NeurIPS'22 | APG:面向CTR预估的自适应参数生成网络
丨目录:
· 摘要
· 背景
· Method
· 实验
· 结语
▐ 摘要
目前基于深度学习的CTR预估模型(即 Deep CTR Models)被广泛的应用于各个应用中。传统的 Deep CTR Models 的学习模式是相对静态的,即所有的样本共享相同的网络参数。然而,由于不同样本的特征分布不尽相同,这样一种静态方式很难刻画出不同样本的特性,从而限制了模型的表达能力,导致次优解。在本文中,我们提出了一个高性能、高效果的通用模块,称为自适应参数生成网络(APG)。其可以基于不同的样本,动态的为CTR模型生成不同的模型参数。大量的实验表明,APG 能够被应用于各种 CTR 模型,并且显著的提升模型效果,同时能节省38.7%的时间开销和96.6%的存储。APG 已在阿里巴巴搜索广告系统部署上线,并获得3%的点击率增长和1%的广告收入增长。目前,该工作已被NeurIPS2022接收。
论 文:APG: Adaptive Parameter Generation Network for Click-Through Rate Prediction
下 载:https://arxiv.org/abs/2203.16218
▐ 1. 背景
近年来,Deep CTR Models在推荐、搜索和广告等领域被广泛应用。这类模型可以被形式化的表达成, 其中分别表示样本的输入输出,是模型参数, 通常是神经网络.
现有的Deep CTR Models可以被分为两大类(1)优化, 通过引入更多的信息(比如用户行为[1,2]、多模态信息[3]、知识图谱[4]等)来丰富特征的表征空间。(2)优化,通过设计先进的网络结构(包括交叉网络[5,6],自动化网络结构[7]等)来提升模型的表达能力。
然而,少有工作关注于模型参数,尤其是模型隐层的参数矩阵。这是另一个与上述正交的一个优化方向。实际上,现有在工作均可以被看成是一种静态模式,也就是说所有的样本共享相同的参数。我们认为这样一种方式是次优的并且限制了模型的表达能力:
一方面,尽管样本间的共性能够通过共享的参数来刻画,但是不利于刻画个性化pattern。具体来说,以电商搜索广告为例,不用用户(活跃用户 vs. 低活用户)、不同品类(服饰 vs. 数码)的特征分布是千差万别的(如图1左所示)。简单对所有样本赋予相同的模型参数很难刻画出样本的特性。
另一方面,共享的参数更容易被高频的特征所主导,在长尾的样本上预估能力有所不足。
由此,我们思考一个问题:我们真的需要用相同的、共享的参数来刻画所有样本吗?
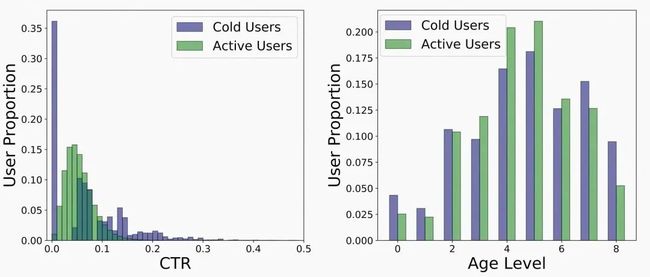 图1 不同用户的特征分布对比(活跃用户 vs. 低活用户). 图左:不同活跃度用户的CTR分布差异较大(特性)。图右:不同活跃度的用户年龄分布类似(共性)
图1 不同用户的特征分布对比(活跃用户 vs. 低活用户). 图左:不同活跃度用户的CTR分布差异较大(特性)。图右:不同活跃度的用户年龄分布类似(共性)
理想情况下,除了刻画共性之外,模型参数期望可以随着样本的不同来动态的调整以刻画样本特性,以此来提升模型的容量和表达能力。为了实现这样一个目标,我们提出一个新的CTR预估范式。核心思想是设计自适应参数生成网络(APG)来根据不同的样本动态的生成参数。首先,我们提出了APG的基础版本: 其中 表示参数生成网络,其通过样本感知的输入,来生成自适应参数。然而这样一个基础模型存在两个问题:
计算和存储开销大。直接生成参数矩阵需要 的计算和存储开销,比该参数对应的CTR预估网络的开销大倍,这样一种开销将是巨大的,尤其是对于web级应用而言,往往是千级别的。实验中也证明,基础版的APG需要而外111倍的时间开销和31倍的性能开销。
次优的pattern学习。由于生成的参数完全依赖于,使得模型更容易刻画出样本的特性而忽视样本间共性的表达(如图1右所示)。
为此,我们基于上述基础模型,提出了高性能高效果的APG。(1)性能上,通过low-rank、decomposed feed-forwarding、parameter sharing等技术,成功的将APG的时间复杂度降到,存储开销降到 (其中)。这样一种开销,甚至可以做到比原始的Deep CTR Models更优。实验表明,相比于原始的Deep CTR Models,APG能够节约38.7%的时间,96.6%的存储开销。(2)效果上,parameter sharing和over parameterization等技术的提出,能同时刻画样本的特性和共性、丰富了模型的表达能力。
▐ 2. Method
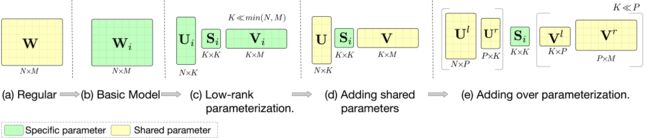 图2 不同版本的APG
图2 不同版本的APG
2.1 Basic Model
APG的基本想法是根据动态的生成参数,即 其中表示参数生成网络。接下来,我们介绍:(1)如何为不同的样本, 设计. (2)如何实现.
2.1.1 Condition Design
这里,我们提出三种策略(包括group-wise, mix-wise, and self-wise)来生成。
Group-wise. 基于样本有些时候可以被分组成不同的Group,同Group内的样本可能有相似的pattern(比如同一user的样本)。因此,我们可以对不同Group样本,生成不同的参数。此时,可以令为表征Group的向量。
Mix-wise. 为了进一步挖掘自适应参数的表达能力和灵活性,我们可以将多种因素考虑进来生成。比如令为
Self-wise. 上述的两种策略均需要先验知识的输入。Self-wise则是一种更加简单的策略,即为Deep CTR Models的每一个隐层输入本身。比如Deep CTR Models的第层隐层, 其中 是第层隐层输入.
2.1.2 Parameters Generation
当得到后,我们可以利用MLP来生成自适应参数(如图2(b)所示):
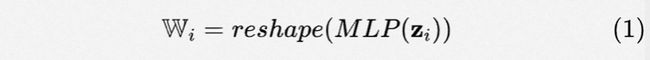
其中 , 。表示将输出向量reshape成矩阵的形式。此时,自适应参数的Deep CTR Model可以表示为:
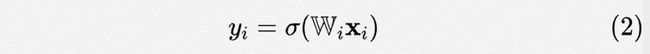
其中 是激活函数。这里主要以MLP形式的Deep CTR Model为例子。但该方法也及易推广至其他形式的CTR预估模型。
2.2 Effective and Efficient Adaptive Parameter Generation Network
如第1章所介绍,上述的基础模型有两大问题:(1)计算存储开销大(2)次优的pattern学习。为了解决这两个问题,我们提出了高性能高效果的APG(如图3所示)。
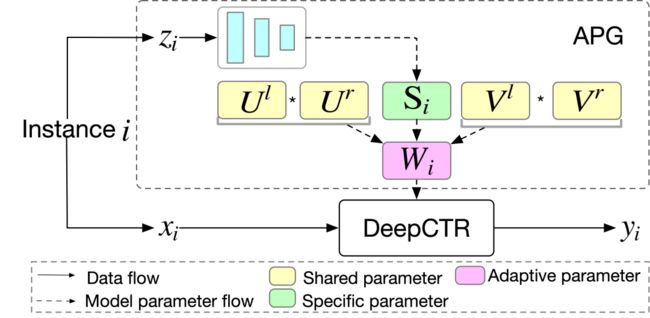 图3 APG 结构图
图3 APG 结构图
Low-rank parameterization. 借鉴于low-rank相关方法,其通过在低秩空间优化参数,取得效果和性能均优的结果[8,9]。这里,我们也假设自适应参数存在低秩关系。由此,我们将分解成低质形式,即其可以由三个子矩阵()相乘得到,其中秩 (如图2(c)所示)。形式化讲,参数生成可以表示成:
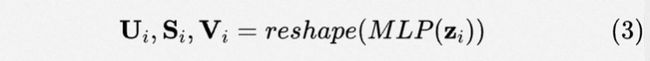
直观上看,我们可以通过设置为一个较小的值,来控制计算和存储开销。同时在不考虑开销下,也可通过增大来增大参数空间。最终,参数生成过程的计算和存储开销均可以被缩减至(如表1所示)。
Decomposed Feed-forwarding. 通过low-rank parameterization之后,公式2可以被改写成:

这里,我们并不是直接通过子矩阵乘来重构,我们设计decomposed feed-forwarding让输入依次乘以各个子矩阵(如图4所示)。这样一种方式,可以避免计算开销较大()的子矩阵乘操作。由于公式4的计算开销是,一个带有自适应参数的Deep CTR Model的隐层整体计算开销是(如表1所示)。
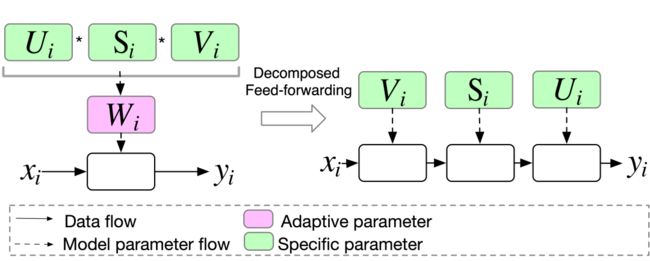 图4 Decomposed feed-forwarding示例
图4 Decomposed feed-forwarding示例
Parameter sharing. 这里我们介绍共性建模的策略。得益于参数矩阵的分解,我们可以更加自由的设计, 和。我们将这三个矩阵分成两类:(1)私有参数:刻画不同样本的特性(2)共享参数:所有样本共享,刻画样本共性。具体来讲,利用规模仅受影响的特点,我们将其设为私有参数以便高效的生成自适应参数。剩下的 和 则作为共享参数(如图2(d)所示)来刻画共性。这样,我们将公式3和4改写成:
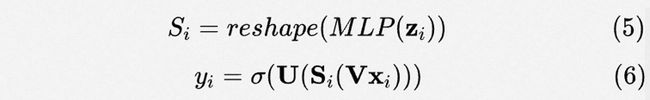
此外,这样一种设计对于性能而言也是十分友好的。因为,私有参数的规模被缩减至,对应的计算开销为。因此整体的带有APG的Deep CTR Model的时间开销被缩减至 (如表1所示)。同时存储开销减少至, 其中和表示存储共享参数和的开销。
Over Parameterization. 相比于采用静态模式下采用的共享参数(如图2(a)所示),在APG中, 和 由于受限于的约束,参数规模很难上去,导致共性刻画不足。因此,为了解决这样一个问题,受over parameterization [10,11]的思想的启发,我们将公式6中的共享参数替代为两个大矩阵(如图2(e)所示):
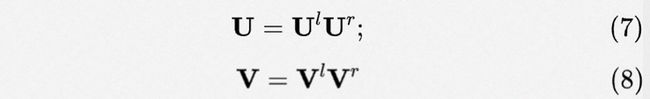
其中,,,, 。尽管, (或 ) 从数学上将等价于 (或者 ),这样一种设计的好处是:(1) 由于, 我们可以增加更多的参数来提升模型的容量 [10,11]。(2) 这样一种矩阵乘的方式,有隐含的正则效果 [8]。
No Additional Inference Latency and Memory Cost. 在训练阶段,通过设置较大的,我们可以增强模型表达能力。在inference阶段,我们可以预先计算并存储好,并且inference的时候直接使用这两个矩阵。这样一来,就保证在inference的时候,可以不引入任何额外的开销(如图5所示)。
 图5 Over Parameterization示例
图5 Over Parameterization示例
2.3 Complexity
 表1 不同版本的APG每一层的计算和存储开销比较。其中SPG指参数生成过程的开销。R-Wi是重构的开销。SPS表示存储共享参数的开销。此外,由于over parameterization不引入额外的存储和时间开销,这里并不记录在内。
表1 不同版本的APG每一层的计算和存储开销比较。其中SPG指参数生成过程的开销。R-Wi是重构的开销。SPS表示存储共享参数的开销。此外,由于over parameterization不引入额外的存储和时间开销,这里并不记录在内。
这里我们详细的分析所提模型在inference阶段的时间和存储复杂度。为了分析方便,参数生成网络被实例化为一层MLP,然后对常规的Deep CTR Model和带有APG的Deep CTR Model的每一层的计算和存储开销进行比较。
Memory Complexity. 对于常规的Deep CTR Model而言,每一层的存储开销是(存共享参数所需)。对于APG而言,其开销有两部分:(1)公式5中生成私有参数的开销;(2)共享参数 的开销。所以合计每层。
Computation Complexity. 对于常规的Deep CTR Model而言,每一层的前向计算开销是。而APG需要来计算私有参数 (即公式5)。同时其ctr预估部分的前向计算需要 (即公式6)。因此,合计。
总结而言,APG 有 的存储开销和计算开销. 又由于且 通常小于, 因此APG有能力比常规的Deep CTR Model在性能上更优。
▐ 3. 实验
3.1 实验设置
数据集
Amazon
MovieLens
IAAC
IndusData
Baselines
WDL
PNN
FIBINET
DIFM
DeepFM
DCN
AutoInt
常规的Deep CTR Model
3.2 CTR 预估任务
公开数据集. APG是一个通用的模块,因此可以将其应用于现有的Deep CTR Models。因此,我们比较带有和不带有APG的情况下,各个CTR预估模型的AUC表现。如表2所示,可以看到通过APG的帮助,所有模型均有显著提升。
 表2 公开数据集上CTR预估实验
表2 公开数据集上CTR预估实验
内部数据. 同时我们也将APG部署在我们的搜索广告引擎中,离线取得0.2%AUC提升,在线取得CTR+3%和RPM+1%的收益。
3.3 效果评估
为了充分评估APG的效果,我们实现了多种版本如表3所示。并且比较不同版本下的效果。由于decomposed feed-forwarding并不影响效果,这里不做比较。结果如表4所示,可以看到(1)对于basic model而言,相比于base,v1引入自适应参数后,效果有所提升。(2)对于low-rank parameterization。相比于v1,v2在效果上没有显著的下降,且对于性能十分友好(详见下章)。(3)对于parameter sharing而言,通过v2和v4的比较,我们可以看到引入共享参数后能进一步提升模型效果。(4)对于over parameterization,相比于v4,v5也是更优的。
 表3 不同版本的APG设置
表3 不同版本的APG设置 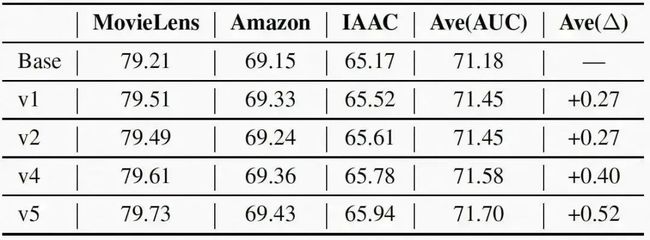 表4 不同版本APG的实验效果
表4 不同版本APG的实验效果
3.4 性能评估
这里我们评估各个版本APG(如表3所示)的计算和存储在inference时的开销。对于所有版本,我们设置Deep CTR Model的每一个隐层从[64,32,16]到[1024,512,256],输入是393维。由于over parameterization不带来额外开销,在此并不比较。结果如表5所示。我们可以看到,(1) v1在时间和存储熵的开销是巨大的,使得其很难在实际中被应用 (2)通过 low-rank parameterization + decomposed feed-forwarding的配合,v3能够显著的减少时间和存储开销。(3)进一步的,引入共享参数后,使得私有参赛计算规模进一步下降。甚至在整体开销上,存储上v4减少45%~96.9%,时间少上减少0.7%~38.7%。
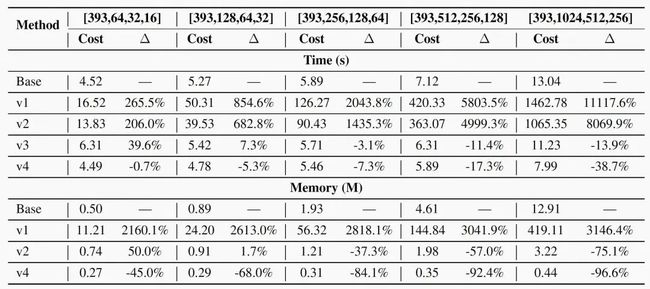 图5 不同版本APG的计算和存储在inference时的开销
图5 不同版本APG的计算和存储在inference时的开销
▐ 结语
本文通过引入动态参数,对不同样本进行参数个性化定制,使得模型表达能力拥有更加广阔的空间。我们相信APG绝不是终点,而是新的起点。这样一种新的CTR预估范式,能够再次赋予CTR模型新的活力。
Reference
[1] Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. Deep interest network for click-through rate prediction. In KDD, pages 1059–1068. ACM, 2018.
[2] Qi Pi, Guorui Zhou, Yujing Zhang, Zhe Wang, Lejian Ren, Ying Fan, Xiaoqiang Zhu, and Kun Gai. Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction. In CIKM, pages 2685–2692, 2020.
[3] Xu Chen, Hanxiong Chen, Hongteng Xu, Yongfeng Zhang, Yixin Cao, Zheng Qin, and Hongyuan Zha. Personalized fashion recommendation with visual explanations based on multimodal attention network: Towards visually explainable recommendation. In SIGIR, pages 765–774, 2019.
