扩散模型:Diffusion models as plug-and-play priors作为即插即用先验的扩散模型
扩散模型:Diffusion models as plug-and-play priors作为即插即用先验的扩散模型
- 0.摘要
- 1.概述
- 2.方法
-
- 2.1.问题设置
- 2.2.将去噪扩散概率模型作为先验
- 3.实验:图像生成
-
- 3.1.MNIST的简单说明
- 3.2.使用现成组件条件生成脸部图像
- 4.实验:语义分割
- 附录B:实验细节和扩展
-
- B.1:MNIST
- B.2:FFHQ
- B.3:土地覆盖
- 参考文献
论文下载
开源代码
0.摘要
我们考虑在一个由先验p(x)和辅助可微约束c(x,y)组成的模型中推断高维数据的问题。在本文中,先验是一个独立训练的去噪扩散生成模型。辅助约束预计具有可微形式,但可以来自不同的来源。这种推断的可能性将扩散模型转化为即插即用模型,从而允许在适应模型的领域和任务(如条件生成或图像分割)方面的一系列潜在应用。扩散模型的结构允许我们通过在每个步骤中富含不同数量噪声的固定去噪网络迭代微分来执行近似推断。考虑到x的许多噪声版本,对其适应度的评估是一种新的搜索机制,可能会导致解决组合优化问题的新算法。
1.概述
深度生成模型,如去噪扩散概率模型[DDPMs;39,13]可以捕捉高维连续数据地图p(x)上非常复杂的分布细节[30,7,1,38,43,15]。DDPM的巨大有效深度,有时在生成过程中有成千上万的深度网络评估,这明显限制了它们在分层生成模型中作为现成模块的使用,其中模型可以混合,一个模型可以作为另一个条件模型的先验。在本文中,我们证明了在图像数据上训练的DDPM可以直接用作包含其他可微约束的系统的先验
在我们的主要问题设置中,我们假设我们在高维数据上有一个先验p(x),我们希望在一个模型中执行推理,该模型包含这个先验和一个约束(x,y)以及给定的一些附加信息。也就是说,我们要找到后验分布p(x|y)∝p(x)c(x,y)的近似。在本文中, p ( x = x 0 , h = x T , … , x 1 ) p(x=x_0,h={x_T,…,x_1}) p(x=x0,h=xT,…,x1)以在xT,…,x0独立训练的DDPM的形式提供(§2.2),使DDPM成为“即插即用”先验。
尽管最近社区对DDPM的兴趣促进了训练算法和快速生成计划的进展[30,37,45],但它们作为即插即用模块使用的可能性还没有被探索。此外,与即插即用模型的现有工作(从[29]开始)不同,我们提出的算法不需要对模型组件或推理网络进行传统的训练或微调。
即插即用先验的一个明显应用是条件图像生成(§3.1,§3.2)。例如,在MNIST数字图像上训练的去噪扩散模型可能定义p(x),而约束c(x,y)可能是现有分类器下数字分类的概率。然而,通过改变x的语义,我们也可以将这种模型用于神经网络难以适应领域的推理任务,例如图像分割:c(x,y)约束分割x以匹配外观或弱标签(§4)。最后,我们描述了一种使用DDPM先验解决组合搜索问题的连续松弛的途径,方法是将y作为具有x中确定性编码的组合结构的潜在变量(§5)。
2.方法
2.1.问题设置
回想一下,我们想找到**后验分布p(x|y)∝p(x)c(x,y)**的近似,其中p(x)是一个固定的先验分布。固定y并引入近似变分后验q(x),自由能量:
![]()
当q(x)最接近真实的后验、KL(q(x)||p(x|y))最小时 自由能最小。当q(x)和用于拟合它的学习算法具有足够的表达能力来捕获真后验时,这种最小化产生精确的后验p(x|y)。否则,q将捕捉到“模式寻找”近似真正的后验[27];特别地,如果q(y)是狄拉克函数,在p(x|y)模式下集中。当先验涉及潜变量(即p(x) =∫hp(x|h)p(h)dh)时,自由能为
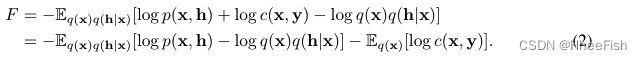
我们特别感兴趣的是,当为DDPM(§2.2)时,对于任何可微集,F对近似匹配的后验q(x)求极小化的一般过程。
