语义分割--Understand Convolution for Semantic Segmentation
Understanding Convolution for Semantic Segmentation
Understanding Convolution for Semantic Segmentation
收录:IEEE Winter Conference on Applications of Computer Vision (WACV 2018)
原文地址:HDC
代码:
- 官方-MXNet
Abstract
本文介绍了两种操控卷积相关运算(convolution-related operations)方法用于提高语义分割效果:
-
设计**密集上采样卷积(dense upsampling convolution,DUC)**生成预测结果,这可以捕获在双线性上采样过程中丢失的细节信息。
-
设计混合空洞卷积框架(hybrid dilated convolution,HDC),用于减轻扩张卷积产生的"gidding issue"影响,扩大接收野聚合全局信息。
论文在CityScapes上达到了80.1%mIoU,同样在KITTI和VOC12上也达到了state-of-the-art 结果.
Introduction
大部分应用在语义分割任务上的CNN系统可分为三类:
- 全卷积神经网络。例如FCN. 使用卷积层代替FC层,提高训练和推断效率,并可接收任意大小输入;
- 使用CRF. 结构预测用于捕获图片内的本地和长距离依赖,用于细化分割结果;
- 使用空洞卷积。增加中间featue map的分辨率,可在保持相同计算成本的同时提高预测精度。
大部分提高预测准确率的系统可分为两类:
- 使用更优秀的特征提取模型。即使用VGG16、ResNet等预训练架构。这些更深的模型可对更复杂的信息建模,学习更有区分力的feature并可更好的区分类别。
- 使用CRF作为后端处理,集成CRF到模型内构成end2end训练,并将额外的信息例如边缘合并到CRF内。
本文以另一个角度来提升性能,考虑到现在大多数模型分为encoding和decoding两部分:
-
对于decoding:大多数模型在最终预测图的基础上,采用双线性插值上采样直接获得与输入同分辨率的输出,双线性插值没有学习能力并且会丢失细节。本文提出了密集上采样卷积(dense upsampling convolution,DUC),取代了简单的双线性插值,学习一组上采样滤波器用于放大低分辨率的feature。DUC支持end2end,便于融入FCN网络架构中。
-
对于encoding:使用扩张卷积可以扩大感受野,减少使用下采样(下采样丢失细节比较严重)。本文指出空洞卷积存在"girdding"问题,即空洞卷积在卷积核两个采样像素之间插入0值,如果扩张率过大,卷积会过于稀疏,捕获信息能力差。 本文提出了混合扩展卷积架构(hybrid dilation convolution,HDC): 使用一组扩展率卷积串接一下构成block,可扩大感受野的同时减轻"gridding"弊端。
论文以DUC和HDC为基础卷积操作,构建更适合语义分割任务的深度神经网络系统.
Related Work
-
**特征表示解码(Decoding of Feature Representation)?*因为池化操作不可避免的会下采样。现在多种方案针对低分辨率feature解码出准确信息,常见的双线性上采样节省存储空间并且快;解卷积:使用池化的位置信息帮助解码阶段,也有使用堆叠的解卷积层来恢复信息,等等
-
扩张卷积(Dilated Convolution): 在卷积采样中插入0值,用以扩张采样分辨率。例如DeepLab设计的ASPP聚合多个尺度信息。等等
Approach
Dense Upsampling Convolution
为什么要使用DUC?
考虑到模型输入图片大小 ( H , W , C ) (H,W,C) (H,W,C),整个模型在预测前的输出feature map大小为 F o u t = ( h , w , c ) F_{out}=(h,w,c) Fout=(h,w,c),其中 H / d = h , W / d = w H/d=h, W/d=w H/d=h,W/d=w, d d d称为下采样因子(downsampling factor)。
- 双线性插值存在的问题:如果模型的 d = 16 d=16 d=16,即输入到输出下采样了16倍。如果一个目标物的长或宽长度小于16个pixel,训练label map需要下采样到与模型输出维度相同,即下采样16倍时已经丢失了许多细节, 对应的模型预测结果双线性插值上采样是无法恢复这个信息 。
DUC的方案:
针对这一问题,DUC将 F o u t F_{out} Fout的尺寸 ( h , w , c ) (h,w,c) (h,w,c)通道转为到 ( h , w , d 2 × L ) (h,w,d^2×L) (h,w,d2×L), L L L是分割类别数目。再reshape到label map大小 ( H , W , L ) (H,W,L) (H,W,L)。 reshape操作代替了解卷积上采样,可直接对接label map。
这里比较难理解的是reshape操作,开源的代码如下:
# Base Network
res = get_resnet_hdc(bn_use_global_stats=bn_use_global_stats)
# ASPP
aspp_list = list()
for i in range(aspp_num):
pad = ((i + 1) * aspp_stride, (i + 1) * aspp_stride)
dilate = pad
conv_aspp=mx.symbol.Convolution(data=res, num_filter=cell_cap * label_num, kernel=(3, 3), pad=pad,
dilate=dilate, name=('fc1_%s_c%d' % (exp, i)), workspace=8192)
aspp_list.append(conv_aspp)
# 这是是ASPP模块输出作像素和
summ = mx.symbol.ElementWiseSum(*aspp_list, name=('fc1_%s' % exp))
# Reshape操作
cls_score_reshape = mx.symbol.Reshape(data=summ, shape=(0, label_num, -1), name='cls_score_reshape')
# Reshape完后直接送到Softmax
cls = mx.symbol.SoftmaxOutput(data=cls_score_reshape, multi_output=True,
normalization='valid', use_ignore=True, ignore_label=ignore_label, name='seg_loss')
return cls
可以看到reshape操作传入的是shape= ( 0 , l a b e l _ n u m , − 1 ) (0, label\_num, -1) (0,label_num,−1) MXNet中0代表保持不变,-1表示推断~.
ASPP出来的数据形式为(N,channel,h,w)经过reshape甩成了(N,label_num,-1),即把每类的分类结果拍成向量形式。
下图是本文一作关于DUC卷积的回答:

下图更好的阐述了DUC思想:

该图来自:Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
从另一个角度想:DUC将整个label map ( H , W , L ) (H,W,L) (H,W,L)分为为 d 2 d^2 d2个等大小的子图(subparts),每个子图和大小和 F o u t F_{out} Fout输出的feature map大小相同。也就是说将label map切分为 ( h , w , d 2 × L ) (h,w,d^2×L) (h,w,d2×L)。
模型的整体结构如下,DUC应用在输出部分:

DUC以原始分辨率像素级解码,并且能够自然的集成到FCN框架中,使得整个编码和解码能以end2end方式训练。
Hybrid Dilated Convolution
对于二维信号,卷积核大小 k × k k×k k×k,经过扩张卷积的结果为 k d × k d k_d×k_d kd×kd,其中 k d = k + ( k − 1 ) ( r − 1 ) k_d=k+(k-1)(r-1) kd=k+(k−1)(r−1).例如:

- 对于左边: r = 2 , k = 3 r=2,k=3 r=2,k=3. k d = 3 + ( 3 − 1 ) ( 2 − 1 ) = 5 k_d=3+(3-1)(2-1)=5 kd=3+(3−1)(2−1)=5,接收野为 5 × 5 5×5 5×5
- 对于右边: r = 3 , k = 3 r=3,k=3 r=3,k=3. k d = 3 + ( 3 − 1 ) ( 3 − 1 ) = 7 k_d=3+(3-1)(3-1)=7 kd=3+(3−1)(3−1)=7,接收野为 7 × 7 7×7 7×7
扩张卷积可增加features map的分辨率,故可替换FCN架构中的池化层。但是,扩张卷积存在一个理论上的问题,称之为"gridding":对于扩张卷积的一个像素点p,对其有贡献的是上一层以p为中心的 k d × k d k_d×k_d kd×kd的邻近区域,因为扩张卷积引入0值,在 k d × k d k_d×k_d kd×kd的区域只计算 k × k k×k k×k个像素点,非0像素点之间间隔为 r − 1 r-1 r−1.
例如 k = 3 , r = 2 k=3,r=2 k=3,r=2的扩张卷积,从 C o n v 2 − − > C o n v 3 Conv2-->Conv3 Conv2−−>Conv3,25个像素只有9个像素做了贡献:

可以看到top feature map使用扩张卷积只能以棋盘的形式查看信息,这会丢失大量信息.
-
当high layer中 r r r变的越来越大,这会使得从输入中采样的数据越来越稀疏,不利于卷积学习,因为
- 局部的信息完全丢失
- 信息之间太远不相关
-
r × r r×r r×r的区域从完全不同的“网格”集合内接收信息,这会损害本地信息的一致性。
论文提出了HDC用于缓解"gridding"产生的影响:考虑到一个 N N N个的size为 K × K K×K K×K的扩张卷积,对应的扩张率为 [ r 1 , … , r i , . . , r n ] [r_1,…,r_i,..,r_n] [r1,…,ri,..,rn],HDC的目标是让最后的接收野全覆盖整个区域(没有任何空洞或丢失边缘),我们定义两个非零点之间最大距离为: M i = max [ M i + 1 − 2 r i , M i + 1 − 2 ( M i + 1 − r i ) , r i ] M_i=\max[M_{i+1}-2r_i,M_{i+1}-2(M_{i+1}-r_i),r_i] Mi=max[Mi+1−2ri,Mi+1−2(Mi+1−ri),ri]
其中 M n = r n M_n=r_n Mn=rn,设计的目标是让 M 2 ≤ K M_2≤K M2≤K.
这是公式是怎么来的,我邮件咨询了一作PanQu Wang:

HDC实例:
-
对于常见的扩张卷积核大小 K = 3 K=3 K=3,如果 r = [ 1 , 2 , 5 ] r=[1,2,5] r=[1,2,5] 则 M 2 = max [ M 3 − 2 r 2 , − M 3 + 2 r 2 , r 2 ] = max [ 1 , − 1 , 2 ] = 2 M_2=\max[M_3-2r_2,-M_3+2r_2,r_2]=\max[1,-1,2]=2 M2=max[M3−2r2,−M3+2r2,r2]=max[1,−1,2]=2此时 M 2 = 2 ≤ K = 3 M_2=2≤K=3 M2=2≤K=3,满足设计要求.设计的示意图如下:

-
如果 r = [ 1 , 2 , 9 ] r=[1,2,9] r=[1,2,9]则 M 2 = max [ M 3 − 2 r 2 , − M 3 + 2 r 2 , r 2 ] = max [ 5 , − 5 , 2 ] = 5 M_2=\max[M_3-2r_2,-M_3+2r_2,r_2]=\max[5,-5,2]=5 M2=max[M3−2r2,−M3+2r2,r2]=max[5,−5,2]=5此时 M 2 = 5 > K = 3 M_2=5>K=3 M2=5>K=3,不满足设计要求.

论文给出使用不同扩张率的扩张卷积策略是锯齿波(sawtooth wave-like)变化形式:即取几层为一组,每个组的扩张率从低向高增加,每个组类似,即扩张率变换类似锯齿波。锯齿波能同时满足小物体大物体的分割要求(小rate提取本地信息,大rate提取长距离信息)。
例如:对于r=2的层,将3个层组成一组,对应的扩张率分别为1,2,3。这样顶层可以获取更宽阔的区域信息,这能在保持接收野大小不变的情况下提高信息利用率。

需要注意的是,一个组内的卷积不应该有一个固定的变换因子,即不要用大于1的公约数(例如2,4,8的公约数为2>1),否则依旧无法减小"girdding"效应。
HDC的另一个好处是可以使用任意的扩张率,很自然的扩大了接收野且不需要添加额外的模块,这对识别大型相关目标很关键。
Experiment
论文一共在三个数据集上做了测试:CityScapes,KITTI dataset for road estimation, PASCAL VOC2012. 以预训练的ResNet101和ResNet152为特征提取层。
CityScapes
CityScapes的数据尺寸固定为 1024 × 2048 1024×2048 1024×2048,本文的策略是将图片分成重叠的12个 800 × 800 800×800 800×800的patches,整个训练集大小为 2975 ∗ 12 = 35700 2975*12=35700 2975∗12=35700.这样的数据增强可保证图片的每个区域都被访问到,比随机的cropping要跟细腻。
Baseline-model:
| 设置项 | 设置 |
|---|---|
| 优化器 | 使用mini-batch SGD |
| patch size | 544 × 544 544×544 544×544(randomly cropped from the 800x800 patch) |
| batch_size | 12 |
| 学习率策略 | poly,power=0.9,初始的学习率为 2.5 × 1 0 − 4 2.5×10^{-4} 2.5×10−4. |
| 权重衰减 | 5 × 1 0 − 4 5×10^{-4} 5×10−4,momentum为0.9 |
DUC
DUC做的事情就是改变原本top layer输出的shape.
例如:Baseline-model的输出为 68 × 68 × 19 68×68×19 68×68×19(19是cityscapes的类别)。DUC将输出变化为 68 × 68 × ( d 2 × 19 ) 68×68×(d^2×19) 68×68×(d2×19), d d d是下采样因子,这里 r = 8 r=8 r=8. 再reshape为 544 × 544 × 19 544×544×19 544×544×19即预测的map. DUC只在ResNet的top端引入了新参数,与Baseline相比,提高了2%mIoU,可视化结果如下:

由图可以清晰的看见DUC主要提高了小目标物的识别率,验证了DUC可以恢复双线性插值上采样损失的信息。
Abation Studies:主要做以下方面的实验.
- 网络的下采样扩张率,用于控制内部的feature map的分辨率
- 是否使用ASPP模块,以及使用并行路径的数量
- 是否做数据增强,即将数据切分为12个子patches
- 一个预测像素投影的邻近区域大小 ( c e l l , c e l l ) (cell,cell) (cell,cell).像素级的DUC应该使用 c e l l = 1 cell=1 cell=1,但因为Gound Truth无法达到像素级,在实验中尝试 c e l l = 2 cell=2 cell=2

降低下采样率会降低准确率。ASPP模块通常有助于改善性能。数据增强有助于提高准确率,使用cell=2有轻微的提升,同时有助于降低计算消耗。
Bigger Patch Size: 因为 c e l l = 2 cell=2 cell=2会大幅度减少计算量消耗,故讨论patch size对性能的影响。将patch size提高到 880 × 880 880×880 880×880,将原本的12倍cropping换成7倍的cropping,性能提升了1%;
Compared with Deconvolution: 使用上采样效率略低于DUC model;
Conditional Random Fields(CRF): 使用CRF提高了1%的性能。
HDC
以最佳的101 layer的ResNet-DUC为基础,添加HDC,实验探究了几种变体:
- 无扩张卷积(no dilation):对于所有包含扩张卷积,设置 r = 1 r=1 r=1
- 扩张卷积(dilation Conv ):对于所有包含扩张卷积,将2个block和为一组,设置第一个block的 r = 2 r=2 r=2,第二个block的 r = 1 r=1 r=1
- Dilation-RF:对于 r e s 4 b res4b res4b包含了23个blocks,使用的 r = 2 r=2 r=2,设置3个block一组, r = 1 , 2 , 3 r=1,2,3 r=1,2,3.对于最后两个block,设置 r = 2 r=2 r=2;对于 r e s 5 b res5b res5b,包含3个block,使用 r = 4 r=4 r=4,设置为 r = 3 , 4 , 5 r=3,4,5 r=3,4,5.
- Dilation-Bigger:对于 r e s 4 b res4b res4b模块,设置4个block为一组,设置 r = 1 , 2 , 5 , 9 r=1,2,5,9 r=1,2,5,9.最后3个block设置为 1 , 2 , 5 1,2,5 1,2,5;对于 r e s 5 b res5b res5b模块,设置 r = 5 , 9 , 17 r=5,9,17 r=5,9,17

可以看到增加接收野大小会获得较高的精度。如下图所示:

ResNet-DUC-HDC在较大的目标物上表现较好。下图是局部放大:

可以看到HDC有效的消除"gridding"产生的影响。
Deeper Networks: 同样尝试了将ResNet-101切换为ResNet-152,使用ResNet152先跑了10个epoch学习了BN层参数,再固定BN层,跑了20个epochs.结果如下:

ResNet152为基础层的有1%的提升。
Test Set Results: 论文将ResNet101开始的 7 × 7 7×7 7×7卷积拆分为3个 3 × 3 3×3 3×3的卷积,再不带CRF的情况下达到了80.1%mIoU.与其他先进模型相比如下:

模型同时在coarse labels跑了一圈,与同样以deliated convolution为主的DeepLabv2相比,提升了9.7%.
KITTI Road Segmentaiton
KITTI有289的训练图片和290个测试图片。示例如下:

因为数据集有限,为了避免过拟合。论文以100的步长在数据集中裁剪 320 × 320 320×320 320×320的patch. 使用预训练模型,结果如下:

结果达到了state-of-the-art水平.
PASCAL VOC2012 dataset
先用VOC2012训练集和MS-COCO数据集对ResNet-DUC做预训练。再使用VOC2012做fine-tune。使用的图片大小为 512 × 512 512×512 512×512。达到了state-of-the-art水平:
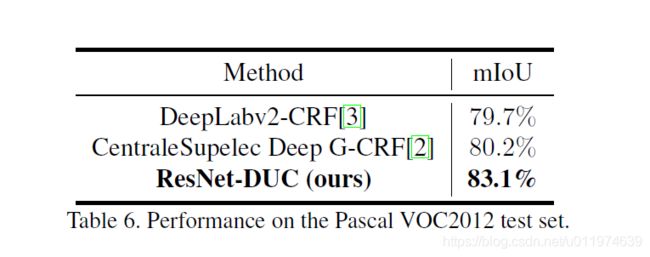
可视化结果如下:

Conclusion
论文提出了简单有效的卷积操作改进语义分割系统。使用DUC恢复上采样丢失的信息,使用HDC在解决"gridding"的影响的同时扩大感受野。实验证明我们的框架对各种语义分割任务的有效性。