【论文阅读笔记】CycleISP: Real Image Restoration via Improved Data Synthesis
论文地址:https://arxiv.org/abs/2003.07761
代码地址:https://github.com/swz30/CycleISP
论文小结
总的来说,就是现实世界中无法获取有效的图像对。且之前合成噪声的方式是在sRGB上添加高斯白噪声,但对于相机传感器成像管道来说,经过一系列的处理,噪声早已不是高斯白噪声了,所以之前的论文方法在相机图像中效果不好。
所以作者设计了一种模式,实现sRGB图像->RAW图像->添加噪声->sRGB图像的一个循环过程,所以整个架构成为CycleISP。
在训练的时候,sRGB图像->RAW图像的子网络,与RAW图像->sRGB图像的子网络使用干净图像单独训练。在RAW图像->sRGB图像的子网训练完成后,对RAW图像添加噪声,则能得到对应的有噪声的sRGB图像。通过完成的管道,可以得到sRGB去噪图像对。
论文简介
真实世界中,由于数据不容易制作。所以图像去噪算法主要是在合成数据上开发和评估的。这些合成数据通常在广泛假设加性高斯白噪声 (AWGN) 的情况下生成的。
但正如最近的基准数据集所报告的那样,它们在应用于真实相机图像时表现不佳。这主要是因为 AWGN 不足以模拟真实的相机噪声,它是信号相关的并且由相机成像管道经过大量转换得到的。在本文中,作者提出了一个框架,可以在正向和反向方向上对相机成像管道进行建模。 它允许我们生成任意数量的真实图像对,用于在 RAW 和 sRGB 空间中进行去噪。
本文模型中的参数比以前最好的 RAW 降噪方法少 5 倍。
在本文中,作者提出了一种数据合成方式方法,可以在RAW和sRGB空间中生成真实的噪声图像。主要思想,是将噪声注入到我们学习到的设备位置变换获得的RAW图像中,而不是直接注入到sRGB图像中。这种框架背后的关键见解是:sRGB图像中存在的真实噪声被常规图像信号处理(ISP)管道中执行的一系列步骤所扭曲[6, 46]。所以,与原始传感器数据[35]相比,在sRGB中建模真实相机噪声是一项固有的艰巨任务。例如,RAW传感器空间是信号相关(signal-dependent)的,在经过去马赛克后,它变成空间-色彩相关。再通过其余的管道后,它概率分布不一定仍然保持高斯分布。这表示着相机ISP将传感器噪声进行了严重的转换。因此,相较于统一的AWGN模型,我们需要对图像管道对真实合成噪声的影响进行更详细的建模过程。(therefore more sophisticated models that take into account the influence of imaging pipeline are needed to synthesize realistic noise than uniform AWGN model [1, 26, 44].)
