目标检测YOLO初学入门综述
文章目录
- 本文是本人在学习YOLO大家族中的一点总结,新开坑持续更新中~
- 一、目标检测算法简介
- 二、YOLO系列中输入侧,Backbone,Neck,Head,Tricks的特点
-
- 先上个YOLO论文代码大合集(截止22年11月)
- 三、YOLOV1
- 三、YOLOV4
- 四、YOLOV5
- 五、YOLOV6
- 六、YOLOV7
- 七、PP-YOLO
- 总结
- 参考资料
本文是本人在学习YOLO大家族中的一点总结,新开坑持续更新中~
仅适合初学者食用,仅适合初学者食用, 仅适合初学者食用。 里面出现的一些英文先记着混眼熟就完事,初学者了解了可以多学(zhuang)习(bi)
笔者水平有限,写的不对的地方欢迎大佬指出来~,本文参考文献在文末。
引言:作为一个在计算机视觉领域长期存在的具有挑战性的
基础性问题,目标检测在近几十年的研究中都是热点领域。
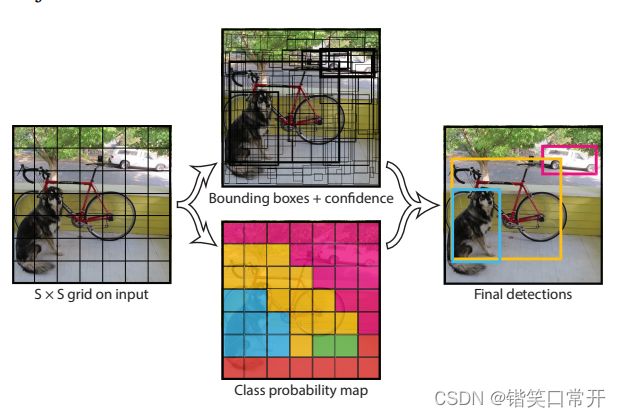
目标检测即找出图像中所有感兴趣的物体,包含物体定位和物体分类两个子任务,同时确定物体的类别和位置。
目标检测模型的主要性能指标是检测准确度和速度,对于准确度,目标检测是要考虑到物体的定位准确性,而不单单是分类准确度。
一、目标检测算法简介
深度学习算法主导的目标检测技术分为Two-stage(两阶段)和One-stage(单阶段)算法。因为Two Stage框架先于One Stage被提出,所以先介绍Two-stage。
一、Two-stage类别的目标检测算法.
技术框架分为两部分:
- 使用Region Proposal Network(RPN)处理输入图像,从输入图像中抽取感兴趣区域,也叫候选区(Region of Interest,俗称Rol),这里面包括我们想要检测目标的部分位置信息。
----可以理解为选备胎,海王们选出备胎了那就要进行筛选备胎嘛,所以进入下面步骤,选出最好的那一个。 - 抽取每一个RoI的特征,现在一般是用CNN网络去抽取特征。结合若干全连接层(Fully connected layers)完成对每一个RoI的类别识别。这一步主要是完成了分类和精确坐标回归。
总之就是做了两件事,六字口诀–先定位(找到感兴趣的区域),后识别(给该区域分类和位置精修)。上来先定位是为了将有用的前景信息尽可能多地保留下来,滤除掉对后续任务无用的背景信息,之后
再将有用的前景信息进行分类。
优点:因为进行了两个步骤,因此精度肯定是有保障的。
缺点:也正是因为进行了两个步骤,那计算时间成本就不可避免的增加了,所以才有了后面One-stage算法的提出。
代表作:常见的有RCNN、Fast RCNN、Faster RCNN以及Mask RCNN等。
二、One-stage类别的目标检测算法.
最早的One-stage工作大概可以追溯到YOLOv1,它最大的亮点就是它只需要一个单一的网络就能够同时完成定位和分类两件事。
YOLO的这种做法其实就是对Two-stage中的RPN的合理扩展。前面已经说过,RPN网络就干一件事,处理输入图像,最后输出包含前景信息的RoI,这里,我们稍微想得细一些,RPN其实它同时完成了定位和分类两件事,定位就是输出RoI的边界框坐标,分类就是判别是前景还是背景。就结果来看,我们说RPN是得到了RoI,完成了定位,但就过程而言,它还做了分类,只不过分类的是前背景这种,不是我们感兴趣的阿猫阿狗。
那么,一个很合理的idea就出来了:能否将RPN中的“前景/背景”二分类推广到我们感兴趣的类别识别上,即一步就数出来RoI的坐标和RoI的类别呢?于是,YOLO便出来了,也摒弃了RPN模块。
流程:输入一个Tensor(原图像),将输入图片分割成NxN的image patch(图像块),然后每个image patch有M个固定尺寸的anchor box(先验框), 输出anchor box的位置和分类标签。
优点:因为模型结构相对简洁,所以识别的速度快,常用于工业的部署,甚至可以部署到军事上面。(小故事:YOLOv1-3作者Joseph Redmon就是因为美军将其研究部署到无人机上面才宣布不继续推进了,后面的一些系列都是其他研究人员站在巨人的肩膀继续向上的)
缺点:精度方面略微欠缺。你想嘛,别人Two是两个小伙伴合作一个任务,One是一个小伙伴自己做,压力很大的,难免结果(精度方面)会差一丢丢。
代表作:常见的有SSD、Retina-Net以及YOLO系列大家族(v1-v7)等。
三、总结.
