MACHINE COMPREHENSION USING MATCH-LSTM AND ANSWER POINTER(MATCH-LSTM)
原文链接:https://arxiv.org/pdf/1608.07905.pdf
原文代码:https://github.com/shuohangwang/SeqMatchSeq
ABSTRACT:
机器理解是自然语言处理中的一个重要问题。最近发布的数据集Stanford Question answers dataset (SQuAD)提供了大量由人类通过众包创建的真实问题及其答案。SQuAD为评估机器理解算法提供了一个具有挑战性的测试平台,部分原因是与之前的数据集相比,SQuAD中的答案不是来自一小组候选答案,而且它们的长度是可变的。我们提出了一种端到端的神经网络结构。该体系结构基于match-LSTM(我们之前提出的用于文本隐含的模型)和 Vinyals等人提出的sequence-to-sequence模型Pointer Net,该模型用于约束输出字符来自输入序列。我们提出了两种使用Pointer Net完成任务的方法。我们的实验表明,我们的两个模型都大大优于Rajpurkar等人(2016)使用逻辑回归和手工制作的特性所得到的最佳结果。
1 INTRODUCTION
机器理解文本是自然语言处理的终极目标之一。虽然机器理解文本的能力可以通过许多不同的方法进行评估,但近年来,已经创建的几个基准数据集,重点将回答问题作为评估机器理解能力的一种方法。在这个设置中,通常首先向机器显示一段文本,比如一篇新闻文章或一个故事。然后,机器将回答与文本相关的一个或多个问题。
在大多数基准数据集中,一个问题可以被视为一个多选题,其正确答案是从一组提供的候选答案中选择出来的。有多个答案的问题更具挑战性。Rajpurkar等人(2016)最近推出的Stanford Question answer Dataset (SQuAD)包含了这样更具挑战性的问题,这些问题的正确答案可以是给定文本中的任意符号序列。此外,不像其他一些数据集的问题和答案是自动创建完形填空风格, SQuAD中的问题和答案是由人类通过众包的方式创建的,这使得数据集更加真实。鉴于SQuAD数据集的这些优点,本文将重点研究这一新数据集对文本的机器理解。表1显示了一段示例文本及其三个相关问题。
解决这类问题的传统方法依赖于NLP流程,它涉及到语言分析和特征工程的多个步骤,包括句法分析、命名实体识别、问题分类、语义分析等。近年来,随着神经网络模型在NLP中的应用进展,为各种NLP任务构建端到端神经结构受到了广泛的关注,其中包括机器理解方面的几项工作。然而,考虑到以前机器理解数据集的属性,现有的端到端任务神经架构要么依赖于候选答案或假设答案是单个字符,这使得这些方法不适用于SQuAD数据集。本文提出了一种新的端到端神经网络结构来解决班组数据集中定义的机器理解问题。
具体来说,我们注意到在SQuAD数据集中,很多问题都是对原文句子的转述,我们采用了之前为文本隐含意义开发的match-LSTM模型。我们进一步采用了Vinyals等人(2015)开发的Pointer Net模型,该模型只允许从输入序列而不是更大的固定词汇表预测字符,从而允许我们从原始文本生成由多个令牌组成的答案。我们提出了两种方法来应用Ptr-Net模型来完成我们的任务:序列模型和边界模型。利用搜索机制进一步扩展了边界模型。在SQuAD数据集上的实验表明,我们的两个模型都优于Rajpurkar等人(2016)报道的最佳性能。此外,使用我们的几个模型进行融合,可以得到非常有竞争力的结果。
我们的主要贡献:(1)提出了两种新的机器理解端到端神经网络模型,结合match-LSTM和Ptr-Net来处理SQuAD数据集的特殊属性。(2)在不可见的测试数据集上,我们获得了67.9%的精确匹配分数和77.0%的F1分数,这比特征工程解决方案要好得多。我们的表现也接近最先进的结果,精确匹配分数是71.6%,F1分数是80.4%。(3)对模型的进一步分析,为进一步改进该方法提供了一些有益的启示。除此之外,我们也提供了我们的代码。
2 METHOD
在本节中,我们首先简要回顾match-LSTM和Pointer Net。这两项现有的工作为我们的方法奠定了基础。然后,我们提出了机器理解的端到端神经结构。