为了利用互联网上可用的sRGB照片的丰富性和多样性,所提出的合成方法的主要挑战是如何将他们转换回原始测量值。[7]提出了一种技术,可用逐步反转相机ISP,因此可用转换sRGB数据到RAW数据。然而,这种方法需要关于目标相机设备的先验信息(例如,颜色校正矩阵和白平衡增益),这使得它特定于给定的设备,因此缺乏普遍性。此外,相机管道中的一些操作是专有的,这样的黑盒很难进行逆向工程。
为了解决这些挑战,在本文中,我们提出了一个CycleISP框架,它可以将sRGB图像转换为RAW数据,然后再转换回sRGB图像,而不需要任何相机参数的知识。这个属性允许我们在RAW和sRGB空间中合成任意数量的干净和真实的噪声图像对。
作者的主要贡献有:
- 学习一种设备无关的转换,称为CycleISP,它允许我们在sRGB和RAW图像空间之间来回移动。
- 真实图像噪声合成器,用于在RAW和sRGB空间中生成干净/噪声配对数据。
- 一个具有双重注意机制的深度CNN,在各种任务中都有效:学习CycleISP,合成真实噪声和图像去噪。
- 从RAW和sRGB图像中去除噪声的算法,在DND[44]和SIDD[1]的真实噪声基准上设置了最新的技术(见下图1)。此外,我们的去噪网络的参数(2.6M)比之前的最佳模型(11.8M)[7]少得多。
- CycleISP框架的推广超越了去噪,作者通过一个额外的应用,即立体电影中的颜色匹配来证明这一点。

一个更精确的真实RAW传感器噪声模型既包含信号相关的噪声分量(射击噪声),也包含信号无关的加性高斯分量(读噪声)[22,23,24]。
CycleISP
为了合成真实的噪声数据集,作者在这项工作中使用了两阶段方案。首先,开发了一个框架,在正向和反向两个方向上对相机ISP建模,因此命名为CycleISP。其次,利用CycleISP合成真实噪声数据集用于RAW图像去噪和sRGB图像去噪。
CycleISP模型的模块如下图所示,(a) RGB2RAW网络分支;(b)RAW2RGB网络分支。此外,作者还引入了一个额外的颜色校正网络分支,为RAW2RGB网络提供显式的颜色attention,以正确恢复原始sRGB图像。

上图中的噪声注入,只有在合成噪声数据阶段时才需要。CycleISP的训练过程分为两步:(1)独立训练RGB2RAW和RAW2RGB网络(2)进行联合微调。
RGB2RAW网络分支
数码相机对RAW传感器数据进行一系列操作,以生成可用于监控的sRGB图像[46]。本文的RGB2RAW网络分支旨在扭转摄像机ISP的影响。与[7]的非处理技术相比,RGB2RAW分支不需要任何相机参数。
RGB图像 I r g b ∈ R H ∗ W ∗ 3 I_{rgb}\in\mathbb{R}^{H*W*3} Irgb∈RH∗W∗3作为输入,经过一个卷积层 M 0 M_0 M0得到特征 T 0 ∈ R H ∗ W ∗ C T_0\in\mathbb{R}^{H*W*C} T0∈RH∗W∗C,再通过N个循环残差组(RRGs,recursive residual groups)提取深层特征 T d ∈ R H ∗ W ∗ C T_d\in\mathbb{R}^{H*W*C} Td∈RH∗W∗C,起重每个RRG包含多个多重注意块。 T d = R R G N ( . . . ( R R G 1 ( T 0 ) ) ) (1) T_d=RRG_N(...(RRG_1(T_0)))\tag{1} Td=RRGN(...(RRG1(T0)))(1)
