目标检测2.0新范式!DETR:Transformer目标检测的开山之作
1、本文速览
本文重新审视目标检测领域存在的问题,提出了一种基于Transformer的端到端目标检测网络,没有NMS非极大值抑制、没有anchor生成等多先验知识的约束,大大简化了目标检测pipeline。在COCO数据集上与FasterRcnn性能相当,且很容易地迁移到全景分割任务上。为后续目标检测提供了一种强大的baseline。

论文:https://arxiv.org/abs/2005.12872
代码:https://github.com/facebookresearch/detr
2、本文背景
传统目标检测的流程,以faster-rcnn举例:
训练数据集上聚类生成anchor -> backbone提取特征 -> 利用RPN网络搜寻所有的框并筛选regeion proposal -> 在regeion proposal上得到每个框的类别和置信度。
存在的问题:
• 训练数据集聚类预定义anchor,难以泛化到其他数据集上;
• 在每个像素点上都枚举预定义anchor;造成大量无效的候选框,增加算法复杂度;
• NMS过滤来自RPN产生的大量冗余框。
基于此,DETR提出一个简洁的pipeline,无需先验知识、手工操作,通过transformer编解码结构和二分图匹配优化,直接得到目标检测框和类别属性。
文章的两大核心思想为:
• 应用transformer编解码结构,保证了全局建模能力;
• 二分匹配(匈牙利算法),确保了一一对应。
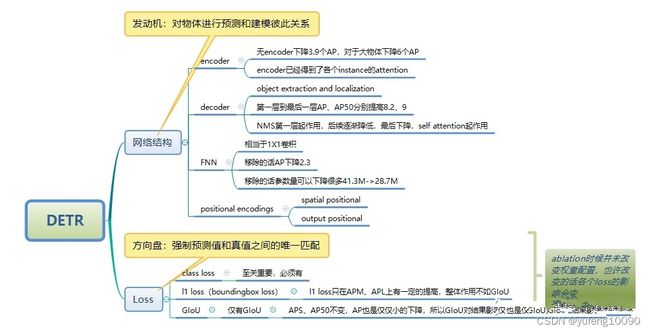
3、DETR框架
DETR包含四个模块,CNN提取特征的backbone、transformer encoder、transformer decoder和预测头FFN。

3.1 CNN backbone
Transformer模块与输入特征图的分辨率呈平方级关系,当输入分辨率过大时,会产生巨大的内存消耗,所以先用 CNN 进行特征提取并缩减尺寸,再输入 Transformer进行全局建模。Resnet Backbone 的输出通道为2048,特征图高和宽都变为原来的1/32。
3.2 transformer encoder
结构上,DETR在两个FFN层之后输出分类和BBox回归信息。Encoder和Decoder上,positional encoding在原本的transformer中是直接与input embeding相加,但是在DETR中,positional encoding 与image features 拼接到一起。DETR Decoder上,还添加自定义的object queeries查询模块。


Backbone输出的特征图维度为C × HW,其中C 表示2048个token,再经过一个1 × 1的卷积进行降维,然后输入到Transformer Encoder提取全局特征关系。transformer encoder由四个部分组成:Multi-Head Self-Attention多头注意力机制模块、object queries查询模块、Add&Norm模块、FFN前向传播模块。
(1)Multi-Head Self-Attention多头注意力机制模块
在NLP中,自注意力机制就是通过某种运算来直接计算得到句子在编码过程中每个位置上的注意力权重,然后再以权重和的形式来计算得到整个句子隐含的向量表示。模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置, 因此作者提出了通过多头注意力机制来解决这一问题。

