MMDetection的学习笔记(V2.25.2)
学习资料
A. MMDet组件整体介绍
【博文】《轻松掌握 MMDetection 整体构建流程(一)》
系统性地介绍了MMDet中的各种组件,例如:Backbone, Neck, Head和Enhance等等。
1 安装
新建conda环境:openmmlab
conda create --name openmmlab python=3.10 -y
使用国内镜像安装mim
pip install -U openmim -i https://pypi.tuna.tsinghua.edu.cn/simple
Note: -U即--upgrade,表示安装指定包最新可用的版本。
用mim安装mmcv
mim install mmcv-full
使用国内镜像进行安装
mim install mmcv-full -i https://pypi.tuna.tsinghua.edu.cn/simple
Note:
如果直接使用mim命令安装,出现超时现象:
raise ReadTimeoutError(self._pool, None, “Read timed out.”)
pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host=‘files.pythonhosted.org’, port=443): Read timed out.
可以开启全局代理后再进行安装。
如果mim安装出现重复下载多个mmcv-full版本的问题,改用pip安装
Mmcv官方安装文档:《MMCV文档 | 安装 MMCV》
安装CPU平台的MMCV
pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cpu/torch_version/index.html
例如:安装基于torch1.12.1版本CPU平台的MMCV,
pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cpu/torch1.12.1/index.html
编译,同时使用豆瓣源安装依赖
pip install -v -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
2 目录结构
configs:配置文件目录,例如:configs/centernet/centernet_resnet18_dcnv2_140e_coco.py。
3 CookBook
3.1 Basics
Epoch:从1开始计数
3.2 模型训练
CPU训练:tools/train.py
示例:
python tools/train.py configs/centernet/centernet_resnet18_dcnv2_140e_coco.py
单GPU训练:tools/train.py
python tools/train.py \
CONFIG_FILE \
[optional arguments]
多GPU训练:tools/dist_train.sh
bash ./tools/dist_train.sh \
${CONFIG_FILE} \
${GPU_NUM} \
[optional arguments]
CONFIG_FILE:模型配置
GPU_NUM:显卡数量
3.2 日志分析:tools/analysis_tools/analyze_logs.py
绘制参数曲线 — plot_curve
python tools/analysis_tools/analyze_logs.py plot_curve $LOG_FILE [--keys ${KEYS}] [--eval-interval ${EVALUATION_INTERVAL}] [--title ${TITLE}] [--legend ${LEGEND}] [--backend ${BACKEND}] [--style ${STYLE}] [--out ${OUT_FILE}]
LOG_FILE:日志的.json文件,示例如下,
./work_dirs/config_name/yyyymmdd_hhmmss.log.json
--keys ${KEYS}:打印的参数名关键字,例如:bbox_mAP
--out ${OUT_FILE}:输出图像的文件名,例如:mAP.png
--title ${TITLE}:图像标题
Note
plot_curve会根据输出文件名,自动生成该格式的图像文件,这一点跟OpenCV的imwrite()是类似的。
使用plot_curve比较两个模型的运行指标
python tools/analysis_tools/analyze_logs.py plot_curve log1.json log2.json --keys bbox_mAP --legend run1 run2
Legend:图例
