姿态估计之2D人体姿态估计(1)(仅供个人参考)
参考
- 自顶向下的 2D 人体姿态估计 - 知乎
- 人体姿态估计(Human Pose Estimation)经典方法整理 - 知乎
- 2D人体姿态估计浅析 - 知乎
- 人体姿态估计中回归出了heatmap如何去计算关键点的坐标位置? - 知乎
- 论文阅读 - Deep High-Resolution Representation Learning for Human Pose Estimation
- 【HRNet】《Deep High-Resolution Representation Learning for Human Pose Estimation》
- 2D 多人姿态估计论文汇总、分类与简介(2022.02.17发布) - 知乎
第一部分 参见 姿态估计之2D人体姿态估计(1)
第二部分 参见 姿态估计之2D人体姿态估计(2)
0 前言
2D Human Pose Estimation (以下简称 2D HPE) 旨在从图像或者视频中预测人体关节点(或称关键点,比如头,左手,右脚等)的二维空间位置坐标。2D HPE 的应用场景非常广泛,包括动作识别,动画生成,增强现实等。传统的 2D HPE 算法,设计手工特征提取图像信息,从而进行关键点的检测。
当前主流的 2D HPE 方法主要可以分为自底向上(bottom up)和自顶向下(top down)两种方式。自底向上的方法同时预测图片中的所有关键点,然后将不同类型的关键点组合成人体。自顶向下的方法首先检测出输入图片中的一个或者多个人,然后对于每个个体单独预测其关键点。自底向上方法的推断时间不随人数的增加而上升,而自顶向下的方法对于不同尺寸的人体更加鲁棒。
在实际求解时,对人体姿态的估计常常转化为对人体关键点的预测问题,即首先预测出人体各个关键点的位置坐标,然后根据先验知识确定关键点之间的空间位置关系,从而得到预测的人体骨架。
对于2D姿态估计,当下研究的多为多人姿态估计,即每张图片可能包含多个人。解决该类问题的思路通常有两种:top-down和bottom-up:
- top-down的思路是首先对图片进行目标检测,找出所有的人;然后将人从原图中crop出来,resize后输入到网络中进行姿态估计。换言之,top-down是将多人姿态估计的问题转化为多个单人姿态估计的问题。
- bottom-up的思路是首先找出图片中所有关键点,然后对关键点进行分组,从而得到一个个人。
通常来说,top-down具有更高的精度,而bottom-up具有更快的速度。top-down的方法将多人姿态估计转换为单人姿态估计,那么网络的输入就是包含一个人的bounding box,网络预测的是人的 k 个关键点坐标。对于关键点的ground truth(对应网络的输出)如何表示有两种思路:
 ,即直接对坐标进行回归,网络的输出是经过fc层输出的2k 个数字
,即直接对坐标进行回归,网络的输出是经过fc层输出的2k 个数字- k个heatmap,即为每个关键点预测一个heatmap作为关键点的中间表示,heatmap上的最大值处即对应关键点的坐标。对于改种方法,heatmap的ground truth是以关键点为中心的二维高斯分布(高斯核大小为超参)
早期的工作如DeepPose多为直接回归坐标,当下的工作多数以heatmap作为网络的输出,这种中间表示形式使得回归结果更加精确。
1. 单人姿态估计——回归方法
共4篇
2014.08_(DeepPose) Human Pose Estimation via Deep Neural Networks
首个使用回归方法的级联网络。
2016.06_(IEF) Human Pose Estimation with Iterative Error Feedback
给定初始姿态,使用迭代的方式归回修正姿态。
2017.08_Compositional Human Pose Regression
将骨架向量和关键点一起考虑进网络。
2017.10_Human Pose Regression by Combining Indirect Part Detection and Contextual Information
取最大值方式不可微,用soft_argmax替换。
2. 单人姿态估计——检测(热图)方法
共7篇
2014.09_Joint Training of a Convolutional Network and a Graphical Model for Human Pose Estimation
开始使用热图检测的方式得到姿态结果。
2015.06_Efficient Object Localization Using Convolutional Networks
是上一篇的扩展。
2016.04_(CPM) Convolutional Pose Machines
每个关键点部位训练一个检测器。
2016.07_(Hourglass) Stacked Hourglass Networks for Human Pose Estimation
堆叠式沙漏结构的级联网络。
2017.02_Multi-Context Attention for Human Pose Estimation
加入了多种注意力机制。
2017.08_Learning Feature Pyramids for Human Pose Estimation
给姿态估计网络加入了多尺度特征金字塔。
2019.02._Cascade Feature Aggregation for Human Pose Estimation
3. 姿态估计——复合方法
共4篇
2016.09_Human pose estimation via Convolutional Part Heatmap Regression
使用先检测后回归的策略。
2018.05_(DSNT) Numerical Coordinate Regression with Convolutional Neural Networks