然后再通过一个最后的卷积操作 M 1 M_1 M1获得去马赛克图像 I ^ d e m ∈ R H ∗ W ∗ 3 \hat{I}_{dem}\in\mathbb{R}^{H*W*3} I^dem∈RH∗W∗3。这里让 M 1 M_1 M1的channel为 3 3 3是有意为之的,是想让其尽量与原图有一样的结构信息。且实验结果也表明,channel为 3 3 3有助于网络更快、更准确地学习从sRGB到RAW的映射。在这一点上,该网络能够反转色调映射、伽马校正、颜色校正、白平衡和其他转换的效果,并为我们提供图像 I ^ d e m \hat{I}_{dem} I^dem,其值与场景亮度线性相关。最后,为了生成有马赛克的RAW输出 I ^ r a w ∈ R H ∗ W ∗ 1 \hat{I}_{raw}\in\mathbb{R}^{H*W*1} I^raw∈RH∗W∗1。将拜耳采样函数 f B a y e r f_{Bayer} fBayer应用到 I ^ d e m \hat{I}_{dem} I^dem,依据拜耳模式,每个像素省略两个颜色通道。 I ^ r a w = f B a y e r ( M 1 ( T d ) ) (2) \hat{I}_{raw}=f_{Bayer}(M_1(T_d))\tag{2} I^raw=fBayer(M1(Td))(2)
看来,图上的马赛克层,就是 f B a y e r f_{Bayer} fBayer了,拜耳函数。
RGB2RAW网络使用线性域和对数域的 L 1 L_1 L1损失进行优化,下公式中的 ϵ \epsilon ϵ是小数值的常量, I r a w I_{raw} Iraw是ground truth RAW图像,也像[21]一样,加入了对数损失项以强制对所有像素值进行近似相等的处理,否则网络将更多的注意力用于恢复突出区域。 L s → r ( y ^ r a w , I r a w ) = ∥ I ^ r a w − I r a w ∥ 1 + ∥ l o g ( m a x ( I ^ r a w , ϵ ) ) − l o g ( m a x ( I r a w , ϵ ) ) ∥ 1 (3) \mathcal{L}_{s\rightarrow r}(\hat{y}_{raw},I_{raw})=\|\hat{I}_{raw}-I_{raw}\|_1 + \|log(max(\hat{I}_{raw}, \epsilon))-log(max(I_{raw}, \epsilon))\|_1\tag{3} Ls→r(y^raw,Iraw)=∥I^raw−Iraw∥1+∥log(max(I^raw,ϵ))−log(max(Iraw,ϵ))∥1(3)
RAW2RGB网络分支
RAW2RGB网络的最终目标是为sRGB图像去噪问题生成合成的真实噪声数据。本节的内容还是先描述如何将干净的RAW图像映射到干净的sRGB图像(即图2中让噪声注入模块保持"OFF"状态)。
为了减少计算消耗,将 I r a w I_{raw} Iraw装成 2 ∗ 2 2*2 2∗2的块,变为4个channel(RGGB)。也因为输入的RAW图像可能来自于不同的相机,有不同的拜耳模式,所以我们需要注意channel的顺序,利用拜耳模式统一技术,保持图像的通道顺序为RGGB。再然后,通过一个卷积层 M 2 M_2 M2后,接着 K − 1 K-1 K−1个RRG模块对堆叠的RAW图像 I p a c k ∈ R H 2 ∗ 2 W 2 ∗ 4 I_{pack}\in\mathbb{R}^{\frac H2*2\frac W2*4} Ipack∈R2H∗22W∗4进行编码,得到深层特征tensor T d ′ ∈ R H 2 ∗ W 2 ∗ C T_{d'}\in \mathbb{R}^{\frac H2 * \frac W2 * C} Td′∈R2H∗2W∗C。 T d ′ = R R G K − 1 ( . . . ( R R G 1 ( M 2 ( P a c k ( I r a w ) ) ) ) ) (4) T_{d'}=RRG_{K-1}(...(RRG_1(M_2(Pack(I_{raw})))))\tag{4} Td′=RRGK−1(...(RRG1(M2(Pack(Iraw)))))(4)
