【论文学习笔记】《Voice Conversion from Non-parallel Corpora Using Variational Auto-encoder》
《Voice Conversion from Non-parallel Corpora Using Variational Auto-encoder》论文学习
文章目录
- 《Voice Conversion from Non-parallel Corpora Using Variational Auto-encoder》论文学习
-
- 摘要
- 1 介绍
- 2 提出的方法
-
- 2.1 从未对齐的数据为 SC 重新制定自动编码器
- 2.2 架构
-
- 2.2.1 估计预期项
- 2.2.2 潜在空间建模
- 2.2.3 可见空间的建模
- 2.2.4 进行转换
- 2.3 训练过程
- 3 实验
-
- 3.1 实验设置
-
- 3.1.1 VCC2016语音语料库
- 3.1.2 特征集
- 3.2 基线系统
- 3.3 变分自动编码器
-
- 3.3.1 配置和超参数
- 3.3.2 三个变体
- 3.4 客观评价
- 3.5 主观评价
- 3.6 非平行语料库训练
- 3.7 多对多语音转换
- 4 总结
摘要
我们提出了一种灵活的光谱转换( SC )框架,以促进使用非对齐语料库进行训练。
许多 SC 框架需要平行语料库、语音对齐或显式的框架对应,以便在对齐的帮助下学习转换函数或合成目标频谱。
然而,由于平行语料库的缺乏甚至不可用,这些要求严重限制了平行语料库的实际应用范围。
我们提出了一种基于变分自编码器的非并行语料库开发框架。
该框架包括学习与说话人无关的语音表示的编码器和学习重构指定说话人的解码器。
它不需要平行语料库或语音对齐来训练频谱转换系统。
我们报告了客观和主观的评价来验证我们所提出的方法,并将其与能够获得对齐的语料库的 SC 方法进行比较。
1 介绍
语音转换是一种将特定话语的说话人的感知身份进行转换的技术。
一个典型的例子是,当一个人想要把自己的声音转换成一个名人的时候,就要求转换后的语言内容和其他与说话人无关的信息保持不变。
一个完整的语音转换系统涉及许多任务。在本研究中,我们将重点放在谱转换( SC )上,而对韵律的检验不在本文的讨论范围之内。
目前,光谱转换技术已经得到了广泛的应用,包括高斯混合模型( GMM )(《Voice conversion based on maximum-likelihood estimation of spectral parameter trajectory》,《Modulation spectrum-constrained trajectory training algorithm for GMM-based voice conversion》,《Incorporating global variance in the training phase of GMM-based voice conversion》),频率扭曲(《Voice conversion based on weighted frequency warping》,《Voice conversion using dynamic frequency warping with amplitude scaling, for parallel or nonparallel corpora》),深度神经网络( DNN )(《Spectral mapping using artificial neural networks for voice conversion》,《Voice conversion in high-order eigen space using deep belief nets》,《A probabilistic interpretation for artificial neural network-based voice conversion》),以及基于范例的方法(《Exemplar-based sparse representation with residual compensation for voice conversion》,《Locally linear embedding for exemplar-based spectral conversion》)。
