「从零入门推荐系统」07:召回算法之规则策略方法
作者 | gongyouliu
编辑 | gongyouliu
我们在上一篇文章中对推荐系统中的召回算法进行了简单梳理。从本章开始,我们会花3章的篇幅来详细介绍推荐系统召回算法的具体思路和实现细节。上一章中我们提到了可以按照算法复杂度将召回算法分为3类,接下来的3章我们按照这个分类来介绍召回算法,我们会分别讲解规则策略召回算法、基础召回算法、高阶召回算法。本章我们介绍规则策略召回算法。
下面我们分5小结分别介绍基于热门、物品标签、用户画像、地域、时间的召回方法。这些召回算法都非常简单,非常容易理解,本章讲解的方法可以给读者提供一些基本的方法和思路,让读者更好地理解基于规则策略召回的原理。这类召回算法非常多,我们不能穷尽所有,不同的行业、场景、阶段都可选择的方法也不一样,读者可以基于自己公司的业务场景去思考该怎么做,是否还有其他更好的选择。
7.1 基于热门的召回
所谓热门召回,就是将大家都喜欢的物品作为召回。这个召回算法的核心思想是利用了人的从众效应,从众效应说的是个体受到群体的影响而怀疑、改变自己的观点、判断和行为等,以和他人保持一致,也就是通常人们所说的“随大流”。从众效应是有进化论的理论作为基础的,随大流能够最大限度降低人的决策风险(想想在狩猎时代,有个同伴突然跑起来,他身边的人肯定也会跑起来,这个跑起来的同伴可能是看到了危险信号,比如发现了一只野兽)。介绍完什么是热门召回及背后的理论基础,下面我们来说一下具体怎么做。
一般来说,上架到某个产品中的物品都是有用户行为记录的,比如淘宝上的商品销售记录,那么我们就可以根据行为日志统计商品在某个时间区间(比如过去半年)的统计量(比如销售量、播放量、阅读量等),按照统计量降序排列就可以获得topN的物品,那么这个topN的物品就可以作为召回列表。
在实际情况中可能会考虑到物品的多样性、价格、质量等多个维度,可以对topN进行微调,或者先将物品按照某个分类规则(如果物品是商品,可以按照生活用品、服饰、3C等分类,如果物品是内容,可以按照新闻、科技、军事、影视等分类),然后在每个类目中统计topN,再将不同类目下的topN混编在一起作为最终的召回。
如果数据量不大,用Python就可以统计topN。如果数据量大并且公司也有大数据平台,利用Spark等大数据分析系统就可以非常容易统计topN物品。总之,热门召回算法在工程实现上是非常容易实施的。召回的热门物品可以存放到Redis等数据库中供具体的召回服务调用。对于一般的产品来说,每日计算一次召回就够了,对于像新闻等时效性非常强的产品,可以按照小时级别来统计topN召回的新闻,也可以T+1和实时都分别计算topN召回,用于不同推荐场景中。
对于物品统计量变化不大的场景(即两次统计topN发现结果基本没变化,甚至一样的),可以采用更灵活的策略,比如可以先取top200,然后再从中随机选择100个形成最终的top100。
热门召回除了作为一种召回策略外,也经常作为冷启动用户的备选推荐策略。人的从众效应决定了利用热门召回作为冷启动一般是一个不太差的选择。
7.2 基于物品标签的召回
对于任何一个业务场景来说,物品一般都是有标签的,比如电商的价格、材质、产地、尺码等都是标签,新闻的类目、关键词等也是标签。基于标签来进行召回是一种比较好的方法,实现难度比较低,计算量小,可解释性也很好。基于物品标签的召回可以用于两个推荐场景,一是用于物品关联物品推荐,一是用于个性化推荐,按照这两个场景,下面我们来分别说明怎么实现这个召回算法。
7.2.1 物品关联物品的召回
假设物品X的标签集合是A(即X所有标签构成的集合),物品Y的标签集合是B,那么物品X和Y的相似度可以用Jaccard相似系数(Jaccard similarity coefficient,中文名杰卡德系数)来计算,计算公式如下:
![]()
Jaccard相似系数取值范围为0到1,值越大表明越相似,这很好理解。这个方法计算非常简单,在具体实施时可以采用如下两种方法来实现。
方法1:利用Redis数据结构
将每个物品的标签存到Redis中(可以不用存标签的中文,而是存标签的id,一般业务上标签都是有唯一id的),利用Set这个数据结构来存储每个物品的标签,其中key是物品id,value是这个物品的所有标签构成的Set。另外建立一个标签到物品的倒排索引结构,也利用Redis的Set数据结构,key是标签,value是所有包含这个标签的物品id构成的Set。
计算X物品最相似的物品时,可以先从Redis中查到X所有的标签、、...、, 然后从Redis中基于标签到物品的反向索引查到、、...、关联的物品(这些物品必须包含、、...、中至少一个标签),标签关联的物品结构如下:
![]()
![]()
......
