贝叶斯网络
其实我们有些时候研究的随机变量并不是相互独立的,它可能是相互之间有关系的,也就是说若干个样本之间并不相互独立,可能产生了某种关系,最后就产生了一个看起来像网的东西,我们把这样的一个有向的无环图叫做贝叶斯网络。而每一个节点都是一个随机变量,所以这是一个概率图模型。有向无环图和贝叶斯网络是一个等价的概念,都属于概率图模型,只是有些时候除了贝叶斯网络这种有向无环图可能还有无向图模型,但它也是概率图模型,叫做马尔可夫网络,也就是有两种网络,一种是贝叶斯网络,一种是马尔可夫网络。LDA和HMM其实就是一种贝叶斯网络。而如果是给定一些条件比如X,Y是不确定的,由X去确定Y,那就是在给定条件的情况下做了一个随机场。
现在来谈谈贝叶斯网络和深度网络的结合,因为它们有许多相似的地方,一个是对模型本身建立的连接,一个是对概率建立的连接,它们都看起来是一个有向图。
现在来说明一个事情哈,就是贝叶斯网络它是一个有向无环图,它的结点表示的是一些随机变量,这些随机变量有些是可以观测到的,有些是无法观测到的。无环是为了表示在信息流动的过程中能够有一个确定的方向的,如果是循环的走这样会产生一些很麻烦的事情哈。我们有些时候可能会看到X有一个箭头指向了Y,但这并不表明因为X所以Y。其实我们在做的时候完全得不出X是原因Y是结果。我们这里更多的是不相关,或者说是相关,或者不独立,相似或者关联这么一个东西,无法表示因果关系。这个箭头仅仅表示它们之间是有关系的,这两个事件是不独立的,至于说谁是原因谁是结果不确定,甚至于都可能没有原因和结果,它可能是有中间的。
来看一个简单的贝叶斯网络: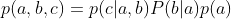 ,我们就可以把这个a拿出来,乘上不就是
,我们就可以把这个a拿出来,乘上不就是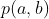 嘛。所以可以引出有向的线段:
嘛。所以可以引出有向的线段:

那我们可以做多个吗?
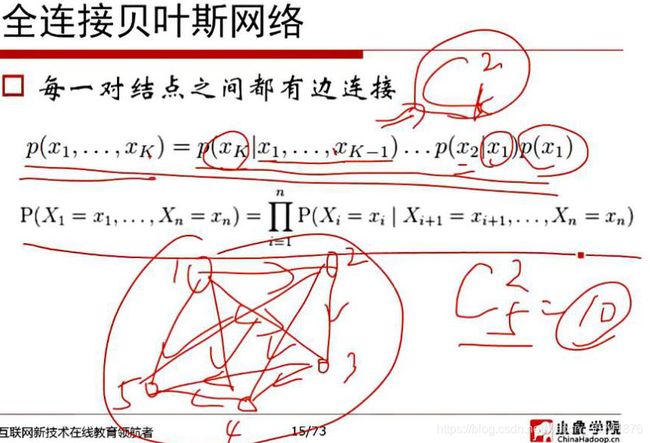
这是一个全连接的,也就是任何两个结点之间都是相连的,这是我们最不希望的,它把所有的边都保留着,那就意味着建立这么一个模型比较复杂,甚至可能会过拟合。所以我们研究正常的贝叶斯网络:
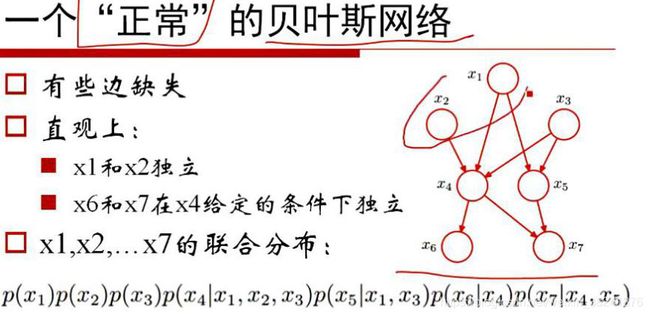
比如我们现在就研究x4吧,它有一个孩子结点是x6,有一个是x7,我们甚至于可以这么来讲,当然x6和x7显然是不独立的,但现在如果是在给定了x4这个节点的前提之下他们是否又是独立的呢?所以说在这里边有一些很有趣的事情发生,这么一个贝叶斯网络其实我们可以这么来去看待它,首先这么一个东西我们可以求的这么一个联合概率,而在里面因为有些边缺失,本来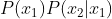 但x1到x2没有边,我们写这个东西就直接写成p(x2)就是了嘛,没有边的就直接忽略,直接写过来就可以得到这么一个乘积的结论,这个东西就等价于x1到x7的联合分布,因为我们有些边缺失了,缺失不再显得式子那么的那么的难看。举个例子,我们来看一下如何来研究贝叶斯网络呢?