也是在先检测,再在热图上进行回归,避免不可微操作。
2018.09_Integral Human Pose Regression
也是在先检测,再在热图上进行回归,避免不可微操作。
2021.03_Composite Localization for Human Pose Estimation
先找到近似位置,用预测偏移获取具体位置
4. 多人姿态估计——自上而下
自上而下:先检测人再框出来检测人的姿势
共9篇
2016.08_Multi-Person Pose Estimation with Local Joint-to-Person Associations
2017.04_Towards Accurate Multi-person Pose Estimation in the Wild
2018.02_(AlphaPose) RMPE Regional Multi-person Pose Estimation
2018.04_(CPN) Cascaded Pyramid Network for Multi-Person Pose Estimation
2018.04_Learning to Refine Human Pose Estimation
2018.07_MultiPoseNet: Fast Multi-Person Pose Estimation using Pose Residual Network
2018.08_(Simple Baselines) for Human Pose Estimation and Tracking
2019.01_(CrowdPose) Efficient Crowded Scenes Pose Estimation and A New Benchmark
2019.05_(MSPN) Rethinking on Multi-Stage Networks for Human Pose Estimation
5. 多人姿态估计——自下而上
自下而上:先检测关键点再连接成人的姿势
共12篇
2016.04_(DeepCut) Joint Subset Partition and Labeling for Multi Person Pose Estimation
2017.06_Associative Embedding-End-to-End Learning for Joint Detection and Grouping
2018.11_(OpenPose) Real-time 2D Multi-Person Pose Estimation on CPU: Lightweight OpenPose
2019.04_(PifPaf) Composite Fields for Human Pose Estimation
2019.05_(Openpose) Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
2019.11_(Simple Pose) Rethinking and Improving a Bottom-up Approach for Multi-Person Pose Estimation
2020.03_(HRNet) HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation
2020.06_(HRNet) Bottom-Up Human Pose Estimation by Ranking Heatmap-Guided Adaptive Keypoint Estimates
2020.07_Differentiable Hierarchical Graph Grouping for Multi-Person Pose Estimation
2021.04_(HRNet) Bottom-Up Human Pose Estimation Via Disentangled Keypoint Regression
2021.04_(Lite-HRNet) A Lightweight High-Resolution Network
2021.07_Human Pose Regression with Residual Log-likelihood Estimation
6. 多人姿态估计——单阶段网络
共5篇
2019.08_Single-Stage Multi-Person Pose Machines
2019.11_(DirectPose) Direct End-to-End Multi-Person Pose Estimation
2021.05_(FCPose) Fully Convolutional Multi-Person Pose Estimation with Dynamic Instance-Aware Convolutions
2021.07_(InsPose) Instance-Aware Networks for Single-Stage Multi-Person Pose Estimation
2021.07_(PoseDet) Fast Multi-Person Pose Estimation Using Pose Embedding
7. 姿态估计——多任务学习
共4篇
2018.01_Mask R-CNN
将实例分割与姿态估计合并多任务学习。
2018.03_(PersonLab) Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model
将实例分割与姿态估计合并多任务学习,并取消了box。
2019.05_Multi-task human analysis in still images-2D_3D pose, depth map, and multi-part segmentation
将实例分割与2D姿态估计,3D姿态估计,深度估计合并多任务学习。
