电商离线数仓项目实战(下)
电商离线数仓项目实战(下)
电商分析——核心交易
文章目录
- 电商离线数仓项目实战(下)
-
- 电商分析——核心交易
-
- 一、业务需求
- 二、业务数据库表结构
-
-
- 1. 数据库表之间的联系
-
- img
-
-
- 2. 业务数据库——数据源
- 3. 数据库表结构设计
-
- 3.1 交易订单表
- 3.2 订单产品表
- 3.3 产品信息表
- 3.4 产品分类表
- 3.5 商家店铺表
- 3.6 地域组织表
- 3.7 支付方式表
-
- 三、数据导入
-
-
- 3.1 全量数据导入
-
- 3.1.1 产品分类表
- 3.1.2 商家店铺表
- 3.1.3 商家地域组织表
- 3.1.4 支付方式表
- 3.2 增量数据导入
-
- 3.2.1 订单表
- 3.2.2 订单明细表
- 3.2.3 产品信息表
-
- 四. ODS 层建表与数据加载
-
-
- 4.1 ODS 层建表
- 4.2 ODS 层数据加载
-
- 五、缓慢变化维度与周期性事实表
-
-
- 5.1 缓慢变化维
-
- 5.1.1 保留原值
- 5.1.2 直接覆盖
- 5.1.3 增加新属性列
- 5.1.4 快照表
- 5.1.1 拉链表
- 5.2 维度拉链表应用案例
-
- 5.2.1 创建表加载数据(准备工作)
- 5.2.2 拉链表的实现
- 5.2.3 拉链表的回滚
- 5.2.4 模拟脚本
- 5.3 周期性事实表
-
- 5.3.1 前提条件
- 5.3.2 周期性事实表拉链表的实现
- 5.4 拉链表小结
-
- 六. DIM 层建表加载数据
-
-
- 6.1 商品分类表
- 6.2 商品地域组织表
- 6.3 支付方式表
- 6.4 商品信息表
-
- 6.4.1 创建维表
- 6.4.2 初始数据加载(历史数据加载,只做一次)
- 6.4.2 增量数据导入(重复执行,每次加载数据执行)
-
- 七. DWD 层建表加载数据
-
-
- 7.1 DWD 层建表
- 7.2 DWD 层数据加载
-
- 八. DWS 层建表加载数据
-
-
- 8.1 DWS 层建表
- 8.2 DWS 层加载数据
-
- 九. ADS 层开发
-
-
-
- 9.1 ADS 层建表
- 9.2 ADS 层加载数据
-
-
- 十. 数据导出
- 十一. 小结
一、业务需求
选取指标:订单数、商品数、支付金额,并对这些指标按销售区域、商品类型进行分析。
二、业务数据库表结构
1. 数据库表之间的联系
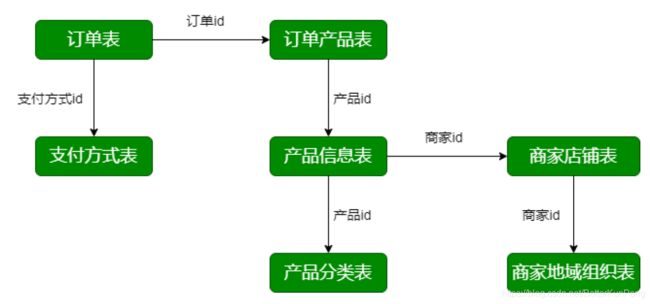
2. 业务数据库——数据源
- 交易订单表(trade_orders)
- 订单产品表(order_product)
- 产品信息表(product_info)
- 产品分类表(product_category)
- 商家店铺表(shops)
- 地域组织表(shop_admin_org)
- 支付方式表(payments)
3. 数据库表结构设计
3.1 交易订单表
DROP TABLE IF EXISTS lagou_trade_orders;
CREATE TABLE `lagou_trade_orders` (
`orderId` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '订单 id',
`orderNo` varchar(20) NOT NULL COMMENT '订单编号',
`userId` bigint(11) NOT NULL COMMENT '用户id',
`status` tinyint(4) NOT NULL DEFAULT '-2' COMMENT '订单状态 -3:用户拒收 -2:未付款的订单 -1:用户取消 0:待发货 1:配送中 2:用户确认收 货',
`productMoney` decimal(11, 2) NOT NULL COMMENT '商品金额',
`totalMoney` decimal(11, 2) NOT NULL COMMENT '订单金额(包括运 费)',
`payMethod` tinyint(4) NOT NULL DEFAULT '0' COMMENT '支付方 式,0:未知;1:支付宝,2:微信;3、现金;4、其他',
`isPay` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否支付 0:未 支付 1:已支付',
`areaId` int(11) NOT NULL COMMENT '区域最低一级',
`tradeSrc` tinyint(4) NOT NULL DEFAULT '0' COMMENT '订单来源 0:商城 1:微信 2:手机版 3:安卓App 4:苹果App',
`tradeType` int(11) DEFAULT '0' COMMENT '订单类型',
`isRefund` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否退款 0:否 1:是',
`dataFlag` tinyint(4) NOT NULL DEFAULT '1' COMMENT '订单有效标 志 -1:删除 1:有效',
`createTime` varchar(25) NOT NULL COMMENT '下单时间',
`payTime` varchar(25) DEFAULT NULL COMMENT '支付时间',
`modifiedTime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '订单更新时间',
PRIMARY KEY (`orderId`)
) ENGINE = InnoDB AUTO_INCREMENT = 355 CHARSET = utf8;
备注:
记录订单的信息
status:订单状态
createTime、payTime、modifiedTime。创建时间、支付时间、修改时间
3.2 订单产品表
DROP TABLE IF EXISTS lagou_order_produc;
CREATE TABLE `lagou_order_product` (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`orderId` bigint(11) NOT NULL COMMENT '订单id',
`productId` bigint(11) NOT NULL COMMENT '商品id',
`productNum` bigint(11) NOT NULL DEFAULT '0' COMMENT '商品数 量',
`productPrice` decimal(11, 2) NOT NULL DEFAULT '0.00' COMMENT '商品价格',
`money` decimal(11, 2) DEFAULT '0.00' COMMENT '付款金额',
`extra` text COMMENT '额外信息',
`createTime` varchar(25) DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`),
KEY `orderId` (`orderId`),
KEY `goodsId` (`productId`)
) ENGINE = InnoDB AUTO_INCREMENT = 1260 CHARSET = utf8;
备注:
记录订单中购买产品的信息,包括产品的数量、单价等
3.3 产品信息表
DROP TABLE IF EXISTS lagou_product_info;
CREATE TABLE `lagou_product_info` (
`productId` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '商品 id',
`productName` varchar(200) NOT NULL COMMENT '商品名称',
`shopId` bigint(11) NOT NULL COMMENT '门店ID',
`price` decimal(11, 2) NOT NULL DEFAULT '0.00' COMMENT '门店 价',
`isSale` tinyint(4) NOT NULL DEFAULT '1' COMMENT '是否上架 0:不上架 1:上架',
`status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否新品 0:否 1:是',
`categoryId` int(11) NOT NULL COMMENT 'goodsCatId 最后一级商品 分类ID',
`createTime` varchar(25) NOT NULL,
`modifyTime` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`productId`),
KEY `shopId` USING BTREE (`shopId`),
KEY `goodsStatus` (`isSale`)
) ENGINE = InnoDB AUTO_INCREMENT = 115909 CHARSET = utf8;
备注:
记录产品的详细信息,对应商家 ID、商品属性(是否新品,是否上架)
3.4 产品分类表
DROP TABLE IF EXISTS lagou_product_category;
CREATE TABLE `lagou_product_category` (
`catId` int(11) NOT NULL AUTO_INCREMENT COMMENT '品类ID',
`parentId` int(11) NOT NULL COMMENT '父ID',
`catName` varchar(20) NOT NULL COMMENT '分类名称',
`isShow` tinyint(4) NOT NULL DEFAULT '1' COMMENT '是否显示 0:隐藏 1:显示',
`sortNum` int(11) NOT NULL DEFAULT '0' COMMENT '排序号',
`isDel` tinyint(4) NOT NULL DEFAULT '1' COMMENT '删除标志 1:有 效 -1:删除',
`createTime` varchar(25) NOT NULL COMMENT '建立时间',
`level` tinyint(4) DEFAULT '0' COMMENT '分类级别,共3级',
PRIMARY KEY (`catId`),
KEY `parentId` (`parentId`, `isShow`, `isDel`)
) ENGINE = InnoDB AUTO_INCREMENT = 10442 CHARSET = utf8;
备注:
产品分类表,共分为三个级别
-- 第一级产品目录 select catName, catid from lagou_product_category where level =1; -- 查看电脑、办公的子类(查看二级目录) select catName, catid from lagou_product_category where level =2 and parentId = 32; -- 查看电脑整机的子类(查看三级目录) select catName, catid from lagou_product_category where level =3 and parentId = 10250;
3.5 商家店铺表
DROP TABLE IF EXISTS lagou_shops;
CREATE TABLE `lagou_shops` (
`shopId` int(11) NOT NULL AUTO_INCREMENT COMMENT '商铺ID,自 增',
`userId` int(11) NOT NULL COMMENT '商铺联系人ID',
`areaId` int(11) DEFAULT '0',
`shopName` varchar(100) DEFAULT '' COMMENT '商铺名称',
`shopLevel` tinyint(4) NOT NULL DEFAULT '1' COMMENT '店铺等 级',
`status` tinyint(4) NOT NULL DEFAULT '1' COMMENT '商铺状态',
`createTime` date DEFAULT NULL,
`modifyTime` datetime DEFAULT NULL COMMENT '修改时间',
PRIMARY KEY (`shopId`),
KEY `shopStatus` (`status`)
) ENGINE = InnoDB AUTO_INCREMENT = 105317 CHARSET = utf8;
备注:
记录店铺的详细信息
3.6 地域组织表
DROP TABLE IF EXISTS lagou_shops;
CREATE TABLE `lagou_shop_admin_org` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '组织ID',
`parentId` int(11) NOT NULL COMMENT '父ID',
`orgName` varchar(100) NOT NULL COMMENT '组织名称',
`orgLevel` tinyint(4) NOT NULL DEFAULT '1' COMMENT '组织级别 1;总部及大区级部门;2:总部下属的各个部门及基部门;3:具体工作部门',
`isDelete` tinyint(4) NOT NULL DEFAULT '0' COMMENT '删除标 志,1:删除;0:有效',
`createTime` varchar(25) DEFAULT NULL COMMENT '创建时间',
`updateTime` varchar(25) DEFAULT NULL COMMENT '最后修改时间',
`isShow` tinyint(4) NOT NULL DEFAULT '1' COMMENT '是否显示,0: 是 1:否',
`orgType` tinyint(4) NOT NULL DEFAULT '1' COMMENT '组织类 型,0:总裁办;1:研发;2:销售;3:运营;4:产品',
PRIMARY KEY (`id`),
KEY `parentId` (`parentId`)
) ENGINE = InnoDB AUTO_INCREMENT = 100332 CHARSET = utf8;
备注:
记录店铺所属区域
3.7 支付方式表
DROP TABLE IF EXISTS lagou_payments;
CREATE TABLE `lagou_payments` (
`id` int(11) NOT NULL,
`payMethod` varchar(20) DEFAULT NULL,
`payName` varchar(255) DEFAULT NULL,
