机器学习笔记(第一周)——吴恩达ML课程
机器学习笔记(第一周)——吴恩达ML课程
文章目录
- 机器学习笔记(第一周)——吴恩达ML课程
- 前言
- 一、机器学习概念
-
- 1.什么是机器学习
- 2.什么是监督学习
- 2.什么是无监督学习
- 二、单变量线性回归(Linear Regression with One Variable)
-
- 1.模型表示(Model Representation)
- 2.代价函数(Cost Function)
- 3.梯度下降(Gradient Descent )
- 4.梯度下降的线性回归(Gradient Descent For Linear Regression)
- 总结
前言
已顺利考上研究生,从5月至开学之际,想充实自己的生活,从上大学以来一直对机器学习很感兴趣,现在正好有这么空下来的一段时间潜心学习,如有不对的地方欢迎大家批评指正!
一、机器学习概念
1.什么是机器学习
机器学习(Machine Learning):是研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。一个程序被认为能从经验E中学习,解决任务 T,达到性能度量值P,当且仅当,有了经验E后,经过P评判, 程序在处理T时的性能有所提升。
2.什么是监督学习
监督学习(Supervised Learning):对于数据集中每一个样本都有对应的标签,包括回归(Regression)和分类(Classification);
2.什么是无监督学习
无监督学习(Unsupervised Learning):数据集中没有任何的标签,包括聚类(Clustering),即无监督学习中没有任何的标签或者是有相同的标签或者就是没标签。
二、单变量线性回归(Linear Regression with One Variable)
1.模型表示(Model Representation)
h θ x = θ 0 + θ 1 x h_{\theta }x=\theta _{0}+\theta _{1}x hθx=θ0+θ1x
由于只含有一个特征/输入变量,因此这样的问题叫作单变量线性回归问题。举一个简单的例子:房价问题,如下图所示红色的点表示样本数据,即不同面积的房子所具有的价值,图中品红色的线就是我们所建立的模型,用于对房子的估价,不难发现,我们所建立的模型是一条直线,有两个未知参数 θ 0 , θ 1 \theta_{0},\theta_{1} θ0,θ1,当这两个参数确定时,模型也随之确定。
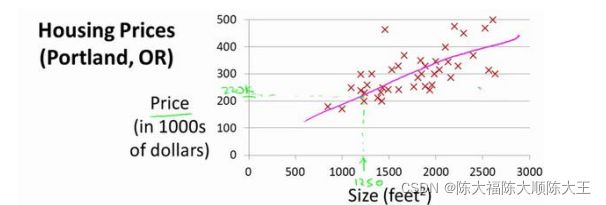
2.代价函数(Cost Function)
J ( θ 0 , θ 1 ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta _{0},\theta _{1})=\frac{1}{2m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})^{2} J(θ0,θ1)=2m1i=1∑m(hθ(x(i))−y(i))2
代价函数:通过当前模型得到的预测值和实际值之间的差,这个差是关于模型参数的函数,自然希望它越小越好。其中 m m m表示样本的数量,给定训练样本 ( x i , y i ) (x_{i},y_{i}) (xi,yi), i = 1 , 2 , 3 … , m i=1,2,3…,m i=1,2,3…,m, x x x表示特征, y y y表示输出目标,如房价问题所示, x x x表示房子的面积, y y y表示在该面积下,房子的价格。训练的目的在于得到建模误差的平方和能够最小的模型参数 : m i n i m i z e θ 0 , θ 1 = J ( θ 0 , θ 1 ) :\underset{\theta _{0},\theta _{1}}{minimize}=J(\theta _{0},\theta _{1}) :θ0,θ1minimize=J(θ0,θ1)
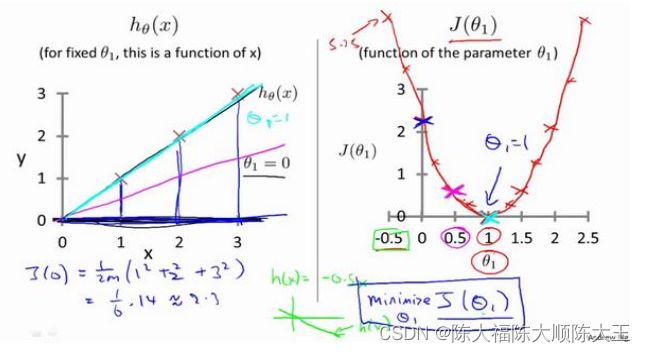
为了便于对代价函数的理解,不妨假设 θ 0 = 0 \theta_{0}=0 θ0=0,那假设模型此时转化为 h θ x = θ 1 x h_{\theta }x=\theta _{1}x hθx=θ1x,给与点对 ( x 0 , y 0 ) = ( 0 , 0 ) ; ( x 1 , y 1 ) = ( 1 , 1 ) , ( x 3 , y 3 ) = ( 3 , 3 ) (x_{0},y_{0})=(0,0);(x_{1},y_{1})=(1,1),(x_{3},y_{3})=(3,3) (x0,y0)=(0,0);(x1,y1)=(1,1),(x3,y3)=(3,3),如上图所示,不难看出,当 θ 1 = 1 \theta_{1}=1 θ1=1时,假设函数对给与的点对拟合最好此时代价函数 J ( θ 1 ) = 0 J(\theta _{1})=0 J(θ1)=0,当我们对 θ 1 \theta_{1} θ1取不同值时,代价函数的值也是不同的,如上右图所示,但我们必须要明确的一点是我们建立的假设模型最后的代价函数越小越好(排除过拟合的情况,这个之后再讲)。
