DETR精读笔记
DETR精读笔记
论文:End-to-End Object Detection with Transformers (发表于 ECCV-2020)
代码:https://github.com/facebookresearch/detr
解读视频:DETR 论文精读【论文精读】 本笔记主要基于 Yi Zhu 老师的解读
引言
2020年5月出现在 arXiv 上的 DETR(DEtection TRansformer)可以说是近年来目标检测领域的一个里程碑式的工作,两年间引用量就已经超过 2000,并且有一系列基于它的改进工作,如 Deformable-DETR, Omni-DETR, up-DETR, PnP-DETR, SMAC-DETR, DAB-DETR, SAM-DETR, DN-DETR, OW-DETR, OV-DETR, …。其他有这么多直接加前缀的改进工作的论文如 ResNets、RCNNs、YOLOs,都已经成为了 CV 领域大家耳熟能详的工作。
从论文题目 End-to-End Object Detection with Transformers 中不难看出,本文的关键创新点有两个:end-to-end(端到端)和 Transformer。众所周知,不同于简单的图像分类任务,目标检测任务的定义更为复杂,模型需要同时预测图像中物体的种类和位置,并且通常每张图片的物体个数都是不一致的。因此,现有的目标检测方法都有着复杂的流程。现有的主流目标检测方法大致可分为 proposal-based,anchor-based,anchor-free 几类方法,它们都需要借助先验知识,先为模型提供一些候选的区域或者锚框,并且在后处理时, NMS(Non Maximum Suppression)操作基本是必不可少的。这样看来,现有的目标检测方法都不能称为严格意义上的 “端到端”。实际上,这种复杂的架构可以看作是一种间接的、 “曲线救国” 的方式,因为在之前,直接端到端地做目标检测任务,无法取得很好的结果,只能通过设计 anchor、proposal,NMS 等前后处理方式,来提升性能。
本文回归到了目标检测任务的本质,将其视作集合预测的问题,即给定一张图像,预测图像中感兴趣物体的集合。DETR 不需要先验地设置 anchor 和 proposal,并且通过借助 Transformer 的全局建模能力和 learned object query,DETR 输出的结果中不会含有对于同一个物体的多个冗余的框,其输出结果就是最终的预测结果,因此也不需要后处理 NMS 的操作,从而实现了一个端到端的目标检测框架。具体来说,DETR 设计的点主要有两个:
- 提出了一种新的目标检测的损失函数。通过二分图匹配的方式,强制模型输出一个独特的预测,对图像中的每个物体只输出一个预测框;
- 使用了 Transformer Encoder-Decoder 的架构。相比于原始的 Transformer,为了适配目标检测任务,DETR 的 Decoder 还需要输入一个可学习的目标查询(learned object query),并且 DETR 的 Decoder 可以对每个类别进行并行预测。