需要注意的是, I r a w I_{raw} Iraw是原始的相机RAW图像,而不是RGB2RAW图像的输出。因为这里的首要目标是先独立地学习RAW到sRGB的映射。
颜色attention单元
使用MIT-Adobe FiveK数据集[10]训练CycleISP。MIT-Adobe FiveK数据集包含数个不同相机的图像,这些相机有不同而复杂的ISP系统。
CNN很难准确地学习所有不同类型相机的RAW到sRGB映射函数(因为一个RAWimage可以映射到许多sRGB图像)。一种解决方案是为每个摄像头ISP训练一个网络[13,51,62]。然而,这样的解决方案是不可扩展的,性能可能无法推广到其他相机。为了解决这个问题,我们建议在RAW2RGB网络中包含一个颜色注意单元,它通过一个颜色校正分支提供显式的颜色注意。
颜色校正分支是一个CNN,以sRGB图像 I r g b I_{rgb} Irgb作为输入,生成颜色编码的深层特征tensor T c o l o r ∈ R H 2 ∗ W 2 ∗ C T_{color}\in\mathbb{R}^{\frac H2 * \frac W2 * C} Tcolor∈R2H∗2W∗C。在颜色校正分支中,先对 I r g b I_{rgb} Irgb应用高斯模糊,再接着一个卷积层 M 3 M_3 M3,接着两个RRGs,以及一个门机制的sigmoid激活函数 σ \sigma σ: T c o l o r = σ ( M 4 ( R R G 2 ( R R G 1 ( M 3 ( K ∗ I r g b ) ) ) ) ) (5) T_{color}=\sigma(M_4(RRG_2(RRG_1(M_3(K*I_{rgb})))))\tag{5} Tcolor=σ(M4(RRG2(RRG1(M3(K∗Irgb)))))(5)
公式(5)中, ∗ * ∗表示卷积, K K K表示标准差经验性设为 12 12 12的高斯核。这种强模糊操作确保了只有颜色信息可以流经这个分支,而结构内容和精细纹理主要来自RAW2RGB网络。使用较弱的模糊处理会削弱公式(4)的特征张量 T d ′ T_{d'} Td′的有效性。 T a t t e n = T d ′ + ( T d ′ ⊗ T c o l o r ) (6) T_{atten}=T_{d'}+(T_{d'}\otimes T_{color})\tag{6} Tatten=Td′+(Td′⊗Tcolor)(6)
公式(6)中的 ⊗ \otimes ⊗是哈达玛积(Hadamard product),即点乘。然后再通过一个RRG模块,一个卷积层 M 4 M_4 M4,一个上采样层 M u p M_{up} Mup将颜色注意力单元输出的特征 T a t t e n T_{atten} Tatten转换为最后的sRGB图像 I ^ r g b \hat{I}_{rgb} I^rgb。 I ^ r g b = M u p ( M 5 ( R R G K ( T a t t e n ) ) ) \hat{I}_{rgb}=M_{up}(M_5(RRG_K(T_{atten}))) I^rgb=Mup(M5(RRGK(Tatten)))