![]()
那么就可以利用Jaccard相似系数计算X与下面的物品集合的相似度了,然后按照相似度降序排列选取topN的物品作为最终的相似召回结果。
![]()
Redis具备丰富的集合操作,上面计算相似度的操作可以利用Redis的集合操作函数来实现。如果物品的标签数量不是很多,这个算法完全可以实时实现,当推荐系统请求某个物品的相似召回时,可以实时基于上面计算过程计算出该物品的相似物品。当然也可以利用Spark事先计算好存储下来(即计算好每个物品的topN相似并且存放到Redis中)供召回服务调用。这里利用Spark计算跟下面方法2介绍的方案是不一样的,这里是利用Spark对所有物品按照上面的计算过程调用Redis来实现的,主要用的是Spark来并行计算物品的相似物品,是对物品的并行化。
方法2:利用Spark分布式计算
利用Spark可以将每个物品及对应的标签存放到一个DataFrame数据结构中,这个DataFrame包含两列,一列是物品id,另外一列是物品的标签,数据结构是Array的形式。具体参考如下表格的案例说明:
物品id |
标签集合 |
12345 |
Array(134, 456, 789) |
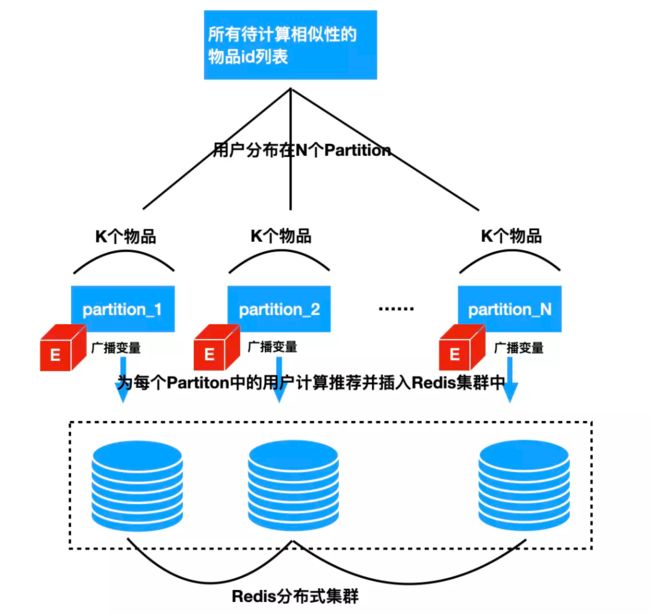
下面简单说明一下具体的计算逻辑:假设这个DataFrame记为D,如果物品数量不是很大,那么我们可以将D广播到每个Spark的计算节点,广播变量记为E,那么就可以利用Spark提供的函数将物品id列表并行化到多个计算节点中计算每个物品的最相似的topN物品了,计算好之后可以将结果存放到Redis中,下图很好地说明了这个过程。
上面讲完了基于物品标签计算相似召回的两种方法,相信读者可以非常容易地理解其中的思想。具体的代码实现在本文中就不写出来了,等这一系列文章更新完,这一系列文章中的代码实现作者会在github上开源出来,方便大家去学习。
基于标签的召回方法也可以推广到标签有权重的情况,只不过这时候Jaccard相似系数的计算公式要调整一下,另外利用Redis方法时要用sorted_set而不是Set,sorted_set中的score刚好表示权重,Spark方法的计算过程也需要稍微调整一下。由于没有太大的挑战,这里不再赘述,感兴趣的读者自己可以探索一下。
7.2.2 个性化召回
个性化召回就是基于标签来为每个用户召回该用户可能喜欢的物品,是属于个性化推荐范式。我们可以采用两种方法实现个性化召回,下面分别介绍。
7.2.2.1 利用种子物品召回
这个方法是将用户喜欢过的物品最相似的物品召回作为该用户的召回。可以选择用户最近一段时间评分比较高的几个物品作为种子去召回(具体选择多少个可以根据实际情况来定)。这种方法比较适合用在实时推荐场景中,这时一般可以将用户最近操作过的1-2个物品最相似的物品召回,然后进行排序插入到用户的推荐流中。比如在抖音中,如果你刚刚看了一个瑜佳的视频,那么就可以将这个瑜佳视频最相似的视频(可能还是瑜伽视频)召回,然后放到给你的后续推荐列表中。
7.2.2.2 利用用户兴趣标签召回
