Part-aware Prototype Network for Few-shot Semantic Segmentation阅读笔记
第2节
贡献:
1.针对小样本语义分割提出了一种基于prototype的方法,在 one-way和multi-way当中都取得了很好的效果
2.提出了一个针对语义类的part-aware prototype表达,能够对细颗粒的目标特征进行编码,然后得到更好的分割
3.为了更好的得到类内的变量,使用一个图注意力网络对没有标签的数据进行半监督学习
本文的工作受到了度量学习方法的启发,其中包括由Oriol提出的将输入编码为一个embedded特征,并且实现加权最近邻来匹配类别。prototypical网络目的是学习一个度量空间,在这个空间中输入根据与类别的距离来进行分类。
同时也有很多方法为了增强小样本学习,利用了一些无标签数据,具体可以参考半监督小样本学习[24,16,1]。文【24】中通过soft k-means来从无标签的数据中获得prototypes。文【1】在局部与全局中引入了一个consistency loss来更好的利用无标签数据.
目前针对小样本的工作主要分成了两种: parametric matchingbased methods [37,36,35,20,3] and prototype-based methods [27,33]。当然也存在例外,MetaSegNet[29]采取了一种基于优化的小样本学习方法,将小样本分割转化为了像素分类问题.
参数匹配方法:Shaban[3]等人首先提出了一个权重imprinting方法,这个方法产生的分类权重用于小样本分割。【36】文中提出将在每一个空间位置的query特征的整体目标表示进行串接,并且引入了一个dense comparison模型来估计预测值。【35】文中将图注意力机制应用于每个query特征的前景(foreground)特征。然而这些方法都是适用于one-way小样本的情况,拓展到multi-way的情况计算量都很大。
prototype方法使用整体语义类的prototype来对query图像进行像素匹配。【33】在support和query图像间提出了指定类的prototype表示。[27]采取了一种新型的多重分辨率的prototype方法,这个方法是针对小样本分割的imprinting方法。而所有基于prototype的方法都受限于整体表示。为了解决这个问题,本文提出了将目标表示分解成一些part级的特征,进而对不同目标特征在一个细颗粒的级别上进行建模。
文[9]首次将图卷积网络引入小样本图像分类当中。相对的,本文就是使用图卷积神经网络来学习一组prototype用于语义分割任务
第3节
本文认为小样本语义分割的问题是为了从每个类的一小部分注释训练图像中来学习分割语义目标。为了这个目的,本文利用了一个元学习策略,即创建一个元学习器M来解决一类小样本语义分割任务T,这个任务主要是在一个潜在的任务分布PT中进行采样。
从形式上来说,每一个小样本分割任务T(也称为一个episode)都是由一些有标签值的support数据S和query图像组成。在半监督小样本中,support数据S={Sl,Su},而Sl表示有注释带标签的数据集,而Su表示有注释没有标签的数据集。准确来说,是在样本中随机抽取C个类,每个类取K张图片下,注释的support数据每个类包含K个图像与标签对。具体表示
![]()
其中Y表示像素级的注释

C T C^T CT指的是任务T中类别的子集,| C T C^T CT|=C。无标签support图像
![]()
从语义类集C中任意采样,在训练与推理过程中删除他们的类别标签。同样,query集
![]()
包含来自类别集 C T C^T CT的 N q N_q Nq个图像,而这里面的图像注释在训练时存在,在测试时未知。
元学习器M旨在学习一个映射函数,这个函数的功能是对于所有任务将support集S和query集Iq映射到分割类Y上。为了实现这个目标,本文构建了具有一个类别集Ctr的分割任务的一个训练集,并且在Dtr任务上episodically训练元学习器。在元学习之后,使用模型M对信息进行编码,这个信息是关于在任务中如何在不同的语义类别中进行分割。最后在任务Dte的测试集上评估学习到的模型,Dte与Dtr不重叠。
第4节
在本文中,针对语义分割,采用了基于prototype的小样本学习结构来构建元学习器M。本文的主要思想就是通过一个新的prototype表示来获取到语义类的类内变量以及fine-grained特征。将每个类的support目标的整体性信息分解成了一些part-aware prototype表示,并且使用无标签数据来增强表示。

这里的元学习器选择了深度图网络,用于进行新表示的编码,query图像的分割。网络包含三个主要的网络:一个embedding网络(在任务下计算图像的特征图-4.1),一个prototype generation网络(从有标签和无标签的support数据集中提取到一些part-aware prototype-4.2)和一个part-aware掩膜生成网络(生成query图像的最后语义分割图像-4.3)。
为了训练元模型,使用一个混合(hybrid)损失并且引入了一个语义分支(4.4部分),这个语义分支获取到最初的语义类,为的是更加有效的信息。
4.1 embedding网络
在一个任务当中,PPNet的第一个模块就是一个提取所有图片特征的网络,而在本文中使用的是ResNet网络,同时引入了一个膨胀卷积来增大感受域和保存更多的空间信息。
![]()
f_em表示网络,I表示输入数据,F表示输出
![]()
n_ch表示特征通道数,(H_f,W_f)表示特征图的宽和高,同时设置掩膜的大小与特征图的大小相同。
在Sl中将图像特征分为了C+1个类别,其中有一个类别表示图像背景,其他C个表示图像语义类别
![]()
其中
![]()
包含了语义类k的所有特征
4.2 prototypes生成网络
prototypes生成网络主要是为了产生每个类的一些不同part-aware prototypes。假设语义类为k,输入
![]()
输出一些prototype P k P_k Pk,因此引入了一个定义在特征上的图神经网络,根据有标签和无标签的support集不同性质,两步计算得到prototypes。网络直接从标签support数据 F k l F^l_k Fkl得到part-aware prototype,然后利用无标签的数据得到他们的表示。
Part Generation with Labeled data
为了在目标区域获取到fine-grained的part-level的变量,从带标签的support集中构建了一个part-aware prototype。使用 N p N_p Np表示每个类中prototype的数量, P k = { p i } i = 1 N p , p i ∈ R n c h P_k={\lbrace p_i \rbrace^{N_p}_{i=1}},p_i\in R^{n_{ch}} Pk={pi}i=1Np,pi∈Rnch,使用K-means聚类在特征集Fl得到数据划分 g = { G 1 , G 2 , . . . G N p } g=\lbrace G_1,G_2,...G_{N_p}\rbrace g={G1,G2,...GNp},然后使用平均池化层来得到一些初始的prototypes集 P k = { p i } i = 1 N p P_k={\lbrace p_i \rbrace^{N_p}_{i=1}} Pk={pi}i=1Np
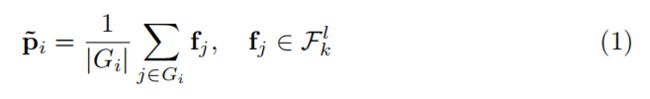
同时通过使用一个环境向量来增强每个初始prototype,进而将语义类的全局信息应用到part-aware prototypes中。基于注意力机制,利用相同类的其他prototype中进行估计.