3.梯度下降(Gradient Descent )
在直观感受梯度下降之前,先回顾一下之前的假设函数和代价函数:
假设(Hypothesis):
h θ x = θ 0 + θ 1 x h_{\theta }x=\theta _{0}+\theta _{1}x hθx=θ0+θ1x
参数(Parameter):
θ 0 , θ 1 \theta _{0},\theta _{1} θ0,θ1
代价函数(Cost Function):
J ( θ 0 , θ 1 ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta _{0},\theta _{1})=\frac{1}{2m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})^{2} J(θ0,θ1)=2m1i=1∑m(hθ(x(i))−y(i))2
目标(Goal):
m i n i m i z e θ 0 , θ 1 = J ( θ 0 , θ 1 ) \underset{\theta _{0},\theta _{1}}{minimize}=J(\theta _{0},\theta _{1}) θ0,θ1minimize=J(θ0,θ1)
通过上面两个小节,已经对假设函数,代价函数有了一定的理解,并且也知道了我们最终的目标是求参数 ( θ 0 , θ 1 ) (\theta _{0},\theta _{1}) (θ0,θ1)使得代价函数取得最小值,而梯度下降就是求最小值的办法。
 从宏观上去理解梯度下降这一概念,如上图所示假设我们此时站在山的顶峰往山脚走去,先旋转 360 度,看看我们的周围,并问自己要在某个方向上,用小碎步尽快下山。这些小碎步需要朝什么方向?如果我们站在山坡上的这一点,你看一下周围,你会发现最佳的下山方向,你再看看周围,然后再一次想想,我应该从什么方向迈着小碎步下山?然后你按照自己的判断又迈出一步,重复上面的步骤,从这个新的点,你环顾四周,并决定从什么方向将会最快下山,然后又迈进了一小步,并依此类推,直到你接近局部最低点的位置,但时由于我们出发的位置不同,我们最终会达到一个谷底,但可能每次所到达的位置并不相同,可能局部最小值(Local Minimum)也有可能是全局最小值(global minimum),我们可以得到批量梯度下降( Batch Gradient Descent)算法的公式:
从宏观上去理解梯度下降这一概念,如上图所示假设我们此时站在山的顶峰往山脚走去,先旋转 360 度,看看我们的周围,并问自己要在某个方向上,用小碎步尽快下山。这些小碎步需要朝什么方向?如果我们站在山坡上的这一点,你看一下周围,你会发现最佳的下山方向,你再看看周围,然后再一次想想,我应该从什么方向迈着小碎步下山?然后你按照自己的判断又迈出一步,重复上面的步骤,从这个新的点,你环顾四周,并决定从什么方向将会最快下山,然后又迈进了一小步,并依此类推,直到你接近局部最低点的位置,但时由于我们出发的位置不同,我们最终会达到一个谷底,但可能每次所到达的位置并不相同,可能局部最小值(Local Minimum)也有可能是全局最小值(global minimum),我们可以得到批量梯度下降( Batch Gradient Descent)算法的公式:
θ j : = θ j − α ∂ ∂ θ j J ( θ 0 , θ 1 ) ( 当 j = 0 和 j = 1 时 ) \theta _{j}:=\theta _{j}-\alpha \frac{\partial }{\partial \theta _{j}}J(\theta_{0},\theta_{1}) (当j=0和j=1时) θj:=θj−α∂θj∂J(θ0,θ1)(当j=0和j=1时)
需要注意的是 : = := :=为赋值符号。其中 α \alpha α为学习率,在下山的例子中,它就代表快速下山的方向向下迈出的步子有多大,在批量梯度下降中,我们每一次都同时让所有的参数减去学习速率乘以代价函数的导数。值得一提的是在梯度下降中,我们需要同时更新 θ 0 \theta _{0} θ0和 θ 1 \theta _{1} θ1的值,如下所示:
t e m p 0 : = θ 0 − α ∂ ∂ θ 0 J ( θ 0 , θ 1 ) temp0:=\theta _{0}-\alpha \frac{\partial }{\partial \theta _{0}}J(\theta_{0},\theta_{1}) temp0:=θ0−α∂θ0∂J(θ0,θ1) t e m p 1 : = θ 1 − α ∂ ∂ θ 1 J ( θ 0 , θ 1 ) temp1:=\theta _{1}-\alpha \frac{\partial }{\partial \theta _{1}}J(\theta_{0},\theta_{1}) temp1:=θ1−α∂θ1∂J(θ0,θ1) θ 0 : = t e m p 0 \theta _{0}:=temp0 θ0:=temp0 θ 1 : = t e m p 1 \theta _{1}:=temp1 θ1:=temp1
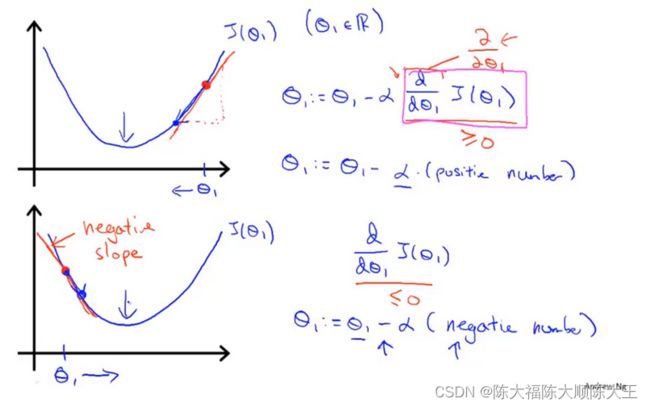
α \alpha α为学习率(Learning Rate),如果 α \alpha α太小,梯度下降会变得缓慢;如果 α \alpha α太大,梯度下降可能无法收敛甚至发散,如下图所示。
4.梯度下降的线性回归(Gradient Descent For Linear Regression)
有了上面的储备之后,得出的平方误差函数,结合梯度下降法,以及平方代价函数,将会迎来第一个机器学习算法,即线性回归算法,先回顾一下上述两个算法:梯度下降和线性回归。
 关键在于求梯度下降算法中的偏导数项,即:
关键在于求梯度下降算法中的偏导数项,即:
∂ ∂ θ j J ( θ 0 , θ 1 ) = ∂ ∂ θ j 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 \frac{\partial }{\partial \theta _{j}}J(\theta _{0},\theta _{1})=\frac{\partial }{\partial \theta _{j}}\frac{1}{2m}\sum_{i=1}^{m}(h_{\theta }(x^{(i)})-y^{(i)})^{2} ∂θj∂J(θ0,θ1)=∂θj∂2m1i=1∑m(hθ(x(i))−y(i))2 j = 0 时 : ∂ ∂ θ 0 J ( θ 0 , θ 1 ) = 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) j=0时:\frac{\partial }{\partial \theta _{0}}J(\theta _{0},\theta _{1})=\frac{1}{m}\sum_{i=1}^{m}(h_{\theta }(x^{(i)})-y^{(i)}) j=0时:∂θ0∂J(θ0,θ1)=m1i=1∑m(hθ(x(i))−y(i)) j = 1 时 : ∂ ∂ θ 0 J ( θ 0 , θ 1 ) = 1 m ∑ i = 1 m ( ( h θ ( x ( i ) ) − y ( i ) ) ⋅ x ( i ) ) j=1时:\frac{\partial }{\partial \theta _{0}}J(\theta _{0},\theta _{1})=\frac{1}{m}\sum_{i=1}^{m}((h_{\theta }(x^{(i)})-y^{(i)})\cdot x(i)) j=1时:∂θ0∂J(θ0,θ1)=m1i=1∑m((hθ(x(i))−y(i))⋅x(i))
则批量梯度下降算法改写成:
θ 0 : = θ 0 − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) \theta _{0}:=\theta _{0}-\alpha \frac{1}{m}\sum_{i=1}^{m}(h_{\theta }(x^{(i)})-y^{(i)}) θ0:=θ0−αm1i=1∑m(hθ(x(i))−y(i)) θ 1 : = θ 1 − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) ⋅ x ( i ) ) \theta _{1}:=\theta _{1}-\alpha \frac{1}{m}\sum_{i=1}^{m}(h_{\theta }(x^{(i)})-y^{(i)})\cdot x(i)) θ1:=θ1−αm1i=1∑m(hθ(x(i))−y(i))⋅x(i))
在梯度下降的每一步中,我们都用到了所有的训练样本,在梯度下降中,在计算微分求导项时,我们需要进行求和运算,所以,在每一个单独的梯度下降中,我们最终都要计算这样一个东西,这个项需要对所有 m m m个训练样本求和。因此,批量梯度下降法这个名字说明了我们需要考虑所有这一"批"训练样本,而事实上,有时也有其他类型的梯度下降法,不是这种"批量"型的,不考虑整个的训练集,而是每次只关注训练集中的一些小的子集在后面将介绍这些方法。
总结
这是机器学习第一周的内容,如上述内容有问题,欢迎大家批评指正,如果觉得文章对你有帮助的话,点个赞就当给我的鼓励咯!这个课程我已经学了一大半了,后续的内容也会不定期更新的。(PS:如果真的有人看的话哈哈哈)