4 配置文件:model_backbone_epoch_*.py
可以使用 Config View(VSCode插件)来查看完整的配置参数;

4.1 workflow:工作流程
示例说明:当配置为workflow = [('train', n),('val', 1)],表示先进行n个epoch的训练,然后再进行1个epoch的验证,然后循环往复,如果写成 [(‘val’, 1),(‘train’, n)] 表示先进行验证,然后再开始训练。
4.2 model:模型
4.2.1 model.backbone:主干网络
(1) backbone.type:主干网络的类名
属于mmdetection/mmdet/models/backbones/__init声明的类之一;
其它参数则是传入到backbone构造函数中的形参;
(2) frozen_stages:在训练时冻结的stages
例如:ResNet 结构包括 stem + 4-stages,
- frozen_stages=-1,表示全部可学习
- frozen_stages=0,表示stem权重固定
- frozen_stages=1,表示stem和第一个stage权重固定
- frozen_stages=2,表示stem和前两个stage权重固定
自定义主干网络
关于自定义网络,可以参考mmdet的官方文档;
| ResNet | 主干网络class |
|---|---|
__init__() |
初始化函数 |
forward() |
前向运算函数 |
3.2 data:数据读取
data.samples_per_gpu
每个GPU上载入的样本数量。
data.train:训练数据
train.dataset:数据集设置train.dataset.type:属于mmdetection/mmdet/datasets声明的类之一,例如:CocoDataset;train.dataset.ann_file:train标注.json文件;train.dataset.img_prefix:训练图像文件夹;train.dataset.pipeline:训练预处理流程;train.dataset.filter_empty_gt:False表示不会过滤无标注图像;
Note
在默认设置下,(未使用filter_empty_gt=False的情况),在dataset读数据的时候过滤掉无标注图像的图像,使用“fliter data”的操作过滤掉这些图像样本,不参加训练。
3.3 lr_config:学习率设置
3.3.1 policy:学习率策略
step:表示StepLrUpdaterHook
在使用epoch设置训练周期的情况下,step填入的参数以epoch计数;
3.4 optimizer_config:优化器设置
Centernet_dcnv2使用了默认的优化器设置:[SGD]

优化器的类名也会与type的名称保持一致,可以在对应文件夹中查找;
3.5 checkpoint_config:检查点设置
例如:checkpoint_config = dict(interval=1)
表示每间隔1个epoch保存一次;
3.6 log_config:日志设置
log_config.interval:每间隔n次输出一次状态信息;
5 常用命令
单GPU训练:[mmdet-doc]
# CONFIG:模型配置文件
python tools/train.py ${CONFIG}
6 数据增广:data_pipeline
关于每个数据增广操作对数据结构具体的更新情况,请参考《MMDet-doc | Data loading》
5.1 Expand:搭配Resize使用实现缩放效果
关于Expand的效果图,请参考《mmdetection中数据增强的可视化 | 八、Expand》
5.2 RandomFlip:随机翻转图像
Note:
如果想要停用RandomFlip操作,不能直接在代码中注释掉,而需要将flip_ratio设成0,即flip_ratio=0.0,注意这里用的是0.0,因为函数要求flip_ratio参数是float格式。
5.3 自定义增广操作:[mmdet-CustomizeDataPipelines]
关于自定义增广操作的示例,可以参考《数据增强神器 SimpleCopyPaste 支持全流程》
7 自定义数据集 [mmdet]
示例标注:
'images': [
{
'file_name': 'COCO_val2014_000000001268.jpg',
'height': 427,
'width': 640,
'id': 1268
},
...
],
'annotations': [
{
'segmentation': [[192.81,
247.09,
...
219.03,
249.06]], # if you have mask labels
'area': 1035.749,
'iscrowd': 0,
'image_id': 1268,
