分类任务之LeNet-5、AlexNet、VGG、ResNet、GoogLeNet
1、LeNet-5
手写体数字识别模型,是一个广为人知的商用的卷积神经网络, 当年美国大多数银行用它来识别支票上面的手写数字。
Lenet-5 原始结构如下图所示,包括:卷积层,降采样,卷积层,降采样,卷积层(实现全连接),全连接层,高斯连接层(进行分类)。

在后期发展中,降采样层被 m a x _ p o o l i n g max\_pooling max_pooling 所取代,分类也被 s o f t m a x softmax softmax 所替代,现在 T e n s o r f l o w Tensorflow Tensorflow 或者其他框架下的网络实现为:
总结:
(1)到现在LeNet-5的实际应用价值并不大,更多的时候是作为学习实例,了解其中卷积、采样、全连接、激活函数等CNN基础内容。
(2)降采样和池化的区别:原始的信号处理采用的就是采样,说白了就是采集样本,这种采样一旦方式确定那么接下来所有框选取的像素位置都是固定的,要么隔一个、要么隔两个;池化中平均池化是利用了框选位置的所有像素特征,最大池化虽然只用了最大像素值,但是这个像素值的位置是不确定的,所选取的特征也是具有代表性的。
(3)LeNet-5 对于小尺寸的图像还能够有一定的识别率,但是当输入图像尺寸很大时,为了满足网络对于输入的要求需要进行缩放(到224*224),就会丢失局部细微特征,LeNet-5 就比较难捕捉不同类别间的区别了。
2、AlexNet
AlexNet是2012年ImageNet图像分类竞赛(ILSVRC)的冠军,以 Top-5 错误率15.3%打败上一年的冠军,而且远远超过当年的第二名。它使用 R e L U ReLU ReLU 替了传统的激活函数,而且网络针对多GPU训练进行了优化设计,用于提升速度。不过随着硬件发展,现在我们训练AlexNet都可以直接用简化后的代码来实现了。
AlexNet 的输入数据尺寸为 224 ∗ 224 ∗ 3 224*224*3 224∗224∗3,这比之前的 LeNet-5( 32 ∗ 32 ∗ 1 32*32*1 32∗32∗1 的灰度图)大了许多,但是随着后人的优化发现227*227应该是最优的;其次它的参数量达到了 60 M 60M 60M,这比LeNet-5的 60 k 60k 60k 参数量也大得多。AlexNet 论文中特别提到几点:
- ReLU的使用,这使得训练时的错误率能够迅速下降到25%(比tanh快了将近7倍的时间);
- 双GPU,从上面的网络结构就可以看出,中间的部分是分开的、分别在两个相同的GPU上进行,因为当时的GPU性能限制了网络的大小,用两个GPU是受制于硬件的无奈之举但却收到意外的好效果;
- 局部响应归一化LRN,相当于是做了亮度归一化处理;
- 使用Overlapping Pooling,就是池化层的池化大小大于步长,使得相邻的池之间产生重叠。