在[43]中也研究了相同结构的自由能,其中潜伏空间上的DDPM p(z)被杂交为解码器p(x|z)的双亲,并使用一个附加的推理模型q(z|x)与这两个模型联合训练。另一方面,我们的目标是使用独立训练的组件,这些组件直接在像素空间中操作,例如,在人脸图像上训练的现成的扩散模型p(x)和现成的人脸分类器p(y|x),而不需要联合训练或调整它们(§3.2)。
2.2.将去噪扩散概率模型作为先验
去噪扩散概率模型(DDPMs)[39,13]通过反转(高斯)噪声过程生成样本x0。DDPM是深度有向随机网络:

μθ和Σθ是具有学习参数的神经网络(通常,如本文中所述,Σθ固定为依赖于t的标量对角矩阵)。该模型从单位高斯矩阵的样本开始,根据噪声时间表,在每步增加一个小高斯变换信号的非线性网络μθ(xt,t)对样本进行变换。经过T步,得到采样x=x0。
一般情况下,使用这样的模型作为x的先验将需要对潜在变量h=(xT,…,x1)进行棘手的积分

然而,训练DDPM的前提是,假定后验q(xt|xt−1)是一个简单的扩散过程,根据预定义的调度βt依次添加高斯噪声:
![]()
因此,如果p(x)是在DDPM下x的可能性(5),那么在(2)的第一个期望中,我们应该使用 q ( h = x T , … , x 1 ∣ x 0 = x ) = ∏ t = 1 T q ( x T ∣ x T − 1 ) q(h={x_T,…,x_1}|x_0=x) = \prod ^T_{t=1}q(x_T | x_{T−1}) q(h=xT,…,x1∣x0=x)=∏t=1Tq(xT∣xT−1)。x=x0的后验最简单的近似是一个点估计:
![]()
δ表示狄拉克函数。因此,我们可以使用前向噪声过程在任意时间步长采样
![]()
其中αt= 1−βt. αt= ∏ i = 1 t α t \prod ^t_{i=1}α_t ∏i=1tαt。类似于[13],我们也可以提取一个条件高斯 q ( x t − 1 ∣ x t , η ) q(x_{t−1}|x_t,η) q(xt−1∣xt,η),并将(2)中的第一个期望表示为
![]()
重新参数化后[13]:
![]()
阶段噪声重构θ(xt,t)是模型期望μθ(xt,t)的线性变换:

权重wt(β)通常是噪声调度的函数,但在大多数预训练的扩散模型中,它被设置为1。因此,(2)中的自由能减少为
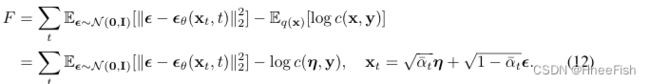
第一项是通常用来学习扩散模型参数θ的代价。对于在已训练好的模型θ下的性能,我们通过在表中对η抽样来使η最小
如果对后验q(x)使用高斯近似,则可以采用类似的推导(见§A)。这样的近似不仅允许建模后验模式,而且允许建模其附近的不确定性

我们将点估计q(x)的算法总结为算法1。这个算法的变体是可能的。根据我们初始化η的良好模式的接近程度,这个优化可能只涉及到求和显性t≤tmax≤T;不同的时间步进度表可以考虑取决于所需的多样性在估计的x。注意,优化是随机的,每次运行它都可以产生不同的x点估计,它们都可能在扩散先验下,并尽可能满足约束。
我们观察到,在图像生成应用中,同时优化所有参数使得引导样本向模态方向发展变得困难;因此,我们从高到低的值退火。直观地说,最初的几次梯度下降迭代应该粗略地探索搜索空间,而随后的迭代逐渐降低温度,稳定地达到p(x|y)附近的局部最大值。为§3,4,5中演示的任务设计的退火计划的例子在附录中给出
另一个有趣的情况是当x通过一个潜变量参数化时(这可以被看作是一个硬的,不可微的约束的情况:如果x是y的确定性函数,x=f(y),那么c(x,y)在相应的流形上得到支持)。然后算法1中的过程可以针对y进行梯度下降步骤
![]()
而不是步骤4和5。(对于潜在表征的某些语义,人们可能希望通过在潜在y上的已知先验的f,使得x的先验向前推理。在这种情况下,(13)必须用雅可比矩阵法提来加权。
3.实验:图像生成
3.1.MNIST的简单说明