这些方法大多要求对源-目标帧或对语音状态进行对齐来训练转换函数或适应转换。
最广泛采用的方法是使用动态时间扭曲( DTW )技术对源帧和目标帧进行对齐。
但是,如果并行语料库不可用, DTW 就无法工作。
在非平行语料库中,有许多技术被用来对齐源和目标框架。
最直观的方法是对话语应用语音识别器,并进行显式对齐或模型适应(《Mapping frames with DNN-HMM recognizer for non-parallel voice conversion》,《Text-independent voice conversion based on state mapped codebook》)。
将语音识别器应用于每个话语,就会给每一帧语音标签(通常是语音状态)。
它特别适用于基于模型的语音转换技术,因为它们可以很容易地利用这些标记的帧(《Non-parallel training for voice conversion based on adaptation method》)。
这种基于框架的、基于模型的方法的问题是,它不适用于跨语言的情况,而跨语言的情况需要更一般的对齐形式。
为此,提出了 INCA 算法和(《INCA algorithm for training voice conversion systems from nonparallel corpora》,《Non-parallel voice conversion using joint optimization off alignment by temporal context and spectral distortion》,《The matching-minimization algorithm, the INCA algorithm and a mathematical framework for voice conversion with unaligned corpora》)相关方法,利用转换后的代理帧迭代寻找帧间对应关系。
另一种尝试是分别为源和目标构建框架集群,然后在它们之间建立一个(《A first step towards text-independent voice conversion》)映射。
让我们来思考一下这些对齐技术在语音转换任务中所扮演的角色。
考虑一个由源说话人 s s s 和目标说话人 t t t 组成的语料库。
其中 X s = { X s , n } n = 1 N s X_s = \{X_{s,n}\}^{N_s}_{n=1} Xs={Xs,n}n=1Ns 表示来自源的所有帧, X t = { X t , m } m = 1 N t X_t = \{X_{t,m}\}^{N_t}_{m=1} Xt={Xt,m}m=1Nt 表示来自目标的帧,其中 N s N_s Ns 和 N t N_t Nt 分别为源和目标的帧总数。
第一种可能也是最普遍的一种对齐方式是帧对齐。
它寻找索引对 ( n , m ) (n, m) (n,m) ,使 x s , n x_{s,n} xs,n 和 x t , m x_{t,m} xt,m 具有相似的语音内容。
为简单起见,我们假设对应关系是一个函数(尽管在大多数情况下不是)。
因此,帧对齐是 x s , n x_{s,n} xs,n 的函数,产生相应的 x t , m x_{t,m} xt,m 。
在这种情况下,对齐不仅是必要的,对 SC 来说也几乎是足够的,因为 SC 也有类似的功能。
第二种是借助于语音识别器实现的帧-模型对齐。
它假设每一帧都对应于一个(语音)模型(或者,等价地,一个集群)。