One-stage检测器大大简化了Two-stage的框架,将定位和分类全部交给RPN独自完成,后续的RoI pooling等统统拿掉。
一般情况下,Two-stage算法在准确度上有优势,而One-stage算法在速度上有优势。不过,随着研究的发展,两类算法都在两个方面做改进,均能在准确度和速度上取得不错的结果。
从发展的眼光来看,从Two-stage到One-stage是一个历史的必然,事物的发展总是由繁至简,奥卡姆剃刀原理体现得淋漓尽致。
二、YOLO系列中输入侧,Backbone,Neck,Head,Tricks的特点
输入侧
YOLO系列中的输入侧主要包含了输入数据,数据增强算法以及一些特殊预处理操作。
输入数据可以是图片,也可以是视频。
数据增强算法包含通用增强以及YOLO自带的一些高阶增强算法。
YOLO系列的输入侧可谓是通用性最强的一个部分,具备很强的向目标检测其他模型,图像分类,图像分割,目标跟踪等方向迁移应用的价值。
Backbone(骨干网络)
YOLO系列中的Backbone结构主要作为算法模型的一个核心特征提取器(等于把信息进行了一个提取浓缩),随着时代的变迁不断发展。某种程度上,YOLO系列的各个Backbone代表着当时的高价值模型与AI行业的发展记忆。
YOLO系列的Backbone与输入侧一样,是通用性非常强的一个部分,在不同的计算机视觉细分方向,都有广泛的应用。
Neck
YOLO从v3版本开始设计Neck结构,其中的特征融合思想最初在FPN(feature pyramid networks多尺度预测,特征金字塔网络 )网络中提出,在YOLOv3中进行结构的微调,最终成为YOLO后续系列不可或缺的部分。
《Feature Pyramid Networks for Object Detection》是17年的论文,解决的问题就是所有目标检测算法的短板——识别小尺度目标精度低的问题。
我们假设在深层网络中,最后的高层特征图中一个像素可能对应着输出图像20x20的像素区域,那么小于20x20像素的小物体的特征大概率已经丢失。 与此同时,低层的特征语义信息比较少,但是目标位置准确,这是对小目标检测有帮助的。FPN将高层特征与底层特征进行融合,从而同时利用低层特征的高分辨率和高层特征的丰富语义信息,并进行了多尺度特征的独立预测,对小物体的检测效果有明显的提升。
对最底层的特征进行向上采样,并与该底层特征进行融合,得到高分辨率、强语义的特征(即加强了特征的提取)。

Head
YOLO系列中的Head结构主要包含了Head检测头,损失函数部分以及Head结构的优化策略。
- Head检测头
这里体现了YOLO系列“简洁美”的思想,与two-stage检测算法相比,YOLO取消了RPN模块,设计了特征提取网络Backbone+检测头Head的end-to-end整体逻辑。
- 损失函数部分
YOLO系列的损失函数部分可谓是目标检测领域中的“掌上明珠”,其在业务,竞赛和研究等维度都有很强的迁移价值。那些数学公式看的我头皮发麻,改天尝试手推一波look look。
- Head结构的优化策略
可以看看Rocky的一篇文章YOLOv1-v7全系列大解析(Head篇)
Tricks
YOLO系列中使用的Tricks,从横向角度来看,基本算是当时的最优Trcks;从纵向角度来看,其大部分都具备了可迁移性,强适应性,到现在依旧发挥余热。
YOLO系列中使用的Tricks和Backbone以及输入侧一样,是通用性非常强的一个部分,迁移应用在业务,竞赛,研究等维度,可能会带来出其不意的效果与惊喜。
先上个YOLO论文代码大合集(截止22年11月)
YOLOv1论文名以及论文地址:You Only Look Once:Unified, Real-Time Object Detection
YOLOv1开源代码:YOLOv1-Darkent
YOLOv2论文名以及论文地址:YOLO9000:Better Faster Stronger
YOLOv2开源代码:[YOLOv2-Darkent](https://github.com/pjreddie/darknet)
YOLOv3论文名以及论文地址:YOLOv3: An Incremental Improvement
YOLOv3开源代码:YOLOv3-PyTorch
