预训练语言模型(五):Self-attention
目录
- Self-Attention
-
- 1. 比较相似度
- 2. 进行softmax操作
- 3. 对V(Values)进行加权求和
- 关于注意力矩阵怎么来的
- Multi-head Self-Attention
- Position Encoding
参考一个很全的总结:
预训练语言模型的前世今生 - 从Word Embedding到BERT
同时也参考了李宏毅老师 self-attention
这里是老师讲解的ppt: https://speech.ee.ntu.edu.tw/~hylee/ml/ml2021-course-data/self_v7.pdf
Self-Attention
首先对注意力机制而言,很重要的两个概念是Query和Values,注意力只有相对于特定的Query才有意义,这样才能够通过Query从Values中筛选出重要信息。
对于注意力模型来讲,可以分为三个阶段:
1. 比较相似度
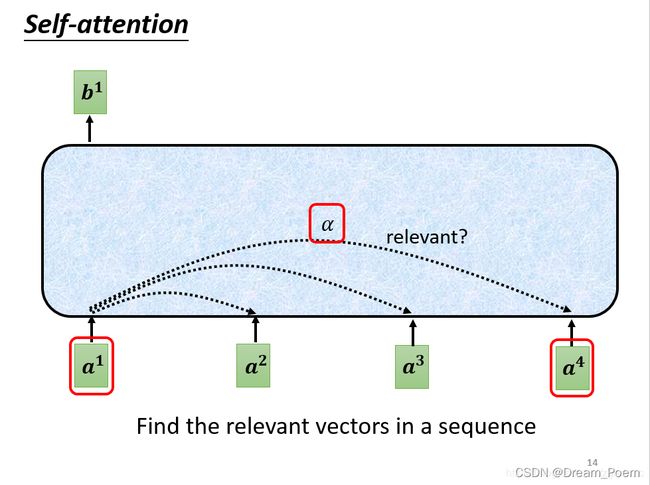
首先需要通过 α \alpha α 找到几个向量之间的相似度, 如下图所示,分别以 a 1 , a 2 , a 3 , a 4 a^1,a^2,a^3,a^4 a1,a2,a3,a4 作为query,根据其它的 a i a^i ai 关键词key求出相关度 α \alpha α:
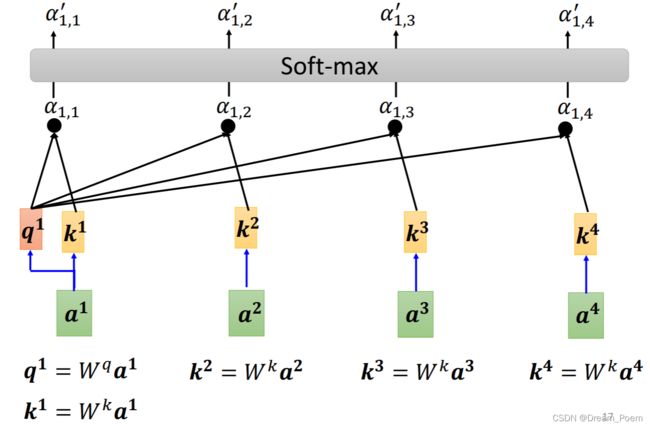
关于这个 α \alpha α 的计算,主要有以下几种方式:
- 使用点乘方法(最常用): f ( Q , K i ) = Q T K i f(Q,K_i)=Q^TK_i f(Q,Ki)=QTKi
- 权重: f ( Q , K i ) = Q T W K i f(Q,K_i)=Q_TWK_i f(Q,Ki)=QTWKi
- 级联后权重: f ( Q , K i ) = W [ Q T ; K i ] f(Q,K_i)=W[Q^T;K_i] f(Q,Ki)=W[QT;Ki]
- 感知器: f ( Q , K i ) = V T tanh ( W Q + U K i ) f(Q,K_i)=V^T\tanh (WQ+UK_i) f(Q,Ki)=VTtanh(WQ+UKi)
将其应用到self-attention中,求 α \alpha α 的过程如下图所示

在这里 q 1 q^1 q1 相当于查询内容, k 2 , k 3 , k 4 k^2,k^3,k^4 k2,k3,k4 相当于关键词,这里做点乘之后计算出的 α \alpha α 就是相似度。
2. 进行softmax操作
这里使用的公式是这样的:
α i ′ = s o f t m a x ( f ( Q , K i ) d k ) \alpha_i'=softmax(\frac{f(Q,K_i)}{\sqrt{d_k}}) αi′=softmax(dkf(Q,Ki))
这里除以 d k \sqrt{d_k} dk 的作用:假设 Q , K 里的元素的均值为0,方差为 1,那么 A T = Q T K A^T=Q^TK AT=QTK 中元素的均值为 0,方差为 d。当 d 变得很大时, A 中的元素的方差也会变得很大,如果 A 中的元素方差很大(分布的方差大,分布集中在绝对值大的区域),在数量级较大时, softmax 将几乎全部的概率分布都分配给了最大值对应的标签,由于某一维度的数量级较大,进而会导致 softmax 未来求梯度时会消失【梯度消失为啥呢我没明白】。总结一下就是 softmax(A) 的分布会和d有关。因此 A 中每一个元素乘上 1 d k \frac{1}{\sqrt{d_k}} dk1 后,方差又变为 1,并且 A 的数量级也将会变小。
小补充:这里在运算的时候,全部是使用的矩阵运算,即 Q = q 1 q 2 q 3 q 4 Q=q^1q^2q^3q^4 Q=q1q2q3q4,这样就可以实现矩阵的并行运算,使用GPU大大提高运算效率。
3. 对V(Values)进行加权求和
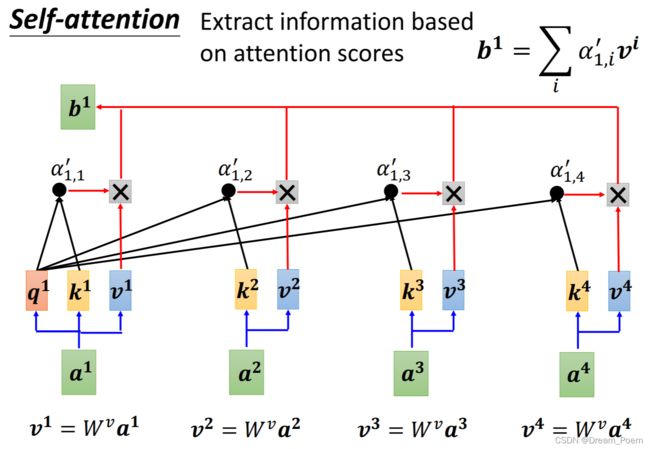
得到Attention向量: A t t e n t i o n = ∑ i = 1 m α i ′ V i Attention=\sum_{i=1}^m \alpha_i'V_i Attention=∑i=1mαi′Vi
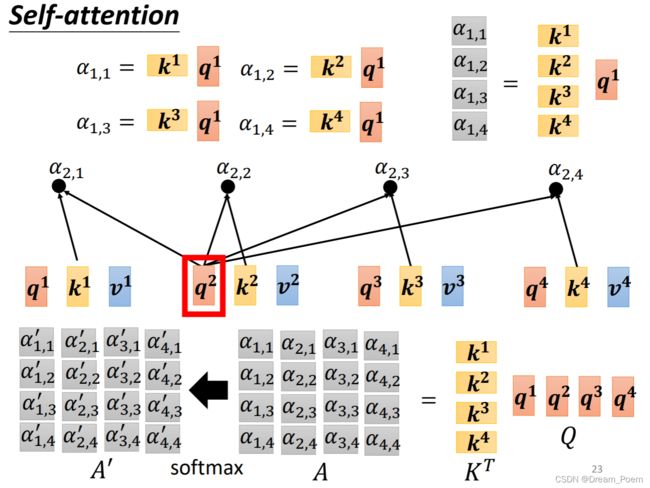
关于注意力矩阵怎么来的
(李宏毅老师讲解很细致,这里放两张很清晰的图好了)

Multi-head Self-Attention
多头注意力机制在transformer中应用很多,以双头注意力机制为例:
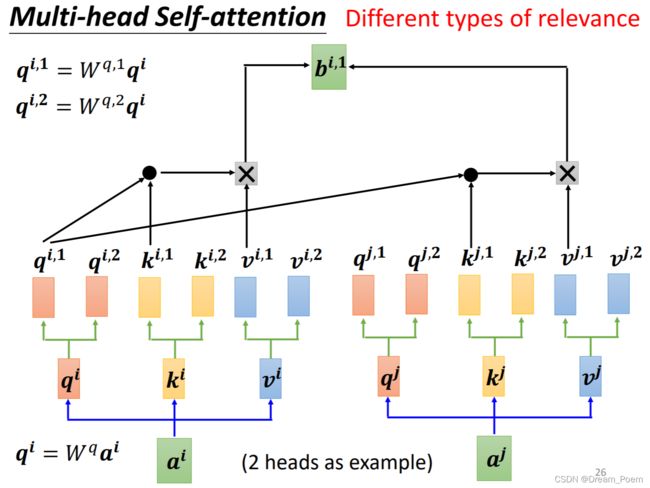
双头注意力机制即将每个 q i q^i qi 分为两个,分别为 q i , 1 q^{i,1} qi,1 和 q i , 2 q^{i,2} qi,2 ,再分别对所有上标为1的进行计算得到 b i , 1 b^{i,1} bi,1,对 所有上标为2的进行计算得到 b i , 2 b^{i,2} bi,2。
之后对两个矩阵级联再与权重矩阵相乘,得到 b i b^i bi

多头注意力机制的好处在于把原始信息放入了多个子空间中,保证attention可以注意到不同子空间的信息, 捕捉到更加丰富的特征信息。
Position Encoding
self-attention对于语言模型最大的缺陷在于 它没有编码位置信息,即便将输入的词汇序列改变,注意力机制仍然会在对应位置上赋予其相应的权重,所以self-attention是与位置没有关系的,此时就需要添加一些位置信息,添加方法也很简单,就是用简单的相加就可以:
X f i n a l _ e m b e d d i n g = E m b e d d i n g + P o s i t i o n a l E m b e d d i n g X_{final\_embedding}=Embedding+Positional Embedding Xfinal_embedding=Embedding+PositionalEmbedding
位置编码的公式如下:
P E p o s , 2 i = sin ( p o s / 1000 0 2 i / d m o d e l ) P E p o s , 2 i + 1 = cos ( p o s / 1000 0 2 i / d m o d e l ) PE_{pos,2i}=\sin (pos/10000^{2i/d_{model}})\\ PE_{pos,2i+1}=\cos (pos/10000^{2i/d_{model}}) PEpos,2i=sin(pos/100002i/dmodel)PEpos,2i+1=cos(pos/100002i/dmodel)
上面这组公式中, p o s pos pos 表示位置, i i i 表示维度, d m o d e l d_{model} dmodel 表示位置向量的向量维度, 2 i 2i 2i、 2 i + 1 2i+1 2i+1 表示的奇偶维度,偶数位置用 s i n sin sin,奇数位置用 c o s cos cos 函数。
由上面这个公式可以看到, P E PE PE 是一个绝对位置的编码,但事实上,它其中也蕴含了相对编码,下面进行说明:
首先我们知道三角函数的性质有:
sin ( α + β ) = sin α cos β + cos α sin β cos ( α + β ) = cos α cos β − sin α sin β \sin (\alpha+\beta)=\sin \alpha\cos\beta+\cos\alpha\sin\beta\\ \cos (\alpha+\beta)=\cos \alpha\cos\beta-\sin\alpha\sin\beta sin(α+β)=sinαcosβ+cosαsinβcos(α+β)=cosαcosβ−sinαsinβ
假设相对位置为 k k k ,那么位置编码的公式可以写成:
P E ( p o s + k , 2 i ) = P E ( p o s , 2 i ) × P E ( k , 2 i + 1 ) + P E ( p o s , 2 i + 1 ) × P E ( k . 2 i ) P E ( p o s + k , 2 i + 1 ) = P E ( p o s , 2 i + 1 ) × P E ( k , 2 i + 1 ) − P E ( p o s , 2 i ) × P E ( k . 2 i ) PE(pos+k,2i)=PE(pos,2i)\times PE(k,2i+1)+PE(pos,2i+1)\times PE(k.2i)\\ PE(pos+k,2i+1)=PE(pos,2i+1)\times PE(k,2i+1)-PE(pos,2i)\times PE(k.2i) PE(pos+k,2i)=PE(pos,2i)×PE(k,2i+1)+PE(pos,2i+1)×PE(k.2i)PE(pos+k,2i+1)=PE(pos,2i+1)×PE(k,2i+1)−PE(pos,2i)×PE(k.2i)
这样对于pos+k位置的位置向量某一维 2 i 2i 2i 或 2 i + 1 2i+1 2i+1 而言,可以表示为pos位置与k位置的位置向量的 2 i 2i 2i 与 2 i + 1 2i+1 2i+1 维的线性组合,这样的线性组合意味着位置向量中蕴含了相对位置信息。
某个单词的位置信息是其它单词位置信息的线性组合,这种线性组合就意味着位置向量中蕴含了相对位置信息。