小米AI实验室六篇论文获 ICASSP 2022收录,多模态语音唤醒挑战赛夺冠
![]()
![]()
近日,全球语音、声学顶级会议ICASSP 2022公布了论文入选名单,小米AI实验室6篇学术论文被接收。同时,小米“自由说”系统在MISP(基于多模态信息的语音处理)挑战赛中荣获多模态语音唤醒第一名和多模态语音识别第二名,这也是小米语音方向取得的第6个世界级比赛冠军。
![]()

ICASSP(International Conference on Acoustics, Speech and Signal Processing)即国际声学、语音与信号处理会议,是IEEE主办的全世界最大的,也是最全面的信号处理及其应用方面的顶级会议,在国际上享有盛誉并具有广泛的学术影响力。
小米AI实验室被录用的论文涉及语音识别、语音合成、声学语音质量评价等诸多方向,在此次 ICASSP 2022录用的论文概述如下。
01
▍《MSDTRON:基于多样性数据的高性能多说话人个性化语音合成系统》
Wu Q, Shen Q, Luan J, Wang Y, MSDTRON: A High-Capability Multi-Speaker Speech Synthesis System For Diverse Data Using Characteristic Information, ICASSP 2022
业务应用:提升小爱同学声音定制的效果。2021年自研声音定制2.0上线小爱同学,除声音定制外,我们还首发了个性化歌唱功能。
算法设计如下图所示:

本文针对多说话人语音合成(Multi-speaker TTS)定义了一种结合语音谐波结构(harmonic structure)的激励谱(excitation-spectrogram)特征,激励谱特征可以很好的优化语音mel谱(mel-spectrogram)特征的学习。在解码器(decoder)的LSTM网络部分,本文提出了一种结合说话人信息(speaker-embedding)的CGLSTM(conditional gated LSTM)结构。对比传统的多说话人语音合成系统,本文的方法提升了模型对不同说话人的风格和情感等信息的学习能力,有效提升了个性化语音合成的效果。
>>>>
合成样音抢先听:
02
▍《PAMA-TTS:使用合成进度敏感的单调注意力机制精准控制音素韵律的稳定端到端语音合成》
He Y, Luan J, Wang Y, PAMA-TTS: Progression-Aware Monotonic Attention for Stable Seq2Seq TTS With Accurate Phoneme Duration Control, ICASSP 2022
业务应用:提升小爱同学语音合成流畅度与稳定性。
算法设计如下图所示:
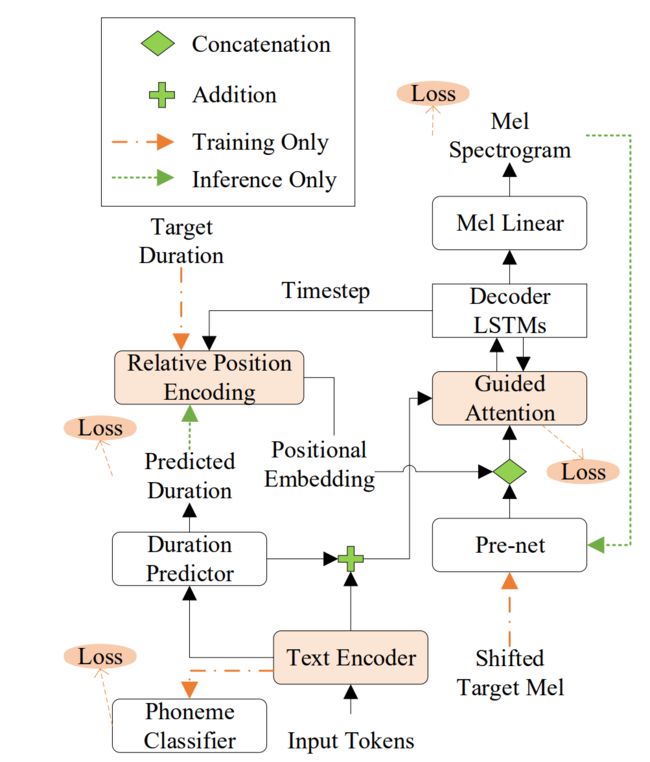