'bbox': [192.81, 224.8, 74.73, 33.43],
'category_id': 16,
'id': 42986
},
...
],
'categories': [
{'id': 0, 'name': 'car'},
]
自定义数据集代码示例:
# 定义数据集字典
coco_output = {
"images": [],
"categories": [],
"annotations": []
}
categories = [{"id": 1, "name": "..."},]
8 MMDet模块化设计原理
8.1 Config:实现字典与类属性的自动转换
MMDet知乎教程:《MMCV 核心组件分析(四): Config》
8.1.1 通过dict生成config
cfg = Config(dict(a=1, b=dict(b1=[0, 1])))
# 可以通过 .属性方式访问,比较方便
cfg.b.b1 # [0, 1]
8.2 Registry:实现type字符串到模块类名的自动映射
Registry – mmcv:用于接收字典参数进行模块构造的工厂类。
关于Registry实现原理的介绍,请参考MMLab视频教程《社区开放麦#9 | OpenMMLab 模块化设计背后的功臣》
Registry机制实现了type字符串到模块类名的自动映射,而不需要手动填写字典条目,即:
self._module_dict[cls_obj.__name__] = cls_obj
8.2 Hook:实现训练过程的非侵入式功能扩展
MMDet-1.0版本的Hook点位如图所示
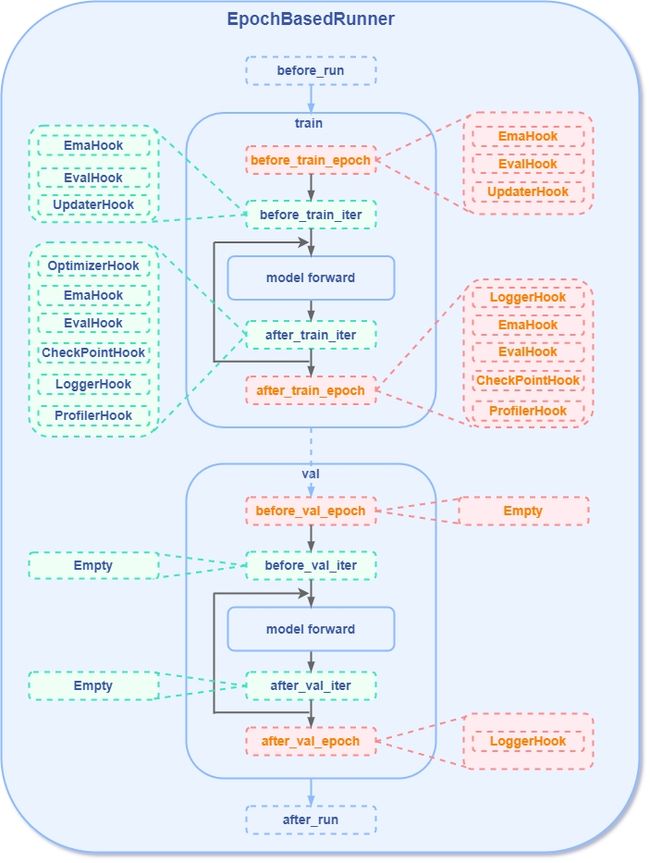
MMLab-2.0版本中对Hook整体结构的设计进行了一定的更新,这里我们咨询了MMDet的叶老师:
叶老师:首先 1.0-val 里的点位,在实际训练的过程中是很多是走不到的,因为验证会调用Evalhook,而在 Evalhook 里再去调用别的hook也不合适。其次2.0中,除了图示里提到的点位(train和val的点位都会起作用),还新增了一些点位,例如 before_train, after_load_checkpoint 等;
具体差异可以参考https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/migration/hook.md
Hook函数说明
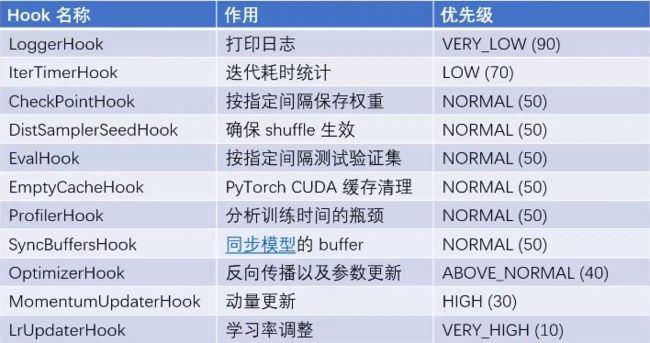
IterTimerHook:用于计时的Hook类
IterTimerHook: [mmcv/runner/hooks/iter_timer.py]
IterTimerHook的计时功能最终会在EpochBasedRunner的train()函数中调用,来输出每个iteration计算时长:
def train(self, data_loader, **kwargs):
...
for i, data_batch in enumerate(self.data_loader):
self.data_batch = data_batch
self._inner_iter = i
self.call_hook('before_train_iter')
self.run_iter(data_batch, train_mode=True, **kwargs)
self.call_hook('after_train_iter')
# iter_timer_hook.after_iter()会在after_train_iter中被调用
del self.data_batch
self._iter += 1
self.call_hook('after_train_epoch')
self._epoch += 1
8.3 训练和测试整体代码抽象流程
8.3.1 训练和验证整体流程
MMDet知乎教程:《轻松掌握 MMDetection 整体构建流程(二):训练和测试流程深入解析》
训练脚本:tools/train.py

- 初始化配置
cfg = Config.fromfile(args.config)- 初始化 logger
logger = get_root_logger(log_file=log_file, log_level=cfg.log_level)- 收集运行环境并且打印,方便排查硬件和软件相关问题
env_info_dict = collect_env()- 初始化 model
model = build_detector(cfg.model, …)- 初始化 datasets
datasets = [build_dataset(cfg.data.train)]- 进入训练器函数流程
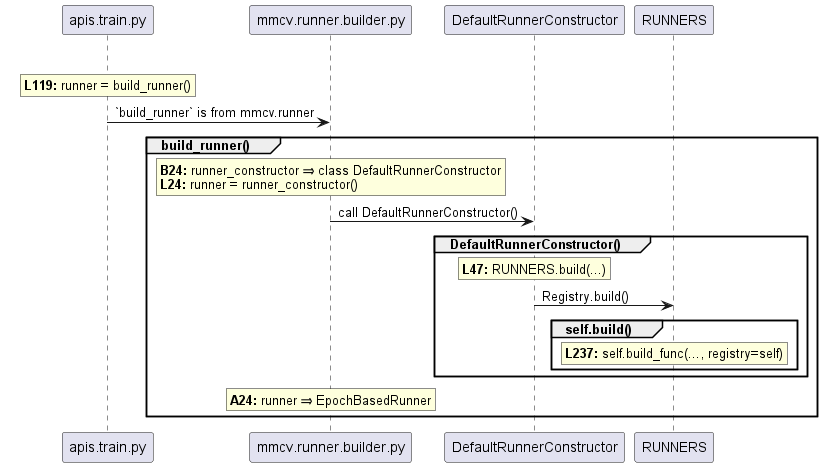
train_detector(model, datasets, cfg, distributed=distributed, …)