但x1到x2没有边,我们写这个东西就直接写成p(x2)就是了嘛,没有边的就直接忽略,直接写过来就可以得到这么一个乘积的结论,这个东西就等价于x1到x7的联合分布,因为我们有些边缺失了,缺失不再显得式子那么的那么的难看。举个例子,我们来看一下如何来研究贝叶斯网络呢?

我们需要给出一些它的概率的参数,你比方说,一个人抽烟,有可能会得lung Cancer,但也有可能会得Bronchitis这么一个很正常的疾病,但是不管是得Cancer还是Bronchitis都会造成Dyspnea,然后呢临床发现如果一个人得了Bronchitis他去照X光没有什么变化,如果得Cancer会很明显,即使没有得癌症但是抽烟可能也会对肺有一定的影响(照X光明显),那这么一来我们就可以得到一个有向的无环图。这个有向无环图不就是贝叶斯网络吗?
然后我们来看这个结论哈,就是说做这么一个贝叶斯网络我们来看哈,第一个抽烟这么一个随机变量它跟其它结点都没有父节点,那Smoking这么一个随机变量它要想做度量的话那就是正常的一个Smoking嘛。对S确定它的随机分布,要么抽烟要么不抽烟,比如一个人他抽烟的概率是0.4,不抽烟的概率是0.6,这不就是定义这个P(S)嘛。相当于他这个里边哈,他真的需要考虑Bronchitis这么一个事情,有或者没有,但是他在得或者不得的时候其实会受到一些影响,如果一个人是抽烟的,那么他得支气管炎的概率可能是0.8,不得是0.2,如果一个人不抽烟他可能得的概率是0.3,不得是0.7。所以Bronchitis其实是条件概率的一个表。
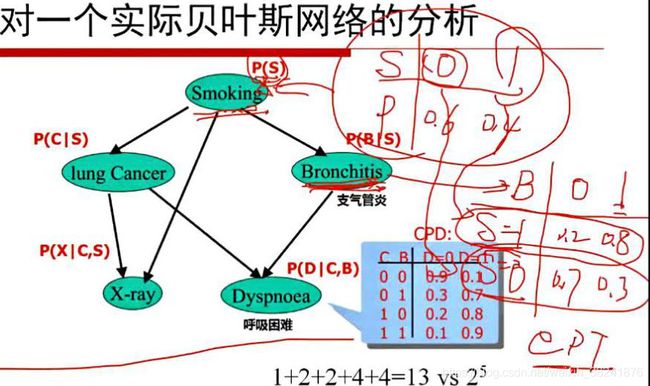
我们接着看Dyspnea,它有两个父节点,一个是Cancer,一个是Bronchitis,所以呢,它可能是Cancer,也可能是Bronchitis,所以我们想来判断这个人是不是Dyspnea,所以我们在来描述这么一个结点的时候,对于Cancer和Bronchitis都可以取0和1,所以说C跟B两两组合就有四种情况,每一种情况都有可能是呼吸困难和不呼吸困难,所以任何一行都是一个条件概率。所以除了这些没有任何根结点的父节点以外,其他的结点都是一些条件概率来去描述它的。比如Dyspnea就需要四个结点才能描述清楚。
贝叶斯网络中的任何一个结点都需要给定一个权值概率表,我们就可以大体的上判断一下这个模型需要多少个参数,在算之前先估计一下参数,看机器能否跑得起来。而如果是一个全连接的网络那么就需要SCBXD五个参数来确定一个概率,就是说任何一个都有两种不同的取值,那一共有多少种不同的取值呢?那就是2^5-1个参数。
我们再来看一下这么一个例子:
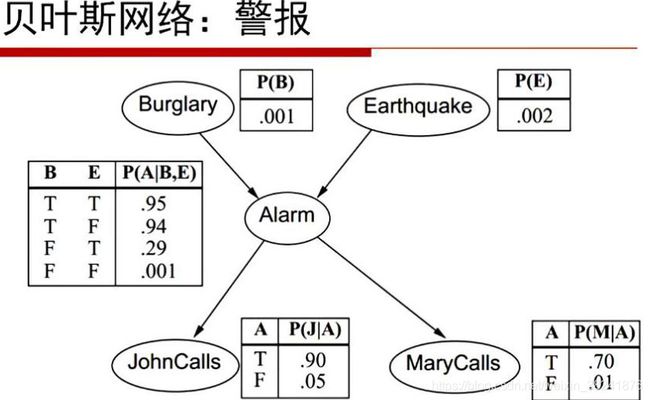