2.1 MATCH-LSTM
在最近关于学习自然语言推理的工作中,我们提出了一个match-LSTM模型来预测文本蕴涵(Wang & Jiang, 2016)。在文本蕴涵中,给出了两个句子,一个是前提,另一个是假设。为了预测前提是否包含假设,match-LSTM模型依次遍历假设的字符。在假设的每个位置上,使用注意机制获得前提的加权向量表示。然后,将这个加权前提与假设的当前字符的向量表示相结合,并输入一个LSTM,我们称之为match-LSTM。matchLSTM本质上是将注意力加权前提的匹配顺序聚合到假设的每个字符上,并使用聚合的匹配结果做出最终预测。
2.2 POINTER NET
Vinyals等人(2015)提出了一种Pointer Network模型,解决了一类特殊的问题,我们想要生成一个输出序列,其中的字符必须来自输入序列。与从固定词汇表中选择输出标记不同,pt-net使用注意机制作为指针,从输入序列中选择位置作为输出符号。指针机制启发了最近一些关于语言处理的工作。在这里,我们采用了pt-net,以便使用输入文本中的标记来构造答案。
2.3 OUR METHOD
形式上,我们要解决的问题可以表述为:给我们一段文字,我们称之为段落,还有一个与段落相关的问题。段落由矩阵![]() 表示,其中P为文章的长度(字符数),d为单词嵌入的维数。同样,问题由矩阵
表示,其中P为文章的长度(字符数),d为单词嵌入的维数。同样,问题由矩阵![]() 表示,其中Q为问题的长度。我们的目标是从文章中找出一个子序列作为问题的答案。
表示,其中Q为问题的长度。我们的目标是从文章中找出一个子序列作为问题的答案。
正如前面所指出的,由于输出标记来自输入,所以我们想采Pointer Network解决这个问题。在这里应用pt-net的一种简单方法是将答案视为输入段落中的标记序列,但是忽略了这些标记在原始段落中是连续的这一事实,因为pt-net没有做出连续性假设。具体来说,我们将答案表示为一个整数序列![]() ,其中每个ai都是1到P之间的整数,表示文章中的某个位置。
,其中每个ai都是1到P之间的整数,表示文章中的某个位置。
或者,如果我们想要确保连续,也就是说,如果我们想要确保从文章中选择一个子序列作为答案,我们可以使用pt-net只预测答案的开始和结束。在本例中,pt-net只需要从输入通道中选择两个字符,而通道中这两个字符之间的所有字符都被视为答案。具体来说,我们可以将预测的答案表示为两个整数![]() ,其中
,其中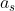 和
和![]() 是1到P之间的整数。
是1到P之间的整数。
我们将上面的第一个设置称为序列模型,将上面的第二个设置称为边界模型。对于这两种模型,我们假设给出了一组三元组![]() 的训练实例。两种神经网络模型的概述如图1所示。两种模型都由三层组成:(1)LSTM预处理层,它使用LSTMs对文章和问题进行预处理。(2)匹配- lstm层,尝试将文章与问题匹配。(3)答题指针(Ans-Ptr)层,使用tr- net从短文中选择一组字符作为答题。两种模型的区别只在于第三层。
的训练实例。两种神经网络模型的概述如图1所示。两种模型都由三层组成:(1)LSTM预处理层,它使用LSTMs对文章和问题进行预处理。(2)匹配- lstm层,尝试将文章与问题匹配。(3)答题指针(Ans-Ptr)层,使用tr- net从短文中选择一组字符作为答题。两种模型的区别只在于第三层。
 Figure 1: An overview of our two models. Both models consist of an LSTM preprocessing layer, a match-LSTM layer and an Answer Pointer layer. For each match-LSTM in a particular direction, h¯q i , which is defined as H qα | i , is computed using the α in the corresponding direction, as described in either Eqn. (2) or Eqn. (5).