这个方法是基于用户的行为构建用户的兴趣标签画像,将物品的标签赋予到用户身上,然后用户也具备标签了,那么就可以采用物品关联物品类似的方法给用户进行关联召回了。这里举个例子说明一下怎么给用户赋予标签。比如你看了一个电影,这个电影有3个标签,分别是爱情、生活、艺术,那么就可以给你打上爱情、生活、艺术这3个标签,代表你对这3个标签感兴趣。当我们将你看过的所有电影的标签都赋予给你时,为你构建兴趣标签的过程就完成了。这个方法其实就是下面将要介绍的用户画像召回算法的一种(基于用户兴趣标签画像的召回),为了内容的完整性,我们在基于标签召回这一节提前介绍了。
上面两个方法其实都是可以赋予标签权重的,可以基于用户操作过的物品的喜好程度来赋予权重。这里拿抖音上观看视频为例,如果一个视频A用户U观看了w(![]() )比例的时间,那么权重就是w(比如一个视频5分钟,你看了2分钟,那么w=2/5=0.4)。如果视频A本身的标签也有权重,那么用户对标签的权重就是这两个权重的乘积,利用公式说明如下:
)比例的时间,那么权重就是w(比如一个视频5分钟,你看了2分钟,那么w=2/5=0.4)。如果视频A本身的标签也有权重,那么用户对标签的权重就是这两个权重的乘积,利用公式说明如下:
![]()
![]()
如果用户U观看了多个视频,每个视频都可以按照上面公式获得用户基于这个视频的标签权重,所有这些标签权重合并同类项(有相同的标签,权重累加)就可以了,读者应该可以很容易理解这个过程,这里就不再展开写具体的公式了。
在实际推荐系统中,不同的场景还有一些不一样的具体实施方式,这里拿音乐推荐举例。音乐的标签可以基于歌手、风格两个维度来打标签。那么给用户打标签可以基于歌手、风格两个维度。分别统计用户最喜欢的几个歌手,最喜欢的几个风格(比如都保留最喜欢的3个),那么就可以将这些歌手创作的歌曲,具备这些风格的歌曲作为该用户的召回。这个例子其实是对标签进行分类,在每一类中分别统计用户的兴趣标签,然后分类召回,比上面介绍的平展化的兴趣标签更复杂一些。
到这里我们介绍完了基于物品标签的召回算法。基于物品标签的方法原理非常简单,实现方式也非常方便,推荐过程也方便解释,所以是一种很实用、常用、有效的召回策略。下面我们来介绍基于用户画像的召回。
7.3 基于用户画像的召回
用户画像其实就是用户的标签化,通过给用户贴上标签,我们可以更好地了解这个用户的特点。上面介绍的兴趣标签其实是其中的一种标签化。我们还可以从用户自然属性、社会属性、业务属性、设备属性等多个维度来刻画用户(详细的用户画像讲解超出了本系列文章的范畴,这里不过细说,感兴趣的读者可以参考相关文章、书籍),下面我们就从这4个纬度来简单说说怎么基于用户画像进行召回。希望本节的讲解可以给大家提供一些思路,大家也可以琢磨一下还可以从哪些维度去召回。
7.3.1 基于用户自然属性的召回
像用户的年龄、性别等都是用户固有的属性,是非常确定的。基于这些属性可以给用户进行召回,下面分别举例说明。
对于年龄,怎么去召回呢?我们可以将用户按照年龄分为学生、青年、中年、老年等4大类,每类用户可能喜欢的物品是不一样的,那么就可以根据用户所属的年龄类别分别进行召回。拿音乐推荐举例说明,我们可以将这4个年龄段的用户最喜欢的歌曲的top100统计出来(注意这里用到了前面提到的热门召回方法了),分别作为这4类用户的召回。
