SMO(序列最小优化算法)解析
什么是SVM
SVM是Support Vector Machine(支持向量机)的英文缩写,是上世纪九十年代兴起的一种机器学习算法,在目前神经网络大行其道的情况下依然保持着生命力。有人说现在是神经网络深度学习的时代了,AI从业者可以不用了解像SVM这样的古董了。姑且不说SVM是否真的已经没有前途了,仅仅是SVM在数学上优美的推导就值得后来者好好欣赏一番,这也是笔者迄今为止见过机器学习领域最优美的数学推导。
和大多数二分类算法一样,SVM算法也是致力于在正例和反例之间找出一个超平面来将它们区分开来,如下图所示:
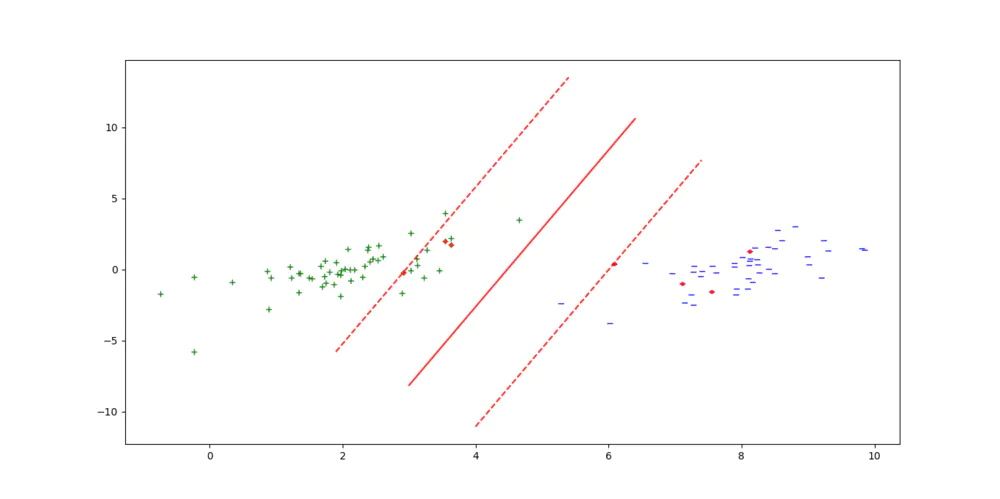
图1
如图所示,正例用“+”号表示,反例用“-”号表示。从图中可以看出,正例和反例是线性可分的。学习器的目的就是要学出一条如图所示的红色超平面将正例和反例区分开来。这也是其他非SVM分类器的共同目标,即:

而SVM与其它分类器所不同的是它引入了“支持向量”这一概念,反映到图中也就是红色的小点所代表的向量。(注:由于笔者作图时采用的SVM是软间隔的版本,因此支持向量不像是大多数教科书上采用硬间隔的SVM那样)由SVM的优化目标我们可以知道:样本空间中任意一个点x到该超平面的的距离可写为:

假设超平面可以完全正确地将所有样本分类,则对于任意一个样本(xi,yi)来说都有如下性质(注:样本的标签用+1代表正例,-1代表反例):
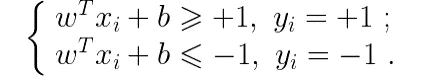
训练样本中使上式成立的样本称为支持向量,两个异类支持向量到超平面距离之和为:

上式被称为“间隔”。SVM的优化目标是为了找到这样一个划分超平面,该超平面能使间隔最大化,则SVM的优化目标可以表示为如下形式:
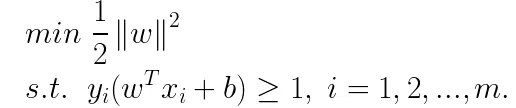
这就是SVM的基本数学表达,接下来就要对SVM问题进行求解。从上面的数学形式可以看出这是一个优化问题,可以使用拉格朗日乘子法求解其对偶问题。由于本文不是专门介绍SVM的,因此忽略掉具体的推导,直接给出SVM的对偶问题表达:

由于采用了拉格朗日乘子法,因此该对偶问题还有一个KKT条件约束,即要求:
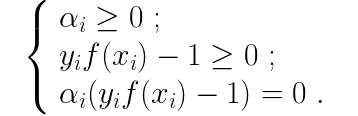
以上,就是SVM的一些相关介绍。需要特别说明的是,以上的推导都是建立在“硬间隔”的基础上,“硬间隔”要求样本集中每一个样本都满足约束条件。在现实中往往很难确定合适的核函数使得训练样本在特征空间中是线性可分的,缓解该问题的一个办法是允许支持向量机在一些样本上出错,为此引入“软间隔”的概念。具体来说,“硬间隔”要求所有参与训练的样本都必须满足SVM的约束条件,而“软间隔”允许有部分样本不满足这样的约束。由于本文不是专门论述SVM的,因此就不展开讲“软间隔”所带来的一些新的问题,只说一下“软间隔”条件下新的优化目标:
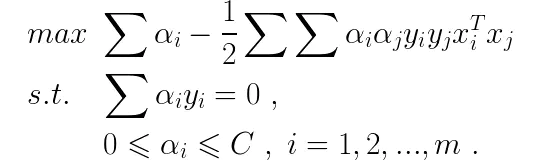
KKT条件为:

其中,C为容忍度因子,可以理解为SVM对“软间隔”的支持度。若C为无穷大,则所有的训练样本均必须满足SVM的约束条件,C值越小就允许越多的样本不满足约束条件。
SMO算法思想
通过观察SVM的优化目标我们可以发现其最终的目的是要计算出一组最优的alpha和常数项b的值。SMO算法的中心思想就是每次选出两个alpha进行优化(之所以是两个是因为alpha的约束条件决定了其与标签乘积的累加等于0,因此必须一次同时优化两个,否则就会破坏约束条件),然后固定其他的alpha值。重复此过程,直到达到某个终止条件程序退出并得到我们需要的优化结果。接下来,就具体推导一下SMO算法的细节。
算法数学推导
由于SVM中有核函数的概念,因此我们用Kij来表示在核函数K下向量i和向量j的计算值。现在假定我们已经选出alpha1和alpha2两个待优化项,然后将原优化目标函数展开为与alpha1和alpha2有关的部分和无关的部分:
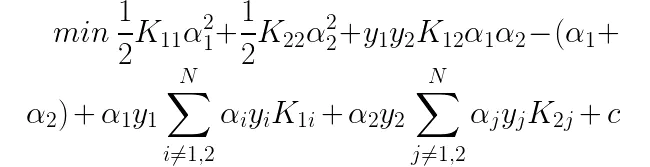
其中c是与alpha1和alpha2无关的部分,在本次优化中当做常数项处理。由SVM优化目标函数的约束条件:

可以得到:
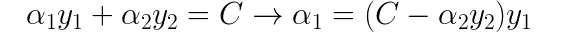
将优化目标中所有的alpha1都替换为用alpha2表示的形式,得到如下式子:
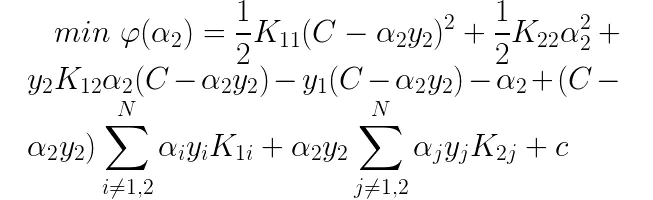
此时,优化目标中仅含有alpha2一个待优化变量了,我们现在将待优化函数对alpha2求偏导得到如下结果:
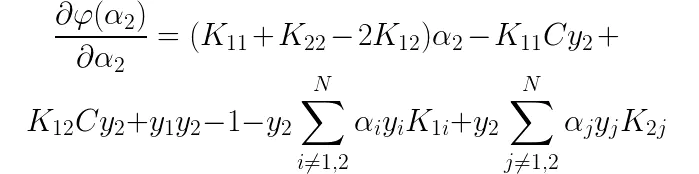
已知:

将以上三个条件带入偏导式子中,得到如下结果:
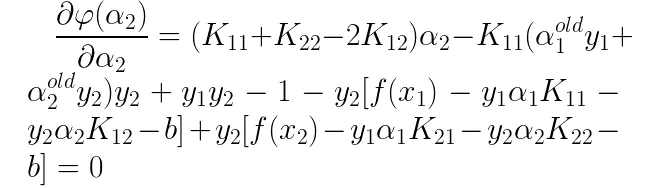
化简后得:

记:
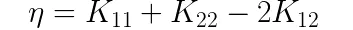
若n<=0则退出本次优化,若n>0则可得到alpha2的更新公式:
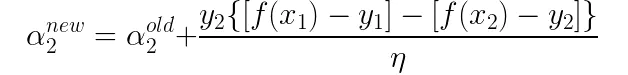
此时,我们已经得到了alpha2的更新公式。不过我们此时还需要考虑alpha2的取值范围问题。因为alpha2的取值范围应该是在0到C之间,但是在这里并不能简单地把取值范围限定在0至C之间,因为alpha2的取值不仅仅与其本身的范围有关,也与alpha1,y1和y2有关。设alpha1*y1+alpha2*y2=k,画出其约束,在这里要分两种情况,即y1是否等于y2。我们在这里先来考虑y1!=y2的情况:在这种情况下alpha1-alpha2=k:
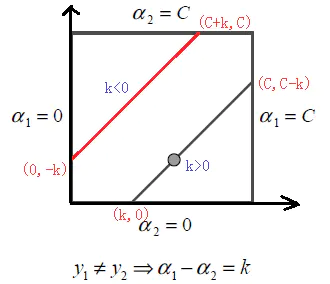
图2
可以看出此时alpha2的取值范围为:
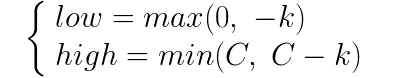
当y1=y2时,alpha1+alpha2=k:
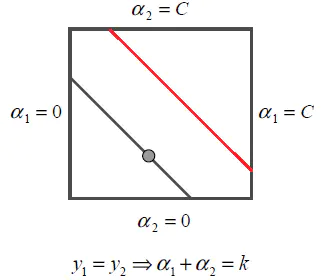
图3
可以看出此时alpha2的取值范围为:
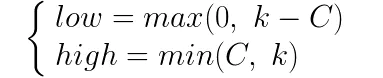
以上,可以总结出alpha2的取值上下界的规律:

故可得到alpha2的取值范围:

由alpha_old1y1+alpha_old2y2=alpha_new1y1+alpha_new2y2可得alpha1的更新公式:
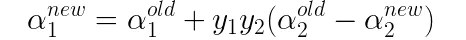
接下来,需要确定常数b的更新公式,在这里首先需要根据“软间隔”下SVM优化目标函数的KKT条件推导出新的KKT条件,得到结果如下:
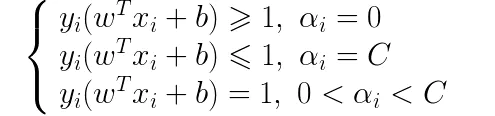
由于现在alpha的取值范围已经限定在0至C之间,也就是上面KKT条件的第三种情况。接下来我们将第三种KKT条件推广到任意核函数的情境下:

由此我们可以得到常数b的更新公式:
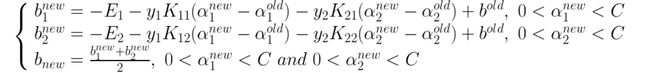
其中Ei是SVM的预测误差,计算式为:
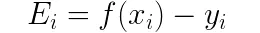
以上,笔者就已经把SMO算法的大部分细节推导出来了。接下来,我们可以根据这些推导对SMO算法进行实现,并且用我们的算法训练一个SVM分类器。