我们首先探讨了从MNIST上的无条件扩散模型生成条件样本的想法。我们在MNIST数字上训练[7]的DDPM模型,并使用不同的**约束集c(x,y)**进行实验,以生成具有特定属性的样本。图1中的示例显示了生成的样本。对于(a)中的数字,我们将约束log©设置为“薄”数字的非标准化分数,计算为平均图像强度的负值,而在(b)中,我们将其反转并生成具有高平均强度的“厚”数字。类似地,在(c)和(d)中,我们通过计算数字的两个折叠(垂直/水平)之间的L2距离,手工制作了一个分别惩罚垂直和水平对称性的核,这导致产生倾斜的非对称样本
我们还展示了辅助约束(x,y)如何通过不同的独立训练网络来建模。图1(e)中的数字是通过使用分类网络约束DDPM生成的,该分类网络被单独训练以区分数字类别y=3和所有其他数字。在这种情况下,辅助约束是推断数字的可能性,因为它是由分类器估计的。最后,对于(f),我们将水平对称性和数字分类器约束相乘,促进推理过程以生成完全居中和对称的数字。模型训练和推理的详细信息见附录(§B.1)
3.2.使用现成组件条件生成脸部图像
我们考虑使用预训练的DDPM先验和学习约束生成自然图像。我们利用[3]中的FFHQ-256[19]上预训练的DDPM网络和CelebA[25]上预训练的ResNet-18 face属性分类器。属性分类器计算在给定图像x中出现各种面部特征的可能性,因为它们是由CelebA数据集定义的。这样的特征有:无胡子、微笑、金发和男性。为了从无条件DDPM网络中生成条件样本,我们选择了这些样本中的一个子集,并使用分类器预测似然度作为我们的约束来强制它们的存在或不存在。如果是我们希望表示的一组属性,约束 l o g c ( x , y ) log c(x,y) logc(x,y)可以表示为
![]()
我们只严格执行面部属性的一小部分,因此允许向不同的模式收敛,这些模式对应于在不同程度上展示所需特征的样本。
在图2中,我们展示了我们仅使用无条件扩散模型和分类因子p(y|x)推断具有所需属性的条件样本的能力。在第一行中,我们展示了算法1对各种属性的优化过程的结果。分类器目标c(x,y)操作图像的目的是使分类器网络产生所需的数据预测,而扩散目标试图将样本丛拉向学习分布p(x)。如果我们忽略去噪损失,结果将是一些对抗性噪声欺骗分类器网络。然而,DDPM先验足够强,可以引导过程生成看起来逼真的图像,同时满足分类器约束集
我们注意到,生成的样本x虽然已经收敛到p(x)的正确模式,但仍然表现出大量与分类器目标优化相关的噪声。为了解决这个问题,受[31]的启发,我们简单地使用DDPM模型单独去噪图像,从低噪声水平t= 200开始,以保留整体结构。去噪的结果如图2第二行所示。

图2:第一行:约束c(x,y)的条件FFHQ样本,具有各种属性。第二行:像[31]那样去噪,以删除使用强制约束的分类器网络进行优化时出现的工件
在图3中,我们展示了在金发+微笑+非男性条件下的推理优化过程的中间步骤,从而仅使用独立训练的属性分类器和面部无条件生成模型解决了[8]中研究的问题。用高斯噪声 *N(0,I)*初始化样本,当我们执行递减值的梯度步骤时,我们观察到面部特征以从粗到细的方式添加。
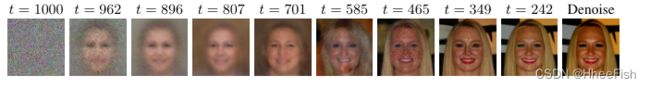
图3:FFHQ条件生成y={金发,微笑,女性}。最后一步如[31]中所述执行去噪,以去除在分类器上作为约束进行训练时出现的伪影
在附录(§B.2)中,我们提供了额外的样本,并进一步讨论了样本质量与无条件生成的对比。我们还介绍了具有冲突属性的推理结果以及常见的失败案例
4.实验:语义分割