`description` varchar(255) DEFAULT NULL,
`payOrder` int(11) DEFAULT '0',
`online` tinyint(4) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `payCode` (`payMethod`)
) ENGINE = InnoDB CHARSET = utf8;
备注:
记录支付方式
三、数据导入
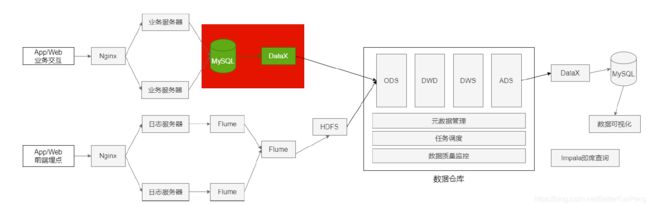
MYSQL 导出:
- 全量导出
- 增量导出(导出前一天的数据)
业务数据保存在MySQL中,每日凌晨导入上一天的表数据。
-
表数据量少,采用全量方式导出 MySQL
-
表数据量大,而且根据字段能区分出每天新增数据,采用增量方式导出MySQL。
-
三张增量表
- 订单表 lagou_trade_orders
- 订单产品表 lagou_order_product
- 产品信息表 lagou_product_info
-
四张全量表
- 产品分类表 lagou_product_category
- 商家店铺表 lagou_shops
- 商家地域组织表 lagou_shop_admin_org
- 支付方式表 lagou_payment
3.1 全量数据导入
MYSQL => HDFS => Hive
每日加载全量数据,形成新的分区;(对 ODS 如何建表有指导作用)
MySQLReader =====> HdfsReader
ebiz.lagou_product_category ===> ods.ods_trade_product_category
3.1.1 产品分类表
使用 DataX 导出时,需要进行 json 文件的编写。
/root/data/lagoudw/json/product_category.json
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "12345678",
"column": [
"catId",
"parentId",
"catName",
"isShow",
"sortNum",
"isDel",
"createTime",
"level"
],
"connection": [{
"table": [
"lagou_product_category"
],
"jdbcUrl": [
"jdbc:mysql://linux123:3306/ebiz"
]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://linux121:9000",
"fileType": "text",
"path": "/user/data/trade.db/product_category/dt=$do_date",
"fileName": "product_category_$do_date",
"column": [{
"name": "catId",
"type": "INT"
},
{
"name": "parentId",
"type": "INT"
},
{
"name": "catName",
"type": "STRING"
},
{
"name": "isShow",
"type": "TINYINT"
},
{
"name": "sortNum",
"type": "INT"
},
{
"name": "isDel",
"type": "TINYINT"
},
{
"name": "createTime",
"type": "STRING"
},
{
"name": "level",
"type": "TINYINT"
}
],
"writeMode": "append",
"fieldDelimiter": ","
}
}
}]
}
}
备注:
-
数据量小的表没有必要使用多个 channel;使用多个 channel 会生成多个小文件
-
执行命令之前要在 HDFS 上创建对应的目录:/user/data/trade.db/product_category/dt=yyyy-mm-dd
-
DATAX 安装在哪台服务器上,就在哪台服务器上执行
do_date='2020-07-01' # 创建目录 hdfs dfs -mkdir -p /user/data/trade.db/product_category/dt=$do_date # 数据迁移 python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/product_category.json # 加载数据 hive -e "alter table ods.ods_trade_product_category add partition(dt='$do_date')"
3.1.2 商家店铺表
lagou_shops =====> ods.ods_trade_shop
/root/data/lagoudw/json/shops.json
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "hive",
"password": "12345678",
"column": [
"shopId",
"userId",
"areaId",
"shopName",
"shopLevel",
"status",
"createTime",
"modifyTime"
],
"connection": [{
"table": [
"lagou_shops"
],
"jdbcUrl": [
"jdbc:mysql://linux123:3306/ebiz"
]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://linux121:9000",
"fileType": "text",
"path": "/user/data/trade.db/shops/dt=$do_date",
"fileName": "shops_$do_date",
"column": [{
"name": "shopId",
"type": "INT"
},
{
"name": "userId",
"type": "INT"
},
{
"name": "areaId",
"type": "INT"
},
{
"name": "shopName",
"type": "STRING"
},
{
"name": "shopLevel",
"type": "TINYINT"
},
{
"name": "status",
"type": "TINYINT"
},
{
"name": "createTime",
"type": "STRING"
},
{
"name": "modifyTime",
"type": "STRING"
}
],
"writeMode": "append",
"fieldDelimiter": ","
}
}
}]
}
}
do_date = '2020-07-01'
# 创建目录
hdfs dfs -mkdir -p /user/data/trade.db/shops/dt=$do_date
# 数据迁移
python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/shops.json
# 加载数据
hive -e "alter table ods.ods_trade_shops add partition(dt='$do_date')"
3.1.3 商家地域组织表
lagou_shop_admin_org =====> ods.ods_trade_shop_admin_org
/root/data/lagoudw/json/shop_org.json
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "12345678",
"column": [
"id",
"parentId",
"orgName",
"orgLevel",
"isDelete",
"createTime",
"updateTime",
"isShow",
"orgType"
],
"connection": [{
"table": [
"lagou_shop_admin_org"
],
"jdbcUrl": [
"jdbc:mysql://linux123:3306/ebiz"
]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://linux121:9000",
"fileType": "text",
"path": "/user/data/trade.db/shop_org/dt=$do_date",
"fileName": "shop_admin_org_$do_date.dat",
"column": [{
"name": "id",
"type": "INT"
},
{
"name": "parentId",
"type": "INT"
},
{
"name": "orgName",
"type": "STRING"
},
{
"name": "orgLevel",
"type": "TINYINT"
},
{
"name": "isDelete",
"type": "TINYINT"
},
{
"name": "createTime",
"type": "STRING"
},
{
"name": "updateTime",
"type": "STRING"
},
{
"name": "isShow",
"type": "TINYINT"
},
{
"name": "orgType",
"type": "TINYINT"
}
],
"writeMode": "append",
"fieldDelimiter": ","
}
}
}]
}
}
do_date='2020-07-01'
# 创建目录
hdfs dfs -mkdir -p /user/data/trade.db/shop_org/dt=$do_date
# 数据迁移
python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/shop_org.json
# 加载数据
hive -e "alter table ods.ods_trade_shop_admin_org add partition(dt='$do_date')"
3.1.4 支付方式表
lagou_payements ====> ods.ods_trade_payments
/root/data/lagoudw/json/payment.json
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "12345678",
"column": [
"id",
"payMethod",
"payName",
"description",
"payOrder",
"online"
],
"connection": [{
"table": [
"lagou_payments"
],
"jdbcUrl": [
"jdbc:mysql://linux123:3306/ebiz"
]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://linux121:9000",
"fileType": "text",
"path": "/user/data/trade.db/trade_payments/dt=$do_date",
"fileName": "payments_$do_date.dat",
"column": [{
"name": "id",
"type": "INT"
},
{
"name": "payMethod",
"type": "STRING"
},
{
"name": "payName",
"type": "STRING"
},
{
"name": "description",
"type": "STRING"
},
{
"name": "payOrder",
"type": "INT"
},
{
"name": "online",
"type": "TINYINT"
}
],
"writeMode": "append",
"fieldDelimiter": ","
}
}
}]
}
}
do_date='2020-07-01'
# 创建目录
hdfs dfs -mkdir -p /user/data/trade.db/trade_payments/dt=$do_date
# 数据迁移
python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/payment.json
# 加载数据
hive -e "alter table ods.ods_trade_payments add partition(dt='$do_date')"
3.2 增量数据导入
初始化数据装载(只执行一次);可以将前面的全量加载作为初次装载
每日加载增量数据(每日数据形成分区)
3.2.1 订单表
lagou_trade_orders =====> ods.ods_trade_orders
/root/data/lagoudw/json/orders.json
备注:条件的选择,选择时间段 modiriedTime
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "12345678",
"connection": [{
"querySql": [
"select orderId, orderNo, userId,status, productMoney, totalMoney, payMethod, isPay, areaId,tradeSrc, tradeType, isRefund, dataFlag, createTime, payTime,modifiedTime from lagou_trade_orders where date_format(modifiedTime, '%Y-%m-%d')='$do_date'"
],
"jdbcUrl": [
"jdbc:mysql://linux123:3306/ebiz"
]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://linux121:9000",
"fileType": "text",
"path": "/user/data/trade.db/orders/dt=$do_date",
"fileName": "orders_$do_date",
"column": [{
"name": "orderId",
"type": "INT"
},
{
"name": "orderNo",
"type": "STRING"
},
{
"name": "userId",
"type": "BIGINT"
},
{
"name": "status",
