利用Python整合多文件夹中数据表(excel\csv)到同一个表
原数据:
有151个文件夹,每个文件夹有30个左右的csv表
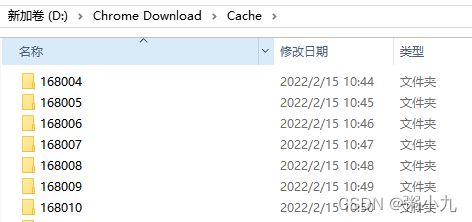
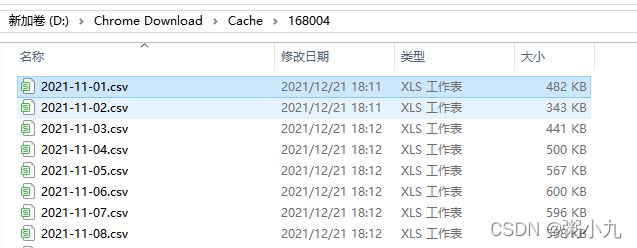
需求:
把每个文件夹下面的数据表的第1行,第1-3列的数据整合写入一张新表
因为文件夹下多个数据表中的第1行,第1-3列的数据都是一样的,就只需要随机选择其中1个日期表
import pandas as pd
import numpy as np
import os
import xlrd
from xlutils.copy import copy
dir = os.listdir('D:\Chrome Download\Cache')
row = 0
def writeFile(path, row, coloum, value):
table = xlrd.open_workbook(path)
tablenew = copy(table)
sheet = tablenew.get_sheet(0)
sheet.write(row, coloum, value)
tablenew.save(path)
for dirname in dir:
file = 'D:\\Chrome Download\\Cache\\' + dirname + '\\2021-12-28.csv'
data = pd.read_csv(file, nrows=1)
data1 = np.array(data)
data2 = data1[0]
data3 = data2[0]
data4 = data2[1]
data5 = data2[2]
writeFile('D:\Chrome Download\data1.xlsx', row, 0, data3)
writeFile('D:\Chrome Download\data1.xlsx', row, 1, data5)
writeFile('D:\Chrome Download\data1.xlsx', row, 2, data4)
row = row + 1