n阶张量表示为n维数组。但张量在TensorFlow中只是对结算结果的引用,它保存的是如何得到这些数字的计算过程。
import tensorflow as tf
a = tf.constant([1.0,2.0],name="a")
b = tf.constant([3.0,4.0],name="b")
result = a + b
print(result)
# Tensor("add_1:0", shape=(2,), dtype=float32)上面输出了三个属性:名字(name)、维度(shape)、类型(type)
张量的第一个属性名字是张量的唯一标识符,也显示出这个张量是如何计算出来的
张量的第二个属性维度是张量的维度信息,上面输出结果shape(2,)表示是一个一维数组,长度为2
张量的第三个属性类型是每个张量都会有的唯一类型,TensorFlow会对所有参与运算的张量进行类型检查,如果类型不匹配会报错。
TensorFlow运行模型--会话
创建会话的两种方式
# 创建一个会话
sess = tf.Session()
sess.run()
sess.cloes()
# 这种创建会话的方式需要显示关闭会话,释放资源# 使用python 上下位管理器来管理这个会话
with tf.Session() as sess:
sess.run()
# 不需要显示调用"sess.close()"函数来关闭会话
# 当上下文退出时会话关闭和资源释放也自动完成了TensorFlow会生成一个默认的计算图,可以通过tf.Tensor.eval函数来计算一个张量的取值
import tensorflow as tf
a = tf.constant([1.0,2.0],name="a")
b = tf.constant([3.0,4.0],name="b")
result = a + b
with tf.Session() as sess:
# 两种方式计算张量的取值
print(sess.run(result))
print(result.eval(session=sess))神经网络参数与TenworFlow变量
变量(tf.Variable)的作用就是保存和更新神经网络中的参数
# 声明一个2 * 3 的矩阵变量,矩阵均值为0,标准差为2的随机数
import tensorflow as tf
weights = tf.Variable(tf.random_normal([2,3],stddev=2))
# 初始化变量
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print(sess.run(weights))
# [[-0.69297457 1.13187325 2.36984086]
# [ 1.20076609 0.77468276 2.01622796]]TensorFlow随机数生成函数

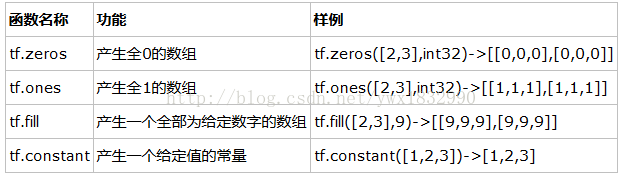
TensorFlow常数生成函数
神经网络程序
import tensorflow as tf
from numpy.random import RandomState
# 定义训练数据batch的大小
batch_size = 8
# 定义神经网络的参数
w1 = tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
w2 = tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))
# 在shape的一个维度上使用None可以方便使用不同的batch大小
x = tf.placeholder(tf.float32,shape=(None,2),name='x-input')
y_ = tf.placeholder(tf.float32,shape=(None,1),name='y-input')
# 定义神经网络前向传播的过程
a = tf.matmul(x,w1)
y = tf.matmul(a,w2)
# 定义损失函数和反响传播算法
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y,1e-10,1.0)))
train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
# 通过随机数生成一个模拟数据集
rdm = RandomState(1)
dataset_size = 128
X = rdm.rand(dataset_size,2)
# 定义规则来给出样本的标签,x1+x2<1的样例都被认为是正样本,其他为负样本,0:负样本,1:正样本
Y = [[int(x1+x2<1)] for (x1,x2) in X]
# 创建一个会话来运行TensorFlow程序
with tf.Session() as sess:
# 初始化变量
init_op = tf.global_variables_initializer()
sess.run(init_op)
print(sess.run(w1))
print(sess.run(w2))
# 设定训练的轮数
STEPS = 5000
for i in range(STEPS):
# 每次选取batch_size 个样本进行训练
start = (i * batch_size)% dataset_size
end = min(start+batch_size,dataset_size)
# 通过选取的样本训练神经网络并更新参数
sess.run(train_step,feed_dict={x:X[start:end],y_:Y[start:end]})
if i % 1000 == 0:
total_cross_entropy = sess.run(cross_entropy,feed_dict={x:X,y_:Y})
print("After %d trainint step(s),cross entropy on all data is %g" % (i,total_cross_entropy))
print(sess.run(w1))
print(sess.run(w2))训练神经网络的过程可以分为3个步骤:
- 定义神经网络的结构和前向传播的输出结果
- 定义损失函数以及选择反向传播优化的算法
- 生成会话(tf.Session)并在训练数据上仿佛运行反向传播优化算法
tensorflow实现线性回归
'''
A linear regression learning algorithm example using TensorFlow library.