我们测试了扩散先验在离散任务中的适用性,如从图像中推断语义分割。为此,我们使用了EnviroAtlas数据集[32],该数据集由来自美国四个地理位置不同的城市的5类、100万分辨率的土地覆盖标签组成;宾夕法尼亚州的匹兹堡、北卡罗来纳州的达勒姆、得克萨斯州的奥斯汀和亚利桑那州的凤凰城。我们只能使用匹兹堡的高分辨率标签,而任务是推断其他三个城市的土地覆盖标签,前提是仅根据粗糙辅助数据[34]得出的概率弱标签。我们使用算法1来执行一个推理过程,它不直接将图像作为输入,而是使用来自无监督颜色聚类的约束。我们在推理中只使用聚类索引,使得算法依赖于图像的结构,而不是颜色。局部聚类指数作为一种表示,具有极好的领域可转移性,但它们需要一种组合搜索形式,将局部聚类指数与语义标签匹配,以便创建的形状与之前观察到的土地覆盖相似,这是由语义分割的去噪扩散模型捕获的
语义像素标签上的DDPM
我们使用[7]的U-Net扩散模型体系结构,在1/4分辨率的土地覆盖标签单热表示上训练一个DDPM模型。为了将独热扩散样本转化为概率,我们遵循[15],并假设在推断的采样簇中,对于任何像素列,标签l上的分布是, p ( l i ) ∝ ∫ 0.5 1.5 N ( x i l ∣ η i , σ ) p(l_i)∝∫^{1.5}_{0.5}N(x^l_i|η_i,σ) p(li)∝∫0.51.5N(xil∣ηi,σ),其中σ是用户定义的一个参数。我们选择这种方法是因为它简单,易于应用于算法1的推理集。或者,我们可以对分类数据[14]使用扩散模型,并对推断过程进行适当修改。从学习到的分布中提取的样本如图4所示

图4:土地覆盖分割训练的DDPM的无条件样本(参见图5)。
语义分割预测
为了推断单个图像的分割,在扩散先验下,我们直接应用算法1和手工制作的约束,该约束提供结构和标签指导。为了构造,我们首先计算输入图像的局部颜色聚类z(附录中的§B.3)。此外,我们利用了可用的弱标签lweak[34]并对无重叠块进行平均时,强制预测片段的分布匹配弱标签分布。我们将两个目标合并在一个单一约束c(x,z,lweak)中,方法是(i)在重叠的图像补丁中计算颜色聚类z和预测标签x之间的互信息,由推断的独热向量转换为有效的概率分布,(ii)计算平均预测分布和非重叠块中弱标签给出的分布之间的负KL散度
![]()
根据经验,我们发现,通过使用弱标签lweak来初始化样本x,而不是随机噪声,可以减少执行推理所需的优化步骤的数量,从而允许我们从较小ti的开始。图5显示了图像及其推断分割的示例。
带推断样本的域迁移

图5:分割推断结果。使用weak labels初始化推断的分割轴,以减少所需的步骤数。样本从北卡罗来纳州达勒姆、德克萨斯州奥斯汀和亚利桑那州菲尼克斯(从上到下)选取。尽管AZ在颜色和标签的联合分布上有很大不同,但推断出的分割仍能捕捉到整体结构。注意,推理算法不使用输入图像中的像素强度,仅使用无监督的颜色聚类。
上述推理过程对颜色的设计是不可知的,我们期望它比[34]中的方法具有更大的能力在新的领域中执行,该方法仍然微调以原始图像为输入的网络。我们还研究了域转移方法,其中使用扩散先验分割的面片用于训练神经网络以进行快速推理。我们仅在PA中的20k批16个随机采样的64×64图像块上预处理标准U-Net推理网络 p ( x ∣ I ) p(x|I) p(x∣I)。我们在每个其他地理区域随机采样640个图像,并使用我们的推理程序生成语义分割,然后在这些分割上微调推理网络。然后在整个目标地理上评估该网络。

表1:不同地理区域EnviroAtlas数据集上联合得分的精度和类平均交叉点。从第二排到最后一排的模型在宾夕法尼亚州匹兹堡地区的监督下进行了预训练
表1中的结果表明,对于弱监督训练,这种域转移方法与[34]的最新工作相当。仅根据可用的高分辨率PA数据(PA监督)对U-Net进行训练的方法是无法推广到地理上凤凰城AZ不同地理位置。类似地,[33]的模型(这是一个美国范围内的高分辨率土地覆盖模型,基于图像和标签以及整个美国的多分辨率辅助数据进行训练)也受到了影响。当提供弱标签作为输入(PA监督+弱)时,结果可以显著改善。
附录B:实验细节和扩展
B.1:MNIST
- DDPM训练
为了训练扩散模型,我们使用了[7]的U-Net架构,具有近似βt schedule和T=1000个扩散步骤。我们使用Adam优化器对网络进行了10个时期的训练,批处理大小为128个样本,学习率为10−4.