对比来看,LeNet-5 总共5层,AlexNet总共8层,后者包括5个卷积层、3个全连接层,最终输出分类为1000。特别注意的是:2/4/5层卷积都只和同一GPU的上一层关联,但是第3层卷积是交叉的,全连接的时候也是如此;LRN接在1/2层卷积之后,最大池化层则接在LRN和第5个卷积之后。在防止过拟合时采用两种手段:数据增强(随机剪裁,利用PCA调整RGB值),dropout。
总结:
(1)文章最后说道:“减少网络中的任意一层都会降低模型的性能”,这其实也预示了深度神经网络的发展,越深的网络会拥有更好的表现。
(2)AlexNet的成功归结于几个方面:a. 百万级数据集,使用数据增强;b. 激活函数 ReLU 对抗梯度消失;c. Dropout 避免过拟合;d. LRN 的使用;e . 双GPU并行计算。
3、VGG
VGG是由牛津大学计算机视觉组和 Google DeepMind 公司研究员一起研发的深度卷积神经网络,它通过反复的堆叠 3*3 的小型卷积核和 2*2 的最大池化层,成功地构建了 16~19 层深的卷积神经网络,并一举获得了 ILSVRC 2014年比赛的亚军和定位项目的冠军,在top5上的错误率为7.5%,其中 VGG-16 的参数量为 138M。
VGG 是目前最流行的网络结构之一,因为结构简单、应用性极强而广受研究者欢迎,尤其是它的网络结构设计方法,为构建深度神经网络提供了方向。
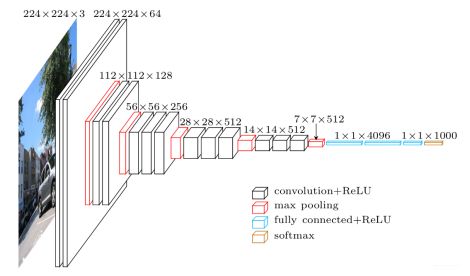
上图给出了VGG的整体结构,以 feature map 大小来对卷积进程进行阶段性划分,作者每次使用的都是 3*3 卷积、2*2 池化,区别在于每一阶段卷积的数量有所不同。VGG 包括多个不同的版本,每一个版本都是通过叠加卷积来实现网络加深,版本之间的区别如下图所示。
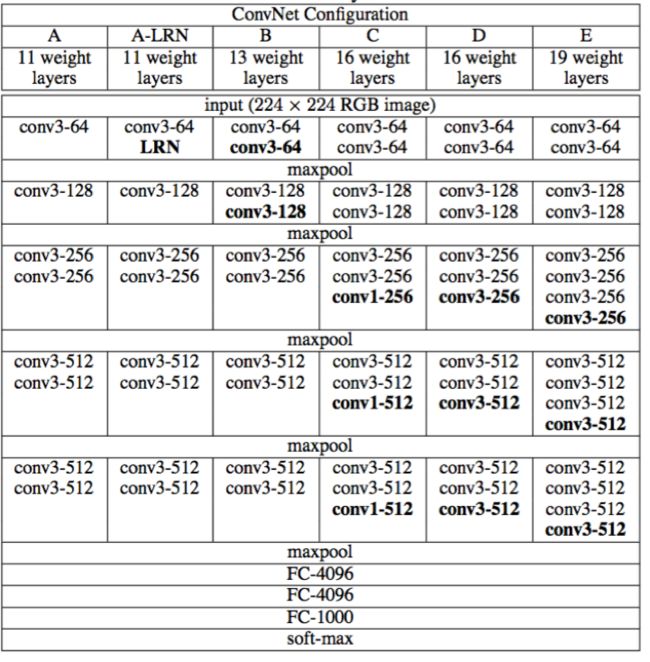
从上图可以看到,作者在部分位置还使用了 1*1 卷积,其作用在于增加线性变换。1*1 的卷积层常被用来提炼特征,即多通道的特征组合在一起,凝练成较大通道或者较小通道的输出,而每张图片的大小不变。有时 1*1 的卷积神经网络还可以用来替代全连接层。
创新点:
(1)多个小卷积连接代替一个大卷积:具体来说就是两个 3*3 卷积代替一个 5*5卷积,3个 3*3 卷积代替一个 7*7 卷积;它的优势在于既可以保证感受野的大小,又能够减小参数量(相当于之前的一半),同时多个卷积的出现相当于增加了非线性操作次数,网络学习特征的能力也就更强。
(2)全部使用3*3的卷积核和2*2的池化核,通过不断加深网络结构来提升性能;网络层数的增长并不会带来参数量上的爆炸,因为参数量主要集中在最后三个全连接层中。
4、ResNet