train_detector是训练检测器的流程函数,在文件起始处的声明为
from mmdet.apis import init_random_seed, set_random_seed, train_detector
根据import语句引用路径,跟踪到 train_detector是位于mmdet/apis/train.py文件中的函数;
MMDet核心逻辑实现: mmdet/apis/train.py
- 构造 data_loaders,内部会初始化 GroupSampler
data_loaders = [build_dataloader(ds, **train_loader_cfg) for ds in dataset]- 查看是否使用分布式训练,初始化对应的 DataParallel
- 初始化 runner,一般常用的就是
EpochBasedRunner
runner = build_runner(…)
mmcv.build_runner(…) ⇒ runner_constructor() ⇒ runner = dict(type=‘EpochBasedRunner’, …)- 注册hooks
runner.register_training_hooks(…, custom_hooks_config=cfg.get(‘custom_hooks’, None))- 如果在训练中进行val,则还需要注册
eval_hook
runner.register_hook( eval_hook(val_dataloader, **eval_cfg), priority=‘LOW’)- 权重恢复和加载 [source]
- 运行,开始训练
runner.run(data_loaders, cfg.workflow)- Runner.run()即是EpochBasedRunner.run()
Build runner调用过程示意图
Runner训练和验证流程:EpochBasedRunner.run()
EpochBasedRunner.run()在内部会调用self.train();之后即是Model具体的训练流程,如图所示,
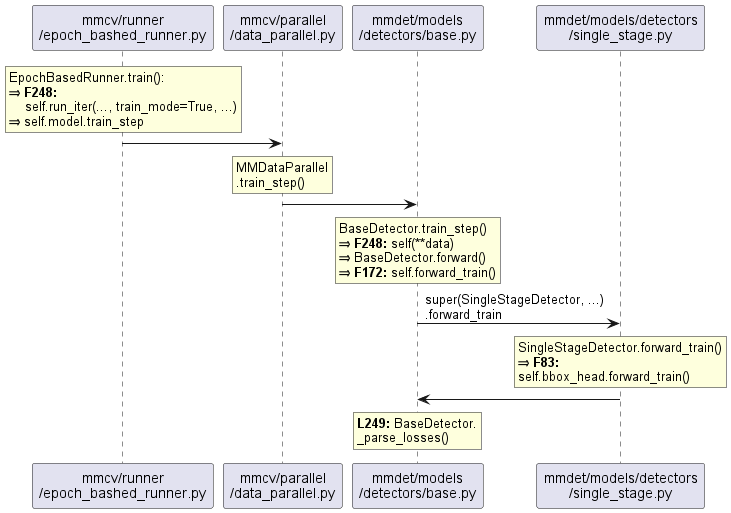
BaseDetector: train_step() | val_step()
其核心代码如下所示:[mmdet/models/detectors/base.py::BaseDetector]
def train_step(self, data, optimizer):
# 调用本类自身的 forward 方法
losses = self(**data)
# 解析loss:内部包含了求和操作
loss, log_vars = self._parse_losses(losses)
# 返回字典对象
outputs = dict(
loss=loss, log_vars=log_vars, num_samples=len(data['img_metas']))
return outputs
def forward(self, img, img_metas, return_loss=True, **kwargs):
if return_loss:
# 训练模式
return self.forward_train(img, img_metas, **kwargs)
else:
# 测试模式
return self.forward_test(img, img_metas, **kwargs)
# forward_train()和forward_test()需要在子类检测器中实现,
# 两个函数会在对应模式下输出结果:
# forward_train() ⇒ Loss
# forward_test() ⇒ 预测结果
SubDetector: forward_train()
目前提供了两个检测器子类,TwoStageDetector和SingleStageDetector,分别用于实现 two-stage 和 single-stage 算法。
其中,CenterNet是基于SingleStageDetector实现的,所以这里我们介绍一下SingleStageDetector的前向训练过程:[mmdet/models/detectors/single_stage.py::SingleStageDetector]
def forward_train(...):
super(SingleStageDetector, self).forward_train(img, img_metas)
# 先经过 backbone + neck 进行特征提取
x = self.extract_feat(img)
# 调用 bbox_head的 forward_train()方法
losses = self.bbox_head.forward_train(x, ...)