为优化RAW2RGB网络,使用 L 1 L_1 L1损失进行优化。 L r → s ( I ^ r g b , I r g b ) = ∥ I ^ r g b − I r g b ∥ 1 \mathcal{L}_{r\rightarrow s}(\hat{I}_{rgb},I_{rgb})=\|\hat{I}_{rgb}-I_{rgb}\|_1 Lr→s(I^rgb,Irgb)=∥I^rgb−Irgb∥1
RRG:循环残差组
RRG模块如下图3所示:RRG包含 P P P个双重注意块(DAB),每个DAB的目标是抑制不太重要的特性,只允许传播更有信息的特性。DAB通过使用两种注意机制:(1)通道级注意(CA)和(2)空间级注意(SA)进行特征的再校准。
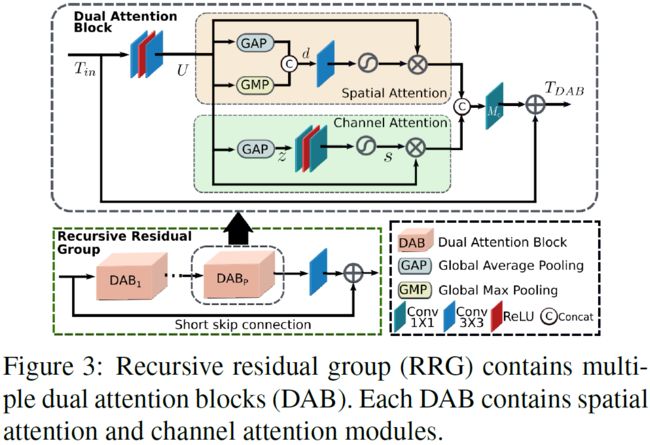
上面管道可以通过如下公式(9)表示:其中 U ∈ R H ∗ W ∗ C U\in \mathbb{R}^{H*W*C} U∈RH∗W∗C表示着输入tensor T i n ∈ R H ∗ W ∗ C T_{in}\in \mathbb{R}^{H*W*C} Tin∈RH∗W∗C通过DAB前端的两层卷积层得到的特征图。而 M c M_c Mc是经过最后一个卷积核大小为 1 ∗ 1 1*1 1∗1的卷积层。 T D A B = T i n + M c ( [ C A ( U ) , S A ( U ) ] ) (9) T_{DAB}=T_{in}+M_c([CA(U), SA(U)])\tag{9} TDAB=Tin+Mc([CA(U),SA(U)])(9)
CycleISP的联合训练
在RGB2RAW网络和RAW2RGB网络单独训练后,进行联合训练,即将RGB2RAW的输出变成RAW2RGB的输入。联合优化的损失函数如下公式所示,其中 β \beta β是一个正常量: L j o i n t = β L s → r ( I ^ r a w , I r a w + ( 1 − β ) L r → s ( I ^ r g b , I r g b ) ) \mathcal{L}_{joint}=\beta\mathcal{L}_{s\rightarrow r}(\hat{I}_{raw}, I_{raw} + (1-\beta)\mathcal{L}_{r\rightarrow s}(\hat{I}_{rgb}, I_{rgb})) Ljoint=βLs→r(I^raw,Iraw+(1−β)Lr→s(I^rgb,Irgb))
合成真实噪声数据生成
RAW去噪数据
CycleISP方法的RGB2RAW网络分支使用干净的sRGB图像作为输入,并将其转换为干净的RAW图像。就像下图的顶部分支。在训练CycleISP时,原本为“OFF”状态的噪声注入模块就需要变成“ON”状态。噪声注入模块在RGB2RAW网络的输出中添加不同级别的射频噪声和读噪声(shot and read noise)。作者使用和[7]中相同的程序来采样射频/读取(shot/read)噪声因子。因此,我们可以从任何sRGB图像生成干净及其对应的图像对 { R A W c l e a n , R A W n o i s e } \{RAW_{clean},RAW_{noise}\} {RAWclean,RAWnoise}。
sRGB去噪数据
给定合成的RAW噪声数据作为输入,RAW2RGB网络将其映射到一个噪声的sRGB图像(上图的底部分支)。因此,我们能够为sRGB去噪问题生成一个图像对 { s R G B c l e a r , s R G B n o i s e } \{sRGB_{clear},sRGB_{noise}\} {sRGBclear,sRGBnoise}。