ResNet 由微软研究院的Kaiming He等四名华人提出,在ILSVRC 2015比赛中取得冠军,Top-5 上的错误率为3.57%,其参数量比 VGG 低,效果非常突出。ResNet的结构可以极快的加速神经网络的训练,模型的准确率也有比较大的提升,同时ResNet的推广性非常好,甚至可以直接用到InceptionNet 网络中。ResNet的主要思想是在网络中增加了直连通道,即Highway Network的思想。此前的网络结构是性能输入做一个非线性变换,而Highway Network则允许保留之前网络层的一定比例的输出。
网络层数越来越深,带来两个主要问题:
- 梯度消失/爆炸:梯度反向传播的累乘效应;
- 网络退化问题:对神经网络来说,恒等映射并不容易拟合。
ResNet 核心解决上述两个问题,解决方式就是残差块(具体分析可以参看 《深入探讨:残差网络解决了什么,为什么有效?》)。
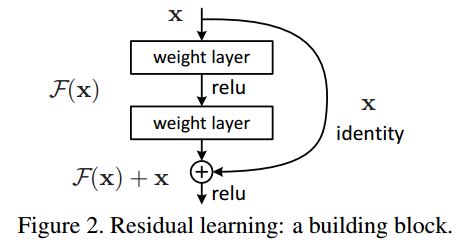
ResNet 的残差块结构如上图所示。按照传统的卷积做法,我们只需要做 F(x) 的前向和反向传播,但是一旦网络达到一定的深度,反向传播的梯度一层层积累会逐渐降低直至消失…为了避免梯度消失,作者在 F(x) 上加入一个 x,保证反向梯度 在 1 左右,残差指的就是上图的 F(x) 部分。
参考解释:
假设 F F F 就是上面所说的 F ( x ) F(x) F(x),是求和前网络映射; H H H 是从输入到求和后的网络映射,也就是上图中的 F ( x ) + x F(x)+x F(x)+x。现在把 5 映射到5.1,那么引入残差前是 F ′ ( 5 ) = 5.1 F'(5)=5.1 F′(5)=5.1,引入残差后是 H ( 5 ) = 5.1 H(5)=5.1 H(5)=5.1, 也就是 H ( 5 ) = F ( 5 ) + 5 H(5)=F(5)+5 H(5)=F(5)+5, F ( 5 ) = 0.1 F(5)=0.1 F(5)=0.1。这里的 F ′ F' F′ 和 F F F 都表示网络参数映射,引入残差后的映射对输出的变化更敏感。比如输出从5.1变到5.2,映射 F ′ F' F′ 的输出增加了 1 / 51 = 2 1/51=2% 1/51=2;而对于残差结构输出从5.1到5.2,映射 F F F 是从0.1到0.2,增加了100%。明显后者输出变化对权重的调整作用更大,效果更好。
残差的思想都是去掉相同的主体部分(也就是 x x x),从而突出微小的变化。
明白了ResNet的思想,再来看看如何设计具体的残差块,文章给出了两种形式,如下图所示。
这两种结构分别针对 ResNet34(左图)和 ResNet50/101/152(右图),左图结构称为“building block”,右图结构称为“bottleneck design”,目的就是为了减少参数量。“bottleneck design” 的第一个 1*1 卷积把256维channel降到64维,然后在最后通过 1*1 卷积恢复,整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632。如果要实现相同通道数的话,“building block” (它里面用了两个 3x3 的卷积)需要的参数量为: 3x3x256x256x2 = 1179648,差了16.94倍。 对于常规ResNet,可以用于34层或者更少的网络中,对于Bottleneck Design的ResNet通常用于更深的如101这样的网络中,目的是减少计算和参数量。