2021.08_MultiTask-CenterNet (MCN)-Efficient and Diverse Multitask Learning using an Anchor Free Approach
8. 姿态估计——GAN
共3篇
2017.05_Adversarial PoseNet-A Structure-aware Convolutional Network for Human Pose Estimation
2017.08_Self Adversarial Training for Human Pose Estimation
2021.05_When Human Pose Estimation Meets Robustness-Adversarial Algorithms and Benchmarks
9. 姿态估计——图网络
共3篇
2019.01_Human Pose Estimation with Spatial Contextual Information
2020.03_Peeking into occluded joints A novel framework for crowd pose estimation
2020.07_Graph-PCNN-Two Stage Human Pose Estimation with Graph Pose Refinement
10. 姿态估计——Backbone
共2篇
2019.02_(HRNet) Deep High-Resolution Representation Learning for Human Pose Estimation
一种高分辨率的backbone,更好提取热图
2020.07_(RSN) Learning Delicate Local Representations for Multi-Person Pose Estimation
更好的利用各个尺度的信息。
11. 姿态估计——使用Transformer
共3篇
2020.12_(TransPose) Towards Explainable Human Pose Estimation by Transformer
2021.03_(TFPose) Direct Human Pose Estimation with Transformers
2021.04_Pose Recognition with Cascade Transformers
12. 姿态估计——Refinement
2019.03_PoseFix-Model-agnostic General Human Pose Refinement Network
提出了一种精细网络用于精细姿态结果,是一个插件,后处理方式。
2019.10_(DARK) Distribution-Aware Coordinate Representation for Human Pose Estimation
2021.07_Polarized Self-Attention-Towards High-quality Pixel-wise Regression
2021.07_Adaptive Dilated Convolution For Human Pose Estimation
13. 姿态估计——轻量化
2019.04_Fast Human Pose Estimation
2020.01_Simple and Lightweight Human Pose Estimation
2021.07_(FasterPose) A Faster Simple Baseline for Human Pose Estimation
14. 姿态估计——其他
共15篇
2018.05_Jointly Optimize Data Augmentation and Network Training: Adversarial Data Augmentation in Human Pose Estimation
使用优化的训练技巧提升精度。
2019.04_Spatial Shortcut Network for Human Pose Estimation
2019.05_Multi-Person Pose Estimation with Enhanced Channel-wise and Spatial Information
2019.10_TRB: A Novel Triplet Representation for Understanding 2D Human Body
2020.01_(UniPose) Unified Human Pose Estimation in Single Images and Videos
2020.02_Towards High Performance Human Keypoint Detection
2020.02_Toward fast and accurate human pose estimation via soft-gated skip connections
2020.12_The Devil is in the Details-Delving into Unbiased Data Processing for Human Pose Estimation
2020.12_Efficient Human Pose Estimation by Learning Deeply Aggregated Representations
2020.12_(EfficientPose) Scalable single-person pose estimation
相比openpose,提出准确又快速的模型(但是实际效果很差)
2021.07_Is 2D Heatmap Representation Even Necessary for Human Pose Estimation
13. 姿态估计——Super Resolution
共1篇