虽然这些合成图像对已经足以训练去噪网络,但我们可以通过以下步骤进一步提高质量。使用真实相机捕获的SIDD数据集[1]对CycleISP模型进行微调。对于每个静态场景,SIDD在RAW和sRGB空间中都包含干净和有噪声的图像对。微调过程如下图4所示。注意,添加随机噪声的噪声注入模块被(仅用于微调)逐像素噪声残留( n o i s e = R A W n o i s y − R A W c l e a n noise=RAW_{noisy}-RAW_{clean} noise=RAWnoisy−RAWclean)所代替,其中 R A W n o i s y RAW_{noisy} RAWnoisy和 R A W c l e a n RAW_{clean} RAWclean的都是真实图像获得的。一旦微调过程完成,我们可以通过给CycleISP模型提供干净的sRGB图像来合成真实的噪声图像。

去噪框架
如下图5所示,作者提出了一个使用多个RRG的图像去噪网络,并将所提出的下面这个网络用语两组不同设置中:(1)RAW图像去噪;(2)sRGB图像去噪。在这两种设置下,使用相同的网络结构,唯一的区别在于输入和输出的处理。对于sRGB空间的去噪,网络的输入和输出是3通道的sRGB图像。对于RAW图像去噪,网络将4通道噪声填充图像与一个4通道噪声级别图连接作为输入,提供的是一个4通道压缩去噪输出。(For denoising the RAW images, our network takes as input a 4-channel noisy packed image concatenated with a 4-channel noise level map, and provides us with a 4-channel packed denoised output.)。噪声级别图提供了输入图像中存在的噪声的标准偏差的估计,基于其拍摄和读取噪声参数[7]。

论文实验
真实图像数据集
DND数据集,是由4款消费级相机捕获的50个去噪图像对。由于原图是超高分辨率的,所以提供者为每张图片提供了 20 20 20 个 512 ∗ 512 512*512 512∗512的切片(crop),所以一共有 20 ∗ 50 = 1000 20*50=1000 20∗50=1000个patches。由于ground-truth的无噪声图片没有公开,所以这个数据集通常用于测试。测试途径是在线服务可以计算得到PSNR和SSIM,RAW空间和sRGB空间均可。
SIDD数据集。由于小的sensor size和高分辨率,相比较于那些DSLRs,智能手机图像要有更多的噪声。这个数据集用五个智能手机相机手机而成。SIDD有320个图片对可以用于训练,1280个图片对可以用于验证。该数据集也提供了RAW空间和sRGB空间图像。
实现细节
使用Adam优化器, β 1 = 0.9 \beta_1=0.9 β1=0.9, β 2 = 0.999 \beta_2=0.999 β2=0.999,patchSize为128。使用拜耳统一(Bayer unification)和增强技术(水平翻转和垂直翻转)。DAB除了最后一个卷积层为 1 ∗ 1 1*1 1∗1,其他的卷积层均为 3 ∗ 3 3*3 3∗3。
CycleISP的初始训练
用MIT-Adobe FiveK数据集训练CycleISP模型。MIT-Adobe FiveK有 5000 5000 5000张RAW图像。作者使用LibRaw 库处理RAW图像,生成sRGB图像。拆分4850张图像用于训练,150张图像用于验证。
RGB2RAW网络和RAW2RGB网络均使用 3 3 3个RRGs和 5 5 5个DABs构建,使用 2 2 2个RRGs和 3 3 3个DABs用于颜色校正网络。CycleISP的RGB2RAW和RAW2RGB分支都独立训练 1200 1200 1200个epochs。batch size为 4 4 4,初始学习率为 1 0 − 4 10^{-4} 10−4,在 800 800 800个epoch后降到 1 0 − 5 10^{-5} 10−5。