不同场景的年龄分类方式不一样,大家也可以基于自己公司产品去考虑一下怎么按照年龄给用户分群。当然,在一些场景中,也是可以基于运营或者产品人员的经验,通过人工为这4类用户事先人工编辑出待召回的物品列表的。
有了上面的介绍,基于性别召回就非常简单了。将用户分为男、女两类,分别为每类用户进行召回,这里我们就不举例说明了。
7.3.2 基于用户社会属性的召回
像职业、收入等可以看成用户的社会属性。基于社会属性,我们也可以给用户进行召回。拿职业来说,不同职业的人可能看的书是不一样的,那么在图书推荐场景下,我们就可以利用职业进行召回。具体做法是将可能的职业分为若干类(大家可以去参考招聘网站上的职业分类方法),为每一类人分别召回。可以跟上面年龄类似,统计每个职业的人最常购买的书的topN作为召回结果。
收入也是一样,可以将用户的收入分为高、中、低3档,为每个用户召回不同的物品。拿滴滴打车举例,针对高收入人群,可以为这类用户召回附近开价位比较高的车的司机。
7.3.3 基于用户业务属性的召回
用户的业务属性种类很多,不同的业务有所不同,比如用户在游戏中的等级、用户使用某个产品的用龄(就是使用了多少年)、用户是不是会员、用户使用该产品是否频繁(活跃用户、非活跃用户)、用户是高净值客户还是低净值客户等等。
不同产品的业务场景是非常不一样的,即使是同样的业务场景,不同的公司定义业务属性的方式也是不同的。具体召回的思路跟上面介绍的一些方法也是类似的,我们这里就不展开讲解在这种情况下怎么去召回了,读者可以结合自己公司的业务场景去思考一下。
7.3.4 基于用户设备属性的召回
这里拿手机APP场景来说明。设备属性按照操作系统可以分为ios、Android,按照品牌可以分为苹果、华为、小米、OPPO、VIVO等,按照屏幕尺寸可以分为4.7吋、5.5吋、6.7吋等,按照价位可以分为高端、中端、低端等。
不同的设备属性进行召回的方式可以多种多样,我这里拿ios和Android来举例。我们知道ios用户普遍来说商业价值更大(说直接一点是更有钱),那么在召回时就可以为ios用户召回客单价更贵的商品。
基于上面4种不同的属性怎么去召回,我们做了简单的讲解,具体召回的思路也非常简单。基于用户画像召回的难点是怎么获得用户的画像,有些公司的业务是很难获得用户非常完善的用户画像的,这时就很难实施这类召回了。不过基于兴趣标签这类画像召回,任何业务都可以做,只要能够对用户的操作行为进行埋点就可以了。
7.4 基于地域的召回
有些产品是LBS(Location Based Services)应用,比如美团外卖、滴滴打车等。对这类产品的用户进行召回时,必须要考虑到地理位置的限制(美团不可能给你推荐离你的下单地址几十公里外的商家)。对于这类场景,一般可以基于用户的手机GPS信号获取用户的地址或者用户填写的下单地址,然后计算服务商距离用户的实际距离(不是物理距离,因为要考虑道路实际的连通性),将某个阈值(这个阈值可以用户自己选择或者根据实际经验由产品经理来设定或者基于某个策略来决定,大家可以拿美团、大众点评、滴滴来参考,这样更好理解)之内的商品或者服务进行召回。