- 执行推断
对于所有的推理示例,我们使用ADAM优化器和学习率执行了1000个优化步骤10−2.如图B.1(a)所示,我们采用了余弦调制、线性递减的制革工艺。我们在观察到线性递减的值以粗略到精细的方式指导推断过程之后,根据经验设计了该退火过程,该方式从决定推断样本的总体结构开始,并详细添加。我们还添加了振荡组件,以允许在推断出具体细节后对粗略结构进行修改
在执行算法1的优化步骤时,我们观察到,为了获得良好的样本质量,逐渐减小条件c(x,y)的影响是很重要的。在实践中,当我们从mt,…,1进行优化时,损失的条件分量的权重几乎降低,从λt = 10−2到λ1= 0。这可以归因于这样一个事实,即我们使用的条件为在较大值时所做的步骤提供了指导,在较大值时,数字的形状和方向是决定的。当组合两个或两个以上的条件时,权重应用于所有的条件。

图b .1: (a) MNIST (b)土地覆盖实验的推断退火时间表。我们并不一定需要优化所有t = 1000值来生成样本,如(b)所示。tsp和FFHQ实验使用了类似定义的调度。
B.2:FFHQ
- 执行推断
对于FFHQ数据集上的条件生成实验,我们使用[3]提供的预训练DDPM模型。人脸属性分类器网络是一个基于CelebA数据集[25]中给出的人脸属性进行训练的resnet -18网络。为了运行我们的推理算法,我们使用Adamax优化器执行了200个优化步骤,选择(β1,β2) =(0.9,0.999),学习率从1到0.5线性递减。晒黑时间表与用于土地覆盖分割实验的时间表相似(图b .1 (b)),但现在的数值在1000到200之间。此外,在这个实验中,我们发现用一个精心选择的加权项来平衡扩散和辅助损失是困难的。因此,我们选择了一种不同的方法,我们将辅助目标的梯度范数剪切到扩散去噪损失的梯度范数的1/2
- 关于样本的进一步讨论
在图B.2中,我们演示了来自无条件DDPM和属性分类器的附加条件生成样本。在第一组例子中,我们可以发现尽管pDDPM(x)的模式在一定程度上满足分类器设定的条件,但样本质量并不总是与无条件生成的样本一样,就像[3]中所示的那样。我们可以将其归因于这样一个事实:对于自然图像,与分割标签相比,模式可能并不总是分布中的一个好看的样本。我们的方法是,从一个较低的温度开始运行扩散去噪过程,以及优化过程中留下的分类器噪声伪影。尽管这可能会提高结果的视觉质量,但在某些情况下,我们的选择往往不足以使样本远离推断。如果我们选择一个更大的,我们就有可能抹去我们最初想要生成的属性。
在第二组示例中,我们首先展示如何解决冲突的属性。当约束设置为满足两个相互矛盾的属性时,我们观察到推断的样本会向一个随机选择的方向延伸。这在前两个例子中很明显,其中我们设置了一个与男性相关的属性,而不是男性属性。在每一种情况下,只有一个条件,不是男性的条件,就是与男性有关的条件,得到满足。在金发+黑发的例子中,我们可以认为这两种属性的混合存在于推断的样本中。然而,分类器对特定图像的预测告诉我们,显示的人完全是金发。
我们还展示了一组失败案例,其中分类器“绘制”了与期望数据相关的特征,但扩散先验并没有以正确的方式完成样本。例如,在眼镜的例子中,我们看到分类器已经在生成的脸上画出了眼镜边缘的轮廓,但扩散模型未能接收到提示。类似地,当要求波浪头发时,我们看到的曲线会让分类器误以为这个人是卷发,或者当属性设置为微笑+胡子时,我们观察到生成的脸上滑稽地画了胡子。由于条件反射同时依赖于扩散先验和分类器的鲁棒性,我们相信通过更好的分类器训练,我们可以在这种情况下改善结果

图B.2:(a)约束c(x,y)的附加条件样本,具有不同的属性集合。(b)属性为setsy的条件生成失败案例。对于这两组图像,我们显示推理结果(上)和去噪后的图像,如[31],以去除由于优化分类器约束而出现的工件(下)
B.3:土地覆盖
- 训练DDPM

图B.3:土地覆盖分割训练的DDPM的无条件样本
土地覆盖DDPM在14分辨率的土地覆盖标签64×64patches上进行训练,随机抽样自EnviroAtlas数据集[32]的匹兹堡、PA块。对于扩散网络,我们使用U-Net架构[7],线性βt schedule和T = 1000扩散步骤。我们使用亚当优化器和10−4的学习网格,训练了105批大小为32的批次。无条件扩散模型的附加样本如图B.3所示。我们观察到,该模型既学习了与地理无关的结构,如道路的连续性和郊区建筑规划,也学习了PA特定的结构,如位于森林地区的建筑,这在AZ可能不常见