报警了如果是有陌生人进入室内,可能概率是0.001%,发生地震概率可能是0.002%,不管是有陌生人入内还是发生地震警报都会响起,然后警报响起不管是John还是Marry都会告诉我一声,而告诉我的概率分别是0.6和0.7,当然除了它们两是两个概率,因此总共需要10个参数来描述这么一个贝叶斯网络。然后就可以算出:

举个例子,比如说我想算John告诉我了,Marry也告诉我了,铃声也响起了但是没有陌生人进入也没有地震发生的概率,那就老老实实写出分式来。
我们在做贝叶斯网络的时候它其实是有这么一个说法,第一个它其实是一个有向无环图,它需要若干参数,而所有的权值概率的分布所形成的参数的集合。而这个东西我们要想算一个X的概率就把X的父节点拿出来直接做这么一个东西。这是我们说的结果。
那现在就思考一下一般需要多少个参数就可以确定这个网络呢?
贝叶斯网络其实并不是想象的离我们那么遥远,如果我们做一个非常退化的网络: 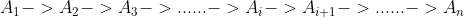
每一个节点上它只和前一个结点相关,跟其他的相对是独立的,就形成了一个链式的网络,这就叫做马尔可夫模型。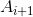 在给定
在给定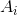 的时候只和这个有关,跟其它没有关系,比如说今天发生雾霾的概率之和昨天有关,这就是所谓的马尔可夫模型。因为我们在去做这样一个模型的时候,比方说我们现在帝都有5天的时间发生雾霾,那就不是一个直接给定i就可以这样子了。
的时候只和这个有关,跟其它没有关系,比如说今天发生雾霾的概率之和昨天有关,这就是所谓的马尔可夫模型。因为我们在去做这样一个模型的时候,比方说我们现在帝都有5天的时间发生雾霾,那就不是一个直接给定i就可以这样子了。

我们现在另加一些边,也就是A3不只和A2,也和A1有关系,A4与A3和A2都有关系,A5和A4和A3都有关系,这个我们叫做二阶马尔可夫网络。同样的A1跟A4也可以加上一条,A2A5、A3A6都可以加上一条,就可以造一个3阶的马尔可夫网络,甚至n阶的马尔可夫网络,但是模型会越来越复杂,因此需要在模型的精确度和复杂度之间取一个折中。但是我们往往不会去做这么高阶的模型。
其实大家早就在应用马尔可夫模型了,伪随机数发生器就是一个马尔可夫网络。
将上述结点推广到结点集:
刚才我们这个东西指的是给定一个结点,不管是tail->tail的模型还是head->tail的模型还是head->head的模型,都是给定一个结点做模型的判断,有些时候并不是非要做一个结点,将这个东西推广到结点集合,什么意思呢?也就是之前的Smoking可能是若干个结点,画成三个集合,那这样的话我们就更加的得到一些有启发性的结论。举个例子哈是这么来说的,某一个车是否能发动,如果现在蓄电池是有电的,那就可以听歌嘛,也可以进行打火嘛,打火之后如果汽油是充足的就对汽车进行发动,一发动就开动起来了。这么一个模型其实举个例子,如果在什么情况都是不知道的前提之下,比如说油箱里是否有汽油跟我是否能听歌这两个随机变量是独立的吗?当然。但是没有任何前提我就说它是独立的,为什么可以怎么说呢?因为:

这个结点集合跟这个结点集合形成了这么个结点集合,它就是A,B会得到中间C的这么一个过程。而我不清楚C的情况,A和B就是独立的,A里面的某一个比如Radio就和Gas是独立的。也就是常识和理论值吻合的。我现在知道这个车是可以开起来的,你说我能不能听歌和油箱是否有油是不是独立的呢?这是不确定的。
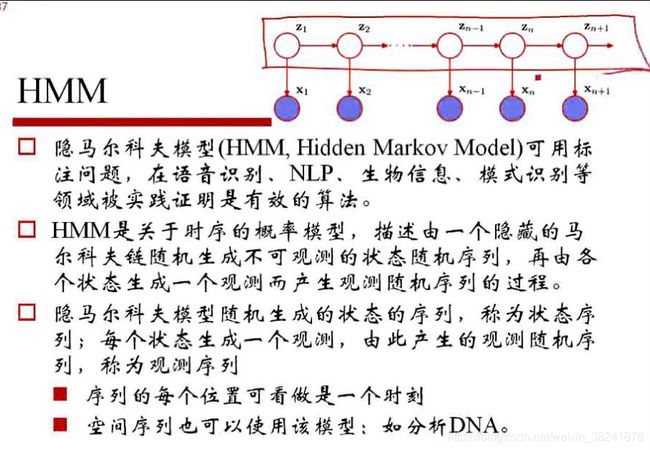
上面这个东西如果做成是一个马尔可夫模型,就是链状的对不对,如果说哈这些链状的这个东西认为是一个隐状态,或者隐特征我们不知道的,我们只能观测到x1,x2一直到xn这些东西,比如说我们现在能观测到给这个声音,然后我不知道这个声音说的是哪一个字,那么所把这个语言得到文字的这个过程那就是我们造的这个模型,我们认为我们这些语音之间会有这样子的一个马尔可夫模型。然后任何一个字比方说文(x1)和字(x2)这两个字,文是一个波形,字是一个波形,我们就拿到了一些说话的波形数据,对这个波形我们就可以来去计算一下这个波形背后到底是什么样的字所产生的就可以做语音识别嘛。当然我们表示给定的波形而是直接给定的一段文本数据,其实也可以对文本数据进行中文的分词,分词之后对这个词性的判定是NLP重要的工作。这个其实就是隐马尔科夫模型,而这样一个模型其实可以给出一个很有趣的概念叫做马尔可夫毯,什么意思呢?就是一个结点它其实对应着一个结点集合,这个结点集合的结点如果都给定的前提之下,这个结点就和其它所有结点条件独立,那么这么一个集合就叫做马尔可夫毯。
贝叶斯网络其实可以做很多事情,根据原因去来找病因,根据病因去来看症状,根据数据去来做判别,这都是可能的,而这里边如果是需要带隐变量的前提之下来算的时候,那么说可能就需要用EM算法了,对吧,所以有些时候是需要用EM算法的。
在建立模型的时候一定要注意,其实在回归的时候就谈到过奥卡姆剃刀,就是说我们不要去过度累加模型复杂度,因为模型越复杂会导致不容易建立。
现在来看一看贝叶斯网络构建的一个方案,中看但不一定中用,但却是一个适宜的办法。然后我们就利用D-separation做局部测试。我们先去把我们关心的若干个特征或者是随机变量列出来,X1到Xn,给出一个合理的顺序,我们现在就来考虑如果说X1到Xn都放在这个网络的情况之下每个结点是否应该与其它结点有边的问题。是否应该有边就看一下与其它数据是不是独立的。也就是说本来是求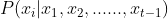 ,现在就是看一下如果删掉X1的前提之下是否还能近似相等,删掉X2的前提之下甚至于删掉很多的前提之下是否还能相等,删的越多越好。得到Xi它的parent,当然这样一个构造过程其实是基于数据说话的一个结果。比如我们刚才的John和Marry的例子,我们看一下P(J|M)与P(J)是否相等。数据样本都给我们了,总可以算是不是相等。相等或近似相等则它们独立的,独立就不应该有边,不相等应该有边。举个例子吧,我们最多的还是P(A|J,M),如果删掉M看P(A|J)是不是相等,如果都删掉看P(A)是不是相等,尽量的少一些嘛,就是尽量的看一下这些边是不是可以不加上,所以说这个工作量是指数增加的。
