Image/Video Deep Anomaly Detection: A Survey阅读笔记
Image/Video Deep Anomaly Detection: A Survey阅读笔记
文章目录
- Image/Video Deep Anomaly Detection: A Survey阅读笔记
-
-
- Abstract
- 1、Introduction
- 2、Problem Formulation
-
- 2.1、 p N p_N pN:Modeling Normal Data
- 2.2、 D D D:Detection Measure
- 3、Supervision
-
- Supervised
- Semi-supervised
- Unsupervised( u u u)
- 4、Deep Image/Video Representation
-
- 4.1 Traditional Features
- 4.2 Deep Features
- Featyre Learning
- Pre-trained Networks
- 5、Deep Networks for AD
-
- 5.1 Self-supervised Learning
-
- Encoder-Decoder Based Methods
- CNNs
- 5.2 Generative Networks
- 5.3 Anomaly Generation
- 6 Datasets
-
- Image
- Video
- 7、Open Challenges and Future Directions
-
- Detection and False Positive Rate
- Fairness
- Explanation of the AD Method
- Object Interaction
- Safety
- Adoptable AD
- Generationg Outliers
- Realistic Datasets
- Early Detection or Prediction
- 8、Conclusions
-
Abstract
异常检测问题非常重要,最近,深度神经网络(DNNs)提出了一套高性能解决方案,但是代价是巨大的计算成本。
1、Introduction
给出异常检测(AD)的定义,直接学习找到异常数据非常难,计算量大;提出,学习所有正常数据的共有分布,而不是学习不规则的异常数据。
如果输入的实例与学习到的正常数据的模型的偏差,来说明是否是异常的。
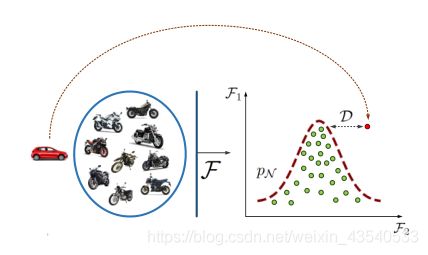
AD算法的共同弱点:
- 误报率高(high false positive rate):漏检隐患大,能够容忍稍多的误报,但是高虚警率带来了不可靠性和无效性。
- 高成本计算(high computational cost)
- 缺少标准数据集进行评估
2、Problem Formulation
U U U个未标记的图像或者视频帧,表示为 X N X_N XN,假设符合正太数据( P N P_N PN)的分布,那么异常检测(AD)可以认为是输入一个测试样本,判断是否符合 P N P_N PN分布的过程,如果不符合,则判定为异常数据。

其中 D D D是计算给定样例之间的距离和正常数据分布的度量。 F F F是特征提取器。
三种训练方法的区分:
根据训练集中用到的正常数据、异常数据、和未标记样本的数量,分为——有监督,半监督和无监督的
无监督的学习技术在现实情况下更有效和适用。
数据实例的高维度和高多样性,显式学习或者拟合分布以及利用距离度量学习并不简单。
目前学习的必要步骤是:先从原始数据中学习或者选择一种又区别的表示(降维),然后再采用基于机器学习的方法来学习概率或者概率分布。
2.1、 p N p_N pN:Modeling Normal Data
普通数据建模——略
2.2、 D D D:Detection Measure
D D D用来区分偏离正常参考模型的数据度量。
3、Supervision
Supervised
适用非常有限,对于类别不平衡,是次优的,即,正常样本的数目远远多余异常样本的类别数据
Semi-supervised
现实中有大量未标记的数据,同时收集异常数据非常昂贵,获得完整的异常数据和正常数据训练是几乎不可能的。
**[Ruff et al., 2019; Liu et al., 2019]**提出了一种基于大量未标记样本和少量异常样本和正常数据(N + A << U)的学习模型
[Ruff et al., 2019] Lukas Ruff, Robert A V andermeulen, Nico
G¨ ornitz, Alexander Binder, Emmanuel M¨ uller, Klaus-
Robert M¨ uller, and Marius Kloft. Deep semi-supervised
anomaly detection. In ICLR, 2019.[Liu et al., 2019] Wen Liu, Weixin Luo, Zhengxin Li, Peilin
Zhao, Shenghua Gao, et al. Margin learning embedded pre-
diction for video anomaly detection with a few anomalies.