因此,对齐是 ( n , k ) (n, k) (n,k) 对,其中 k k k 是语音状态的模型索引。
转换是转换函数,它从源输入模型,从目标输出模型。
为了实现转换,在此场景下还需要对齐。
相比之下,说话人的因素在语音转换中起着相当隐含的作用。
例如,在大多数成对的 SC (一个源和一个目标)中,说话者身份只负责将帧指定给输入(如果来自源)或输出(如果来自源)。
令人好奇的是,我们在建立语音转换系统时,并没有明确地考虑到目的而利用说话人依赖的因素。
我们提出了一个直接利用说话人身份来构建 SC 系统的框架,而不需要明确地对齐源和目标框架。
我们提出的公式将转换分解为编码和解码阶段,并将转换视为自我重建的可控版本。
有了这种自我重建的公式,对齐的框架对甚至平行的语料库不再是 SC 任务所必需的。
我们的实验表明,它的性能可与基线系统相媲美,为一般 SC 任务的新框架提供了佐证。
本文的其余部分组织如下:在第二节,我们描述了启发和概念,并阐述了我们的方法;第三节收集了实验设置和结果,以验证我们提出的框架;最后,我们在第四节对本文进行总结。
2 提出的方法
该方法的灵感来自于一个类似的关于生成手写数字(《Semi-supervised learning with deep generative models》,《Auto-encoding variational bayes》)的工作。
(《Semi-supervised learning with deep generative models》)的作者试图从一幅笔迹图像中提取书写风格和数字身份,并用该提取重新合成图像。
基本上,该框架提供的是一个观察变量和两个因果潜在因素的解释模型:身份和变化。
我们假设语音帧背后的解释模型与手写图像的解释模型是一致的。
对于手写数字,标识是标称数字,变化是手写样式。
对于一个语音框架来说,身份可以是说话源,变化可以是语音内容。
2.1 从未对齐的数据为 SC 重新制定自动编码器
给定来自源扬声器的光谱帧 { X s , n } n = 1 N s \{X_{s,n}\}^{N_s}_{n=1} {Xs,n}n=1Ns 和来自目标的光谱帧 { X t , m } m = 1 N t \{X_{t,m}\}^{N_t}_{m=1} {Xt,m}m=1Nt ,常规 SC 试图估计转换函数,如
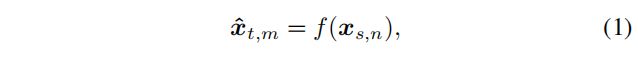
其中 f ( ⋅ ) f(·) f(⋅) 是一个转换函数。
在大多数 SC 系统中,说话者身份(下标 s s s 和 t t t )是隐式处理的;例如,在公式 (1) 中,源始终是输入,而目标始终是期望的输出。
我们明确地将说话人代表 y n y_n yn 纳入 SC 提法。
首先,将转换函数重新表述为自动编码器。
编码器 f ϕ ( ⋅ ) f_\phi(·) fϕ(⋅) 设计为扬声器无关;它忽略传入帧的说话人身份(因此 x s , n x_{s,n} xs,n 和 x t , m x_{t,m} xt,m 现在可以用 x n x_n xn 表示),并将观察到的帧转换为与说话人无关的潜在变量:
![]()
其中 z n z_n zn 是一个潜在变量(或自动编码器术语中的代码)。
据推测, z n z_n zn 包含了与说话者无关的信息,比如语音变化。
为了方便,我们在本文后面将 z n z_n zn 称为语音表征(尽管 z n z_n zn 可能包含更多的语音特征)。
接下来,我们需要一个 f θ ( ⋅ ) f_\theta(·) fθ(⋅) 解码器来重建与说话人相关的帧。
为此,我们引入说话者表示 y n y_n yn 作为另一个潜在变量,并将其与 z n z_n zn 连接起来。
解码器然后利用关节向量 ( y n , z n ) (y_n, z_n) (yn,zn) 重建一个与扬声器相关的框架 x ^ n \hat{x}_n x^n ( x ^ s , n \hat{x}_{s,n} x^s,n 或 x ^ t , m \hat{x}_{t,m} x^t,m,取决于 y n y_n yn ) 。