"type": "TINYINT"
},
{
"name": "productMoney",
"type": "Float"
},
{
"name": "totalMoney",
"type": "Float"
},
{
"name": "payMethod",
"type": "TINYINT"
},
{
"name": "isPay",
"type": "TINYINT"
},
{
"name": "areaId",
"type": "INT"
},
{
"name": "tradeSrc",
"type": "TINYINT"
},
{
"name": "tradeType",
"type": "INT"
},
{
"name": "isRefund",
"type": "TINYINT"
},
{
"name": "dataFlag",
"type": "TINYINT"
},
{
"name": "createTime",
"type": "STRING"
},
{
"name": "payTime",
"type": "STRING"
},
{
"name": "modifiedTime",
"type": "STRING"
}
],
"writeMode": "append",
"fieldDelimiter": ","
}
}
}]
}
}
-- MySQL 中的时间日期转换
select date_format(createTime, '%Y-%m-%d'), count(*)
from lagou_trade_orders
group by date_format(createTime, '%Y-%m-%d');
do_date='2020-07-12'
# 创建目录
hdfs dfs -mkdir -p /user/data/trade.db/orders/dt=$do_date
# 数据迁移
python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/orders.json
# 加载数据
hive -e "alter table ods.ods_trade_orders add partition(dt='$do_date')"
3.2.2 订单明细表
lagou_order_product ====> ods.ods_trade_order_product
/root/data/lagoudw/json/order_product.json
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "12345678",
"connection": [{
"querySql": [
"select id, orderId, productId,productNum, productPrice, money, extra, createTime from lagou_order_product where date_format(createTime, '%Y-%m-%d')= '$do_date' "
],
"jdbcUrl": [
"jdbc:mysql://linux123:3306/ebiz"
]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://linux121:9000",
"fileType": "text",
"path": "/user/data/trade.db/order_product/dt=$do_date",
"fileName": "order_product_$do_date.dat",
"column": [{
"name": "id",
"type": "INT"
},
{
"name": "orderId",
"type": "INT"
},
{
"name": "productId",
"type": "INT"
},
{
"name": "productNum",
"type": "INT"
},
{
"name": "productPrice",
"type": "Float"
},
{
"name": "money",
"type": "Float"
},
{
"name": "extra",
"type": "STRING"
},
{
"name": "createTime",
"type": "STRING"
}
],
"writeMode": "append",
"fieldDelimiter": ","
}
}
}]
}
}
do_date='2020-07-12'
# 创建目录
hdfs dfs -mkdir -p /user/data/trade.db/order_product/dt=$do_date
# 数据迁移
python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/order_product.json
# 加载数据
hive -e "alter table ods.ods_trade_order_product add partition(dt='$do_date')"
3.2.3 产品信息表
lagou_product_info =====> ods.ods_trade_product_info
/root/data/lagoudw/json/product_info.json
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "12345678",
"connection": [{
"querySql": [
"select productid, productname,shopid, price, issale, status, categoryid, createtime,modifytime from lagou_product_info where date_format(modifyTime, '%Y-%m-%d') = '$do_date' "
],
"jdbcUrl": [
"jdbc:mysql://linux123:3306/ebiz"
]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://linux121:9000",
"fileType": "text",
"path": "/user/data/trade.db/product_info/dt=$do_date",
"fileName": "product_info_$do_date.dat",
"column": [{
"name": "productid",
"type": "BIGINT"
},
{
"name": "productname",
"type": "STRING"
},
{
"name": "shopid",
"type": "STRING"
},
{
"name": "price",
"type": "FLOAT"
},
{
"name": "issale",
"type": "TINYINT"
},
{
"name": "status",
"type": "TINYINT"
},
{
"name": "categoryid",
"type": "STRING"
},
{
"name": "createTime",
"type": "STRING"
},
{
"name": "modifytime",
"type": "STRING"
}
],
"writeMode": "append",
"fieldDelimiter": ","
}
}
}]
}
}
do_date='2020-07-12'
# 创建目录
hdfs dfs -mkdir -p /user/data/trade.db/product_info/dt=$do_date
# 数据迁移
python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/product_info.json
# 加载数据
hive -e "alter table ods.ods_trade_product_info add partition(dt='$do_date')"
四. ODS 层建表与数据加载
ODS 层建表
- ODS 层建表结构与数据源基本类似(列名及数据类型)
- ODS 层的表名遵循统一的规范
4.1 ODS 层建表
所有的表都是分区表;字段之间的分隔符为 ‘,’;为表的数据文件指定了位置
DROP TABLE IF EXISTS `ods.ods_trade_orders`;
CREATE EXTERNAL TABLE `ods.ods_trade_orders`(
`orderid` int,
`orderno` string,
`userid` bigint,
`status` tinyint,
`productmoney` decimal(10, 0),
`totalmoney` decimal(10, 0),
`paymethod` tinyint,
`ispay` tinyint,
`areaid` int,
`tradesrc` tinyint,
`tradetype` int,
`isrefund` tinyint,
`dataflag` tinyint,
`createtime` string,
`paytime` string,
`modifiedtime` string)
COMMENT '订单表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by ','
location '/user/data/trade.db/orders/';
DROP TABLE IF EXISTS `ods.ods_trade_order_product`;
CREATE EXTERNAL TABLE `ods.ods_trade_order_product`(
`id` string,
`orderid` decimal(10,2),
`productid` string,
`productnum` string,
`productprice` string,
`money` string,
`extra` string,
`createtime` string)
COMMENT '订单明细表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by ','
location '/user/data/trade.db/order_product/';
DROP TABLE IF EXISTS `ods.ods_trade_product_info`;
CREATE EXTERNAL TABLE `ods.ods_trade_product_info`(
`productid` bigint,
`productname` string,
`shopid` string,
`price` decimal(10,0),
`issale` tinyint,
`status` tinyint,
`categoryid` string,
`createtime` string,
`modifytime` string)
COMMENT '产品信息表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by ','
location '/user/data/trade.db/product_info/';
DROP TABLE IF EXISTS `ods.ods_trade_product_category`;
CREATE EXTERNAL TABLE `ods.ods_trade_product_category`(
`catid` int,
`parentid` int,
`catname` string,
`isshow` tinyint,
`sortnum` int,
`isdel` tinyint,
`createtime` string,
`level` tinyint)
COMMENT '产品分类表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by ','
location '/user/data/trade.db/product_category';
DROP TABLE IF EXISTS `ods.ods_trade_shops`;
CREATE EXTERNAL TABLE `ods.ods_trade_shops`(
`shopid` int,
`userid` int,
`areaid` int,
`shopname` string,
`shoplevel` tinyint,
`status` tinyint,
`createtime` string,
`modifytime` string)
COMMENT '商家店铺表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by ','
location '/user/data/trade.db/shops';
DROP TABLE IF EXISTS `ods.ods_trade_shop_admin_org`;
CREATE EXTERNAL TABLE `ods.ods_trade_shop_admin_org`(
`id` int,
`parentid` int,
`orgname` string,
`orglevel` tinyint,
`isdelete` tinyint,
`createtime` string,
`updatetime` string,
`isshow` tinyint,
`orgType` tinyint)
COMMENT '商家地域组织表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by ','
location '/user/data/trade.db/shop_org/';
DROP TABLE IF EXISTS `ods.ods_trade_payments`;
CREATE EXTERNAL TABLE `ods.ods_trade_payments`(
`id` string,
`paymethod` string,
`payname` string,
`description` string,
`payorder` int,
`online` tinyint)
COMMENT '支付方式表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by ','
location '/user/data/trade.db/payments/';
4.2 ODS 层数据加载
DataX 仅仅是将数据导入到了 HDFS,数据并没有与 Hive 表建立关联。
脚本的任务:数据迁移、数据加载到 ODS 层;
对于增量加载数据而言:初始数据加载,该任务仅仅执行一次,不在脚本中。
/root/data/lagoudw/script/core_trade/ods_load_trade.sh