YOLOv4论文名以及论文地址:YOLOv4: Optimal Speed and Accuracy of Object Detection
YOLOv4开源代码:YOLOv4-Darkent
YOLOv5论文名以及论文地址:TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-Captured Scenarios
YOLOv5开源代码:YOLOv5-PyTorch
YOLOx论文名以及论文地址:YOLOX: Exceeding YOLO Series in 2021
YOLOx开源代码:YOLOx-PyTorch[
YOLOv6论文名以及论文地址:YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
YOLOv6开源代码:YOLOv6-PyTorch
YOLOv7论文名以及论文地址:YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
YOLOv7开源代码:Official YOLOv7-PyTorch
PP-YOLOE+资料;
PP-YOLOE论文名以及论文地址:PP-YOLOE: An evolved version of YOLO
PP-YOLOE+开源代码:https://github.com/PaddlePaddle/PaddleDetection/tree/release/2.5/configs/ppyoloe
三、YOLOV1
YOLOv1 输入侧解析
YOLOv1在输入侧做的最多的工作是调整输入图像的尺寸以支持对图像细粒度特征的挖掘与检测。
同样的,YOLO系列的grid(网格)逻辑(“分而治之”)也从输入侧开始展开,直到Head结构输出相应结果。
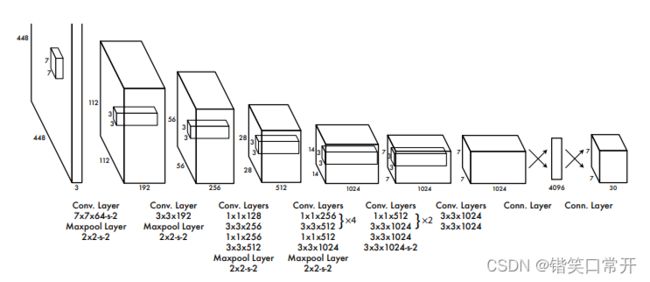
YOLOv1 Backbone大解析
YOLOv1的Backbone结构主要受启发于GoogLeNet思想,从上面的整体结构可以看出,模型结构非常简洁,卷积一卷到底。
by the way YOLOv1的backbone结构中使用了Leaky ReLu激活函数,但并没有引入Batch Normalization层,当时对BN方面研究还不深入,现在网络里面必有BN层。
YOLOv1 Head大解析
YOLOv1其Head结构整体逻辑比较直观,并且对后续的版本影响深远。
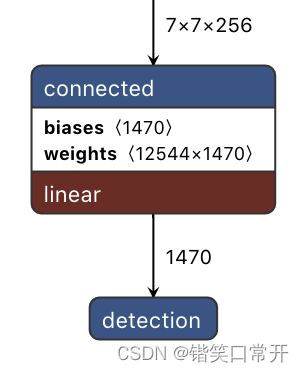
YOLOv1中,图片被划分为7X7的网格(grid cell),每个网络在Head结构中进行独立检测。
YOLOv1在Inference(推理)过程中并不是把每个单独的网格作为输入,网格只是用于物体ground truth(人工标注的结果)中心点位置的分配,如果一个物体的ground truth中心点坐标在一个grid cell中,那么就认为这个grid cell就是包含这个物体,这个物体的预测就由该grid cell负责。而不是对图片进行切片,并不会让网格的视野受限且只有局部特征。
YOLOv1的输出是一个7×7×30的张量, 7X7表示把输入图片划分成 7×7的网格。
30是怎么来的呢?30=(2×5+20)表示每一个网格的通道维度,代表YOLOv1中每个网格能预测2个框,每个框能预测5个参数(x,y,w,h,c)加上20个种类。
把上述内容转换成通用公式就是网格一共是 (S×S)个,每个网格产生B个检测框,每个检测框会经过网络最终得到相应的bounding box。最终会得到个bounding box,每个bounding box都包含5个预测值,分别是bounding box的中心坐标 ,bounding box的宽高和置信度C。其中C代表网格中box能与物体的取得的最大IOU值。
到这里终于可以引出对工业界产生深远影响的YOLOv1的损失函数,YOLO系列的后续版本的损失函数都是从这个最初的形式优化而来。
LOSS公式如下图所示

三、YOLOV4
四、YOLOV5
五、YOLOV6
六、YOLOV7
七、PP-YOLO
总结
欢迎大家点赞收藏~,如果再来个小小的关注那就是对我最大的鼓励了,向您salute!
参考资料
深度学习中的目标检测网络中的one stage和two stage?–知乎
万字综述:目标检测模型YOLOv1-v7深度解析
目标检测算法-----YOLOv1解读