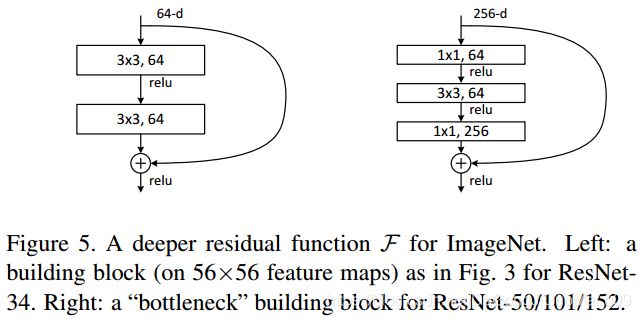
进行卷积操作后,如果通道数量相同可以采用 H(x)=F(x)+x 的方式直接计算,如果使用的卷积数量不同、feature map 的通道不一致,则需要使用额外的卷积操作 W 来调整通道数量:H(x)=F(x)+W*x(具体实现需要看代码)。

上图给出了不同层数的ResNet,简单算一下ResNet-101的层数:1+(3+4+23+3)*3+1=101。
5、GoogLeNet
GoogLeNet 是2014年ImageNet图像分类竞赛(ILSVRC)的冠军,它将 Top-5 的错误率降低到6.67%。它的主要特点是:不仅在纵向上具有深度,在横向上还具有宽度。由于图像信息在空间尺寸上的巨大差异,如何选择合适的卷积核大小来提取特征就显得比较困难了。空间分布范围更广的图像信息适合用较大的卷积核来提取其特征,而空间分布范围较小的图像信息则适合用较小的卷积核来提取其特征。为了解决图像尺寸的差异,GoogLeNet 提出一种解决方案:Inception。实际上 Inception 来源于2014年 ICLR 的文章《Network In Network》(NIN),通过不断的修改、优化,google的 Inception 一直从 v1 发展到 v4。
GoogLeNet这个名字也是挺有意思的,将 L 大写是为了向开山鼻祖的LeNet网络致敬。同时 Inception 一词来源于电影《盗梦空间》,后者的外文名就是“Inception”,意为希望可以搭建更深的网络。

5.1 Inception v1
下图是最原始的Inception,也就是常说的 GoogLeNet,它致力于增加网络深度和宽度,提高深度神经网络性能。

考虑到多个不同size的卷积核能够提高网络的适应能力,该结构使用了1*1、3*3、5*5的卷积核,同时加入maxpool。文章指出,这种结构的主要问题是:每一层 filters 参数量为所有分支上的总数和,多层 Inception 最终将导致模型的参数数量庞大,对计算资源有更大的依赖。我们知道1*1的卷积核拥有降维的作用,于是作者在维度较高的位置使用1*1卷积核,先进行降维然后再做卷积操作,这样既有效保证了模型特征的表达能力,又达到了减少3*3、5*5卷积核数量的目的,于是就有了上图右边的结构。4个分支最后通过一个聚合操作(tf.concat)实现合并,完整的 GoogLeNet 结构在传统的卷积层和池化层后面引入了 Inception 结构,对比 AlexNet 虽然网络层数增加,但是参数数量减少的原因是绝大部分的参数集中在全连接层。