2021.07_Super Resolution in Human Pose Estimation-Pixelated Poses to a Resolution Result
8. 姿态估计——无监督
共1篇
2021.05_Unsupervised Human Pose Estimation through Transforming Shape Templates
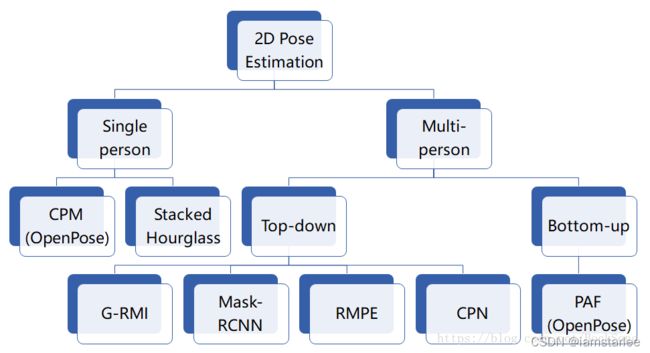
1 主流算法
更多参见 2D人体姿态估计浅析
1.1 基于回归坐标的方法
早期一些自顶向下的深度学习方法用神经网络直接预测人体关键点的 2D 坐标 [1, 2, 3]。

DeepPose [1] 是这类方法的经典代表。DeepPose 采用级联的神经网络来预测人体各个关键点的相对坐标。每一个阶段都拿上一阶段的输出坐标作为输入,并进一步预测更为准确的坐标位置。最终,将预测得到的归一化的相对坐标转换为绝对坐标。
参见
姿态估计之2D人体姿态估计 - DeepPose
1.2 基于热图(heatmap)的方法
近些年,基于热图(heatmap)的人体姿态估计方法成为了主流。基于热图的方法在每个位置预测一个分数,来表征该位置属于关键点的置信度。根据预测的热图,进一步提取关键点的坐标位置。基于热图的方法更好地保留了空间位置信息,更符合卷积神经网络(Convolutional Neural Network, CNN)的设计特性,从而取得了更好的预测精度。
1.2.1 Convolutional Pose Machines(CPM)
Convolutional Pose Machines(CPM)的主要贡献在于:
a) 用Heatmap来表示关节点的位置及位置约束关系,并且将Heatmap和Feature Map同时作为数据在网络中传递,同时在多个尺度处理输入的特征,充分考虑各个关节点之间的空间位置关系。
b) 多个阶段(Stage)有监督训练,避免过深网络难以优化的问题。
OpenPose是GitHub上最受欢迎的人体姿态估计项目(14.8K Stars, 4.2K Folks),其人体关键点检测正是主要基于Convolutional Pose Machines。
Pose estimation是一种全卷积网络,输入是一张人体姿势图,输出n张热力图,代表n个关节的响应。
参见: 姿态估计之2D人体姿态估计 - Convolutional Pose Machines(CPM)
1.2.2 Stacked Hourglass

Stacked Hourglass [6] 通过多尺度特征融合,整合人体结构化的空间关系。该方法连续进行上采样和下采样,并在网络中间利用热图进行监督,提升了网络的性能。
参见:姿态估计之Stakced Hourglass Network(SHN)个人理解_light169的博客-CSDN博客
1.2.3 Cascaded pyramid network for multi-person pose estimation(CPN)
多人 top-down结构
参见:姿态估计之CPN(Cascaded Pyramid Network for Multi-Person Pose Estimation)
CPN,Cascaded Pyramid Network,是2017年旷视提出的一种网络结构,获得了COCO 2017 Keypoint Benchmark的冠军,网络结构如下图所示。这个网络可以分为两部分:GlobalNet和RefineNet,从名字也可以看出后半部分网络是在前半部分的基础上做refinement。GlobalNet的作用主要是对关键点进行一个初步的检测,由于使用了强大的ResNet作为backbone,网络能够提取到较为丰富的特征(在此之前的CPM、Hourglass都没有使用,因此网络的特征提取能力较差),并且使用了FPN结构加强了特征提取,在这个过程中像head、eyes这些简单且可见的关键点基本能够被有效地定位。而对于GlobalNet没有检测到的关键点,使用RefineNet进行进一步的挖掘,RefineNet实际上是将pyramid结构中不同分辨率下的特征进行了一个整合,这样一些被遮挡的、难以定位的关键点,根据融合后的上下文语境信息能够更好的被定位到。
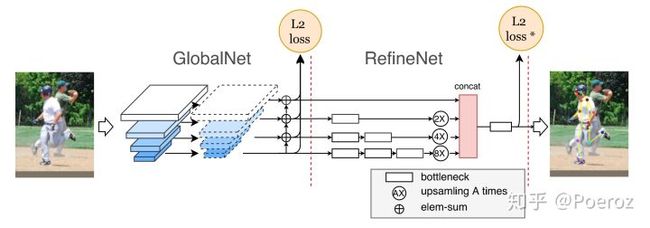
下面这张图给出了一个例子(绿点表示ground truth),对于eye来说较容易定位,通过GlobalNet即可定位到。而对于hip来说,在原图中被遮挡,仅仅使用GlobalNet难以直接精确定位。通过RefineNet将语境信息整合进来,才使得这些关键点被定位

1.2.3 Simple Baseline(SBL)
Simple Baselines,是2018年MSRA的工作,网络结构如下图所示。之所以叫这个名字,是因为这个网络真的很简单。该网络就是在ResNet的基础上接了一个head,这个head仅仅包含几个deconvolutional layer,用于提升ResNet输出的feature map的分辨率,我们提到过多次高分辨率是姿态估计任务的需要。这里的deconvolutional layer是一种不太严谨的说法,阅读源代码可知,deconvolutional layer实际上是将transpose convolution、BatchNorm、ReLU封装成了一个结构。所以关键之处在于transpose convolution,可以认为是convolution的逆过程。
从图中看可以发现Simple Baselines的网络结构有点类似Hourglass中的一个module,但可以发现:①该网络没有使用类似Hourglass中的skip connection;②该网络是single-stage,Hourglass是multi-stage的。但令人惊讶的是,该网络的效果却超过了Hourglass。我个人认为有两点原因,一是Simple Baselines以ResNet作为backbone,特征提取能力相比Hourglass更强。二是Hourglass中上采样使用的是简单的nearest neighbor upsampling,而这里使用的是deconvolutional layer,后者的效果更好(后面可以看到在MSRA的Higher-HRNet中依旧使用了这种结构)。