距离的计算可以利用地图供应商提供的服务,像百度地图、高德地图等是提供这类服务的(即计算任何两个地址之间的距离),也可以利用经纬度用公式或者数据库计算(有些数据库比如Redis、MongoDB等是可以基于地理位置进行查询的)出距离。如果你有大量的真实服务数据,也是可以利用大数据算出来的,比如拿美团来说,美团的骑手非常多,服务了这么多年,从某个店家到某个小区送过的外卖单不计其数,那么这么多单每单派送花了多长时间是有日志记录的,那么就可以利用大数据统计获得一个大概的送达时间。其实美团上有预计送达时间的估计功能,也是利用大数据结合当前的交通拥堵信息利用预测算法预估出来的。
如果你的应用不是LBS应用,也是可以基于地域召回的,这类业务是根据用户所在的区域进行召回,其实也算是用户画像的一种(因为用户的地域也算是一种画像),我放在地域召回这节来讲了。这里我举个例子,拿短视频推荐来说,广东的用户喜欢看粤语视频、东北的用户喜欢看二人转,那么可以基于这两个地区的用户本身的爱好特点分别进行召回。
7.5 基于时间的召回
可以说,人类的任何活动都是跟时间相关的,时间是任何商业行为中最重要的因子之一,对推荐系统来说也不例外,因此基于不同时间为用户进行不同的召回是非常有必要的。本节我们就来简单说明一下基于时间可以从哪些维度进行召回,具体的召回思路是什么。
人类每日的活动有节假日和工作日之分,在工作日和节假日做的事情不一样,那么基于节假日和工作日进行不同的召回就成为可能。节假日大家的时间更加充裕,那么是可以召回“花费用户时间更多的物品”的。比如在携程这种旅游类APP,节假日可以给用户推荐更远距离的旅游地点。
每个人每天的活动又有早晚之分,早上、晚上做的事情也是不一样的,那么推荐的物品就可能有差别。比如美团外卖,早上和中午召回的食物是不一样的,早上推荐早餐,中午推荐正餐。
另外 ,我们的生活中还存在特定事件和特定日期,当这些事件或者日子出现时推荐召回的物品也会不一样。比如最近的世界杯,在今日头条、抖音这类新闻、视频类APP,可以为用户召回一些关于球赛相关的新闻和视频。像双十一等这类特定日期,淘宝上有很多商家和商品参与活动,针对用户的召回方式也可以跟平时不一样。
上面简单列举了3类不同时间场景下的召回思路,不同的产品由于自身的业务属性不一样,做法可能有比较大的差别,大家可以结合自己公司的产品去思考一下,怎么基于时间去设计召回方案,这里不赘述。
总结
我们在本章介绍了5类基于简单规则、策略的召回算法,这些算法原理都非常简单、易懂,工程实现非常容易,计算复杂度也非常低。这些召回方法在真实的推荐业务场景中也经常用到,所以大家还是需要好好掌握的,特别是热门召回、基于标签的召回,是用的非常频繁的两类召回算法。
我们在上一篇文章中说过,在真实业务场景中会用多种召回算法,这个过程类似集成学习,所以别看本章中的召回算法非常简单,只要使用得当,配合后一阶段的排序算法,也是可以获得比较好的推荐结果的。本章的介绍就到这里了,下一章我们会介绍协同过滤、矩阵分解等其它基础召回算法。
大家如果想更全面学习推荐系统,可以购买作者之前出版的图书,购买链接如下:
