Tensorflow.feature_column的总结
一、简介
tensorflow提供了一个功能强大的特征处理函数tf.feature_column,feature columns是原始数据与estimator之间的过程,其内容比较丰富,可以将各种各样的原始数据转换为estimator可以用的格式。
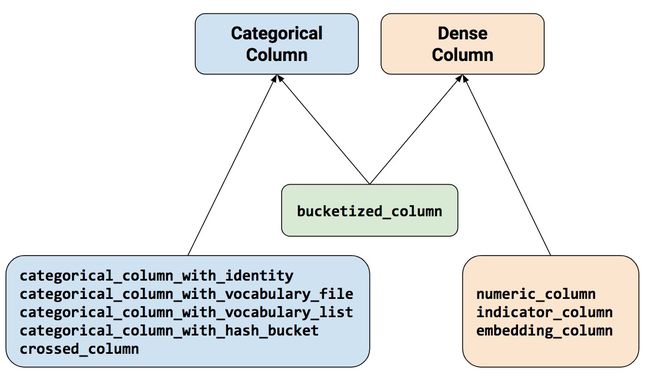
特征数据主要包括categorical和dense(numeric或者continuous)两类,处理方法是使用tensorflow中的feature_column接口来进行定义,如下图,总共有九种不同的函数,分别有五种categorical function、三种numerical function 加上一种bucketized_column可属于任何一种。
特别需要注意的是:categorical column中的 with_identity其实和 dense column中的indicator_column没有区别,都是类别特征的one-hot表示,但是其属于不同的特征类别,前者属于categorical后者属于dense,对于estimator编写的不同网络而言,其可接受的one-hot类型不同,这里在实际操作中需要注意转换。关于这一点后文会说明。
二、类别列Categorical column
2.1 categorical_column_with_identity
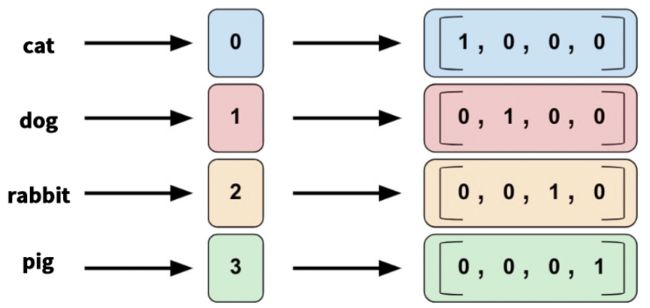
这个功能就是将类别特征转化为one-hot编码。
假设我们有4种宠物分类:猫,狗,兔子,猪,对应列表[a1,a2,a3,a4]那么就有:
语法格式
categorical_column_with_identity(
key,
num_buckets,
default_value=None
)
测试代码
import tensorflow as tf
pets = {'pets': [2,3,0,1]} #猫0,狗1,兔子2,猪3
column = tf.feature_column.categorical_column_with_identity(
key='pets',
num_buckets=4)
indicator = tf.feature_column.indicator_column(column)
tensor = tf.feature_column.input_layer(pets, [indicator])
with tf.Session() as session:
print(session.run([tensor]))
运行输出结果
[array([[0., 0., 1., 0.], #兔子
[0., 0., 0., 1.], #猪
[1., 0., 0., 0.], #猫
[0., 1., 0., 0.]], dtype=float32)] #狗
注: 我们关注到代码里面有个input_layer的操作,input_layer的说明如下:
tf.feature_column.input_layer(
features,
feature_columns,
weight_collections=None,
trainable=True,
cols_to_vars=None,
cols_to_output_tensors=None
)
features:字典,最主要的是 dict的key一定要与 feature_columns的key一致,后续才能根据key进行匹配
feature_columns:必须是继承于DenseColumn的numeric_column, embedding_column, bucketized_column, indicator_column。如果feature是类别的,那么必须先用embedding_column或者indicator_column封装一下使用。
这也就是为什么在代码中出现了indicator = tf.feature_column.indicator_column(column)。
2.2 categorical_column_with_vocabulary_list
在上面的例子我们看到,必须手工在excel里面把cat、dog、rabbit、pig转为0123才行tf.feature_column.categorical_column_with_vocabulary_list这个方法就是将一个单词列表生成为分类词汇特征列的。
语法格式
categorical_column_with_vocabulary_list(
key,
vocabulary_list,
dtype=None,
default_value=-1,
num_oov_buckets=0
)
参数num_ovv_buckets的意思是Out-Of-Vocabulary,也就是说,如果数据里面的某个单词没有对应的箱子,比如出现了老鼠mouse,那么就会在【箱子总数=num_ovv_buckets+ 箱子总数】,如果num_ovv=3, 那么老鼠mouse会被标记为4~6中的某个数字,可能是5,也可能是4或6。num_ovv不可以是负数。
测试代码
import tensorflow as tf
pets = {'pets': ['rabbit','pig','dog','mouse','cat']}
column = tf.feature_column.categorical_column_with_vocabulary_list(
key='pets',
vocabulary_list=['cat','dog','rabbit','pig'],
dtype=tf.string,
default_value=-1,
num_oov_buckets=3)
indicator = tf.feature_column.indicator_column(column)
tensor = tf.feature_column.input_layer(pets, [indicator])
with tf.Session() as session:
session.run(tf.global_variables_initializer())
session.run(tf.tables_initializer())
print(session.run([tensor]))
输出结果如下,注意到独热list 有7个元素,这是由于【猫狗兔子猪4个+num_oov_buckets(3)】得到的。
[array([[0., 0., 1., 0., 0., 0., 0.], #'rabbit'
[0., 0., 0., 1., 0., 0., 0.], #'pig'
[0., 1., 0., 0., 0., 0., 0.], #'dog'
[0., 0., 0., 0., 0., 1., 0.], #mouse
[1., 0., 0., 0., 0., 0., 0.]], dtype=float32)] #'cat'
2.3 categorical_column_with_vocabulary_file
在2.2中,如果单词有些时候比较多,这时候可以直接从文件中读取文字列表:
import os
import tensorflow as tf
pets = {'pets': ['rabbit','pig','dog','mouse','cat']}
dir_path = os.path.dirname(os.path.realpath(__file__))
fc_path=os.path.join(dir_path,'pets_fc.txt')
column=tf.feature_column.categorical_column_with_vocabulary_file(
key="pets",
vocabulary_file=fc_path,
num_oov_buckets=0)
indicator = tf.feature_column.indicator_column(column)
tensor = tf.feature_column.input_layer(pets, [indicator])
with tf.Session() as session:
session.run(tf.global_variables_initializer())
session.run(tf.tables_initializer())
print(session.run([tensor]))
其中pets_fc.txt每行一个单词如:
cat
dog
rabbit
pig
得到以下结果,这次我们oov使用了0,并没有增加元素数量,但是也导致了mouse变成了全部是0的列表
[array([[0., 0., 1., 0.], #rabbit
[0., 0., 0., 1.], #pig
[0., 1., 0., 0.], #dog
[0., 0., 0., 0.],#mosue
[1., 0., 0., 0.]], dtype=float32)] #cat
2.4 categorical_column_with_hash_bucket
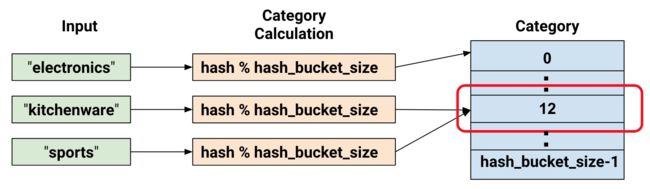
categorical_column_with_hash_bucket:对于处理包含大量文字或数字类别的特征时可使用hash的方式,这能快速地建立对应的对照表,缺点则是会有哈希冲突的问题。
哈希列HashedColumn对于大数量的类别很有效(vocabulary的file模式也不错),尤其是语言文章处理,将文章分句切词之后,往往得到大数量的单词,每个单词作为一个类别,对于机器学习来说,更容易找到潜在的单词之间的语法关系。
但哈希也会带来一些问题。如下图所示,我们把厨房用具kitchenware和运动商品sports都标记成了分类12。这看起来是错误的,不过很多时候tensorflow还是能够利用其他的特征列把它们区分开。所以,为了有效减少内存和计算时间,可以这么做。
语法格式
categorical_column_with_hash_bucket(
key,
hash_bucket_size,
dtype=tf.string
)
测试代码
import tensorflow as tf
colors = {'colors': ['green','red','blue','yellow','pink','blue','red','indigo']}
column = tf.feature_column.categorical_column_with_hash_bucket(
key='colors',
hash_bucket_size=5,
)
indicator = tf.feature_column.indicator_column(column)