λ p \lambda_p λp指的是尺度变换参数, u i j u_{ij} uij是从相似度量方法(比如 cosine度量)中计算得到的注意力权重。
Part Refinement with Unlabeled Data
这个模块的目的就是获取到每个语义类的类内变量,而这是需要借助其他的无标签support图像来增强prototypes。因为没有注释(unannotated),所以这部分数据的噪声更多,并且比标签数据有更多列数据,因此需要提前对这些数据进行处理,得到一个更小且有些有效信息更多的特征集。在本文中通过grouping和pruning(聚合和修剪)来解决以上的两个问题(数据量大,噪声多),最后生成在类别k上的一个更小且相关性更强的特征集 R k u R^u_k Rku。
在这个特征集上,通过聚合这些特征,设计了一个图注意力网络来平滑无标签数据,同时提纯part-aware prototype。具体包含以下三个步骤:
步骤1:产生相关信息
首先利用超像素生成的思想,计算了无标签图像的区域级特征表示。确切来说,本文使用SLIC来处理无标签数据,在Fu上产生一些组。使用
![]()
表示组,使用平均池化来生成一些区域块的特征
![]()
然后在类k里面选择一些相关特征
![]()
d表示衡量 p i p_i pi与 r j r_j rj之间的相似函数
步骤2:无标签特征增强
选择好无标签的特征,第二步的关键就是在这些特征中利用其中的语境信息来增强其中的区域级的表达。在特征集 R k u R^u_k Rku上构建一个全连接层,使用下面的信息传递函数去更新数据特征


r ~ i \widetilde{r}_i r i表示节点i的新的表示,h表示激活函数,Z表示节点i上的归一化因子,W表示权重矩阵,定义了一个来自节点j的信息编码的线性映射。
步骤3:Part-aware prototype refinement
在增强的无标签特征中,我们使用与标签特征相似的注意力机制,进而来提取初始的part-aware prototypes。然后使用P_k作为注意力队列来选择在R~u_k中的无标签特征,并且聚合在P_k当中

λ r \lambda_r λr表示尺度参数, ϕ i j \phi_{ij} ϕij表示注意力权重
![]()
k类中最后筛选下来的prototype集
4.3 part-aware 掩膜产生网络
在query图像Iq上产生一个语义掩膜预测,特征Fq,带位置信息 f m , n q f^q_{m,n} fm,nq
首先每个part-awre prototype生成一个相似度矩阵,这个相似矩阵是使用了prototype-pixel匹配得到
![]() S k , j ( m , n ) S_{k,j}(m,n) Sk,j(m,n)表示在(m,n)上的的得分情况
S k , j ( m , n ) S_{k,j}(m,n) Sk,j(m,n)表示在(m,n)上的的得分情况
本文通过最大池化将类别k的所有得分矩阵进行融合,将来自所有类别的分数矩阵进行串接,最后得到输出分割
![]() ⊕ \oplus ⊕表示串接。为了得到最后的分割,使用双线性插值对 Y ^ q \hat{Y}^q Y^q进行上采样,在每个像素位置上选择类别标签中最高的分数值
⊕ \oplus ⊕表示串接。为了得到最后的分割,使用双线性插值对 Y ^ q \hat{Y}^q Y^q进行上采样,在每个像素位置上选择类别标签中最高的分数值
目前还在入门,仅作为参考,很多都是加入了一些自己的理解,有什么问题可以指出
个人觉得掩膜讲的比较清晰的,可以参考下面的链接
图像中的掩膜(Mask)是什么
个人理解:
本文中的图注意力网络主要利用的是像素点周围的信息,通过调整权重来调整周围点对中心点的影响
[1]Ayyad, A., Navab, N., Elhoseiny, M., Albarqouni, S.: Semi-supervised few-shot learning with local and global consistency. arXiv preprint arXiv (2019)
[6] Chung, Y.A., Weng, W.H.: Learning deep representations of medical images using siamese cnns with application to content-based image retrieval. In: NIPS Machine Learning for Health Workshop(NIPS workshop) (2017)
[24] Ren, M., Triantafillou, E., Ravi, S., Snell, J., Swersky, K., Tenenbaum, J.B., Larochelle, H., Zemel, R.S.: Meta-learning for semi-supervised few-shot classification. arXiv preprint arXiv (2018)