#!/bin/bash
source /etc/profile
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
# 创建目录
hdfs dfs -mkdir -p /user/data/trade.db/product_category/dt=$do_date
hdfs dfs -mkdir -p /user/data/trade.db/shops/dt=$do_date
hdfs dfs -mkdir -p /user/data/trade.db/shop_org/dt=$do_date
hdfs dfs -mkdir -p /user/data/trade.db/payments/dt=$do_date
hdfs dfs -mkdir -p /user/data/trade.db/orders/dt=$do_date
hdfs dfs -mkdir -p /user/data/trade.db/order_product/dt=$do_date
hdfs dfs -mkdir -p /user/data/trade.db/product_info/dt=$do_date
# 数据迁移
python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/product_category.json
python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/shops.json
python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/shop_org.json
python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/payments.json
python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/orders.json
python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/order_product.json
python $DATAX_HOME/bin/datax.py -p "-Ddo_date=$do_date" /root/data/lagoudw/json/product_info.json
# 加载 ODS 层数据
sql="
alter table ods.ods_trade_orders add partition(dt='$do_date');
alter table ods.ods_trade_order_product add partition(dt='$do_date');
alter table ods.ods_trade_product_info add partition(dt='$do_date');
alter table ods.ods_trade_product_category add partition(dt='$do_date');
alter table ods.ods_trade_shops add partition(dt='$do_date');
alter table ods.ods_trade_shop_admin_org add partition(dt='$do_date');
alter table ods.ods_trade_payments add partition(dt='$do_date');
"
hive -e "$sql"
特点:
工作量大,繁琐,容易出错;与数据采集工作在一起;
五、缓慢变化维度与周期性事实表
5.1 缓慢变化维
缓慢变化维(SCD:Slowly Changing Dimensions): 在现实世界中,维度的属性随着时间的流逝发生缓慢的变化(缓慢是相对事实表而言的,事实表数据变化的速度比维度表快)。
处理维度表的历史变化信息的问题称为处理缓慢变化维的问题,简称 SCD 问题。处理缓慢变化维的方式有以下几种:
- 保留原值(不常用)
- 直接覆盖(不常用)
- 增加新属性列(不常用)
- 快照表
- 拉链表
5.1.1 保留原值
维度属性值不做更改,保留原始值。
如商品上架售卖时间:一个商品上架售卖后由于其他原因下架,后来又再次上架,此种情况产生了多个商品上架售卖时间。如果业务重点关注的是商品首次上架售卖时间,则采用该种方式。
5.1.2 直接覆盖
修改维度属性为最新值,直接覆盖,不保留历史信息。
如商品属于哪个品类,当商品品类发生变化时,直接重写为新品类。
5.1.3 增加新属性列
在维度表中增加新的一列,原先属性列存放上一版本的属性值,当前属性列存放当前版本的属性值,还可以增加一列记录变化的时间。
缺点:只能记录最后一次变化的信息

5.1.4 快照表
每天保存一份全量数据。
简单、高效。缺点是信息重复,浪费磁盘空间
使用范围:维度不能太大
使用场景多,范围广;一般而言维度表都不大。
5.1.1 拉链表
拉链表适合于:表的数据量大,而且数据会发生新增和变化,但是大部分是不变的(数据发生变化的百分比不大),且是缓慢变化的(如电商中用户信息表中的某些用户基本属性不可能每天都变化)。主要目的是节省存储空间。
适用场景:
- 表的数据量大
- 表中部分字段会被更新
- 表中记录变化量的比例不高
- 需要保留历史信息
5.2 维度拉链表应用案例
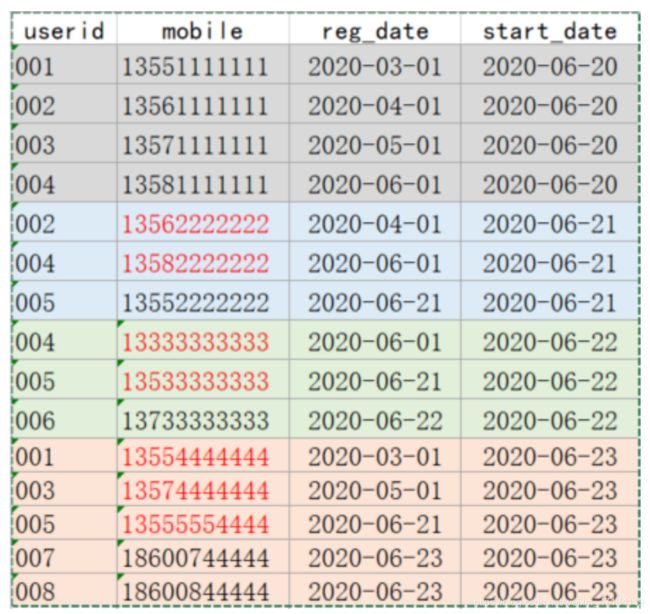
5.2.1 创建表加载数据(准备工作)
-- 用户信息
DROP TABLE IF EXISTS test.userinfo;
CREATE TABLE test.userinfo(
userid STRING COMMENT '用户编号',
mobile STRING COMMENT '手机号码',
regdate STRING COMMENT '注册日期')
COMMENT '用户信息'
PARTITIONED BY (dt string)
row format delimited fields terminated by ',';
-- 拉链表(存放用户历史信息)
-- 拉链表不是分区表;多了两个字段start_date、end_date
DROP TABLE IF EXISTS test.userhis;
CREATE TABLE test.userhis(
userid STRING COMMENT '用户编号',
mobile STRING COMMENT '手机号码',
regdate STRING COMMENT '注册日期',
start_date STRING,
end_date STRING)
COMMENT '用户信息拉链表'
row format delimited fields terminated by ',';
-- 数据(/root/data/lagoudw/data/userinfo.dat)
001,13551111111,2020-03-01,2020-06-20
002,13561111111,2020-04-01,2020-06-20
003,13571111111,2020-05-01,2020-06-20
004,13581111111,2020-06-01,2020-06-20
002,13562222222,2020-04-01,2020-06-21
004,13582222222,2020-06-01,2020-06-21
005,13552222222,2020-06-21,2020-06-21
004,13333333333,2020-06-01,2020-06-22
005,13533333333,2020-06-21,2020-06-22
006,13733333333,2020-06-22,2020-06-22
001,13554444444,2020-03-01,2020-06-23
003,13574444444,2020-05-01,2020-06-23
005,13555554444,2020-06-21,2020-06-23
007,18600744444,2020-06-23,2020-06-23
008,18600844444,2020-06-23,2020-06-23
-- 静态分区数据加载(略)
/root/data/lagoudw/data/userinfo0620.dat
001,13551111111,2020-03-01
002,13561111111,2020-04-01
003,13571111111,2020-05-01
004,13581111111,2020-06-01
load data local inpath '/root/data/lagoudw/data/userinfo0620.dat' into table test.userinfo partition(dt='2020-06-20');
动态分区数据加载
-- 动态分区数据加载:分区的值是不固定的,由输入数据确定
-- 创建中间表(非分区表)
drop table if exists test.tmp1;
create table test.tmp1 as
select * from test.userinfo;
-- tmp1 非分区表,使用系统默认的字段分割符'\001'
alter table test.tmp1 set serdeproperties('field.delim'=',');
-- 向中间表加载数据
load data local inpath '/root/data/lagoudw/data/userinfo.dat' into table test.tmp1;
-- 从中间表向分区表加载数据
-- 直接向 userinfo 表中插入数据时会出现如下错误
FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least one static partition column. To turn this off set hive.exec.dynamic.partition.mode=nonstrict
-- 解决办法为将分区模式变为非严格模式
set hive.exec.dynamic.partition.mode=nonstrict;
insert into table test.userinfo partition(dt) select * from test.tmp1;
与动态分区相关的参数
-
hive.exec.dynamic.partitionDefault Value: false prior to Hive 0.9.0; true in Hive 0.9.0 and laterAdded In: Hive 0.6.0Whether or not to allow dynamic partitions in DML/DDL表示是否开启动态分区功能
-
hive.exec.dynamic.partition.mode-
Default Value: strict -
Added In: Hive 0.6.0 -
In strict mode, the user must specify at least one static partition in case the user accidentally overwrites all partitions. In nonstrict mode all partitions are allowed to be dynamic. -
Set to nonstrict to support INSERT ... VALUES, UPDATE, and DELETE transactions (Hive 0.14.0 and later). -
strict最少需要一个是静态分区 -
nonstrict可以全部是动态分区
-
-
hive.exec.max.dynamic.partitions-
Default Value: 1000 -
Added In: Hive 0.6.0 -
Maximum number of dynamic partitions allowed to be created in total表示一个动态分区语句可以创建的最大动态分区个数,超出报错
-
-
hive.exec.max.dynamic.partitions.pernode-
Default Value: 100 -
Added In: Hive 0.6.0 -
Maximum number of dynamic partitions allowed to be created in each mapper/reducer node表示每个mapper / reducer可以允许创建的最大动态分区个数,默认是100,超出则会报错。
-
-
hive.exec.max.created.files-
Default Value: 100000 -
Added In: Hive 0.7.0 -
Maximum number of HDFS files created by all mappers/reducers in a MapReduce job.表示一个MR job可以创建的最大文件个数,超出报错。
-
5.2.2 拉链表的实现
userinfo(分区表)=> userid、mobile、regdate => 每日变更的数据(修改的+新增的) / 历史数据(第一天)
userhis(拉链表) => 多了两个字段 start_date / end_date
-- 步骤
-- 1. userinfo 初始化(2020-06-20) 获取历史数据
001,13551111111,2020-03-01,2020-06-20
002,13561111111,2020-04-01,2020-06-20
003,13571111111,2020-05-01,2020-06-20
004,13581111111,2020-06-01,2020-06-20
-- 2. 初始化拉链表(2020-06-20) userinfo => userhis
insert overwrite table test.userhis
select userid,mobile,regdate,dt as start_date,'9999-12-31' as end_date
from test.userinfo where dt='2020-06-20'
-- 3. 此时新增数据(2020-06-21) 获取新增数据
002,13562222222,2020-04-01,2020-06-21
004,13582222222,2020-06-01,2020-06-21
005,13552222222,2020-06-21,2020-06-21
-- 4. 构建拉链表(userhis)(2020-06-21)【核心】 userinfo(2020-06-21) + userhis => userhis
-- userinf 新增数据
-- userhis 历史数据