return losses
8.3.2 测试流程
- 调用
MMDataParallel或MMDistributedDataParallel中的forward()方法 - 调用
base.py中的forward()方法 - 调用 base.py 中的 self.forward_test 方法
- 如果是单尺度测试,则会调用
TwoStageDetector或 SingleStageDetector 中的 simple_test方法,如果是多尺度测试,则调用 aug_test 方法 - 最终调用的是每个具体 Head 模块的
simple_test()或者aug_test()方法(one-stage和 two-stage的head调用逻辑有些区别)
Note:在MMDet中,检测器算法解码操作的核心逻辑是在Head中实现,具体则是在simple_test()或aug_test()方法中编写。
8.4 Head:模型结构+损失函数+后处理
MMDet知乎教程:《轻松掌握 MMDetection 中 Head 流程》
8.4.1 训练流程
上文说到SingleStageDetector会调用self.bbox_head.forward_train(),它是Head模块在训练流程中最外层的接口函数;
于是,我们先看看CenterNetHead类的集成关系图:

可以看到CenterNetHead是直接继承于BaseDenseHead;
BaseDenseHead
BaseDenseHead基类比较简单,于是,anchor-based 和 anchor-free 算法会进一步继承派生,得到AnchorHead或者 AnchorFreeHead 类;
对于BaseDenseHead.forward_train():
def forward_train(self,
x,
img_metas,
gt_bboxes,
gt_labels=None,
gt_bboxes_ignore=None,
proposal_cfg=None,
**kwargs):
# 调用子类实现的forward()方法
outs = self(x)
if gt_labels is None:
loss_inputs = outs + (gt_bboxes, img_metas)
else:
loss_inputs = outs + (gt_bboxes, gt_labels, img_metas)
# 调用子类实现的loss()方法
losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
if proposal_cfg is None:
return losses
else:
# two-stage算法还需要返回proposals
proposal_list = self.get_bboxes(*outs, img_metas=img_metas, cfg=proposal_cfg)
return losses, proposal_list
子类Head一般不会重写forward_train(),但是它们都会重写forward()和loss()方法,其中:
6. forward()方法用于运行head网络部分输出分类回归分支的特征图;
7. loss()方法接收forward()输出,并且结合label计算loss值。
AnchorHead训练
Note: TTFHead直接继承于AnchorHead;
对于AnchorHead,其主要是封装了anchor的生成过程。首先我们看看forward()函数的主要逻辑:
@HEADS.register_module()
class AnchorHead(BaseDenseHead, BBoxTestMixin): # BBoxTestMixin 是多尺度测试时候调用
def forward(self, feats):
# 对每张特征图单独计算预测输出
return multi_apply(self.forward_single, feats)
# 单尺度分支的分类回归输出
def forward_single(self, x):
cls_score = self.conv_cls(x)
bbox_pred = self.conv_reg(x)
return cls_score, bbox_pred
Loss计算的时序关系图

[mmdetv2-view/pumls/head_scope.puml]
8.4.2 测试流程
前面说过在测试流程中,最终会调用 Head 模块的 simple_test()或aug_test()方法分别进行单尺度或多尺度测试,涉及到具体代码层面,one-stage 和 two-stage 的函数调用有区别,但最终调用的依然是Head模块的get_bboxes()方法;
AnchorHead测试
One-stage检测器在单尺度模式下,会直接调用self.bbox_head.get_bboxes()方法;
其中,基于AnchorHead实现的调用流程是:
- 遍历每个特征尺度输出分支,利用
nms_pre配置参数对该层预测结果按照scores值进行从大到小进行topk截取,保留scores最高的前nms_pre的预测结果; - 对保留的预测结果进行bbox解码还原操作;
- 还原到最原始图片尺度;
- 如果需要进行nms,则对所有分支预测保留结果进行统一nms即可,否则直接属于多尺度预测结果。
多尺度测试
除了RPN算法的多尺度测试是在mmdet/models/dense_heads/rpn_test_mixin.py中实现外,