参见
姿态估计之2D人体姿态估计 - Simple Baseline(SBL)
1.2.4 HRNet Deep High-Resolution Representation Learning for Human Pose Estimation
HRNet [8] 针对人体姿态估计设计了一个高效的网络结构。不同于以往方法利用低分辨率的特征预测高分辨率的热图,HRNet 设计了多个不同分辨率的平行分支。高分辨率特征始终被保持,并且不同尺度的特征能够相互融合。这种设计结合局部纹理特征和全局语义信息,实现了更加准确和鲁棒的姿态预测。
参见:
HRNet详解_gdtop818的博客-CSDN博客_hrnet详解
姿态估计之2D人体姿态估计 - (HRNet)Deep High-Resolution Representation Learning for Human Pose Estimation(多家综合)
1、HRNet网络简介_太阳花的小绿豆的博客-CSDN博客
2、姿态估计】Deep High-Resolution Representation Learning for Human Pose Estimation论文理解
3、HRNet的网络结构---非常详细_枫呱呱的博客-CSDN博客_hrnet网络结构
4、HRNet网络结构 - Dilthey - 博客园


1.2.5 Joint Training of CNN and a Graphical Model for Human Pose Estimation
参见:
1、Joint Training of a Convolutional Network and a Graphical Model for Human Pose Estimation
2、Joint Training of CNN and a Graphical Model for Human Pose Estimation用于姿态估计的CNN和图模型的联合训练
代码:https://github.com/max-andr/joint-cnn-mrf
文章的核心思想
1、利用CNN做姿态估计,采用heatmap的方式来回归出关键点
2、利用人体关键点之间的结构关系,结合马尔科夫随机场的思想来优化预测结果,主要针对于网络预测的false postive。
1.2.6 MSPN
参见:人体姿态估计(Human Pose Estimation)经典方法整理 - 知乎
MSPN,是2019年旷视的工作,网络结构如下图所示。此前我们介绍的网络中,有single-stage的例如CPN、Simple Baselines,也有multi-stage的如CPM、Hourglass,理论上multi-stage的效果应该更好,但实际上在COCO数据集上single-stage的表现超过了multi-stage。MSPN沿用了multi-stage的思路,并做出了一系列改进,最终使得MSPN的效果超过了当前的single-stage网络。
首先,对于每个stage的module,MSPN采用了前面提到的CPN中的GlobalNet(backbone为ResNet)。其次,MSPN增加了跨阶段的特征融合,即图中的黄色箭头。由于经过反复的下采样-上采样,会有不可避免的信息损失,故MSPN中将前一个stage下采样和上采样过程中对应分辨率的两个feature maps都连接过来,与当前stage下采样的feature map进行融合,这样当前stage得到的feature map就包含了更多prior information,减少了stage之间的信息丢失。此外,这种类似残差结构的设计也有助于缓解梯度消失问题。最后,MSPN还采用了coarse-to-fine supervision,我们知道姿态估计的ground truth是以关键点为中心的二维高斯分布,这里的高斯核大小是一个超参数。直观上来说,对于multi-stage网络,随着stage的增加,我们对keypoint的估计是一个coarse-to-fine的过程,这样我们进行intermediate supervision的时候,可以将ground truth也设置成coarse-to-fine的heatmap,也就是前面stage的高斯核较大,后面stage的高斯核较小,随着stage的增加要求关键点位置越来越精确。

1.3 Bottom-up
前面我们提到诸多top-down的方法都是将多人姿态估计转化为单人姿态估计问题,但在进行多人姿态估计时,top-down的方法有两个缺点:①性能受到detector性能的影响(虽然在CPN的论文中证明了当detector性能足够好时提高detector的性能对最后的结果提高很微小);②运行时间随着图片中人数增加而增加。而bottom-up的方法则是另一条思路:先检测出图中所有人的所有关键点,再对关键点进行分组,进而组装成多个人。这种方法的好处是性能受人数影响较小,实际上bottom-up的速度往往会比top-down的更快,几乎能做到real-time,在移动端部署的时候往往采用的也是bottom-up的方法。接下来介绍近年出现的一些有代表性的bottom-up的工作。
1.3.1 Openpose
Openpose是2016年CMU的一个工作,获得了COCO 2016 Keypoints challenge的冠军,这个工作在后来产生了很大的影响,github上目前有15.8k个stars。下图是openpose的pipeline,首先根据输入图片(a)生成一个Part Confidence Maps(b)和一个Part Affinity Fields(c):前者就是我们上文常提到的heatmap,用来预测关键点的位置;后者是本文的一个主要创新点——PAF,PAF实际上是在关键点之间建立的一个向量场,描述一个limb的方向。有了heatmap和PAF,我们使用二分图最大权匹配算法来对关键点进行组装(d),从而得到人体骨架(e)。由于文字描述过于抽象,下面花一些篇幅引用原文中的一些数学表达形式来分别介绍这几部分。