综上所述,将公式 ( 1 ) (1) (1) 中的 f ( ⋅ ) f(·) f(⋅) 代入公式 ( 3 ) (3) (3) 中的 f θ ( ⋅ ) fθ(·) fθ(⋅) ,再用公式 ( 2 ) (2) (2) 代入 z n z_n zn ,可通过替换来实现重新公式。

对齐在这个公式中不起作用,因为编码器-解码器对在帧的基础上接受帧 x n x_n xn 和说话者表示 y n y_n yn 。
然后将语音表示法 z n z_n zn 和说话者表示法 y n y_n yn 组合成一个框架 x n x_n xn 。
图 1 描述了结构。
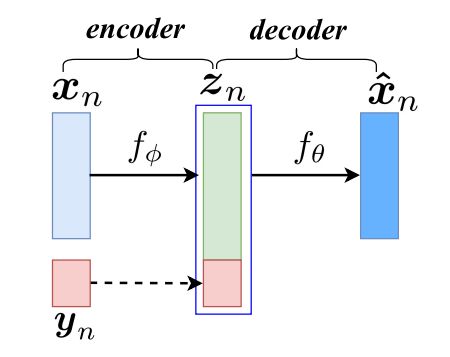
虚线表示复制,潜在变量 zn 和 yn是连接的
该框架的可行性依赖于两个假设。
首先,我们假设说话者表示和语音表示可以从给定的框架中解耦。
其次,我们假设解码器可以混合两个因素(语音和说话人身份)合成一个光谱帧。
2.2 架构
我们改进了变分自编码器( VAE )(《Semi-supervised learning with deep generative models》,《Auto-encoding variational bayes》)来解决未对齐数据的 SC 问题。
VAE 是一种以神经网络形式实现的有向概率模型。
我们之所以选择变分自编码器而不是普通自编码器,是因为前者对潜在空间有更好的理解模型和更好的正则化特性。
我们已经在前一节中描述了基本概念和自动编码器部分。
现在我们将详细阐述一些细节,包括训练目标和推理过程。
我们把 SC 看作是 VAE 的生成过程,因此尽量使单个帧的联合对数概率最大化:

VAE 的个体对数概率可以改写为:

其中 q ϕ ( ⋅ ) q_\phi(·) qϕ(⋅) 为变后验, p ( ⋅ ) p(·) p(⋅) 为真后验。
第一个右手边( RHS )项 D K L ( ⋅ ∣ ∣ ⋅ ) D_{KL}(·||·) DKL(⋅∣∣⋅) 是来自真验后的近似的 Kullback-Leibler 散度( KLD )。
第二个 RHS 项称为边际概率的变分下界,可以进一步重写为:

对公式 (6) 的直接优化通常很难处理,所以我们改用变分下界公式 (7) 作为目标函数。
对编码器参数 ϕ \phi ϕ 和解码器参数 θ \theta θ 的下界 w . r . t . w.r.t. w.r.t. 进行微分和优化。
我们将首先描述如何估计由潜在空间建模所引起的期望项。
然后,我们推导出 KLD 项的封闭形式表达式。
2.2.1 估计预期项
公式 (7) 中常用抽样方法估计期望项:

其中 L L L 为每帧绘制的样本数。
然而,单纯的抽样通常是有问题的,所以我们求助于重新参数化技巧(《Auto-encoding variational bayes》)。
我们通过生成标准正态随机变量对 z n z_n zn 的分布进行抽样,并对其应用数据驱动的确定性函数:
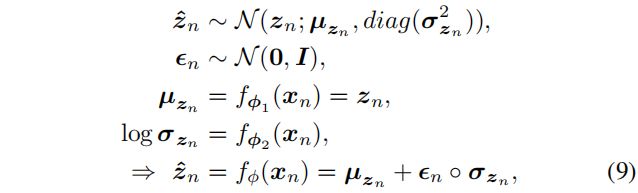
式中 ο \omicron ο 为 Hadamard (元素)积, f ϕ 1 f_{\phi1} fϕ1 和 f ϕ 2 f_{\phi2} fϕ2 为前馈神经网络构成的非线性函数, ϕ = { ϕ 1 , ϕ 2 } \phi = \{\phi_1, \phi_2\} ϕ={ϕ1,ϕ2} 为编码器参数集。
通过重新参数化,公式 (7) 中的期望项近似为:
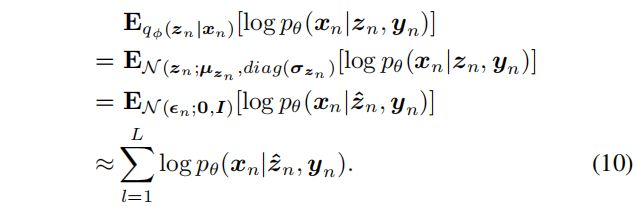
我们通过将 L L L 设置为 $1# 来简化公式 (10) ,从而得到单个帧的最终近似目标函数:

2.2.2 潜在空间建模
潜伏变量 z n z_n zn 的先验分布可以看作是我们对可见变量 x n x_n xn 起源的想象,公式 (7) 中的 KLD 可以看作是一项规则化潜伏变量,使其与所选的 z n z_n zn 的先验分布不太不同的项。