- 执行推断

图B.4:分割推理结果

图B.5:有和没有弱标签引导的推断
由于我们使用弱标签初始化推理过程,因此需要更少的优化步骤,并且不必从T= 1000开始搜索。因此,为了推断土地覆盖分割,我们使用Adam优化器只执行200个优化步骤,学习速率呈线性下降趋势从5×10−3到5×10−6和(β1,β2) =(0,0.999)。我们为该任务设计的退火计划反映了总体步骤较少的需求,如b .1 (b)所示。我们还降低了损耗的两个条件分量的权重,在执行优化步骤st时,从λt = 1到λ1= 0,…,1以减少它们对最终推断样本的影响。此外,我们线性降低了用于将从DDPM模型学到的单热表示转换为概率的σ参数,从σt = 0.2到σ1= 0.02,以模拟这个转换过程的不确定性。进一步的土地覆盖分割推理示例如图所示。B.4。尽管DDPM只训练PA土地覆盖标签,但我们展示了弱标签引导如何允许我们在全新的地理位置进行推断,例如AZ(最后两行),那里最突出的标签现在是Soil和瘠薄的。
我们依旧可以观察到模型学习到的pa相关偏差的一些人工制品,比如添加不间断森林区域的趋势,但语义模型的可移植性仍然远远优于基于图像的模型
我们手工制作的土地覆盖分割推理约束分为两个目标;(i)使用局部颜色聚类匹配目标图像的结构(ii)在图像的非重叠块中平均时,迫使预测片段的分布与弱标签分布的weak相匹配。
局部颜色聚类是用固定数量的局部高斯混合来计算的。为了匹配预测标签和预计算聚类之间的结构,我们计算31×31pixels重叠斑块中两个分布之间的互信息。这种约束的选择推动推断的土地覆盖段,使它们在局部上与颜色聚类段相匹配。虽然这让我们可以推断出像道路和建筑物这样的大型结构的标签,但它也倾向于在集群具有高熵的区域添加噪声标签。然而,通过逐渐减少辅助目标的权重,我们允许推理过程“填充”这些细节,因为它是由扩散先验所决定的。
推理过程中的标签引导是由粗糙辅助数据衍生出的概率弱标签提供的。这些数据由30米分辨率的国家土地覆盖数据库(NLCD)标签组成,并加上建筑足迹、道路网络和水道/水体[34]。相应的弱标签约束计算为在31×31pixels非重叠块的平均预测和弱标签分布之间的kl -发散。在缺乏此类指导的情况下,推理过程很容易混淆语义类,同时仍然产生可能低于pddpm(x)的片段。我们在图b .5中展示了这一点,其中我们从随机初始化开始推断图像的土地覆盖标签,有和没有弱标签引导
- 域迁移
对于域转移实验,我们最初使用学习率为10−4的Adam优化器对宾夕法尼亚州匹兹堡16个随机sampled 64×64 image补丁的标准差分U-Net [35] 或 2×104 batches进行预训练。然后,我们使用上面描述的推断过程,推断出其他每个地理区域(NC, TX,AZ)的640个随机抽样斑块的土地覆盖分段。有了这些生成的标签,我们首先在一个5块的验证集上对原始网络进行微调,以确定最佳的微调参数。对于Durham, NC和Austin, TX,我们只对一个epoch的网络最后一层进行微调,使用16个补丁的批量大小和学习速率5×10−4。对于AZ的Phoenix,我们需要5个时间对整个网络进行微调,学习速率为5×10−4,因为域漂移更大。此外,对于所有区域,根据[34]的实验,我们将预测概率与弱标签相乘并重新正化。
最后,在表1中,我们还展示了推理网络从零开始训练时的结果,以表明结果性能不仅仅是预训练的产物。U-Net对所有640个生成的样本进行了20个课时的训练,批次大小为16个,学习率为10−3。
参考文献
[1]Tomer Amit, Eliya Nachmani, Tal Shaharabany, and Lior Wolf. Segdiff: Image segmentationwith diffusion probabilistic models.arXiv preprint 2112.00390, 2021.