本文最大的贡献是提出了一个简单的、端到端的、基于 Transformer 的新型目标检测框架。实际上,DETR 的目标检测性能与当时最强的检测器相比还有不小的差距。但是作者指出,DETR 使用的模型本身只是一个最简单的模型,还有很多目标检测的网络设计(如多尺度、可形变等)没有进行探索。其他的检测方法(如 RCNNs、YOLOs)也都是经过多年的发展才有了如今的性能,欢迎研究者们继续基于 DETR 进行改进。后来在 DETR 提出的两年时间里,出现了前面提到的大量的对于它的改进工作。甚至,不只是对于目标检测问题,作者希望 DETR 成为一个更通用的视觉任务的框架,并且在原文已经验证了 DETR 在全景分割任务上的有效性。在之后,也有一系列工作将 DETR 应用在了目标追踪、视频姿态预测、视频目标分割等多种视觉任务上。因此,DETR 可以说是近年来目标检测领域甚至整个 CV 领域一个里程碑式的工作。
我们首先通过图1来大致看一下 DETR 的流程,具体的方法会在后面详细介绍
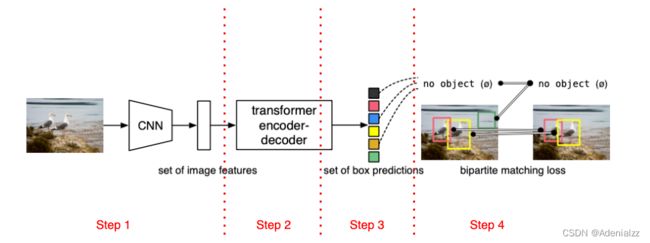
DETR 的流程可以分为四个步骤:
-
通过 CNN 提取输入图像的特征;
-
将 CNN 特征拉直,送入到 Transformer Encoder 中进一步通过自注意力学习全局的特征;
关于 Encoder 的作用,一个直观的理解是:Transformer Encoder 学习到的全局特征有利用移除对于同一个物体的多个冗余的框。具体来说,Transformer 中的自注意力机制,使得特征图中的每个位置都能 attend 到图中所有的其他特征,这样模型就能大致知道哪一个区域是一个物体,哪块区域又是另一个物体,从而能够尽量保证每个物体只出一个预测框;
-
通过 Transformer Decoder 生成输出框;
注意输入到 Decoder 的,除了 Encoder 提取的特征之外,还有 learned object query(图1中没有画出,后面会讲)。图像特征与 learned object query 在 Decoder 中通过自注意力机制进行交互,输出预测框。输出的框的个数是由 learned object query 决定的,是一个固定的值 N N N,原文中设置的是 100;
-
计算生成的 N N N 个输出框与 Ground Truth 的损失函数;
关键问题是输出的框是固定 N N N 个,但是实际数据集中的 GT 框一般只有几个且个数不定,那么怎么计算 loss 呢?这里就是本文最关键的一个贡献,通过二分图匹配来选出 N N N 个输出框中与 M M M 个 GT 框最匹配的 M M M 个,然后再像常规目标检测方法一样计算它们之间的损失,即分类损失和边框回归损失。
在推理时,直接对输出的 N N N 个框卡一个阈值,作为预测结果即可。
可以看到,在整个 DETR 的流程中,确实不需要 anchor、proposal 的设置,也不需要后处理 NMS,因此说 DETR 是一个端到端的目标检测框架。
方法
下面我们详细来看一下 DETR 的具体方法。在原文的方法章节,作者分了两个部分,第一部分介绍将目标检测看做集合预测问题所用的损失函数,这部分是 DETR 能够做成一个端到端的方法(无需前后处理)的关键;第二部分介绍了整个 DETR 的架构,就是更为详细、完整地介绍了我们上面图1中的流程,这一部分的关键在于 Transformer 网络结构怎么用在整个 DETR 的框架中,还有怎样设置 learned object query。接下来依次介绍这两部分。
目标检测的集合预测损失
之前提到,DETR 模型每次输出的框的个数是固定的 N = 100 N=100 N=100 ,自然地,这个 N N N 应该设置为远大于数据集中单张图片的最大物体数。但是,对于每一张图片来说,GT 框的个数都是不一致的,并且通常只有几个,那么怎么知道哪个预测框对应哪个 GT 框呢,怎么来计算损失呢?作者将这个问题转化成了一个二分图匹配的问题(optimal bipartite matching)。