tensor = tf.feature_column.input_layer(colors, [indicator])
with tf.Session() as session:
session.run(tf.global_variables_initializer())
session.run(tf.tables_initializer())
print(session.run([tensor]))
运行得到如下的输出,我们注意到red和blue转化后都是一样的,yellow,indigo,pink也都一样,这很糟糕。
[array([[0., 0., 0., 0., 1.],#green
[1., 0., 0., 0., 0.],#red
[1., 0., 0., 0., 0.],#blue
[0., 1., 0., 0., 0.],#yellow
[0., 1., 0., 0., 0.],#pink
[1., 0., 0., 0., 0.],#blue
[1., 0., 0., 0., 0.],#red
[0., 1., 0., 0., 0.]], dtype=float32)]#indigo
将hash_bucket_size箱子数量设置为10,这个问题可以得到解决。箱子数量的设置很重要,越大获得的分类结果越精确。
有一些设置hash_bucket_size的经验:hash_bucket_size的大小一般设置为总类别数的2-5倍,但hash_bucket_size可以设大也可以设小 设小了节约空间但是增大了冲突;设大了增加空间但是减少了冲突。具体情况需要试验。
2.5 crossed_column
交叉列可以把多个特征合并成为一个特征,比如把经度longitude、维度latitude两个特征合并为地理位置特征location。
语法格式
tf.feature_column.crossed_column(
keys,
hash_bucket_size,
hash_key=None
)
测试代码
import tensorflow as tf
featrues = {
'longtitude': [19,61,30,9,45],
'latitude': [45,40,72,81,24]
}
longtitude = tf.feature_column.numeric_column('longtitude')
latitude = tf.feature_column.numeric_column('latitude')
# 这里是分桶操作,接下来会介绍
longtitude_b_c = tf.feature_column.bucketized_column(longtitude, [33,66])
latitude_b_c = tf.feature_column.bucketized_column(latitude,[33,66])
# 12是人为指定
column = tf.feature_column.crossed_column([longtitude_b_c, latitude_b_c], 12)
indicator = tf.feature_column.indicator_column(column)
tensor = tf.feature_column.input_layer(featrues, [indicator])
with tf.Session() as session:
session.run(tf.global_variables_initializer())
session.run(tf.tables_initializer())
print(session.run([tensor]))
上面的代码中进行了分箱操作,分成~33,33~66,66~三箱,运行得到下面输出
[array([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.]], dtype=float32)]
至此,类别特征的5个函数我们已经介绍完了。
三、稠密列Dense column
3.1 numeric_column
tf.feature_column.numeric_column主要处理的是原始数据是实数(默认为tf.float32),这样的特征值模型可以直接使用,并不需要做其他任何转换。它的默认格式如下
numeric_column(
key,
shape=(1,),
default_value=None,
dtype=tf.float32,
normalizer_fn=None
)
调用方法如下所示:
import tensorflow as tf
price = {'price': [[1.], [2.], [3.], [4.]]} # 4行样本
column = tf.feature_column.numeric_column('price', normalizer_fn=lambda x:x+2)
tensor = tf.feature_column.input_layer(price,[column])
with tf.Session() as session:
print(session.run([tensor]))
将会输出以下内容,每个数值都被+2处理了:
[array([[3.],
[4.],
[5.],
[6.]], dtype=float32)]
默认情况下,创建的是一个单值(标量)。可以使用shape参数来指定其他形状,如下所示:
# Represent a 10-element vector in which each cell contains a tf.float32.
vector_feature_column = tf.feature_column.numeric_column(
key="Bowling",
shape=10,
)
# Represent a 10x5 matrix in which each cell contains a tf.float32.
matrix_feature_column = tf.feature_column.numeric_column(
key="MyMatrix",
shape=[10, 5],
)
3.2 indicator_column
indicator_column我们在2.1中已经介绍过了,再次提醒:
categorical column中的 with_identity其实和 dense column中的indicator_column没有区别,都是类别特征的one-hot表示,但是其属于不同的特征类别,前者属于categorical后者属于dense,对于estimator编写的不同网络而言,其可接受的one-hot类型不同,这里在实际操作中需要注意转换。
3.3 embedding_column
其实就是实现了embedding的功能,关于embeddding的原理和应用,有兴趣的可以翻看我以前的博客,我写了很多关于embedding的理论和实践的博客。
语法格式
embedding_column(
categorical_column,
dimension,
combiner='mean',
initializer=None,
ckpt_to_load_from=None,
tensor_name_in_ckpt=None,
max_norm=None,
trainable=True
)
- dimention维度,即每个列表元素数
- combiner组合器,默认meam,在语言文字处理中选sqrtn可能更好
- initializer初始器
- ckpt_to_load_from恢复文件
- tensor_name_in_ckpt可以从check point中恢复
测试代码
import tensorflow as tf
features = {'pets': ['dog','cat','rabbit','pig','mouse']}
pets_f_c = tf.feature_column.categorical_column_with_vocabulary_list(
'pets',
['cat','dog','rabbit','pig'],
dtype=tf.string,
default_value=-1)
column = tf.feature_column.embedding_column(pets_f_c, 3)
tensor = tf.feature_column.input_layer(features, [column])
with tf.Session() as session:
session.run(tf.global_variables_initializer())
session.run(tf.tables_initializer())
print(session.run([tensor]))
结果如下:
[array([[ 0.15651548, -0.620424 , 0.41636208],
[-1.0857592 , 0.03593585, 0.20340031],
[-0.6021426 , -0.48347804, -0.7165713 ],
[-0.36875582, 0.4034163 , -1.0998975 ],
[ 0. , 0. , 0. ]], dtype=float32)]
至此,稠密特征的3个函数我们已经介绍完了。
四、分箱列Bucketized column
4.1 bucketized_column
bucketized_column: 该函数将连续变量进行分桶离散化,输出one-hot的结果,方便连续值指标与分类变量进行交叉特征构建。
如下图所示,比如【80后,90后,00后,10后】这些就是把一个连续的年份(1980~现在)分成了4段,然后准备四个箱子,分别标上【0号箱80后】【1号箱90后】【2号箱00后】【3号箱10后】,其实就是一个分段函数。

测试代码
import tensorflow as tf
years = {'years': [1999,2013,1987,2005]}
years_fc = tf.feature_column.numeric_column('years')
column = tf.feature_column.bucketized_column(years_fc, [1990, 2000, 2010])
tensor = tf.feature_column.input_layer(years, [column])
with tf.Session() as session:
print(session.run([tensor]))
结果
[array([[0., 1., 0., 0.], #1999
[0., 0., 0., 1.], #2013
[1., 0., 0., 0.], #1987
[0., 0., 1., 0.]], #2005
dtype=float32)]
参考文献
【1】Module: tf.feature_column
【2】Tensorflow-FeutureColumns-数据格式-机器学习
【3】tf.feature_column的特征处理探究