我们选择的 z n z_n zn 是一个各向同性的标准正态分布,与(《Auto-encoding variational bayes》)一致。
由于选择了高斯隐变量, KLD 项(隐变量的代价)可以以封闭形式进行评估:
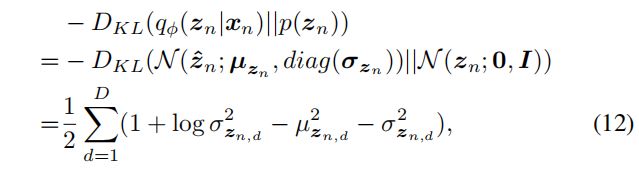
其中 D D D 为潜在空间的维数。
2.2.3 可见空间的建模
我们假设特征的可见变量(对数谱)服从具有对角方差矩阵的高斯分布:
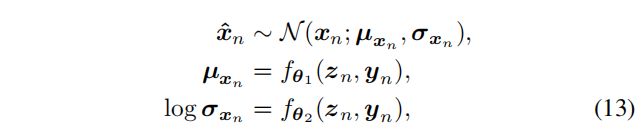
其中, f θ 1 f_{\theta_1} fθ1 、 f θ 2 f_{\theta_2} fθ2 为前馈神经网络构成的非线性函数, θ = { θ 1 , θ 2 } \theta = \{\theta_1, \theta_2\} θ={θ1,θ2} 为解码器参数集。
因此,公式 (11) 中的对数概率项可以表示为封闭形式:

其中 D D D 为可见(特征)空间的维数。
将式 (14) 和式 (12) 代入式 (11) 即可得到最终目标函数。
训练等价于迭代地寻找参数,使变分下界最大化:

我们在实现中使用随机梯度下降( SGD )进行优化。
2.2.4 进行转换
光谱转换很简单,因为我们只需要指定对应于目标的 y n y_n yn 。
编码器首先将输入帧转换为一个潜在表示,然后,解码器将 ( z n , y n ) (z_n, y_n) (zn,yn) 转换为 x ^ n \hat{x}_n x^n 。
注意,在转换阶段不需要采样。
2.3 训练过程
基于 VAE 的 SC 系统的培训程序与传统系统的培训程序不同。
首先,必须引入说话者表示 y n y_n yn来训练解码器。
它可以简单到为每个说话人预先定义一个热点向量,或者一个概率向量。
我们将在下面的段落中使用一个热点向量来描述说话者表示。
第二,训练一个 VAE 需要从潜在变量 z n z_n zn 的概率分布中采样,这意味着注入随机性。
第三,训练 VAE 是分阶段进行的,而传统的训练是结对进行的。
也就是说, x s , n x_{s,n} xs,n 和 x t , m x_{t,m} xt,m 不再区分前者是输入,后者是输出;它们都被视为 x n x_n xn 。
将源集和目标集作为一个统一的集,将每一帧的说话人身份添加到训练集中:

由于我们提出的方法是一个自动编码器,重建输入,训练是通过输入一对频谱帧及其对应的说话人身份 ( x n , y n ) (x_n, y_n) (xn,yn) 到自动编码器。
请注意,在大多数语料库中,为了进行语音转换,总是知道每个话语的说话人身份。
因此,每一帧的说话人身份也是已知的。
因此,我们提出的框架可以明确地利用说话人身份作为额外的输入。
编码器以相同的方式对待每个传入帧,就好像说话人的身份是未知的;它将输入帧转换成独立于说话人的潜在语音表示。
当编码器接收来自源和目标的帧时,它培养了独立于说话人的编码能力。
随后,解码器从潜在表示重新构造输入。
该算法首先从代码(潜在变量 z n z_n zn )的分布中抽取样本,然后利用说话人表示 y n y_n yn 重构输入。
最后,计算定义在可见变量和潜在变量上的开销并进行联合优化,迭代更新网络参数。
当达到最大生成概率时,训练程序将终止。
3 实验
3.1 实验设置
3.1.1 VCC2016语音语料库
在 2016 年语音转换挑战(《The voice conversion challenge 2016》)的平行英语语料库上对所提出的 SC 系统进行了评估。
在这个语料库中有 5 位男性和 5 位女性说话者。每个说话人有 150 个话语作为训练集, 12 个话语作为评价集。
对评价集进行对齐,并对该评价集进行客观评价。
10 名讲话者中有 5 名被指定为转换对象( 2 名女性讲话者和 3 名男性讲话者),其余 5 名讲话者( 3 名女性讲话者和 2 名男性讲话者)。