对于生成heatmap和PAF的部分,使用了下图所示的网络结构。首先 F 是初始的feature map,网络的输出是heatmap和PAF,分别用 ![]() 和
和 ![]() 表示,其中 J是part(即上文中的keypoint,这里遵循原文中的说法)的数量, C是limb的数量。
表示,其中 J是part(即上文中的keypoint,这里遵循原文中的说法)的数量, C是limb的数量。 ![]() ,即第j 个part对应的heatmap,每个pixel对应一个响应值,可以认为是概率值;
,即第j 个part对应的heatmap,每个pixel对应一个响应值,可以认为是概率值; ![]() ,即第 c个limb对应的PAF,每个pixel对应一个二维向量,表示该pixel所在limb的方向。二者都是pixel-wise的。这里借鉴CPM使用了多个stage不断进行refinement,后一阶段的输入是前一阶段的S 、L 和初始的F 的结合。
,即第 c个limb对应的PAF,每个pixel对应一个二维向量,表示该pixel所在limb的方向。二者都是pixel-wise的。这里借鉴CPM使用了多个stage不断进行refinement,后一阶段的输入是前一阶段的S 、L 和初始的F 的结合。

接下来需要说明heatmap和PAF的ground truth分别是怎样的。heatmap和top-down中的类似,对于第 k 个人的第 j 个part,令其位置为 ![]() ,则ground truth是以
,则ground truth是以 ![]() 为中心的二维高斯分布,用
为中心的二维高斯分布,用 ![]() 表示。在这里由于一张图片中有多个人,ground truth中的每个channel对应一个part,第 j个part对应的ground truth为
表示。在这里由于一张图片中有多个人,ground truth中的每个channel对应一个part,第 j个part对应的ground truth为 ![]() , p 表示单个位置,即对所有人该part的ground truth按pixel取max。
, p 表示单个位置,即对所有人该part的ground truth按pixel取max。
PAF的ground truth则更加复杂,对于第 k 个人的第 c 个limb(连接关键点![]() 和
和![]() ),ground truth用
),ground truth用 ![]() 表示。如果位置p 在这个limb上,
表示。如果位置p 在这个limb上, ![]() ,否则为零向量。这里
,否则为零向量。这里 实际上是
实际上是 ![]() 指向
指向 ![]() 的单位向量。那么如何判断一个位置 p 是否在当前limb上呢?只要 p满足:①在线段
的单位向量。那么如何判断一个位置 p 是否在当前limb上呢?只要 p满足:①在线段 ![]() 上,②距离线段
上,②距离线段 ![]() 在一个阈值范围内(框处了一个矩形范围),就认为p 在该limb上。最后对于某个limb的所有,按pixel采用average进行处理,即
在一个阈值范围内(框处了一个矩形范围),就认为p 在该limb上。最后对于某个limb的所有,按pixel采用average进行处理,即  ,这里
,这里 ![]() 为 p位置处非零向量的个数,也就是只有非零向量才参与均值计算。此处用到的一些符号在图中含义如下。
为 p位置处非零向量的个数,也就是只有非零向量才参与均值计算。此处用到的一些符号在图中含义如下。

至于loss的计算,就是对每个stage的 S 和 L分别计算L2 loss,最后所有stage的loss相加即可。同样类似之前top-down中提到的,intermediate supervision有助于缓解梯度消失的问题。
现在我们有了heatmap,在heatmap上采用nms可以为每个part找出一系列候选点(因为图中有不止一个人,以及false positive的点),这些候选点之间互相组合能够产生大量可能的limb,如何从中选出真正的limb,这就需要使用我们预测的PAF。首先定义两个关键点![]() 和
和![]() 之间组合的权值
之间组合的权值  ,这里
,这里 ![]() ,
, ![]() 分别表示
分别表示 ![]() 的坐标。实际上就是对
的坐标。实际上就是对 ![]() 和
和![]() 间各点的PAF在线段
间各点的PAF在线段![]() 上投影的积分,直观上说,如果线段上各点的PAF方向与线段的方向越一致,E就越大,那么这两个点组成一个limb的可能性就越大。
上投影的积分,直观上说,如果线段上各点的PAF方向与线段的方向越一致,E就越大,那么这两个点组成一个limb的可能性就越大。
知道了如何计算两个候选点之间组合的权值,对于任意两个part对应的候选点集合,我们使用二分图最大权匹配算法即可给出一组匹配。但如果我们考虑所有part之间的PAF,这将是一个K分图最大权匹配问题,该问题是NP-Hard的。因此我们做一个简化,我们抽取人体骨架的一棵最小生成树,这样对每条树边连接的两个part采用二分图最大权匹配来求解,不同树边之间是互不干扰的。也就是将原问题划分成了若干个二分图最大权匹配问题,最后将每条树边对应的匹配集合组装在一起即可得到人体骨架。

上述即openpose的整个pipeline,虽然看起来比较复杂,但许多想法都是围绕PAF展开的,毕竟PAF还是这篇文章最大的亮点。
参见:
姿态估计之2D人体姿态估计 - (OpenPose) Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