,现在就是看一下如果删掉X1的前提之下是否还能近似相等,删掉X2的前提之下甚至于删掉很多的前提之下是否还能相等,删的越多越好。得到Xi它的parent,当然这样一个构造过程其实是基于数据说话的一个结果。比如我们刚才的John和Marry的例子,我们看一下P(J|M)与P(J)是否相等。数据样本都给我们了,总可以算是不是相等。相等或近似相等则它们独立的,独立就不应该有边,不相等应该有边。举个例子吧,我们最多的还是P(A|J,M),如果删掉M看P(A|J)是不是相等,如果都删掉看P(A)是不是相等,尽量的少一些嘛,就是尽量的看一下这些边是不是可以不加上,所以说这个工作量是指数增加的。
有些时候我们是根据实际的业务逻辑去来建这么一个贝叶斯网络,我们这样可能真的不是说我们算了发生这个因为它是独立的,感觉地震和有没有人进来我们就感觉它是独立的嘛,所以有些时候就是直接去来做计算比如我们两个人考试是独立事件,就这意思,没有来做更多的探索,就直接根据业务来做这个事情哈。如果没有业务逻辑或者根据业务逻辑也不能断定的情况下,我们再来基于数据做这个事情哈,通过数据与业务做结合能够保证最后的数据更合理一些。就像我们刚才谈到实际业务中没有绝对独立的,例如某某电视剧一上映,某某演员一做什么动作我们就……,但是真的是这样子,你说这有原因吗?这个电视一上映这个股票就会跌,但事实我们发现它们不独立,那你说相关性有多大。所以有些时候只是感觉上独立而已。所以根据数据的驱动去来辅助性的对模型做一点变化。
最后我们来说一下这个混合网络,我们之前的那些例子其实都只是01变量,每一个要么发生要么不发生,那如此一来,所有样本都是离散的,有些情况不一定吧,有时它们是混合在一起的,比如我这里边对某种农产品的税收的倾斜,是对它奖励钱还是罚钱,都为是和否的一个概念。然后这个农产品今年的产量是多少,产量越高价格越低嘛。其实这两个原因都影响它的价格,而这个价格就决定了购买还是不购买,我们就建立这么一个模型出来:

这个模型的Subsidy是鼓励还是不鼓励就是一个布尔型的一个变量,Harvest就是一个值,就是产量有多高的一颗树,cost也是一颗树,buy买还是不买也是离散型变量,这样一个既有离散结点,又有连续结点的混合模型。而这种模型的处理方式也是一个个的来分解就可以了。比如说cost是连续的,比如说是一个高斯分布,均值是某一个值就发生某一个值,而它受到两个因素的影响,而这两个因素是离散的。
当有些时候贝叶斯网络出现了一些环的时候,可以删除原有网络中的若干条边,不让它产生这些环。