[4] Jun Zhao, Zhou Zhou, Ziyu Guan, Wei Zhao, Wei Ning, Guang Qiu, and Xiaofei He. Intentgc: a scalable graph convolution framework fusing heterogeneous information for recommendation. In KDD, pages 2347–2357, 2019.
[5] Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al. Wide & deep learning for recommender systems. In Proceedings of the 1st workshop on deep learning for recommender systems, pages 7–10, 2016.
[6] Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. Deepfm: a factorization-machine based neural network for ctr prediction. arXiv preprint arXiv:1703.04247, 2017.
[7] Manas R Joglekar, Cong Li, Mei Chen, Taibai Xu, Xiaoming Wang, Jay K Adams, Pranav Khaitan, Jiahui Liu, and Quoc V Le. Neural input search for large scale recommendation models. In KDD, pages 2387–2397, 2020.
[8] Chunyuan Li, Heerad Farkhoor, Rosanne Liu, and Jason Yosinski. Measuring the intrinsic dimension of objective landscapes. arXiv preprint arXiv:1804.08838, 2018.
[9] Armen Aghajanyan, Luke Zettlemoyer, and Sonal Gupta. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. arXiv preprint arXiv:2012.13255, 2020.
[10] Xiaohan Ding, Yuchen Guo, Guiguang Ding, and Jungong Han. Acnet: Strengthening the kernel skeletons for powerful cnn via asymmetric convolution blocks. In ICCV, pages 1911–1920, 2019.
[11] Xiaohan Ding, Xiangyu Zhang, Jungong Han, and Guiguang Ding. Diverse branch block: Building a convolution as an inception-like unit. In ICCV, pages 10886–10895, 2021.
END

也许你还想看
丨EXTR:面向外部性的工业级广告点击率预估框架
丨基于对抗梯度的探索模型及其在点击预估中的应用
丨阿里妈妈搜索广告预估模型2021思考与实践
丨基于生成式回放的流式图神经网络模型

喜欢要“分享”,好看要“点赞”哦ღ~
↓欢迎留言参与讨论↓