其余 Head 多尺度测试都是在mmdet/models/dense_heads/dense_test_mixins.py::BBoxTestMixin中实现,其思路是对多尺度图片中每张图片单独运行get_bboxes(),然后还原到原图尺度,最后把多尺度图片预测结果合并统一进行nms。
BBox编解码
关于MMDet中RetinaNet的编解码操作,请参考《轻松掌握 MMDetection 中常用算法(一):RetinaNet 及配置详解》
9 函数和类说明
mmdet.apis:mmdet的核心函数
apis.train_detector():训练过程主要函数
train_detector()内部会调用runner.run()来执行主要的训练过程。
参数说明:
model:检测器。dataset:数据集对象。
变量说明:
cfg:【Config】配置信息对象。
Cfg:配置信息
Cfg.runner:运行信息字典

9.2 mmdet.runner:运行脚本库
Runner.EpochBasedRunner
[EpochBasedRunner from mmcv/runner/epoch_based_runner.py]
run():进行一次workflow指定的训练过程
变量说明:
epoch_runner:【EpochBasedRunner.Method】对应self.train() | self.val()函数。
9.3 Head:CenterNetHead

继承关系:nn.Module ⇒ mmcv.*.BaseModule ⇒ mmdet.*.BaseDenseHead ⇒ CenterNetHead
10 提交PR
请参考博文《【MMDet】提交PR的学习笔记》
11 MMDet-docs调试笔记
MMDet-docs在调试时,其python环境是可以单独配置的;
关于配置MM-docs编译环境的教程,请参考[MMEngine | Build Documentation]
不过在调试过程中,遇到了编译不成功的问题,
正在运行 Sphinx v4.0.2
创建输出目录… 完成
myst v0.18.1: MdParserConfig(commonmark_only=False, gfm_only=False, enable_extensions=[‘colon_fence’], disable_syntax=[], all_links_external=False, url_schemes=(‘http’, ‘https’, ‘mailto’, ‘ftp’), ref_domains=None, highlight_code_blocks=True, number_code_blocks=[], title_to_header=False, heading_anchors=3, heading_slug_func=None, footnote_transition=True, words_per_minute=200, sub_delimiters=(‘{’, ‘}’), linkify_fuzzy_links=True, dmath_allow_labels=True, dmath_allow_space=True, dmath_allow_digits=True, dmath_double_inline=False, update_mathjax=True, mathjax_classes=‘tex2jax_process|mathjax_process|math|output_area’)
Traceback (most recent call last):
File “/home/***/mmdetection/docs/en/./stat.py”, line 31, in
assert len(_papertype) > 0
AssertionError
构建 [mo]: 0 个 po 文件的目标文件已过期
构建 [html]: 29 个源文件的目标文件已过期
更新环境: [新配置] 已添加 29,0 已更改,0 已移除
阅读源… [ 3%] 1_exist_data_model
Extension error (sphinx_markdown_tables):
Handlerfor event ‘source-read’ threw an exception (exception: init() takes 2 positional arguments but 3 were given)
make: *** [Makefile:20:html] 错误 2
我们已经在 MMDet-Github-Discussions上提出了问题“Docs making error: mmdet/docs/en/./stat.py", line 31, in assert len(_papertype) > 0 AssertionError #9029”,不过目前还没有收到回复;
12 学习笔记
10.1 MMDet中有的import语句引入多个关键字时加了“()”,例如:“from … import (DistSamplerSeedHook, EpochBasedRunner, …)”,这是什么特殊的用法吗?
关于import导入时加入小括号的作用,请参考博文《python导入时小括号大作用》
简单来说,其原因是:有时需要导入的函数比较多,会超过一行80个字符的PEP建议。于是PEP建议使用标准分组机制,也就是用小括号括起来,例如: from os import (name,getcwd)这种方式,就可以分成多行了。