测试集由每个目标说话人 54 个语音组成,我们使用这个测试集生成转换后的语音用于主观评价。
我们对一部分说话者进行了实验。
选择两个说话人作为源( SF1 和 SM1 ),另两个作为目标( TF2 和 TM3 )。
我们进一步将训练集划分为不相交(非平行)的子集,以训练第 3.3.2 节中的 VAE 变体之一。
我们报道了两种类型的光谱转换:性别内的和性别间的。
3.1.2 特征集
我们使用直谱工具(《Restructuring speech representations using a pitch-adaptive timefrequency smoothing and an instantaneous-frequency-based F0 extraction: Possible role of a repetitive structure in sounds》)提取语音参数,包括直谱(简称 SP )、非周期性( AP )和音高轮廓( F0 )。
FFT 长度设置为 1024 ,因此得到的 AP 和 SP 都是 513 维的。帧位移为 5ms ,帧长度为 25ms 。
我们没有将上下文相关的或动态的特性合并到特性集中。
将 SP 的每个输入帧归一化为单位和,将归一化因子(能量)作为独立的特征提取出来,不进行修改。
SP 使用我们建议的方法或基线系统进行转换。
请注意,在我们提出的方法中,我们进一步对 SP 应用了对数,而在基线系统中我们使用了线性(非负) SP 。
所有系统在 log-F0 域上使用相同的线性均值-方差变换来转换 F0 。 AP 未被修改。
频谱转换后,能量补偿回 SP , STRAIGHT 接收所有参数合成语音。
3.2 基线系统
基线系统是使用并行数据建立在基于范例的非负矩阵分解( ENMF )之上的。
这些系统与(《Exemplar-based sparse representation with residual compensation for voice conversion》)中描述的类似。
字典是 512 或 3000 随机选择的源-目标对帧,因此基线系统分别标记 ENMF- 512 和 ENMF-3000 。
在基线系统中,每个平行训练集使用动态时间扭曲( DTW )与 24 阶 Melcepstral 系数( MCC )从 SP 中提取。
对齐后,源话语的长度保持不变,而目标的一些帧被复制或抽取。
然后,使用基于能量的语音活动检测( VAD )来排除沉默片段。
这些基线系统不需要训练。
通过优化自重构准则对光谱帧进行转换;在这个过程中,他们得到了一个激活矩阵,即字典基线性组合的权值。
然后将激活矩阵应用到目标的平行字典中,将其转换为目标的光谱框架。
因此,转换可以在线进行。
3.3 变分自动编码器
3.3.1 配置和超参数
编码器和解码器均为 2 个隐层的前馈神经网络,每个隐层 512 个节点
整流线性单元( ReLU )(《Rectified linear units improve restricted boltzmann machines》)应用于每一层,以提供非线性(输出层 z n z_n zn 和 x n x_n xn 为线性)。
潜在(语音)空间是 64 维的。小批的尺寸是 128 。优化器是 ADAM (《Adam: A method for stochastic optimization》)。
说话人表示的维数与训练子集中的说话人数量相同(一对一转换为 2 个,统一的多说话人转换为 4 个)。
对数谱特征的可见空间采用高斯分布建模。
我们忽略了方差建模,采用了单位矩阵,因为方差并不影响系统的生成过程。
潜在变量的预期先验分布是各向同性标准正态分布。
3.3.2 三个变体
我们报告拟议框架的三种变体的 SC 结果。
第一个系统被称为 VAE-pair ,由一个源和一个目标构建,每个源和目标都有 150 个话语。
第二组被命名为 VAE-multi ,是由 4 名演讲者的整个训练子集构建的。
最后一个标记为 VAE-disj ,是由非并行数据构建的。