CycleISP Fine-tuning
先用无噪声图像对CycleISP进行finetune,然后使用合成的噪声图像再次进行finetune。在前者中,CycleISP模型的输出是无噪声的;在后者中,输出是有噪声的。对于每个fine-tuning阶段,训练 600 600 600个epochs,batchSize设为 1 1 1,学习率为 1 0 − 5 10^{-5} 10−5。
去噪网络的训练
在四个训练集中,分别训练了四个网络,数据集分别为:(1)DND RAW 数据;(2)DND sRGB图像;(3)SIDD RAW 数据;(4)SIDD sRGB图像。四个网络,都使用 4 4 4个RRGs和 8 8 8个DABs, 65 65 65个epoch,batchSize为 16 16 16,初始学习率为 1 0 − 4 10^{-4} 10−4,每 25 25 25个epoch学习率衰减 10 10 10倍。
从MIR flickr扩展数据集(MIR flickr extended dataset)去了 1000000 1000000 1000000张图像,依据 90 : 5 : 5 90:5:5 90:5:5的比例划分用于训练、验证和测试。所有图像都使用标准差 σ = 1 \sigma=1 σ=1的高斯核进行预处理,以减少噪声和其他伪影的影响。然后使用前面得到干净/噪声图像对的方式获得数据用于训练。
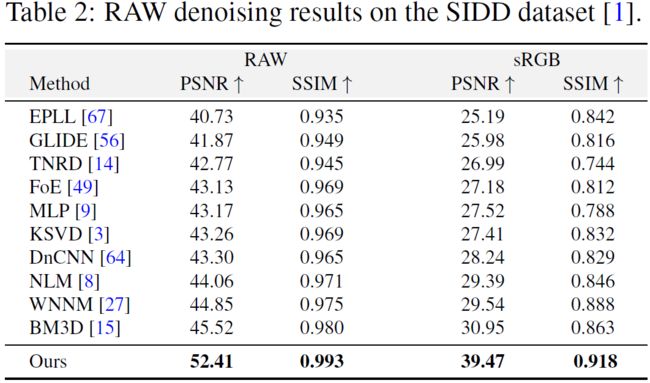
RAW去噪结果
下表展示了所有竞争方法在评估服务器[16]网站上获得的DND数据集的量化结果(PSNR/SSIM)。下表中有两个指标,RAW是在RAW空间去噪后的对比结果,sRGB列是服务器使用图像元数据将去噪后的RAW图像通过摄像机成像管道传递后提供的。本文模型的参数比之前最好的方法[7](2019.)要少5倍的参数。

下表是在SIDD数据集上RAW空间的去噪结果,表现和DND趋势基本一致。
下图是当时最先进网络的视觉对比效果。本文模型能有效地去除真实噪声,特别是低频色度噪声和缺陷像素噪声。

sRGB去噪结果
虽然建议对RAW数据(其中噪声不相关且不太复杂)[26]应用去噪,但去噪通常在sRGB域进行研究。下面两表展示了在DND和SIDD数据集上sRGB图像的去噪结果。
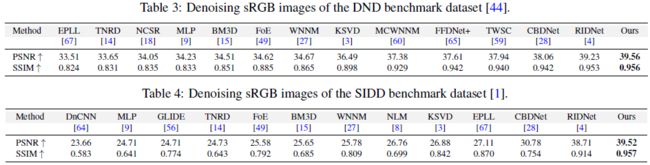
下面两图是在DND和SIDD上sRGB去噪的结果。为了去除噪声,大多数评估算法要么产生过平滑的图像(并牺牲图像细节),要么生成带有斑点纹理和色度伪影的图像。相比之下,本文的方法生成干净和无伪影的结果,同时忠实地保存图像细节。

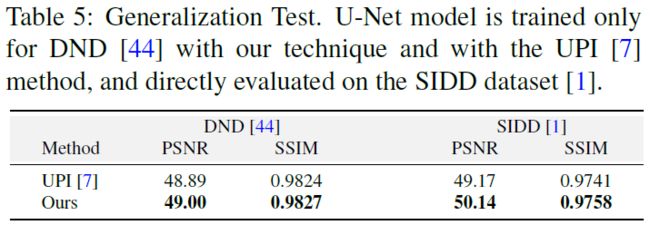
为了比较用我们的方法生成的合成数据训练的去噪模型与[7]的去噪模型的泛化能力,作者进行了以下实验。作者采用(公开的)为DND训练的[7]去噪模型,并直接在SIDD数据集的RAW图像上评估它。作者对去噪模型也重复相同的过程。为了公平的比较,作者使用与[7]相同的网络架构(U-Net)和噪声模型。唯一的区别是从sRGB到RAW的数据转换。表5的结果表明用本文的方法训练的去噪网络不仅在DND数据集上表现良好,而且对SIDD集也有很好的泛化效果(相较于[7]而言,增益大约 1 1 1 dB)。
消融学习
从小表可以看出,短的skip connections是最重要的一部分,其次是颜色校正分支。

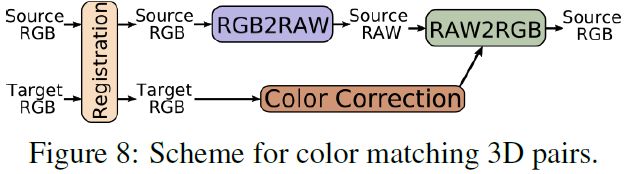
立体电影的色彩匹配