可以看到,GoogLeNet总共包含9个Inception,同时还有两个分支,作为辅助损失函数参与最终 Loss 的计算,可以从一定程度上缓解梯度消失的问题。每一个Inception包含两个层,在第一个Inception之前还有3个卷积,输出层之前加一个全连接,9*2+3+1=22。虽然增加了层数,但是网络的参数数量却大大降低,只有 6.8M 左右,这与AlexNet的 60M 相比,在计算速度上就拥有巨大优势。
5.2 Inception v2
实际上在介绍 Inception v2之前应该先了解 VGG,因为前者是借鉴了后者的“用两个3*3卷积代替一个5*5卷积”的思路。这一思路在降低参数量的同时建立了更多的非线性变换,使得 CNN 对特征的学习能力变得更强。
该模型的另一个贡献就是提出了鼎鼎大名的 BatchNormalization,该方法可以有效防止 Internal covariate shift。简单来说就是:每一次参数更新都会导致每一层卷积的输出数据分布发生改变(偏离0/1正态分布中心),使得我们只能使用较小的学习速率(慢慢的试探、适应这种变化),这就导致梯度下降的速度变得很慢;BN就是在每一次卷积之后将分布拉回0/1正态分布中心,这使得我们可以使用较大的学习率,梯度下降的速度比原来快将近14倍。同时 BN 也具有正则化的效果,对防止过拟合也有一定作用,可以较少或者取消 Dropout 和 LRN 的使用,从而简化网络结构。
最终,Inception v2 取得了 Top-5 错误率 4.8% 的优异成绩,优于正常人眼水平。
5.3 Inception v3
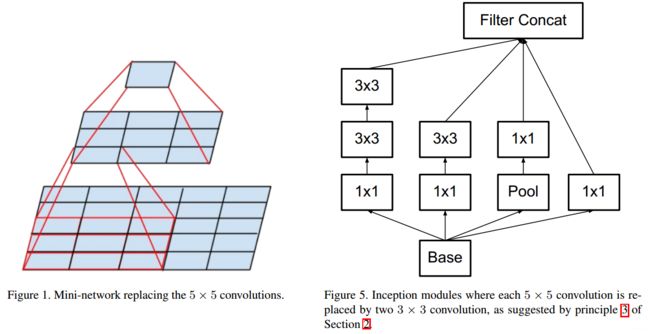
Inception v3 引入了 Factorization into small convolutions 的思想,也就是将一个较大的二维卷积拆成两个较小的一维卷积,比如将 7*7 卷积拆成 1*7 卷积和 7*1 卷积,或者将 3*3 卷积拆成 1*3 卷积和3´1卷积,如下图所示。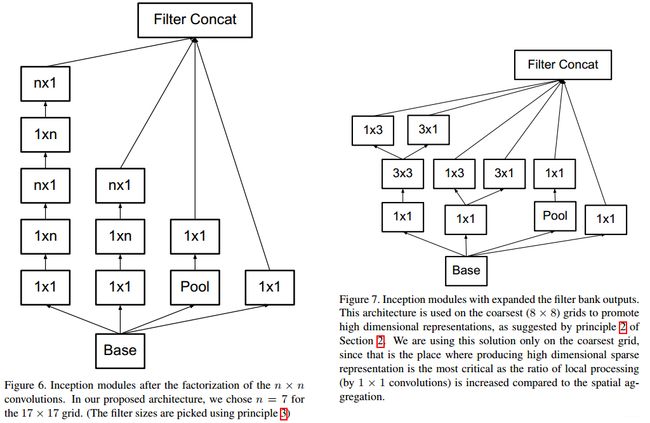
上图是两种不同的拆分方式,这种方式将节约大量的参数(Inception v3 的参数量为23.2M),加速运算并减轻过拟合(将7*7卷积拆成1*7卷积和7*1卷积,比拆成3个3*3卷积更节约参数),同时增加了非线性扩展模型的表达能力。论文中指出,这种非对称的卷积结构拆分,其结果比对称地拆为几个相同的小卷积核效果更明显,可以处理更多、更丰富的空间特征,增加特征多样性。
我们知道,在 Inception v1 中作者为了减少深度模型中反向传播时梯度消失的问题,而提出了在模型的中间与较底部增加了两个辅助 Loss 的方案,他们在Inception v2 中思考了这个辅助 Loss 的作用,觉得它真正意义在于对训练参数进行regularization,于是就在这些辅助 Loss 的FC层里添加了BN或者dropout层(如下图左边所示的那样),果然发现分类结果好了些。