-- 第一步:处理新增数据【userinfo】(处理逻辑与加载历史数据类似)
select userid,mobile,regdate,dt as start_date,'9999-12-31' as end_date
from test.userinfo where dt='2020-06-21'
-- 第二步:处理历史数据【userhis】(历史数据包括两部分:变化的、未变化的)
-- 变化的:start_date 不变 end_date 传入日期 -1
-- 未变化的:不做处理
-- 观察数据
select A.userid, B.userid, B.mobile, B.regdate, B.start_Date,
B.end_date from
(select * from test.userinfo where dt='2020-06-21') A
right join test.userhis B
on A.userid=B.userid;
-- =========================================================================================
a.userid b.userid b.mobile b.regdate b.start_date b.end_date
NULL 001 13551111111 2020-03-01 2020-06-20 9999-12-31
002 002 13561111111 2020-04-01 2020-06-20 9999-12-31
NULL 003 13571111111 2020-05-01 2020-06-20 9999-12-31
004 004 13581111111 2020-06-01 2020-06-20 9999-12-31
-- =========================================================================================
-- 编写 SQL,处理历史数据
select B.userid, B.mobile, B.regdate, B.start_Date,
CASE WHEN B.end_date ='9999-12-31' AND A.userid is not null
then date_add('2020-06-21',-1) else B.end_date end as end_date
from (select * from test.userinfo where dt='2020-06-21') A
right join test.userhis B
on A.userid=B.userid;
-- =========================================================================
b.userid b.mobile b.regdate b.start_date end_date
001 13551111111 2020-03-01 2020-06-20 9999-12-31
002 13561111111 2020-04-01 2020-06-20 2020-06-20
003 13571111111 2020-05-01 2020-06-20 9999-12-31
004 13581111111 2020-06-01 2020-06-20 2020-06-20
-- =========================================================================
-- 第三步:最终的处理(新增+历史数据)
insert overwrite table test.userhis
select userid,mobile,regdate,dt as start_date,'9999-12-31' as end_date
from test.userinfo where dt='2020-06-21'
union all
select B.userid, B.mobile, B.regdate, B.start_Date,
CASE WHEN B.end_date ='9999-12-31' AND A.userid is not null
then date_add('2020-06-21',-1) else B.end_date end as end_date
from (select * from test.userinfo where dt='2020-06-21') A
right join test.userhis B
on A.userid=B.userid;
-- 5. 第三日新增数据(2020-06-22): 获取新增数据
004,13333333333,2020-06-01,2020-06-22
005,13533333333,2020-06-21,2020-06-22
006,13733333333,2020-06-22,2020-06-22
-- 6、构建拉链表(2020-06-22) userinfo(2020-06-22) + userhis =>
userhis
-- 7、第四日新增数据(2020-06-23)
001,13554444444,2020-03-01,2020-06-23
003,13574444444,2020-05-01,2020-06-23
005,13555554444,2020-06-21,2020-06-23
007,18600744444,2020-06-23,2020-06-23
008,18600844444,2020-06-23,2020-06-23
-- 8、构建拉链表(2020-06-23)
处理拉链表的脚本(测试脚本):(/root/data/lagoudw/data/userzipper.sh)
#!/bin/bash
source /etc/profile
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="insert overwrite table test.userhis
select userid, mobile, regdate, dt as start_date, '9999-12-
31' as end_date
from test.userinfo
where dt='$do_date'
union all
select B.userid,
B.mobile,
B.regdate,
B.start_Date,
case when B.end_date='9999-12-31' and A.userid is not
null
then date_add('$do_date', -1)
else B.end_date
end as end_date
from (select * from test.userinfo where dt='$do_date') A
right join test.userhis B
on A.userid=B.userid;
"
hive -e "$sql"
拉链表的使用
-- 查看拉链表中最新数据(2020-06-23以后的数据)
select * from userhis where end_date='9999-12-31';
-- 查看拉链表中给定日期数据("2020-06-22")
select * from userhis where start_date <= '2020-06-22' and end_date >= '2020-06-22';
-- 查看拉链表中给定日期数据("2020-06-21")
select * from userhis where start_date <= '2020-06-21' and end_date >= '2020-06-21';
-- 查看拉链表中给定日期数据("2020-06-20")
select * from userhis where start_date <= '2020-06-20' and end_date >= '2020-06-20';
5.2.3 拉链表的回滚
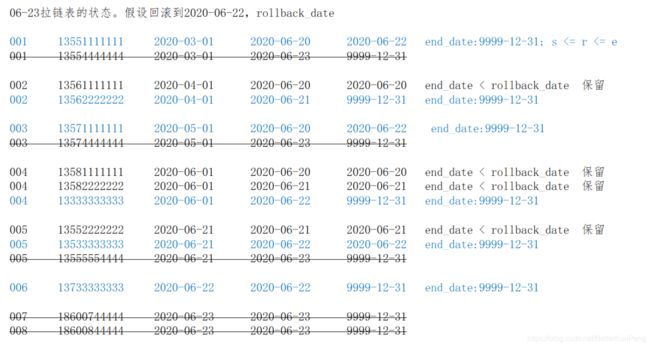
由于种种原因需要将拉链表恢复到 rollback_date 那一天的数据。此时有:
end_date < rollback_date,即结束日期 < 回滚日期。表示该行数据在 rollback_date 之前产生,这些数据需要原样保留。
start_date <= rollback_date <= end_date,即开始日期 <= 回滚日期 <= 结束日期。这些数据时回滚日期之后产生的,但是需要修改。将 end_)date 改为 9999-12-31
其他数据不用管

按以上方案进行编码:
- 处理 end_date < rollback_date 的数据,保留
select userid, mobile, regdate, start_date, end_date, '1' as tag
from test.userhis
where end_date < '2020-06-22';
- 处理 start_date <= rollback_date <= end_date 的数据,设置 end_date = 9999-12-31
select userid, mobile, regdate, start_date, '9999-12-31' as end_date, '2' as tag
from test.userhis
where start_date <= '2020-06-22' and end_date >= '2020-06-22';
- 将前面两步的数据写入临时表 tmp (拉链表)
drop table test.tmp;
create table test.tmp as
select userid, mobile, regdate, start_date, end_date, '1' as tag
from test.userhis
where end_date < '2020-06-22'
union all
select userid, mobile, regdate, start_date, '9999-12-31' as end_date, '2' as tag
from test.userhis
where start_date <= '2020-06-22' and end_date >= '2020-06-22';
-- 查询结果
select * from test.tmp cluster by userid, start_date;
5.2.4 模拟脚本
/root/data/lagoudw/data/zippertmp.sh
#!/bin/bash
source /etc/profile
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
drop table test.tmp;
create table test.tmp as
select userid, mobile, regdate, start_date, end_date, '1' as tag
from test.userhis
where end_date < '$do_date'
union all
select userid, mobile, regdate, start_date, '9999-12-31' as end_date, '2' as tag
from test.userhis
where start_date <= '$do_date' and end_date >= '$do_date';
"
hive -e "$sql"
逐天回滚,检查数据
方案二:保存一段时间的增量数据(userinfo),定期对拉链表做备份(如一个月做一次备份);如需回滚,直接在北分的拉链表上重跑增量数据。处理简单
5.3 周期性事实表
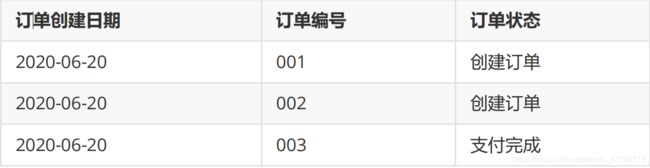
有如下订单表,6月20日有3条记录(001/002/003):
6月21日有5条记录,其中新增2条记录(004/005),修改1条记录(001)

6月22日,表中有6条记录,其中新增1条记录(006),修改2条记录(003/005):

订单事实表的处理方法:
- 只保留一份全量。数据和6月22日的记录一样,如果需要查看6月21的订单001的状态,则无法满足;
- 每天保留一份全量。在数据仓库中可以在找到所有的历史信息,但数据量大了,而且很多信息都是重复的,会造成较大的存储浪费;
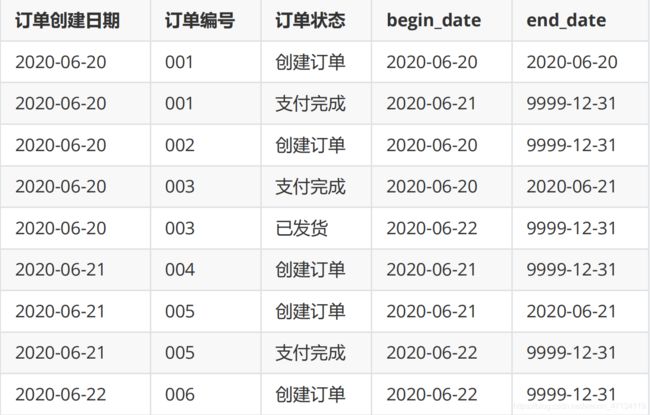
使用拉链表保存历史信息,会有下面这张表。历史拉链表,既能满足保存历史数据的需求,也能节省存储资源。
5.3.1 前提条件
- 订单表的刷新频率为一天,当填获取前一天的增量数据;
- 如果一个订单在一天内有多次状态变化,只记录最后一个状态的信息;
- 订单状态包括三个:创建、支付、完成;
- 创建时间和修改时间只取到天,如果源订单表中没有状态修改时间,那么抽取增量就比较麻烦,需要有个机制来确保能抽取到每天的增量数据;
数仓 ODS 层有订单表,数据按日分区,存放每天的增量数据:
DROP TABLE test.ods_orders;
CREATE TABLE test.ods_orders(
orderid INT,
createtime STRING,
modifiedtime STRING,
status STRING
) PARTITIONED BY (dt STRING)
row format delimited fields terminated by ',';
数仓 DWD 层有订单拉链表,存放订单的历史状态数据:
DROP TABLE test.dwd_orders;
CREATE TABLE test.dwd_orders(
orderid INT,
createtime STRING,
modifiedtime STRING,
status STRING,
start_date STRING,
end_date STRING
)
row format delimited fields terminated by ',';
5.3.2 周期性事实表拉链表的实现
- 全量初始化
-- 数据文件order1.dat
-- /root/data/lagoudw/data/order1.dat
001,2020-06-20,2020-06-20,创建
002,2020-06-20,2020-06-20,创建
003,2020-06-20,2020-06-20,支付
load data local inpath '/root/data/lagoudw/data/order1.dat' into table test.ods_orders partition(dt='2020-06-20');
INSERT overwrite TABLE test.dwd_orders
SELECT orderid, createtime, modifiedtime, status,
createtime AS start_date,
'9999-12-31' AS end_date
FROM test.ods_orders
WHERE dt='2020-06-20';
增量抽取
-- 数据文件order2.dat
001,2020-06-20,2020-06-21,支付
004,2020-06-21,2020-06-21,创建
005,2020-06-21,2020-06-21,创建
load data local inpath '/root/data/lagoudw/data/order2.dat' into table test.ods_orders partition(dt='2020-06-21');
增量刷新历史数据
-- 拉链表中的数据分两部实现:新增数据(ods_orders)、历史数据(dwd_orders)
-- 处理新增数据
SELECT orderid,
createtime,
modifiedtime,
status,
modifiedtime AS start_date,
'9999-12-31' AS end_date
FROM test.ods_orders
where dt='2020-06-21';
-- 处理历史数据。历史数据包括:有修改、无修改的数据
-- ods_orders 与 dwd_orders 进行表连接
-- 连接上,说明数据被修改
-- 未连接上,说明数据未被修改
select A.orderid,
A.createtime,
A.modifiedtime,
A.status,
A.start_date,
case when B.orderid is not null and A.end_date>'2020-06-21'
then '2020-06-20'
else A.end_date
end end_date
from test.dwd_orders A
left join (select * from test.ods_orders where dt='2020-06-21') B
on A.orderid=B.orderid;
-- 用以上信息覆写拉链表
insert overwrite table test.dwd_orders
SELECT orderid,
createtime,
modifiedtime,
status,
modifiedtime AS start_date,
'9999-12-31' AS end_date
FROM test.ods_orders
where dt='2020-06-21'
union all
select A.orderid,
A.createtime,
A.modifiedtime,
A.status,
A.start_date,
case when B.orderid is not null and A.end_date>'2020-06-21'
then '2020-06-20'
else A.end_date
end end_date
from test.dwd_orders A
left join (select * from test.ods_orders where dt='2020-06-21') B
on A.orderid=B.orderid;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NIC3JVY6-1631498645353)(C:\Users\21349\AppData\Roaming\Typora\typora-user-images\image-20210909151346705.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-x9j47UR6-1631498645354)(C:\Users\21349\Desktop\QrCode\2021-09-09_151458.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SuSm8n3e-1631498645356)(C:\Users\21349\Desktop\QrCode\2021-09-09_151834.png)]
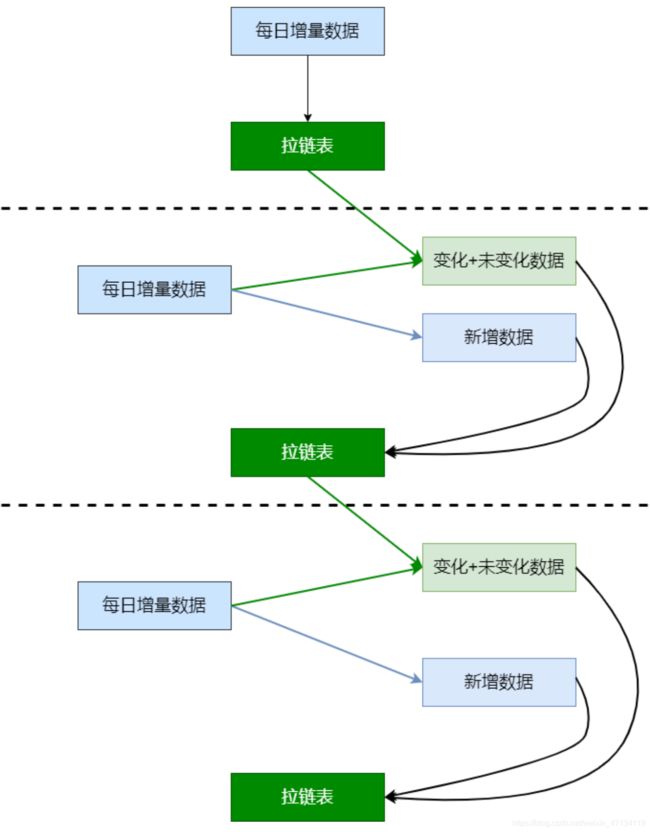
5.4 拉链表小结
六. DIM 层建表加载数据
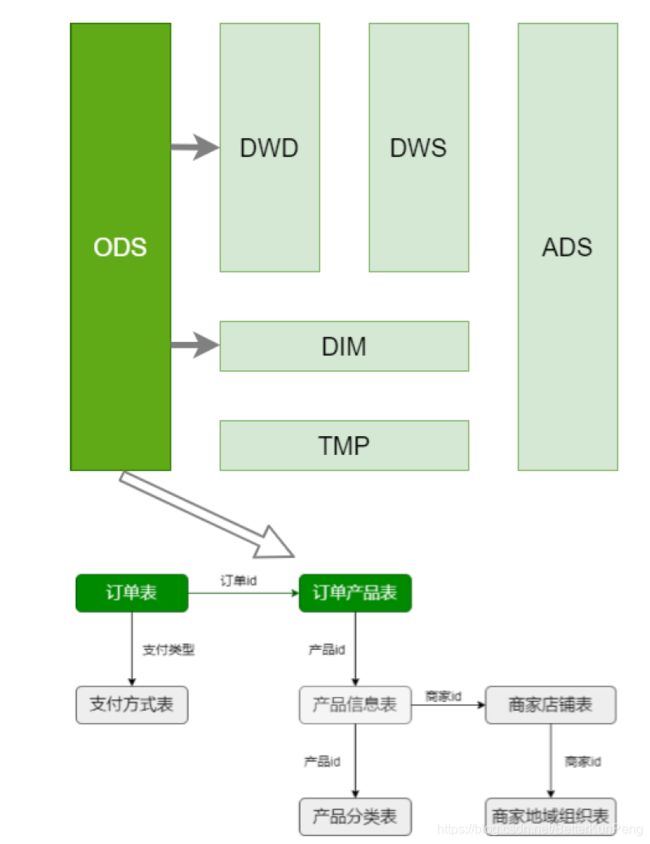
首先要确定哪些是事实表,哪些是维表?
-
绿色的是事实表
-
灰色的是维表
用什么方式处理维表,每日快照、拉链表?
-
小表使用每日快照:产品分类表、商家店铺表、商家地域组织表、支付方式表
-
大表使用拉链表:产品信息表
6.1 商品分类表
数据库中的数据是规范的(满足三范式),但是规范化的数据给查询带来不便。
备注:这里对商品分类维度表做了逆规范化,省略了无关信息,做成了宽表
DROP TABLE IF EXISTS dim.dim_trade_product_cat;
create table if not exists dim.dim_trade_product_cat(
firstId int, -- 一级商品分类id
firstName string, -- 一级商品分类名称
secondId int, -- 二级商品分类Id
secondName string, -- 二级商品分类名称
thirdId int, -- 三级商品分类id
thirdName string -- 三级商品分类名称
)
partitioned by (dt string)
STORED AS PARQUET;
实现
select T1.catid, T1.catname, T2.catid, T2.catname, T3.catid,
T3.catname
from (select catid, catname, parentid
from ods.ods_trade_product_category
where level=3 and dt='2020-07-01') T3
left join
(select catid, catname, parentid
from ods.ods_trade_product_category
where level=2 and dt='2020-07-01') T2
on T3.parentid=T2.catid
left join
(select catid, catname, parentid
from ods.ods_trade_product_category
where level=1 and dt='2020-07-01') T1
on T2.parentid=T1.catid;
数据加载:
/root/data/lagoudw/script/trade/dim_load_product_cat.sh
#!/bin/bash
source /etc/profile
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert overwrite table dim.dim_trade_product_cat
partition(dt='$do_date')
select
t1.catid, -- 一级分类id
t1.catname, -- 一级分类名称
t2.catid, -- 二级分类id
t2.catname, -- 二级分类名称
t3.catid, -- 三级分类id
t3.catname -- 三级分类名称
from
-- 商品三级分类数据
(select catid, catname, parentid
from ods.ods_trade_product_category
where level=3 and dt='$do_date') t3
left join
-- 商品二级分类数据
(select catid, catname, parentid
from ods.ods_trade_product_category
where level=2 and dt='$do_date') t2
on t3.parentid = t2.catid
left join
-- 商品一级分类数据
(select catid, catname, parentid
from ods.ods_trade_product_category
where level=1 and dt='$do_date') t1
on t2.parentid = t1.catid;
"
hive -e "$sql"
6.2 商品地域组织表
商家店铺表、商家地域组织表 => 一张维表
这里也是逆规范化的设计,将商家店铺表、商家地域组织表组织成一张表,并拉宽。在一行数据中体现:商家信息、城市信息、地域信息、信息中包括 id 和 name。
drop table if exists dim.dim_trade_shops_org;
create table dim.dim_trade_shops_org(
shopid int,
shopName string,
cityId int,
cityName string ,
regionId int ,
regionName string
)
partitioned by (dt string)
STORED AS PARQUET;
实现
select T1.shopid, T1.shopname, T2.id cityid, T2.orgname
cityname, T3.id regionid, T3.orgname regionname
from
(select shopid, shopname, areaid
from ods.ods_trade_shops
where dt='2020-07-01') T1
left join
(select id, parentid, orgname, orglevel
from ods.ods_trade_shop_admin_org
where orglevel=2 and dt='2020-07-01') T2
on T1.areaid=T2.id
left join
(select id, orgname, orglevel
from ods.ods_trade_shop_admin_org
where orglevel=1 and dt='2020-07-01') T3
on T2.parentid=T3.id
limit 10;
/root/data/lagoudw/script/trade/dim_load_shop_org.sh
#!/bin/bash
source /etc/profile
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert overwrite table dim.dim_trade_shops_org
partition(dt='$do_date')
select t1.shopid,
t1.shopname,
t2.id as cityid,
t2.orgname as cityName,
t3.id as region_id,
t3.orgname as region_name
from (select shopId, shopName, areaId
from ods.ods_trade_shops
where dt='$do_date') t1
left join
(select id, parentId, orgname, orglevel
from ods.ods_trade_shop_admin_org
where orglevel=2 and dt='$do_date') t2
on t1.areaid = t2.id
left join
(select id, parentId, orgname, orglevel
from ods.ods_trade_shop_admin_org
where orglevel=1 and dt='$do_date') t3
on t2.parentid = t3.id;
"
hive -e "$sql"
6.3 支付方式表
对 ODS 中表的信息做了裁剪,只保留了必要的信息
drop table if exists dim.dim_trade_payment;
create table if not exists dim.dim_trade_payment(
paymentId string, -- 支付方式id
paymentName string -- 支付方式名称
)
partitioned by (dt string)
STORED AS PARQUET;
/root/data/lagoudw/script/trade/dim_load_payment.sh
#!/bin/bash
source /etc/profile
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert overwrite table dim.dim_trade_payment
partition(dt='$do_date')
select id, payName
from ods.ods_trade_payments
where dt='$do_date';
"
hive -e "$sql"
6.4 商品信息表
使用拉链表对商品信息进行处理。
- 历史数据 => 初始化拉链表(开始日期:当日;结束日期:9999-12-31)【只执行一次】
- 拉链表的每日处理【每次加载数据时处理】
- 新增数据:每日新增数据(ODS) => 开始日期;当日;结束日期:9999-12-31
- 历史数据:拉链表(DIM)与每日新增数据(ODS)做左连接
- 连接上数据,数据有变化,结束日期:当日
- 未连接上数据,数据无变化,结束日器保持不变
6.4.1 创建维表
拉链表要增加两列,分别记录生效日期和失效日期
drop table if exists dim.dim_trade_product_info;
create table dim.dim_trade_product_info(
`productId` bigint,
`productName` string,
`shopId` string,
`price` decimal,
`isSale` tinyint,
`status` tinyint,
`categoryId` string,
`createTime` string,
`modifyTime` string,
`start_dt` string,
`end_dt` string
) COMMENT '产品表'
STORED AS PARQUET;
6.4.2 初始数据加载(历史数据加载,只做一次)
insert overwrite table dim.dim_trade_product_info
select productId,
productName,
shopId,
price,
isSale,
status,
categoryId,
createTime,
modifyTime,