Figure 1: An overview of our two models. Both models consist of an LSTM preprocessing layer, a match-LSTM layer and an Answer Pointer layer. For each match-LSTM in a particular direction, h¯q i , which is defined as H qα | i , is computed using the α in the corresponding direction, as described in either Eqn. (2) or Eqn. (5).
LSTM Preprocessing Layer
LSTM预处理层的目的是将上下文信息合并到文章和问题中每个字符的表示中。我们使用标准的单向LSTM 2分别处理短文和问题,如下图所示:
![]()
![]()
结果矩阵![]() 和
和![]() 是段落和问题的隐藏表示,其中l为隐藏向量的维数。换句话说,
是段落和问题的隐藏表示,其中l为隐藏向量的维数。换句话说,![]() (或
(或 )中的第i列向量
)中的第i列向量![]() (或
(或![]() )表示段落(或问题)中的第i个字符以及来自左边的一些上下文信息。
)表示段落(或问题)中的第i个字符以及来自左边的一些上下文信息。
Match-LSTM Layer
我们以问题为前提,以段落为假设,应用match-LSTM模型到我们的机器理解问题中。match-LSTM依次通过段落中的词,在 位置,它首先使用标准词-词的注意机制来获取关注权向量
位置,它首先使用标准词-词的注意机制来获取关注权向量![]() 如下:
如下:
![]()
![]()
其中![]() ,
,![]() 是用来学习的参数,
是用来学习的参数,![]() 是单向match-LSTM在
是单向match-LSTM在 位置的隐藏向量,输出生成器(
位置的隐藏向量,输出生成器(![]() )产生一个矩阵或行向量重复左边的矢量和标量
)产生一个矩阵或行向量重复左边的矢量和标量 次。
次。
从本质上讲,结果注意力权重 显示段落第i个字符和问题第j个字符之间的匹配程度。接下来,我们使用注意力权重向量
显示段落第i个字符和问题第j个字符之间的匹配程度。接下来,我们使用注意力权重向量![]() 和问题向量获得其加权向量,并且要结合段落当前字符形成一个向量
和问题向量获得其加权向量,并且要结合段落当前字符形成一个向量![]() :
:
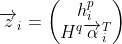
这个向量![]() 被输入到一个标准的单向LSTM中,形成我们所谓的match-LSTM:
被输入到一个标准的单向LSTM中,形成我们所谓的match-LSTM:
![]()
其中,![]() 。
。
我们进一步在反方向构建了一个类似的match-LSTM。其目的是获得一种表示形式,该表示形式对文章中每个字符的上下文中各个方向的上下文进行编码。为了构建这个反向match-LSTM,我们首先定义:
![]()
![]()
注意,这里的参数与之前使用的相同。(2).然后我们以类似的方式定义![]() ,最后将
,最后将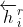 定义为反向匹配lstm产生的位置i的隐藏表示
定义为反向匹配lstm产生的位置i的隐藏表示
令![]() 表示隐藏状态
表示隐藏状态![]() ,
,![]() 表示隐藏状态
表示隐藏状态![[\overleftarrow{h}^r_1,\overleftarrow{h}^r_2,...,\overleftarrow{h}^r_P]](http://img.e-com-net.com/image/info8/36685119322d4884b256c30ce30c11e5.gif) 。我们将
。我们将![]() 定义为两者的拼接:
定义为两者的拼接:
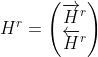
Answer Pointer Layer
顶层是Answer Pointer (Ans-Ptr)层,由Vinyals等人(2015)引入的Pointer Net驱动。这一层使用序列![]() 作为输入。回想一下,我们有两个不同的模型:序列模型生成一个答案标记序列,但是这些标记在原始段落中可能不是连续的。边界模型只生成答案的开始字符和结束字符,然后将原始段落中这两个字符之间的所有字符视为答案。现在我们分别解释这两个模型。
作为输入。回想一下,我们有两个不同的模型:序列模型生成一个答案标记序列,但是这些标记在原始段落中可能不是连续的。边界模型只生成答案的开始字符和结束字符,然后将原始段落中这两个字符之间的所有字符视为答案。现在我们分别解释这两个模型。
序列模型:回想一下,在序列模型中,答案由一个整数序列![]() 表示,表示原始段落中所选标记的位置。Ans-Ptr层以顺序的方式为这些整数的生成建模。由于答案的长度不是固定的,为了在某个点停止生成答案标记,我们允许每个
表示,表示原始段落中所选标记的位置。Ans-Ptr层以顺序的方式为这些整数的生成建模。由于答案的长度不是固定的,为了在某个点停止生成答案标记,我们允许每个 取一个介于1和P + 1之间的整数值,其中P + 1是一个表示答案结束的特殊值。一旦设置为P + 1,答案的生成就停止了。
取一个介于1和P + 1之间的整数值,其中P + 1是一个表示答案结束的特殊值。一旦设置为P + 1,答案的生成就停止了。
为了生成由表示的第k个回答字符,首先,使用注意机制再次获得一个注意力权重向量![]() ,其中
,其中![]() 是从段落中选择第j个字符作为第k个答案字符的概率,
是从段落中选择第j个字符作为第k个答案字符的概率,![]() 表示答案在段落第k个字符结束的概率,
表示答案在段落第k个字符结束的概率, 建模如下:
建模如下:
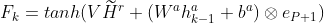
![]()
其中![]() 为
为![]() 与零向量的结合,
与零向量的结合,![]() 是要学习的参数,(
是要学习的参数,(![]() )遵循相同的定义,和
)遵循相同的定义,和![]() 是答案第k-1位置的隐藏向量,LSTM如下定义:
是答案第k-1位置的隐藏向量,LSTM如下定义:

然后我们可以将生成答案序列的概率建模为:
![]()
并且
![]()
为了训练模型,根据训练实例,我们将损失函数最小化如下:
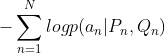
边界模型:边界模型的工作方式与上面的序列模型非常相似,只是我们不需要预测下标![]() 的序列,只需要预测两个指标和
的序列,只需要预测两个指标和![]() 。因此,与上面的序列模型的主要区别在于,在边界模型中,我们不需要向
。因此,与上面的序列模型的主要区别在于,在边界模型中,我们不需要向![]() 添加补零,并且生成答案的概率被简单地建模为:
添加补零,并且生成答案的概率被简单地建模为:
![]()
通过引入搜索机制,进一步扩展了边界模型。具体来说,在预测过程中,我们试图限制跨度的长度,并全局搜索由 计算出的最大概率跨度。此外,由于边界有一个固定数量的值序列,可以简单地组合双向Ans-Ptr来微调正确的跨度。
计算出的最大概率跨度。此外,由于边界有一个固定数量的值序列,可以简单地组合双向Ans-Ptr来微调正确的跨度。
3 EXPERIMENTS
在本节中,我们将展示我们的实验结果,并进行一些分析,以更好地理解我们的模型是如何工作的。
3.1 DATA
我们使用Stanford Question answer Dataset (SQuAD) v1.1进行实验。SQuAD中的文章来自维基百科上的536篇文章,涵盖了广泛的话题。每一段都是维基百科文章的一段,每一段都有5个问题。总共有23215篇文章和107785个问题。数据被分成一个训练集(有87,599个问题-答案对)、一个开发集(有10,570个问题-答案对)和一个隐藏的测试集。