1.3.2 Hourglass+Associative Embedding
Associative embedding,是一种处理detection+grouping任务的方法。也就是先检测再组装的任务,比如多人姿态估计是检测出所有关键点再组装成多个人体,实例分割是先检测出所有像素点的语义类别再组装成多个实例。往往这类任务都是two-stage的,即先detection,再grouping。这篇文章的作者提出了一种新的思路:同时处理detection和grouping两个任务,这么做的初衷是因为detection和grouping两个任务之间本身密切相关,分成两步来先后处理可能会导致性能下降。作者将该方法应用到了Hourglass上,在当时达到了多人姿态估计任务的SOTA。
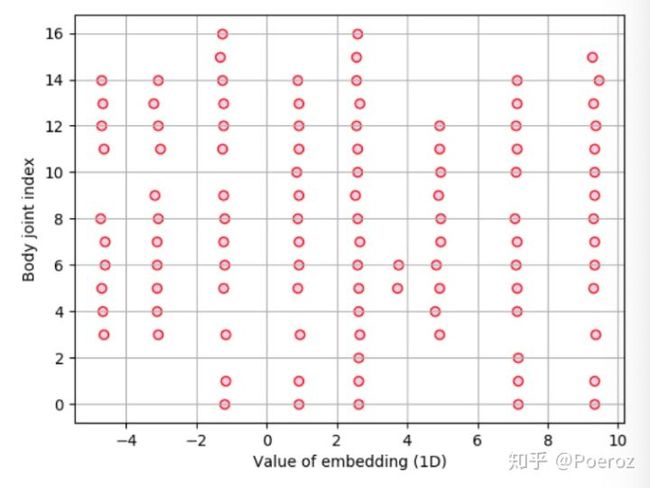
在单人姿态估计时,我们网络的输出是m个heatmap,m表示关键点数量。现在在之前的基础上多输出了m个associative embeddings。Associative embeddings实际上是给heatmap的每个值都额外嵌入一个vector作为一个tag用于标识所在的组,拥有相同tag的所有关键点我们将其划分为一组,也就是属于某一个人。下图是Hourglass+Associative embedding的示意图,Hourglass输出了m个detection heatmaps(灰色)和m个associative embeddings(蓝色),根据heatmaps上的响应值确定关键点的坐标,根据embeddings上的tag(下图中不同tag用不同颜色表示)确定哪些关键点属于同一个人。

现在我们考虑ground truth,对于heatmaps来说和之前一样,不再赘述。对于embeddings来说实际上没有ground truth,因为tag的绝对值并不重要,只要保证同一个人的关键点tag相同,不同人的关键点tag之间互不相同即可。这里需要说明的是,tag虽然是一个vector,但vector的维数并不重要,实践证明1D vector已经足够(即一个实数)。为了使tag满足上述要求,我们需要设计一个loss来评价当前的tag是否符合实际的分组。用 ![]() 表示第 k 个关键点对应的embeddings(tagging heatmap), N表示人的数量, K表示关键点数量,
表示第 k 个关键点对应的embeddings(tagging heatmap), N表示人的数量, K表示关键点数量, ![]() 表示第n个人第 k 个关键点的坐标。我们定义第 n 个人的参考embeddings为
表示第n个人第 k 个关键点的坐标。我们定义第 n 个人的参考embeddings为  ,则loss定义为
,则loss定义为

loss的前半部分使同一个人的所有embeddings尽量接近,后半部分 使不同人的embeddings间隔尽量增大。最后所有关键点的embeddings分布如下图所示。inference时将距离小于一定阈值的embeddings分为一组即可。
1.3.3 HigherHRNet
HigherHRNet,是微软在HRNet之后延续的一个工作。前面我们提到过HRNet在top-down的方法中表现的很好,是因为这种并行的结构使得最后的feature map能够包含各个分辨率的信息,尤其是对高分辨率信息保留的效果较之前提升尤为明显。在bottom-up的方法中,作者认为有两个问题需要解决:①scale variation,即图片中有各种scale的人,如果仅仅在一个分辨率的feature map下进行预测,难以保证每个scale的人的关键点都能被精确预测;②精确定位small person的关键点。之前一些网络在推理时使用multiscale evaluation,能够缓解问题①,但仍然无法解决问题②,对small person的预测不够精确。
HigherHRNet的思路是首先使用HRNet生成feature map(最高分辨率分支),然后接一个类似Simple Baselines中的deconvolution层,生成一个更高分辨率的feature map。显然,更高分辨率的feature map有助于更加精确地定位small person的关键点(实践证明接一层deconv. module足够)。在训练时,使用multi-resolution supervision,即对原图1/4和1/2大小的两个feature map同时进行监督,这样做是为了在训练时就使网络获得处理scale variation的能力,1/4的feature map主要处理大一些的人,1/2的feature map主要处理小一些的人,而不是在推理时依赖multiscale evaluation处理scale variation的问题。在推理时,使用multi-resolution heatmap aggregation,即将不同分辨率的heatmap取平均用于最后的预测,也是为了处理scale variation。

前面仅仅讨论了如何生成一个准确且scale-aware的heatmap,对于grouping采用的也是上文提到的associative embedding。最后这个工作达到了SOTA,是目前bottom-up方法中性能最强劲的网络之一。
参考文献
[1] Toshev, A., & Szegedy, C. (2014). Deeppose: Human pose estimation via deep neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1653-1660).
[2] Carreira, J., Agrawal, P., Fragkiadaki, K., & Malik, J. (2016). Human pose estimation with iterative error feedback. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4733-4742).