[2] Sanjeev Arora. Polynomial time approximation schemes for euclidean traveling salesman andother geometric problems.Journal of the Association for Computing Machinery, 45(5):753–782,09 1998.
[3]Dmitry Baranchuk, Andrey Voynov, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko.Label-efficient semantic segmentation with diffusion models.International Conference onLearning Representations (ICLR), 2022.
[4]Xavier Bresson and Thomas Laurent. The transformer network for the traveling salesmanproblem.arXiv preprint 2103.03012, 2021.
[5]Jooyoung Choi, Sungwon Kim, Yonghyun Jeong, Youngjune Gwon, and Sungroh Yoon. ILVR:conditioning method for denoising diffusion probabilistic models.International Conference onComputer Vision (ICCV), 2021.
[6]Michel Deudon, Pierre Cournut, Alexandre Lacoste, Yossiri Adulyasak, and Louis-MartinRousseau. Learning heuristics for the TSP by policy gradient. InIntegration of ConstraintProgramming, Artificial Intelligence, and Operations Research, pages 170–181. SpringerInternational Publishing, 2018.
[7]Prafulla Dhariwal and Alexander Quinn Nichol. Diffusion models beat GANs on imagesynthesis.Neural Information Processing Systems (NeurIPS), 2021.
[8]Yilun Du, Shuang Li, and Igor Mordatch. Compositional visual generation with energy basedmodels.Neural Information Processing Systems (NeurIPS), 2020.
[9]Jesse H. Engel, Matthew D. Hoffman, and Adam Roberts. Latent constraints: Learning togenerate conditionally from unconditional generative models.International Conference onLearning Representations (ICLR), 2018.
[10]David Applegate et al. Concorde TSP solver.http://www.math.uwaterloo.ca/tsp/concorde, 1997-2003.
[11]Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, SherjilOzair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Neural InformationProcessing Systems (NeurIPS), 2014.
[12]Keld Helsgaun. An effective implementation of the Lin–Kernighan traveling salesman heuristic.European Journal of Operational Research, 126(1):106–130, 2000.
[13]Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.NeuralInformation Processing Systems (NeurIPS), 2020.
[14]Emiel Hoogeboom, Didrik Nielsen, Priyank Jaini, Patrick Forré, and Max Welling. Argmaxflows and multinomial diffusion: Learning categorical distributions.Neural InformationProcessing Systems (NeurIPS), 2021.
[15]Emiel Hoogeboom, Victor Garcia Satorras, Clément Vignac, and Max Welling. Equivariantdiffusion for molecule generation in 3D.arXiv preprint 2203.17003, 2022.
[16]Chaitanya K Joshi, Thomas Laurent, and Xavier Bresson. An efficient graph convolutionalnetwork technique for the travelling salesman problem.arXiv preprint 1906.01227, 2019.
[17]Chaitanya K Joshi, Quentin Cappart, Louis-Martin Rousseau, and Thomas Laurent. Learningtsp requires rethinking generalization.International Conference on Principles and Practice ofConstraint Programming, 2021.
[18]Zahra Kadkhodaie and Eero Simoncelli. Stochastic solutions for linear inverse problems usingthe prior implicit in a denoiser.Neural Information Processing Systems (NeurIPS), 2021
[19]Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generativeadversarial networks.Computer Vision and Pattern Recognition (CVPR), 2019.
[20]Bahjat Kawar, Gregory Vaksman, and Michael Elad. SNIPS: Solving noisy inverse problemsstochastically.Neural Information Processing Systems (NeurIPS), 2021.
[21]Diederik P. Kingma and Max Welling. Auto-encoding variational bayes.International Confer-ence on Learning Representations (ICLR), 2014.
[22]Thomas Kipf and Max Welling. Semi-supervised classification with graph convolutionalnetworks.International Conference on Learning Representations (ICLR), 2017.