Author: Aymeric Damien
Project: https://github.com/aymericdamien/TensorFlow-Examples/
'''
from __future__ import print_function
import tensorflow as tf
import numpy
import matplotlib.pyplot as plt
rng = numpy.random
# Parameters
learning_rate = 0.01
training_epochs = 1000
display_step = 50
# Training Data
train_X = numpy.asarray([3.3,4.4,5.5,6.71,6.93,4.168,9.779,6.182,7.59,2.167,
7.042,10.791,5.313,7.997,5.654,9.27,3.1])
train_Y = numpy.asarray([1.7,2.76,2.09,3.19,1.694,1.573,3.366,2.596,2.53,1.221,
2.827,3.465,1.65,2.904,2.42,2.94,1.3])
n_samples = train_X.shape[0]
# tf Graph Input
X = tf.placeholder("float")
Y = tf.placeholder("float")
# Set model weights
W = tf.Variable(rng.randn(), name="weight")
b = tf.Variable(rng.randn(), name="bias")
# Construct a linear model
pred = tf.add(tf.multiply(X, W), b)
# Mean squared error
cost = tf.reduce_sum(tf.pow(pred-Y, 2))/(2*n_samples)
# Gradient descent
# Note, minimize() knows to modify W and b because Variable objects are trainable=True by default
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
# Initializing the variables
init = tf.global_variables_initializer()
# Launch the graph
with tf.Session() as sess:
sess.run(init)
# Fit all training data
for epoch in range(training_epochs):
for (x, y) in zip(train_X, train_Y):
sess.run(optimizer, feed_dict={X: x, Y: y})
# Display logs per epoch step
if (epoch+1) % display_step == 0:
c = sess.run(cost, feed_dict={X: train_X, Y:train_Y})
print("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(c), \
"W=", sess.run(W), "b=", sess.run(b))
print("Optimization Finished!")
training_cost = sess.run(cost, feed_dict={X: train_X, Y: train_Y})
print("Training cost=", training_cost, "W=", sess.run(W), "b=", sess.run(b), '\n')
# Graphic display
plt.plot(train_X, train_Y, 'ro', label='Original data')
plt.plot(train_X, sess.run(W) * train_X + sess.run(b), label='Fitted line')
plt.legend()
plt.show()
# Testing example, as requested (Issue #2)
test_X = numpy.asarray([6.83, 4.668, 8.9, 7.91, 5.7, 8.7, 3.1, 2.1])
test_Y = numpy.asarray([1.84, 2.273, 3.2, 2.831, 2.92, 3.24, 1.35, 1.03])
print("Testing... (Mean square loss Comparison)")
testing_cost = sess.run(
tf.reduce_sum(tf.pow(pred - Y, 2)) / (2 * test_X.shape[0]),
feed_dict={X: test_X, Y: test_Y}) # same function as cost above
print("Testing cost=", testing_cost)
print("Absolute mean square loss difference:", abs(
training_cost - testing_cost))
plt.plot(test_X, test_Y, 'bo', label='Testing data')
plt.plot(train_X, sess.run(W) * train_X + sess.run(b), label='Fitted line')
plt.legend()
plt.show()tensorflow实现逻辑回归
'''
A logistic regression learning algorithm example using TensorFlow library.
This example is using the MNIST database of handwritten digits
(http://yann.lecun.com/exdb/mnist/)
Author: Aymeric Damien
Project: https://github.com/aymericdamien/TensorFlow-Examples/
'''
from __future__ import print_function
import tensorflow as tf
# Import MNIST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
# Parameters
learning_rate = 0.01
training_epochs = 25
batch_size = 100
display_step = 1
# tf Graph Input
x = tf.placeholder(tf.float32, [None, 784]) # mnist data image of shape 28*28=784
y = tf.placeholder(tf.float32, [None, 10]) # 0-9 digits recognition => 10 classes
# Set model weights
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
# Construct model
pred = tf.nn.softmax(tf.matmul(x, W) + b) # Softmax
# Minimize error using cross entropy
cost = tf.reduce_mean(-tf.reduce_sum(y*tf.log(pred), reduction_indices=1))
# Gradient Descent
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
# Initializing the variables
init = tf.global_variables_initializer()
# Launch the graph
with tf.Session() as sess:
sess.run(init)
# Training cycle
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples/batch_size)
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# Run optimization op (backprop) and cost op (to get loss value)
_, c = sess.run([optimizer, cost], feed_dict={x: batch_xs,
y: batch_ys})
# Compute average loss
avg_cost += c / total_batch
# Display logs per epoch step
if (epoch+1) % display_step == 0:
print("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(avg_cost))
print("Optimization Finished!")
# Test model
correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
# Calculate accuracy
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print("Accuracy:", accuracy.eval({x: mnist.test.images, y: mnist.test.labels}))tensorflow实现K-近邻
'''
A nearest neighbor learning algorithm example using TensorFlow library.
This example is using the MNIST database of handwritten digits
(http://yann.lecun.com/exdb/mnist/)
Author: Aymeric Damien
Project: https://github.com/aymericdamien/TensorFlow-Examples/
'''
from __future__ import print_function
import numpy as np
import tensorflow as tf
# Import MNIST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
# In this example, we limit mnist data
Xtr, Ytr = mnist.train.next_batch(5000) #5000 for training (nn candidates)
Xte, Yte = mnist.test.next_batch(200) #200 for testing
# tf Graph Input
xtr = tf.placeholder("float", [None, 784])
xte = tf.placeholder("float", [784])
# Nearest Neighbor calculation using L1 Distance
# Calculate L1 Distance
distance = tf.reduce_sum(tf.abs(tf.add(xtr, tf.negative(xte))), reduction_indices=1)
# Prediction: Get min distance index (Nearest neighbor)
pred = tf.arg_min(distance, 0)
accuracy = 0.
# Initializing the variables
init = tf.global_variables_initializer()
# Launch the graph
with tf.Session() as sess:
sess.run(init)
# loop over test data
for i in range(len(Xte)):
# Get nearest neighbor
nn_index = sess.run(pred, feed_dict={xtr: Xtr, xte: Xte[i, :]})
# Get nearest neighbor class label and compare it to its true label
print("Test", i, "Prediction:", np.argmax(Ytr[nn_index]),"True Class:", np.argmax(Yte[i]))
# Calculate accuracy
if np.argmax(Ytr[nn_index]) == np.argmax(Yte[i]):
accuracy += 1./len(Xte)
print("Done!")
print("Accuracy:", accuracy)