3.2 EXPERIMENT SETTINGS
我们首先标记所有的段落,问题和答案。生成的词汇表包含117K个惟一的单词。我们使用GloVe (Pennington et al., 2014)中的word embeddings来初始化模型。GloVe中没有找到的单词初始化为零向量。这个词的嵌入在模型的训练过程中不会更新。
隐藏层的维数l设置为150或300。我们使用ADAMAX (Kingma &英航,2015)系数β1 = 0.9和β2 = 0.999优化模型。每次更新都通过30个实例的小批处理计算。我们不使用l2正则化。
性能由两个指标度量:与真实答案精确匹配的百分比,以及将预测答案中的标记与真实答案中的标记进行比较时的单词级F1得分。注意,在开发集和测试集中,每个问题都有三个基本的真实答案。F1得分与最佳匹配的答案用于计算平均F1得分。
3.3 RESULTS
我们的模型结果以及Rajpurkar等人(2016)和Yu等人(2016)给出的基线结果如表2所示。我们可以看到,我们的两个模型都明显优于Rajpurkar等人(2016)基于精心设计的特征的logistic回归模型。此外,我们的边界模型优于序列模型,精确匹配得分为61.1%,F1得分为71.2%。特别是在精确匹配分数方面,边界模型明显优于序列模型。通过对logistic回归模型的改进,证明了我们的端到端神经网络模型在不需要太多特征工程的情况下,对该任务和数据集是非常有效的。考虑到边界模型的有效性,我们进一步探讨了该模型。观察,大多数答案是相对较小的跨度大小,我们只是限制最大跨度不超过15个字符和预测进行了实验与广度搜索,在开发集上F1因此提升了1.5%。此外,我们还尝试在模型中增加内存维度l或添加双向预处理LSTM或添加双向Ans-Ptr。使用前两种方法对开发数据的改进非常小。而在双向预处理LSTM的基础上加入Bi-Ans-Ptr,可以使F1提高1.2%。最后,通过简单计算5个边界模型的边界概率乘积,寻找不超过15个标记的最可能跨度,探讨了集成方法。该集成方法的性能最好,如表所示。
3.4 FURTHER ANALYSES
为了更好地理解我们的模型的优缺点,我们对下面的结果进行了一些进一步的分析。
首先,我们怀疑较长的答案更难预测。来验证这个假设,我们分析了性能方面的精确匹配和F1的分数对答案长度发展。例如,对于问题的答案包含超过9个字符,F1边界模型的得分下降到55%左右,精确匹配分数降到只有30%左右,而F1分数和精确匹配分数的近72%和67%,分别与个标记的问题的答案。这支持了我们的假设。
接下来,我们分析了我们的模型在不同问题组上的性能。我们使用一种简单的方法,根据我们定义的一组疑问词将问题分成不同的组,这些疑问词包括“what,” “how,” “who,” “when,” “which,” “where,” and “why.”。这些不同的疑问词大致指答案类型不同的问题。例如,“when”问题寻找时态表达式作为答案,而“where”问题寻找位置作为答案。根据开发数据集的性能,我们的模型最适合“when”问题。这可能是因为在这个数据集中,时态表达式相对容易识别。另外一组问题的答案是名词短语,如“what”问句、“which”问句和“where”问句,也会得到相对较好的结果。另一方面,“why”是最难回答的问题。这并不令人惊讶,因为“why”问题的答案可能非常多样,而且它们不受限于任何特定类型的短语。
最后,我们想检验match-LSTM层中使用的注意机制是否能够有效地帮助模型找到答案。我们展示了注意力向量α如图2所示。在图中,颜色越深,重量越大。我们可以看到,根据注意力的权重,有些单词已经很好地对齐了。例如,文章中的“German”与第一个问题中的“language”很好地对齐,模型成功地预测出“German”作为问题的答案。对于第二个问题中的疑词“who”,“teacher”实际上得到了相对较高的注意权重,模型预测出后面的短语“Martin Sekulic”作为答案,这是正确的。对于最后一个以“为什么”开头的问题,注意力的权重分布更为均匀,而且不清楚哪些词与“为什么”对齐。