在传统的卷积网络中,池化的作用在于剔除那些无关紧要的特征,为了不让重要的特征信息被过滤掉一般会在池化之前增加特征的数量(用1*1卷积),但是这种操作会使得计算量大大增加。Inception v3 于是提出如下做法:将本来应该串联进行的卷积、池化操作并行进行,即分别使用 pool 与 conv 直接减少 feature map size 的做法分别计算,之后再将两者算出的 feature maps 组合起来,如上图右边所示。
Inception v2 和 v3 实际上属于同一篇文章(2015年)的内容,但是一般将其看作两个不同的 Inception 进化版本。经过一系列的优化,Inception v3 最终取得 Top-5 错误率 3.5%。
5.4 Inception v4
Inception v4 同样来自于对 Inception 结构的完善优化,它发表于2016年的文章,整篇文章没有公式,只有满满的结构图、实验分析图。实际上在阅读这篇文章之前应该先看一下 ResNet,虽然 Inception v4 本身与残差块无关,但是文章结合 Inception 结构和残差块提出了另外两种模型。
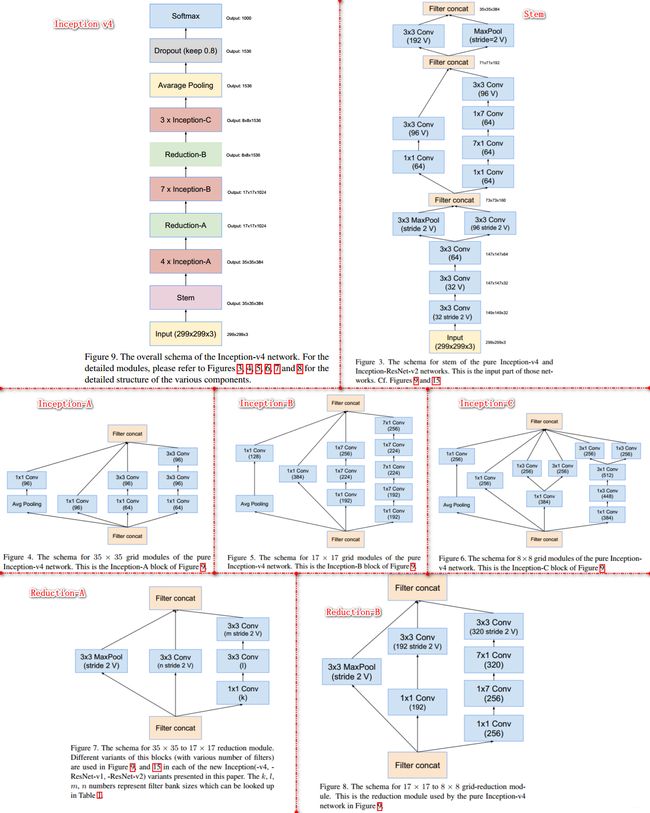
上图第一行最左边给出了 Inception v4 的整体网络结构,其他部分则是该结构的组成模块,分别是:Stem、Inception-A、Inception-B、Inception-C、Reduction-A、Reduction-B。Inception-A 主要用来处理 35*35 的 feature map,Inception-B 主要用来处理 17*17 的 feature map,Inception-C 则是处理 8*8 的feature map,整体来说 Inception v4 的Inception 继续沿袭 v2/v3 的结构,但是结构看起来更加简洁统一,并且使用更多的 Inception module,实验效果也更好。
之后文章结合 ResNet 提出了 Inception-ResNet-v1、Inception-ResNet-v2,前者的计算代价与 Inception v3 大致相同,后者的计算代价与 Inception v4 大致相同。不同模型的结构稍有变化,具体区别作者在文章中做出了详细介绍。对比几种模型作者最终得出结论:
(1)如果滤波器数量超过1000,残差网络开始出现不稳定,同时网络会在训练过程早期便会出现“死亡”,这意味着经过反复迭代后,在平均池化(average pooling) 之前的层开始只生成0。通过降低学习率,或增加额外的batch-normalizatioin都无法避免这种状况。
(2)将残差模块添加到activation激活层之前,对其进行放缩能够稳定训练;通常来说,将残差放缩因子定在0.1到0.3。