backbone特征图进入Encoder模块后分成三份,一份直接作为V值向量,其余两份与位置编码向量直接相加,分别作为K(键向量),Q(查询向量)。
(2)object queries查询模块
Obeject Query可以理解为是对anchor的编码,Query的参数是可学习的。Obeject Query是query embeding,是一个torch.nn.Embedding的对象,该对象保存了固定的查找表look-up。这个模块用来保存词嵌入,且可以通过下标检索到它们。模块的输入是一个带有下标的列表,输出是对应的词嵌入。类实例化之后可以根据字典中元素的下标来查找元素对应的向量。query embeding是一个张量,维度为(num_queries,hidden_dim),num_queries是预设的最大bbox的个数,在DETR中设为100。
(3)FFN前向传播模块
FFN前向传播模块是由3层感知器、线性层、relu激活层组成的。其中预测框由标准化中心坐标、高度、宽度组成,线性层使用softmax预测标签类别。
3.3 transformer decoder
在 DETR中,作者输入100个Object Query,对应的Transformer decoder输出100个经过注意力解码后的token,经过FFN模块就能得到100个BBox框的位置和类别分数。
4、二值图分配和损失函数
4.1 二值图分配
DETR如何把预测出来的100个prediction框与ground truth做匹配,然后计算损失?如何知道prediction框与ground truth一一匹配?首先将ground-truth也扩充成100个检测框,同时使用了一个额外的特殊类标签Φ来表示在未检测到任何对象,认为是背景类别。这样预测和真实都是两个100个元素的集合了。然后采用匈牙利算法进行二分图匹配,对预测集合和真实集合的元素进行计算,使得匹配损失最小。


4.2损失函数
分类loss:CEloss交叉熵损失;
回归loss:预测框与GT的中心点和宽高的L1 loss以及GIoU loss。

5、实验
Fastrcnn与DETR性能的比较,Fastrcnn与DETR表现相当。DETR-DC5-R101在AP上略高于Faster RCNN-R101-FPN+ 0.8个点,在AP50上略高0.8个点。

可视化每个预测对象的解码器注意力(来自COCO val集的图像)。使用DETR-DC5模型进行预测。对于不同的对象,注意力分数用不同的颜色编码。解码器通常处理对象的四肢,例如腿和头,可以看出transformer注意力对局部特征的感知能力很强。

DETR-R101生成的全景分割的结果。分割的细节边缘也非常清晰准确。

在 COCO val 数据集上,与SOTA模型UPSNet和Panoptic FPN进行比较,使用与DETR相同的数据增强来重新训练PanopticFPN,以18 倍的时间表进行公平比较。 UPSNet 使用1x时间表,UPSNet-M 是具有多尺度测试时间增强的版本。

6、结论
DETR是一种基于transformer和二值图分类匹配损失的目标检测的新设计,可直接用于集合预测。在COCO 数据集上实现了与优化的Faster R-CNN baseline相当的结果。DETR易于实施且具有灵活可扩展的架构。此外,与Faster R-CNN 相比,self-attention对全局信息的处理,使得它在大目标上有更好的效果。这种新的检测器设计也带来了新的挑战,特别是关于小目标的训练、优化和性能。
7、计算流程

流程如下:
(1)图片预处理后维度(1,3,800,1066),输入resnet50:(1,2048,25,34)。11卷积降维提取提取特征,特征图的维度(256,25,34);
(2)row_embed与col_embed两个position embeding向量维度均为(50,128),backbone的输出的特征图尺寸不超过5050。11卷积的划分row_embed与col_embed;
(3)分别复制row_embed:(25,128) col_embed(34,128)到相应维度到(25,34,128),concat得到position_embed (25,34,256)。把position_embed(850,256)的850个位置编码向量展平。
(4)将11卷积的特征图原本CHW的编码改为HWC的编码。将词嵌入向量与position_embed相加,得到包含了位置信息的词嵌入向量。给定输出框个数为100个,即query_pos为100。
(5)将(4)中得到了词嵌入向量与训练好的object queries直接输入到transformer网络中。transformer的输出(100,1,256)。将transformer的输出分别输入到FFN,分别进行类别的回归和边界框。
微信公众号关注视觉算法学堂,分享CV技术干货!