[23]Wouter Kool, Herke van Hoof, and Max Welling. Attention, learn to solve routing problems!International Conference on Learning Representations (ICLR), 2019.
[24]Shen Lin and Brian Kernighan. An effective heuristic algorithm for the traveling-salesmanproblem.Operations Research, 21(2):498–516, 1973.
[25]Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in thewild.International Conference on Computer Vision (ICCV), 2015.
[26]James MacGregor and Yun Chu. Human performance on the traveling salesman and relatedproblems: A review.The Journal of Problem Solving, 3, 02 2011.
[27]Tom Minka. Divergence measures and message passing.Microsoft Research Technical Report,2005.
[28]Joseph S. B. Mitchell. Guillotine subdivisions approximate polygonal subdivisions: A simplepolynomial-time approximation scheme for geometric tsp, k-mst, and related problems.SIAMJournal on Computing, 28(4):1298–1309, 1999.
[29]Anh Nguyen, Jeff Clune, Yoshua Bengio, Alexey Dosovitskiy, and Jason Yosinski. Plug &play generative networks: Conditional iterative generation of images in latent space.ComputerVision and Pattern Recognition (CVPR), 2017.
[30]Alex Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models.Inter-national Conference on Machine Learning (ICML), 2021.
[31]Weili Nie, Brandon Guo, Yujia Huang, Chaowei Xiao, Arash Vahdat, and Anima Anandkumar.Diffusion models for adversarial purification.International Conference on Machine Learning(ICML), 2022. To appear; arXiv preprint 2205.07460.
[32]Brian R. Pickard, Jessica Daniel, Megan Mehaffey, Laura E. Jackson, and Anne Neale. Envi-roatlas: A new geospatial tool to foster ecosystem services science and resource management.Ecosystem Services, 14©:45–55, 2015. URLhttps://EconPapers.repec.org/RePEc:eee:ecoser✌️14:y:2015:i:c:p:45-55.
[33]Caleb Robinson, Le Hou, Nikolay Malkin, Rachel Soobitsky, Jacob Czawlytko, Bistra Dilkina,and Nebojsa Jojic. Large scale high-resolution land cover mapping with multi-resolution data.Computer Vision and Pattern Recognition (CVPR), 2019.
[34]Esther Rolf, Nikolay Malkin, Alexandros Graikos, Ana Jojic, Caleb Robinson, and NebojsaJojic. Resolving label uncertainty with implicit posterior models.Uncertainty in ArtificialIntelligence (UAI), 2022. To appear; arXiv preprint 2202.14000.
[35]Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks forbiomedical image segmentation.Medical Image Computing and Computer-Assisted Intervention(MICCAI), 2015.
[36]Chitwan Saharia, Jonathan Ho, William Chan, Tim Salimans, David J. Fleet, and MohammadNorouzi. Image super-resolution via iterative refinement.arXiv preprint 2104.07636, 2021.
[37]Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models.International Conference on Learning Representations (ICLR), 2022.
[38]Abhishek Sinha, Jiaming Song, Chenlin Meng, and Stefano Ermon. D2C: diffusion-decodingmodels for few-shot conditional generation.Neural Information Processing Systems (NeurIPS),2021.
[39]Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli. Deepunsupervised learning using nonequilibrium thermodynamics.International Conference onMachine Learning (ICML), 2015.
[40]Yang Song, Liyue Shen, Lei Xing, and Stefano Ermon. Solving inverse problems in medi-cal imaging with score-based generative models. InInternational Conference on LearningRepresentations (ICLR), 2021.
[41]Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Good-fellow, , and Rob Fergus. Intriguing properties of neural networks.International Conference onLearning Representations (ICLR), 2014.
[42]Yusuke Tashiro, Jiaming Song, Yang Song, and Stefano Ermon. CSDI: conditional score-based diffusion models for probabilistic time series imputation.Neural Information ProcessingSystems (NeurIPS), 2021.
[43]Arash Vahdat, Karsten Kreis, and Jan Kautz. Score-based generative modeling in latent space.Neural Information Processing Systems (NeurIPS), 2021.
[44]Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez,Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Neural Information ProcessingSystems (NIPS), 2017.
[45]Zhisheng Xiao, Karsten Kreis, and Arash Vahdat. Tackling the generative learning trilemmawith denoising diffusion GANs.International Conference on Learning Representations (ICLR),2022