在序列到序列的语音合成中,在编码器和解码器之间进行序列扩展是是一项有挑战性的任务。虽然基于注意力机制的方式取得了不错的自然度,但会使得合成语音不稳定,带来丢字或重复等问题,更不用说用于精确控制时长。与之相反,基于时长的方法看上去可以轻松的音素时长进行控制,然而这往往会导致明显的合成自然度下降。
本文提出了PAMA-TTS模型来解决这些问题。PAMA-TTS模型即利用了注意力机制的灵活性,又利用显示的时长信息。同时,以单调注意力机制为基础,PAMA-TTS也对每一帧的倒计时信息加以利用,例如,某一帧到当前音素发音结束还剩余多少帧。这些策略能帮助注意力模块计算得到的对齐信息以一种受控的方式沿着序列的向前移动,这一控制是一种软性的限制,同时也是可靠的。一些实验也证实了PAMA-TTS能够取得更高的自然度,同时在时长控制能力上,也比基于时长的方式更加优异。
PAMA-TTS实现了时长可控语音合成,为小米打造虚拟人,实现发音嘴型跟合成声音同步,奠定了技术支持。
>>>>
合成样音抢先听:
03
▍《使用SUS约束的VAE和聚合文本编码器提升情感化语音合成》
Yang F, Luan J, Wang Y, Improving Emotional Speech Synthesis by Using SUS-Constrained VAE and Text Encoder Aggregation, ICASSP 2022
业务应用:提升小爱同学语音合成的情感化。小爱同学是第一个使用情感化语音合成的语音助手。
算法设计如下图所示:
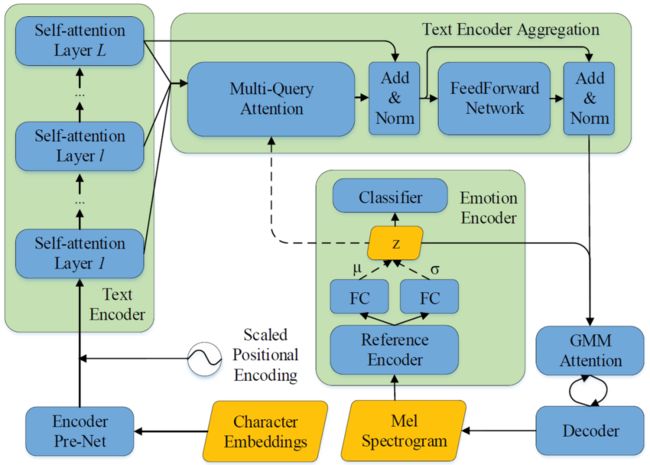
本文利用SUS(the Surface of the Unit Sphere)约束的VAE(Variational AutoEncode)和聚合的文本编码器提升了情感语音合成的效果。该模型在广被应用的端到端模型Tacotron的基础上,利用SUS约束的VAE获得了更好的情感表征,并将该表征和文本表征一起作为查询加入到了聚合的文本编码器中,实验证明提出的方法能合成出更富有表现力的情感语音,为小爱同学的情感语音合成提供了技术支持。
>>>>
合成样音抢先听:
04
▍《使用正交正则化学习特征分解》
Wang L, Gu R, Zhuang W, Gao P, Wang Y, Zou Y, Learning Decoupling Features Through Orthorgonality Regularization, ICASSP 2022
业务应用:提升手机个性化语音唤醒性能、降低小爱“句中”误唤醒率,保障语音唤醒质量。
算法设计如下图所示:

关键词识别和说话人识别的多任务模型可以应用于小米手机和AIoT的各种设备上,一方面可以简化现有系统架构,减少资源占用,另一方面也可以获得更好的性能。本文论述了在个性化语音唤醒任务上,设计基于正交性正则化的个性化语音唤醒算法。
我们创新性地利用正交性正则化来约束模型解耦关键词信息和说话人信息,设计双分支神经网络,浅层网络共享参数提取两个任务共有的特征,深层网络分别进行关键词识别和说话人验证。在开源数据集上达到了start-of-the-art水平,在小米内部业务数据集上也有性能提升。2021年小米集团技术委的语音唤醒取得了集团质量二等奖、小爱的语音唤醒性能在2021年有了极大的改善。
