ccc-机器学习数学基础
偏向于理解,不涉及证明
Hello world:
代码:
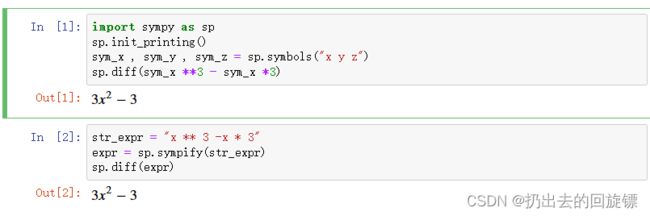
import sympy as sp
sp.init_printing()
sym_x , sym_y , sym_z = sp.symbols("x y z")
sp.diff(sym_x **3 - sym_x *3)
也可以简单一点:
str_expr = "x ** 3 -x * 3"
expr = sp.sympify(str_expr)
sp.diff(expr)
结果:
1.链式求导
h ′ ( x ) = f ′ ( g ( x ) ) g ′ ( x ) {\displaystyle h'(x)=f'(g(x))g'(x)} h′(x)=f′(g(x))g′(x)
等效
h ′ = ( f ∘ g ) ′ = ( f ′ ∘ g ) ⋅ g ′ {\displaystyle h'=(f\circ g)'=(f'\circ g)\cdot g'} h′=(f∘g)′=(f′∘g)⋅g′
莱布尼茨的符号表示
d z d x = d z d y ⋅ d y d x 或者 d z d x ∣ x = d z d y ∣ y ( x ) ⋅ d y d x ∣ x {\displaystyle {\frac {dz}{dx}}={\frac {dz}{dy}}\cdot {\frac {dy}{dx}}} 或者{\displaystyle \left.{\frac {dz}{dx}}\right|_{x}=\left.{\frac {dz}{dy}}\right|_{y(x)}\cdot \left.{\frac {dy}{dx}}\right|_{x}} dxdz=dydz⋅dxdy或者dxdz∣ ∣x=dydz∣ ∣y(x)⋅dxdy∣ ∣x
多变量函数的导数
∂ 2 y ∂ x i ∂ x j = ∑ k ( ∂ y ∂ u k ∂ 2 u k ∂ x i ∂ x j ) + ∑ k , ℓ ( ∂ 2 y ∂ u k ∂ u ℓ ∂ u k ∂ x i ∂ u ℓ ∂ x j ) {\frac {\partial ^{2}y}{\partial x_{i}\partial x_{j}}}=\sum _{k}\left({\frac {\partial y}{\partial u_{k}}}{\frac {\partial ^{2}u_{k}}{\partial x_{i}\partial x_{j}}}\right)+\sum _{{k,\ell }}\left({\frac {\partial ^{2}y}{\partial u_{k}\partial u_{\ell }}}{\frac {\partial u_{k}}{\partial x_{i}}}{\frac {\partial u_{\ell }}{\partial x_{j}}}\right) ∂xi∂xj∂2y=k∑(∂uk∂y∂xi∂xj∂2uk)+k,ℓ∑(∂uk∂uℓ∂2y∂xi∂uk∂xj∂uℓ)
2.费马定理
定理定义:设函数f(x)在点x0的某邻域U(x0)内有定义,并且在x0处可导,如果对任意的x∈U(x0),有f(x)≤f(x0)(或f(x)≥f(xo)),那么f’(x0)=0
解释:一段区间内的极值点如果它可导那么其导数一定等于0。反之不成立
3.泰勒展开
f ( a ) + f ′ ( a ) 1 ! ( x − a ) + f ′ ′ ( a ) 2 ! ( x − a ) 2 + f ′ ′ ′ ( a ) 3 ! ( x − a ) 3 + ⋯ {\displaystyle f(a)+{\frac {f'(a)}{1!}}(x-a)+{\frac {f''(a)}{2!}}(x-a)^{2}+{\frac {f'''(a)}{3!}}(x-a)^{3}+\cdots } f(a)+1!f′(a)(x−a)+2!f′′(a)(x−a)2+3!f′′′(a)(x−a)3+⋯
4.凸函数
典型凸函数的形状类似于字母U。 严格凸函数只有一个局部最低点,该点也是全局最低点。经典的 U 形函数都是严格凸函数。
5.偏导数
是一个比较基础的性质,反应函数沿轴的正方向的变化率。偏导存在不一定连续,连续也不一定偏导;可微一定连续,偏导一定存在;偏导连续则函数一定连续也一定可微。
6.方向导数
反应的是函数y在某一点X0处沿着特定方向(不一定是轴正方向)的变化率。
7.可微函数
可微函数是平滑的(该函数在每个内部点处局部很好地近似为线性函数)并且不包含任何中断、角度或尖点。一般情况会利用偏导连续来证明可微。
8.梯度