它的训练集由源的前 75 个语音和目标的其他75个语音组成。
我们要澄清三件事。
首先,使用并行但未对齐的数据训练 VAE-pair 和 VAE-multi ,使用非并行数据训练 VAE-disj 。
第二, VAE-disj 训练集的大小大约减半,因为来自源和目标的句子集是相互排斥的。
3.4 客观评价
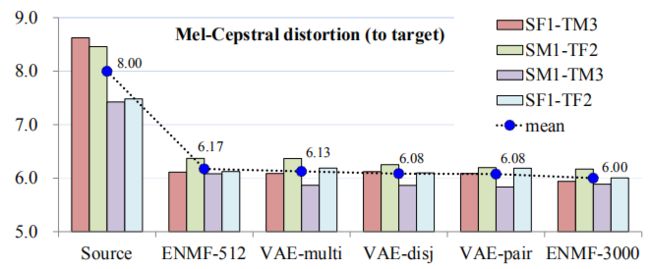
这个数字是按照 MCD 的平均值排列的
我们在图 2 的评价集上显示平均梅尔倒谱失真( MCD )值。
我们提出的方法训练未经对齐的数据与使用对齐帧的基线执行相同。
结果可能意味着所有的系统都达到了相当的性能水平。
由于 MCD 不是一个具有代表性的感知指标,我们进一步对语音质量和相似度进行了主观评价。
3.5 主观评价
在主观评价方面,我们选择 ENMF-3000 作为基准,因为它比 ENMF-512 提供更高的合成声音质量。
我们通过听力测试来评估我们提出的方法( VAE-pair )。
10 位听众被邀请来评估结果。
我们将我们的实验分为间因子和内因子转换。
每个听者被要求评价一个平均意见评分( MOS )的声音质量和 ABX 测试的声音质量和目标相似度。
结果如图 3 所示。

对目标相似性的 ABX 测试显示,两种系统在一个可比较的水平。
该结果为预期结果,与 MCD 客观评价结果一致。
在语音质量方面,我们提出的方法也达到了与 ENMF-3000 基线相似的水平。
VAE-pair 到 2.76 MOS (标准偏差为 0.44 ),而 ENMF-3000 达到 2.75 MOS (标准偏差为 0.50 )。
这个结果是相当鼓舞人心的,因为我们最初推测,由于 VAE-pair 使用了未对齐的训练数据,性能下降会稍微高一些。
请注意, ENMF-3000 的语音质量是相当可以接受的(不像 ENMF-512 ,它处于满意的边缘)。
我们将在未来的工作中对 VAE-multi 和 VAE-disj 进行更多的主观评价。
3.6 非平行语料库训练
让我们惊讶的是, VAE-disj 的表现与 VAE-pair 在客观评估中的表现几乎相同(参见图 2 ),因为前者的训练条件明显比后者更苛刻。
实验验证了我们的框架适用于非平行语料库,同时也指出了一些问题。
例如,由于 VAE-pair 的训练集规模是 VAE-disj 的两倍,模型的能力可能没有得到充分利用。
我们将在今后更深入地研究原因。
3.7 多对多语音转换
从图 2 中我们也可以看到,在客观评价中, VAE-multi 的表现与 VAE-pair 的表现接近。
它有两个有趣的方面。
首先,这两个系统共享几乎相同的超参数设置。 VAE-multi 模型必须学习更复杂的功能,因为它将许多成对系统合并成一个。
第二, VAE-multi 实际上能够转换 4 个说话人的 12 种排列中的任何一种,即, VAE-multi 将 12 个系统合并为一个。
它的能力是唤起多对多( M2M )语音转换。
我们推测我们可能只比 M2M 转换落后一步。 M2M 转换系统有两个要求。
首先,它必须能够将任意的、甚至看不见的源转换为给定的目标。
其次,它必须能够将源转换为在训练阶段从未出现、但在转换期间资源有限的目标。
从概念上讲,我们的框架能够适应 M2M 任务。
这可以通过引入一个说话人识别网络(以另一个编码器的形式)来代替给定的说话人表示(在我们的例子中是一个热向量)来实现。
或者,说话人代表可以是其他形式。
一旦从有限的语音中获得未知目标说话人的说话人表示,解码器很可能将说话人和语音表示混合,合成一个与说话人相关的光谱帧,从而实现 M2M 转换。
4 总结
在本文中,我们介绍了一个基于 VAE 的 SC 框架,它能够利用未对齐的数据。
这是一种不需要明确调整的训练尝试。
客观和主观的评估验证了其转换光谱的能力,并且所提出的方法的性能可以与基线系统的对齐数据相媲美。
我们将继续改进它的性能,研究它适应多对多语音转换的能力,并将其推广到更多的任务中。