05
▍《利用伪强标签提升大规模弱监督声音标签》
Dinkel H, Yan Z, Wang Y, Zhang J, Wang Y, Pseudo Strong Labels For Large Scale Weakly Supervised Audio Tagging, ICASSP 2022
业务应用:提升小米闻声的性能。
类比视觉标签,算法设计如下图所示:
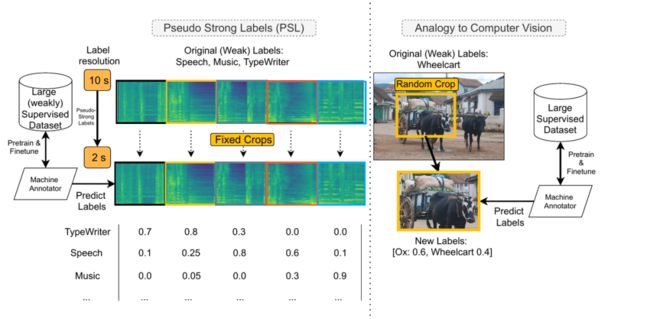
语音是声音成分的一种,想要在语音识别和语音生成这些任务上取得好性能,除了需要对语音精细建模,也离不开对声音空间的全面掌握。这是语音信号处理一直以来的基本思路。随着预训练技术在语音任务中越来越多的应用,语音社区对声音的先验知识的描述越来越重视。
这项研究利用预训练的“机器标注器”,更加细致的针对声音内容重打标签,利用声音内容里不含精确时间信息的标签对数据进行重新理解,形成了有精确时间信息的伪强标签数据。利用这些有精细化标签重新训练模型,可以提升语音VAD的准确度、发现语音误唤醒。该方法被应用在小米闻声中,声音判断的精度从70.76%提升到88.74%。
06
▍声学方向论文:《基于i-vector输入的语音质量评价模型》
Miao Liu, Jing Wang, Shicong Li, Fei Xiang, Yue Yao, Lidong Yang, MOS Predictor For Synthetic Speech With I-vector Inputs, ICASSP 2022
业务应用:填补手机通话业务线上质量评估空白。
语音质量是通信业务的核心体验,线上质量监控是通信领域数十年的行业难题。基于此,我们结合信号处理和心理听觉的语音感知机理,利用深度学习方法分析传输路径特征信息,设计了一种可以用于线上业务的实时无参考语音通话质量评估方法,实现对语音通信质量进行实时评分。
经过全面测试验证,此算法与国际广泛采用的有参考语音质量标准ITU-T P.863(POLQA)的评价结果相关度达到95%以上,并且对手机通话、微信视频、多方会议、电商直播、游戏对战等多种通信场景具有广泛的适应性。同时,该项技术可在汽车、手机、可穿戴、智能家电、PC等智能终端快速部署,通过实时监控语音通信业务质量全方位提升语音通话体验,有效填补行业空白。
在这篇论文中,小米探索了i-vector在无参考质量评价领域应用的可能性,证明了i-vector中包含了丰富的语音质量信息,i-vector的输入有助于提高基于神经网络的评价模型的检测性能。实验结果无参考质量评价对比有参考评价,MSE从0.088下降到0.029。当前,我们的预研项目是在接收端做的下行质量评估,主要用来评估经过编解码损伤和网络损伤后的得分,后续会扩展到在发送端做的上行质量评估,用来评估数据录制、信号处理算法的质量得分。

07
▍one more thing 彩蛋:小米“自由说”系统在MISP(基于多模态信息的语音处理)挑战赛中获得多模态语音唤醒第一名和多模态语音识别第二名,并受邀在今年5月的全球会议上向工业界和学术界进行方案报告。