一个函数沿各方向上的变化率,经常用来通过梯度上升来最大化函数。
雅可比矩阵(Jacobian):多个变量的向量值函数的一阶偏导数的矩阵
J = [ ∂ f ∂ x 1 ⋯ ∂ f ∂ x n ] = [ ∇ T f 1 ⋮ ∇ T f m ] = [ ∂ f 1 ∂ x 1 ⋯ ∂ f 1 ∂ x n ⋮ ⋱ ⋮ ∂ f m ∂ x 1 ⋯ ∂ f m ∂ x n ] {\displaystyle \mathbf {J} ={\begin{bmatrix}{\dfrac {\partial \mathbf {f} }{\partial x_{1}}}&\cdots &{\dfrac {\partial \mathbf {f} }{\partial x_{n}}}\end{bmatrix}}={\begin{bmatrix}\nabla ^{\mathsf {T}}f_{1}\\\vdots \\\nabla ^{\mathsf {T}}f_{m}\end{bmatrix}}={\begin{bmatrix}{\dfrac {\partial f_{1}}{\partial x_{1}}}&\cdots &{\dfrac {\partial f_{1}}{\partial x_{n}}}\\\vdots &\ddots &\vdots \\{\dfrac {\partial f_{m}}{\partial x_{1}}}&\cdots &{\dfrac {\partial f_{m}}{\partial x_{n}}}\end{bmatrix}}} J=[∂x1∂f⋯∂xn∂f]=⎣ ⎡∇Tf1⋮∇Tfm⎦ ⎤=⎣ ⎡∂x1∂f1⋮∂x1∂fm⋯⋱⋯∂xn∂f1⋮∂xn∂fm⎦ ⎤
9.黑森矩阵(Hessian_matrix):
如果实多元函数的所有的二阶偏导数存在,则有
H f = [ ∂ 2 f ∂ x 1 2 ∂ 2 f ∂ x 1 ∂ x 2 ⋯ ∂ 2 f ∂ x 1 ∂ x n ∂ 2 f ∂ x 2 ∂ x 1 ∂ 2 f ∂ x 2 2 ⋯ ∂ 2 f ∂ x 2 ∂ x n ⋮ ⋮ ⋱ ⋮ ∂ 2 f ∂ x n ∂ x 1 ∂ 2 f ∂ x n ∂ x 2 ⋯ ∂ 2 f ∂ x n 2 ] , {\displaystyle \mathbf {H} _{f}={\begin{bmatrix}{\dfrac {\partial ^{2}f}{\partial x_{1}^{2}}}&{\dfrac {\partial ^{2}f}{\partial x_{1}\,\partial x_{2}}}&\cdots &{\dfrac {\partial ^{2}f}{\partial x_{1}\,\partial x_{n}}}\\[2.2ex]{\dfrac {\partial ^{2}f}{\partial x_{2}\,\partial x_{1}}}&{\dfrac {\partial ^{2}f}{\partial x_{2}^{2}}}&\cdots &{\dfrac {\partial ^{2}f}{\partial x_{2}\,\partial x_{n}}}\\[2.2ex]\vdots &\vdots &\ddots &\vdots \\[2.2ex]{\dfrac {\partial ^{2}f}{\partial x_{n}\,\partial x_{1}}}&{\dfrac {\partial ^{2}f}{\partial x_{n}\,\partial x_{2}}}&\cdots &{\dfrac {\partial ^{2}f}{\partial x_{n}^{2}}}\end{bmatrix}},} Hf=⎣ ⎡∂x12∂2f∂x2∂x1∂2f⋮∂xn∂x1∂2f∂x1∂x2∂2f∂x22∂2f⋮∂xn∂x2∂2f⋯⋯⋱⋯∂x1∂xn∂2f∂x2∂xn∂2f⋮∂xn2∂2f⎦ ⎤,
该矩阵描述多变量的函数的局部曲率
10.拉格朗日乘数法
基本思想是通过引入拉格朗日乘子来将含有n个变量和k个约束条件的约束优化问题转化为含有(n+k)个变量的无约束优化问题:即为了找到一个函数的最大值或最小值f(x)受到等式约束g(x)=0, 形成拉格朗日函数
L ( x , λ ) = f ( x ) + λ g ( x ) {\displaystyle {\mathcal {L}}(x,\lambda )=f(x)+\lambda g(x)} L(x,λ)=f(x)+λg(x)
参考网站:
wiki-导数
自助在线求导网站
wiki-链式求导
wiki-泰勒
wiki-可微分函数
wiki-梯度
wiki-黑森矩阵
wiki-拉格朗日乘数法
拉格朗日乘数法的实例理解