In IJCAI, pages 3023–3030, 2019.
Unsupervised( u u u)
前提假设,异常数据很少发生或者很少出现在未标记的样本中。由于异常事件没有精确定义,并且再可用数据中非常偶然的出现。
4、Deep Image/Video Representation
4.1 Traditional Features
基于轨迹特征、或者例如梯度直方图、直方图光流等低级特征。
缺点:高计算成本、低性能。
视频的时间和空间特性对于异常检测任务起着至关重要的作用。深度学习中,普遍使用RNN、LSTM和3D-CNN来获取包含时间特征的AD任务。空间上通过加深网络层数来提取。
4.2 Deep Features
分为两种:特征学习和预训练网络
Featyre Learning
[Xu et al., 2018]提出使用堆叠去噪自动编码器来学习特征,再将其作为其他模型的输入。
[Xu et al., 2018] Haowen Xu, Wenxiao Chen, Nengwen
Zhao, Zeyan Li, Jiahao Bu, Zhihan Li, Ying Liu, Y oujian
Zhao, Dan Pei, Yang Feng, et al. Unsupervised anomaly
detection via variational auto-encoder for seasonal kpis in
web applications. In WWW, pages 187–196, 2018.
Pre-trained Networks
使用迁移学习
5、Deep Networks for AD
端到端的DNN,包括:
自监督学习、生成网络和异常生成
5.1 Self-supervised Learning
现实应用中,模型只访问正常数据或者最小化的异常数据。通过端到端训练神经网络来学习正常数据的 P N P_N PN分布。训练完成后,给定一个测试样本,输入到模型,如果不符合约束,即不符合 P N P_N PN分布,则认为该样本为异常数据。
Encoder-Decoder Based Methods
学习自编码器的网络参数,以精确重建训练实例,即正常数据。
这些网络参数通过等式2来训练:

其中 D ( E ( X ) ) D(E(X)) D(E(X))是隐含学习正态数据分布的编解码网络。直接使用编码器-解码器进行重构,是拟合分布数据最简单的方法。虽然有效但是,假阳性检测有问题。
通过使用自编码器的潜在空间可以获得更好的结果。
虽然相对误差是区分正常和异常的有用便准,但是高误差并不是决定证据。
[Liu et al., 2018]通过U-Net作为深度自编码器来预测视频的下一帧,在训练阶段,神经网络的输入(时间t或It的帧)和输出(时间t + 1或It+1的帧)都是正常的,即遵循正常帧(pN)的分布。在测试阶段,如果某个帧明显偏离了预测值,则该帧被视为异常样本。
[Liu et al., 2018] Wen Liu, Weixin Luo, Dongze Lian, and
Shenghua Gao. Future frame prediction for anomaly detec-
tion – a new baseline. In CVPR, pages 6536–6545, 2018.
CNNs
一般图像和视频维度过高,计算成本巨大,解决办法,通过分析神经网络对于不同类型输入数据的不同响应来检测分布不均匀的数据。这种方式不是端到端训练。
5.2 Generative Networks
使用GAN来解决
主要缺点昂贵的训练,不稳定,复现困难,模式崩溃。
5.3 Anomaly Generation
略
6 Datasets
Image
MNIST、CIFAR-10和CIFAR-100、ImageNet、MVTec
Video
UMN、UCSD、CUHK、UCF-Crime、ShanghaiTech Campus、Street Scene
7、Open Challenges and Future Directions
Detection and False Positive Rate
虽然一些模型具有显著的准确性,但是不能有效的处理高虚警率。
提出一种检测率高,同时保持低误报率的方法是一个有价值的研究课题。
Fairness
略
Explanation of the AD Method
Object Interaction
Safety
DNN易受到攻击
Adoptable AD
Generationg Outliers
Realistic Datasets
Early Detection or Prediction
8、Conclusions
主要精力在无监督学习上,同时给出了精确的异常检测概念的定义。