-- modifyTime非空取modifyTime,否则取createTime;substr取日期
case when modifyTime is not null
then substr(modifyTime, 0, 10)
else substr(createTime, 0, 10)
end as start_dt,
'9999-12-31' as end_dt
from ods.ods_trade_product_info
where dt = '2020-07-12';
6.4.2 增量数据导入(重复执行,每次加载数据执行)
/root/data/lagoudw/script/trade/dim_load_product_info.sh
#!/bin/bash
source /etc/profile
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert overwrite table dim.dim_trade_product_info
select productId,
productName,
shopId,
price,
isSale,
status,
categoryId,
createTime,
modifyTime,
case when modifyTime is not null
then substr(modifyTime,0,10)
else substr(createTime,0,10)
end as start_dt,
'9999-12-31' as end_dt
from ods.ods_trade_product_info
where dt='$do_date'
union all
select dim.productId,
dim.productName,
dim.shopId,
dim.price,
dim.isSale,
dim.status,
dim.categoryId,
dim.createTime,
dim.modifyTime,
dim.start_dt,
case when dim.end_dt >= '9999-12-31' and ods.productId
is not null
then '$do_date'
else dim.end_dt
end as end_dt
from dim.dim_trade_product_info dim left join
(select *
from ods.ods_trade_product_info
where dt='$do_date' ) ods
on dim.productId = ods.productId
"
hive -e "$sql"
七. DWD 层建表加载数据
要处理的表有两张:订单表、订单产品表。其中:
-
订单表是周期性事实表;为保留订单状态,可以使用拉链表进行处理;
-
订单产品表普通的事实表,用常规的方法进行处理;
- 如果有数据清洗、数据转换的业务需求, ODS => DWD
- 如果没有数据清洗、数据转换的业务需求,保留在 ODS,不做任何变化。这个是本项目的处理方式。
订单状态
- -3:用户拒收
- -2:未付款订单
- -1:用户取消
- 0:待发货
- 1:配送中
- 2:用户确认接收
订单从创建到最终完成,是有时间限制的;业务上也不允许订单在一个月之后,状态仍然在发生变化;
7.1 DWD 层建表
备注:
- 与维表不同,订单事实表的记录数非常多
- 订单有生命周期;订单状态不可能永远处于变化之中(订单的生命周期一般在15天左右)
- 订单是一个拉链表,而且是分区表
- 分区的目的:订单一旦终止,不会重复计算
- 分区的条件:订单的创建日期;保证相同的订单在同一个分区
-- 订单事实表(拉链表)
DROP TABLE IF EXISTS dwd.dwd_trade_orders;
create table dwd.dwd_trade_orders(
`orderId` int,
`orderNo` string,
`userId` bigint,
`status` tinyint,
`productMoney` decimal,
`totalMoney` decimal,
`payMethod` tinyint,
`isPay` tinyint,
`areaId` int,
`tradeSrc` tinyint,
`tradeType` int,
`isRefund` tinyint,
`dataFlag` tinyint,
`createTime` string,
`payTime` string,
`modifiedTime` string,
`start_date` string,
`end_date` string
) COMMENT '订单事实拉链表'
partitioned by (dt string)
STORED AS PARQUET;
7.2 DWD 层数据加载
-- 备注:时间日期格式转换
-- 'yyyy-MM-dd HH:mm:ss' => timestamp => 'yyyy-MM-dd'
select unix_timestamp(modifiedtime, 'yyyy-MM-dd HH:mm:ss')
from ods.ods_trade_orders limit 10;
select from_unixtime(unix_timestamp(modifiedtime, 'yyyy-MM-ddHH:mm:ss'), 'yyyy-MM-dd')
from ods.ods_trade_orders limit 10;
/root/data/lagoudw/script/trade/dwd_load_trade_orders.sh
#!/bin/bash
source /etc/profile
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.dynamic.partition=true;
INSERT OVERWRITE TABLE dwd.dwd_trade_orders
partition(dt)
SELECT orderId,orderNo,userId,status,productMoney,totalMoney,payMethod,isPay,areaId,tradeSrc,tradeType,isRefund,
dataFlag,createTime,payTime,modifiedTime, case when modifiedTime is not null
then from_unixtime(unix_timestamp(modifiedTime,'yyyy-MM-dd HH:mm:ss'),'yyyy-MM-dd')
else from_unixtime(unix_timestamp(createTime,'yyyy-MM-dd HH:mm:ss'), 'yyyy-MM-dd')
end as start_date,'9999-12-31' as end_date,
from_unixtime(unix_timestamp(createTime, 'yyyy-MM-dd HH:mm:ss'), 'yyyy-MM-dd') as dt
FROM ods.ods_trade_orders WHERE dt='$do_date' union all
SELECT A.orderId,A.orderNo,A.userId,A.status,A.productMoney,A.totalMoney,A.payMethod,A.isPay,A.areaId,A.tradeSrc,
A.tradeType,A.isRefund,A.dataFlag,A.createTime,A.payTime,A.modifiedTime,A.start_date,
CASE WHEN B.orderid IS NOT NULL AND A.end_date >'$do_date' THEN date_add('$do_date', -1)
ELSE A.end_date END AS end_date,
from_unixtime(unix_timestamp(A.createTime, 'yyyy-MM-dd HH:mm:ss'), 'yyyy-MM-dd') as dt
FROM (SELECT * FROM dwd.dwd_trade_orders WHERE dt>date_add('$do_date', -15)) A
left outer join (SELECT * FROM ods.ods_trade_orders WHERE dt='$do_date') B ON A.orderId = B.orderId;
"
hive -e "$sql"
八. DWS 层建表加载数据
DIM、DWD => 数据仓库分层、数据仓库理论
需求:计算当天
-
全国所有订单信息
-
全国、一级商品分类订单信息
-
全国、二级商品分类订单信息
-
大区所有订单信息
-
大区、一级商品分类订单信息
-
大区、二级商品分类订单信息
-
城市所有订单信息
-
城市、一级商品分类订单信息
-
城市、二级商品分类订单信息
需要的信息:订单表、订单商品表、商品信息表维表、商品分类维表、商家地域维表
订单表 => 订单 id、订单状态
订单商品表 => 订单 id、商品 id、商家 id、单价、数量
商品信息维表 => 商品 id、三级分类 id
商品分类维表 => 一级名称、一级分类 id、二级名称、二级分类 id、三级名称、三级分类 id
商家地域维表 => 商家 id、区域名称、区域 id、城市名称、城市 id订单表、订单商品表、商品信息维表 => 订单 id、商品 id、商家 id、三级分类 id、单价、数量(订单明细表)
订单明细表、商品分类维表、商家地域维表 => 订单 id、商品 id、商家 id、三级分类名称、单价、数量、区域、城市 => 订单明细表
8.1 DWS 层建表
- dws_trade_orders(订单明细)由以下表轻微聚合而成:
- dwd.dwd_trade_orders (拉链表、分区表)
- ods.ods_trade_order_product(分区表)
- dim.dim_trade_product_info(维表、拉链表)
- dws_trade_orders_w(订单明细宽表)由以下表组成:
- ads.dws_trade_orders(分区表)
- dim.dim_trade_product_cat(分区表)
- dim.dim_trade_shops_org(分区表)
-- 订单明细表(轻度汇总事实表)。每笔订单的明细
DROP TABLE IF EXISTS dws.dws_trade_orders;
create table if not exists dws.dws_trade_orders(
orderid string, -- 订单id
cat_3rd_id string, -- 商品三级分类id
shopid string, -- 店铺id
paymethod tinyint, -- 支付方式
productsnum bigint, -- 商品数量
paymoney double, -- 订单商品明细金额
paytime string -- 订单时间
)
partitioned by (dt string)
STORED AS PARQUET;
-- 订单明细表宽表
DROP TABLE IF EXISTS dws.dws_trade_orders_w;
create table if not exists dws.dws_trade_orders_w(
orderid string, -- 订单id
cat_3rd_id string, -- 商品三级分类id
thirdname string, -- 商品三级分类名称
secondname string, -- 商品二级分类名称
firstname string, -- 商品一级分类名称
shopid string, -- 店铺id
shopname string, -- 店铺名
regionname string, -- 店铺所在大区
cityname string, -- 店铺所在城市
paymethod tinyint, -- 支付方式
productsnum bigint, -- 商品数量
paymoney double, -- 订单明细金额
paytime string -- 订单时间
)
partitioned by (dt string)
STORED AS PARQUET;
8.2 DWS 层加载数据
/root/data/lagoudw/script/trade/dws_load_trade_orders.sh
备注:dws_trade_orders/dws_trade_orders_w 中一笔订单可能出现多条记录
#!/bin/bash
source /etc/profile
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert overwrite table dws.dws_trade_orders
partition(dt='$do_date')
select t1.orderid as orderid,t3.categoryid as cat_3rd_id,t3.shopid as shopid,t1.paymethod as paymethod,
t2.productnum as productsnum,t2.productnum*t2.productprice as pay_money,t1.paytime as paytime
from (select orderid, paymethod, paytime from dwd.dwd_trade_orders where dt='$do_date') T1
left join
(select orderid, productid, productnum, productprice from ods.ods_trade_order_product
where dt='$do_date') T2 on t1.orderid = t2.orderid left join
(select productid, shopid, categoryid from dim.dim_trade_product_info where start_dt <= '$do_date'
and end_dt >= '$do_date' ) T3 on t2.productid=t3.productid;
insert overwrite table dws.dws_trade_orders_w
partition(dt='$do_date')
select t1.orderid,t1.cat_3rd_id,t2.thirdname,t2.secondname,t2.firstname,t1.shopid,t3.shopname,t3.regionname,t3.cityname,
t1.paymethod,t1.productsnum,t1.paymoney,t1.paytime from (select orderid,cat_3rd_id,shopid,paymethod,productsnum,