业务应用:多模态语音交互。
ICASSP 2022中的MISP(基于多模态信息的语音处理)挑战赛,是国际语音声学领域顶级会议ICASSP下属的语音信号处理挑战赛,由来自中科大、乔治亚理工和卡内基梅隆大学等知名学府的教授联合举办,旨在促进复杂场景下音视频多模态信息交互的技术进步。比赛分为音视频多模态唤醒和音视频多模态识别两个赛道。由于要判别语音的内容需要同时解决混响、噪声和多人说话问题,比赛难度非常高。
为此,小米AI实验室语音组、Daniel Povey新一代语音团队和视觉组的工程师们组成联合团队,共同设计了参赛系统——小米“自由说”,取得了赛道一冠军和赛道二亚军的优异成绩,并受邀于今年5月在新加坡举办的全球会议上向工业界和学术界进行方案报告。
小米工程师们分析了两个赛题的关键,针对性的提出了专业的解决方案。对于多模态语音唤醒赛道,团队提出了业界领先的两阶段唤醒算法,包含一个多通道异构端到端唤醒模型和一个混淆词判别模型,其中多通道模型巧妙的利用了丰富的阵列声学特性,而混淆词判别模型则采用了我们首席语音科学家Daniel Povey提出的Alignment-Free Lattice-Free MMI模型,最终取得了最高的分数。

赛道1 音视频多模态唤醒 系统流程图
在多模态语音识别赛道,首要解决的是严重的说话人混叠问题,其次是混响和噪音对于语音识别的干扰问题。团队利用传统分离方法和深度神经网络分离模型相结合的算法,从嘈杂信号中分离出目标说话人的语音,再采用音视频多模态联合学习的算法进行识别,创新性地在端到端模型中采用了首席语音科学家Daniel Povey提出了K2解码方式,大大提高了解码效率和识别精度。
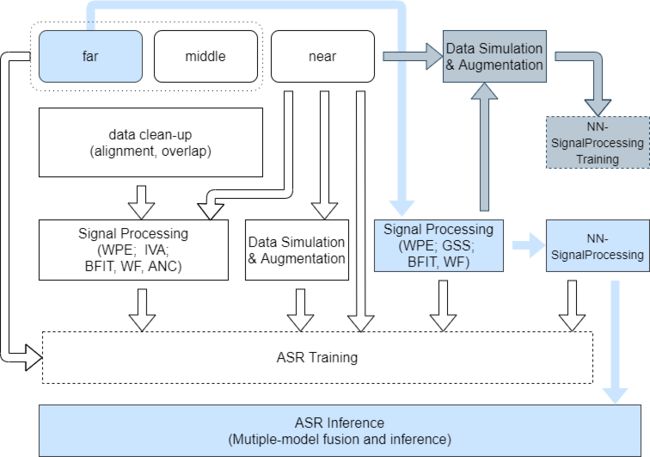
赛道2 音视频多模态识别 系统流程图
08
▍ 总 结
随着人工智能技术的发展,语音交互提供了更自然、更便利、更高效的沟通形式,成为最主要的人机互动接口之一。此次,小米语音、声学取得了优异的成绩,离不开小米工程师们在实际业务中扎实的技术积累,将实践中总结的技术进步向业界和学术界进行回馈,共同促进AI技术的繁荣和发展。
在语音领域,小米语音团队在2017年开始在学术顶会发表重要论文,并在TTS(语音合成)全面自研以及在合成的韵律、个性化、以及情感这三个方面实现了重大的突破;智能生活助理小爱同学的声音定制效果、合成流畅度与稳定性、合成的情感化都有显著提升。
同时,我们在语音唤醒和预训练方面进行了深入研究,提升了手机个性化语音唤醒和小米闻声的性能,降低了小爱误唤醒率,保障了语音唤醒的质量,受到ICASSP的审稿人的高度评价。
在声学领域,小米声学团队致力于AI声学技术的研究及工程落地,为小米手机及IoT全生态硬件产品打造业界领先的音频体验。目前AI通话降噪、协同唤醒、协同放音、空间音频等技术已在手机、电视、小爱、耳机等60余款产品中落地。4年来累计过审专利已达123项。
未来,小米将不断探索科技新高度,为大家带来更多黑科技,让更多人享受科技带来的美好生活。
END