[3] Sun, X., Shang, J., Liang, S., & Wei, Y. (2017). Compositional human pose regression. In Proceedings of the IEEE International Conference on Computer Vision (pp. 2602-2611).
[4] Tompson, J. J., Jain, A., LeCun, Y., & Bregler, C. (2014). Joint training of a convolutional network and a graphical model for human pose estimation. Advances in neural information processing systems, 27, 1799-1807.
[5] Wei, S. E., Ramakrishna, V., Kanade, T., & Sheikh, Y. (2016). Convolutional pose machines. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (pp. 4724-4732).
[6] Newell, A., Yang, K., & Deng, J. (2016, October). Stacked hourglass networks for human pose estimation. In European conference on computer vision (pp. 483-499). Springer, Cham.
[7] Xiao, B., Wu, H., & Wei, Y. (2018). Simple baselines for human pose estimation and tracking. In Proceedings of the European conference on computer vision (ECCV) (pp. 466-481).
[8] Sun, K., Xiao, B., Liu, D., & Wang, J. (2019). Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 5693-5703).
[9] Zhang, F., Zhu, X., Dai, H., Ye, M., & Zhu, C. (2020). Distribution-aware coordinate representation for human pose estimation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 7093-7102).
[10] Yu, C., Xiao, B., Gao, C., Yuan, L., Zhang, L., Sang, N., & Wang, J. (2021). Lite-hrnet: A lightweight high-resolution network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10440-10450).
[11] Xu, L., Guan, Y., Jin, S., Liu, W., Qian, C., Luo, P., ... & Wang, X. (2021). ViPNAS: Efficient Video Pose Estimation via Neural Architecture Search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 16072-16081).
[12] Lin, T. Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., ... & Zitnick, C. L. (2014, September). Microsoft coco: Common objects in context. In European conference on computer vision (pp. 740-755). Springer, Cham.
[13] Jin, S., Xu, L., Xu, J., Wang, C., Liu, W., Qian, C., ... & Luo, P. (2020, August). Whole-body human pose estimation in the wild. In European Conference on Computer Vision (pp. 196-214). Springer, Cham.
[14] Andriluka, M., Pishchulin, L., Gehler, P., & Schiele, B. (2014). 2d human pose estimation: New benchmark and state of the art analysis. In Proceedings of the IEEE Conference on computer Vision and Pattern Recognition (pp. 3686-3693).
[15] Li, J., Wang, C., Zhu, H., Mao, Y., Fang, H. S., & Lu, C. (2019). Crowdpose: Efficient crowded scenes pose estimation and a new benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10863-10872).