paymoney,paytime from dws.dws_trade_orders where dt='$do_date') T1
join (select thirdid, thirdname, secondid, secondname,firstid, firstname from dim.dim_trade_product_cat
where dt='$do_date') T2 on T1.cat_3rd_id = T2.thirdid join
(select shopid, shopname, regionname, cityname from dim.dim_trade_shops_org where dt='$do_date') T3
on T1.shopid = T3.shopid
"
hive -e "$sql"
备注:要自己准备测试数据,保证测试的日期有数据
-
dwd.dwd_trade_orders(拉链表、分区表)
-
ods.ods_trade_order_product(分区表)
-
dim.dim_trade_product_info(维表、拉链表)
-
dim.dim_trade_product_cat(分区表)
-
dim.dim_trade_shops_org(分区表)
构造测试数据(拉链分区表)
insert overwrite table dwd.dwd_trade_orders
-- 日期可以随意定,自己选
partition(dt='2020-07-12')
select orderid,orderno,userid,status,productmoney,totalmoney,paymethod,ispay,areaid,tradesrc,tradetype,isrefund,dataflag,
'2020-07-12',paytime,modifiedtime,start_date,end_date from dwd.dwd_trade_orders where end_date='9999-12-31';
九. ADS 层开发
需求:计算当天
-
全国所有订单消息
-
全国、一级商品分类订单消息
-
全国、二级商品分类订单消息
-
大区所有订单消息
-
大区、一级商品分类订单消息
-
大区、二级商品分类订单消息
-
城市所有订单消息
-
城市、一级商品分类订单消息
-
城市、二级商品分类订单消息
用到的表:
dws.dws_trade_orders_w
9.1 ADS 层建表
-- ADS层订单分析表
DROP TABLE IF EXISTS ads.ads_trade_order_analysis;
create table if not exists ads.ads_trade_order_analysis(
areatype string, -- 区域范围:区域类型(全国、大区、城市)
regionname string, -- 区域名称
cityname string, -- 城市名称
categorytype string, -- 商品分类类型(一级、二级)
category1 string, -- 商品一级分类名称
category2 string, -- 商品二级分类名称
totalcount bigint, -- 订单数量
total_productnum bigint, -- 商品数量
totalmoney double -- 支付金额
)
partitioned by (dt string)
row format delimited fields terminated by ',';
9.2 ADS 层加载数据
/root/data/lagoudw/script/trade/ads_load_trade_order_analysis.sh
备注:一笔订单,有多个商品;多个商品有不同的分类;这会导致一笔订单有多个分类,它们是分别统计的;
#!/bin/bash
source /etc/profile
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
with mid_orders as (
select regionname,
cityname,
firstname category1,
secondname category2,
count(distinct orderid) as totalcount,
sum(productsnum) as total_productnum,
sum(paymoney) as totalmoney
from dws.dws_trade_orders_w
where dt='$do_date'
group by regionname, cityname, firstname, secondname
)
insert overwrite table ads.ads_trade_order_analysis
partition(dt='$do_date')
select '全国' as areatype,
'' as regionname,
'' as cityname,
'' as categorytype,
'' as category1,
'' as category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
union all
select '全国' as areatype,
'' as regionname,
'' as cityname,
'一级' as categorytype,
category1,
'' as category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by category1
union all
select '全国' as areatype,
'' as regionname,
'' as cityname,
'二级' as categorytype,
'' as category1,
category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by category2
union all
select '大区' as areatype,
regionname,
'' as cityname,
'' as categorytype,
'' as category1,
'' as category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by regionname
union all
select '大区' as areatype,
regionname,
'' as cityname,
'一级' as categorytype,
category1,
'' as category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by regionname, category1
union all
select '大区' as areatype,
regionname,
'' as cityname,
'二级' as categorytype,
'' as category1,
category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by regionname, category2
union all
select '城市' as areatype,
'' as regionname,
cityname,
'' as categorytype,
'' as category1,
'' as category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by cityname
union all
select '城市' as areatype,
'' as regionname,
cityname,
'一级' as categorytype,
category1,
'' as category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by cityname, category1
union all
select '城市' as areatype,
'' as regionname,
cityname,
'二级' as categorytype,
'' as category1,
category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by cityname, category2;
"
hive -e "$sql"
备注:由于在 dws.dws_trade_orders_w 中,一笔订单可能有多条记录,所以在统计订单数量的时候要用 count(distinct orderid)
十. 数据导出
ads.ads_trade_order_analysis 分区表,使用 DataX 导出到 MySQL。
十一. 小结
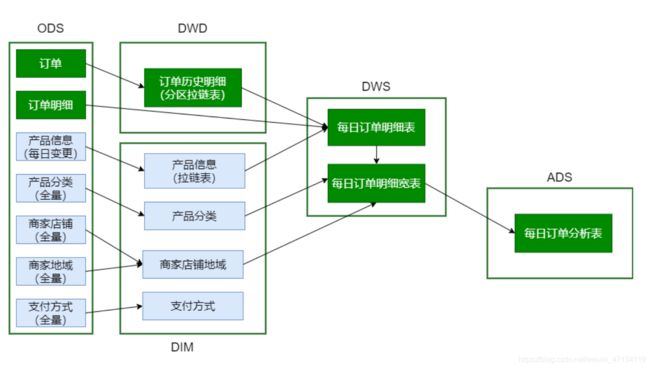
脚本调用次序:
# 加载ODS数据(含DataX迁移数据)
/data/lagoudw/script/trade/ods_load_trade.sh
# 加载DIM层数据
/data/lagoudw/script/trade/dim_load_product_cat.sh
/data/lagoudw/script/trade/dim_load_shop_org.sh
/data/lagoudw/script/trade/dim_load_payment.sh
/data/lagoudw/script/trade/dim_load_product_info.sh
# 加载DWD层数据
/data/lagoudw/script/trade/dwd_load_trade_orders.sh
# 加载DWS层数据
/data/lagoudw/script/trade/dws_load_trade_orders.sh
# 加载ADS层数据
/data/lagoudw/script/trade/ads_load_trade_order_analysis.sh
主要技术点:
- 拉链表]:创建、使用与回滚;商品信息表、订单表(周期性事实表;分区表+拉链表)
- 宽表(逆规范化):商品分类表、商品地域组织表、订单明细及订单明细宽表(轻度汇总的事实表)
um(totalmoney)
from mid_orders
group by category2
union all
select ‘大区’ as areatype,
regionname,
‘’ as cityname,
‘’ as categorytype,
‘’ as category1,
‘’ as category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by regionname
union all
select ‘大区’ as areatype,
regionname,
‘’ as cityname,
‘一级’ as categorytype,
category1,
‘’ as category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by regionname, category1
union all
select ‘大区’ as areatype,
regionname,
‘’ as cityname,
‘二级’ as categorytype,
‘’ as category1,
category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by regionname, category2
union all
select ‘城市’ as areatype,
‘’ as regionname,
cityname,
‘’ as categorytype,
‘’ as category1,
‘’ as category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by cityname
union all
select ‘城市’ as areatype,
‘’ as regionname,
cityname,
‘一级’ as categorytype,
category1,
‘’ as category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by cityname, category1
union all
select ‘城市’ as areatype,
‘’ as regionname,
cityname,
‘二级’ as categorytype,
‘’ as category1,
category2,
sum(totalcount),
sum(total_productnum),
sum(totalmoney)
from mid_orders
group by cityname, category2;
"
hive -e “$sql”
备注:由于在 `dws.dws_trade_orders_w` 中,一笔订单可能有多条记录,所以在统计订单数量的时候要用 `count(distinct orderid)`
### 十. 数据导出
`ads.ads_trade_order_analysis` 分区表,使用 DataX 导出到 MySQL。
### 十一. 小结

脚本调用次序:
```sh
# 加载ODS数据(含DataX迁移数据)
/data/lagoudw/script/trade/ods_load_trade.sh
# 加载DIM层数据
/data/lagoudw/script/trade/dim_load_product_cat.sh
/data/lagoudw/script/trade/dim_load_shop_org.sh
/data/lagoudw/script/trade/dim_load_payment.sh
/data/lagoudw/script/trade/dim_load_product_info.sh
# 加载DWD层数据
/data/lagoudw/script/trade/dwd_load_trade_orders.sh
# 加载DWS层数据
/data/lagoudw/script/trade/dws_load_trade_orders.sh
# 加载ADS层数据
/data/lagoudw/script/trade/ads_load_trade_order_analysis.sh
主要技术点:
- 拉链表]:创建、使用与回滚;商品信息表、订单表(周期性事实表;分区表+拉链表)
- 宽表(逆规范化):商品分类表、商品地域组织表、订单明细及订单明细宽表(轻度汇总的事实表)