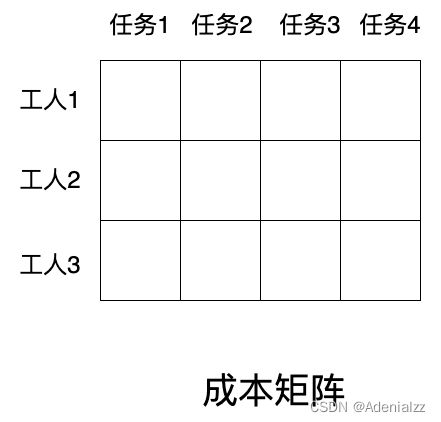
我们先来介绍一下二分图匹配到底是一个什么问题。假设现在有 3 个工人和 4 个任务,由于每个工人的特长不一样,他们完成不同任务的时间(成本)也是不一样的,现在的问题就是怎样分配任务,能够使得总成本最低。最直接的,用暴力遍历的方法也能找出各种排列组合的最小成本值,但这样的复杂度无疑是很高的。匈牙利算法是解决该问题的一个知名算法,能够以较优的复杂度得到答案。
在 scipy 库中,已经封装好了匈牙利算法,只需要将成本矩阵输入进去就能够得到最优的匹配。在 DETR 的官方代码中,也是调用的这个函数进行匹配。
from scipy.optimize import linear_sum_assignment
实际上,我们目前面对的 “从 N N N 个预测框中选出 M M M 个与 GT 对应的框” 的问题也可以视作二分图匹配的问题。而这里所谓的 “成本”,就是每个框与 GT 框之间的损失。对于目标检测问题,损失就是分类损失和边框损失组成。即: − 1 { c i ≠ ∅ } p ^ σ ( i ) + 1 { c o ≠ ∅ } L b o x ( b i , b ^ σ ( i ) ) -\mathbb{1}_{\{c_i\ne\empty\}}\hat{p}_{\sigma(i)}+\mathbb{1}_{\{c_o\ne\empty\}}\mathcal{L}_{box}(b_i,\hat{b}_{\sigma(i)}) −1{ci=∅}p^σ(i)+1{co=∅}Lbox(bi,b^σ(i)) 。
其实这里与之前匹配 proposal 的 anchor 的方式类似,但是这里要的是 “一对一” 的对应关系,即强制要对每个物体只出一个框,因而不需要 NMS 的后处理。
在确定了预测框与 GT 框的对应关系之后,再按照常规的目标检测方式去计算损失函数即可:
L H u n g a r i a n ( y , y ^ ) = ∑ i = 1 N [ − log p ^ σ ^ ( i ) ( c i ) + 1 c i ≠ ∅ L b o x ( b i , b ^ σ ^ ( i ) ) ] \mathcal{L}_{Hungarian}(y,\hat{y})=\sum_{i=1}^N[-\log \hat{p}_{\hat{\sigma}(i)}(c_i)+\mathbb{1}_{c_i\ne\empty}\mathcal{L}_{box}(b_i,\hat{b}_{\hat{\sigma}(i))}] LHungarian(y,y^)=i=1∑N[−logp^σ^(i)(ci)+1ci=∅Lbox(bi,b^σ^(i))]
对于损失函数,DETR 还有两点小改动:
- 一是对于分类损失,即上式前一项,通常目标检测方法计算损失时是需要加 log \log log 的,但是 DETR 中为了保证两部分损失的数值区间接近,便于优化,选择了去掉 log \log log ;
- 二是对于边框回归损失,即上式后一项,通常方法只计算一个 L 1 L_1 L1 损失,但是 DETR 中用 Transformer 提取的全局特征对大物体比较友好,经常出一些大框,而大框的 L 1 L_1 L1 损失会很大,不利于优化,因此作者这里还添加了一个 Generalized IoU 损失,与 L 1 L_1 L1 一起,组成边框回归损失。
这都属于小的实现细节了。
DETR 框架
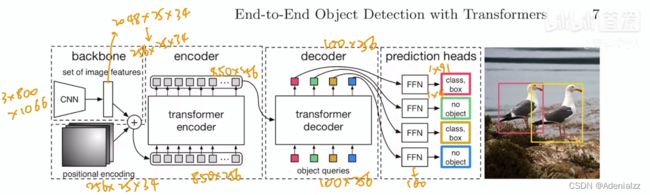
DETR 的整体框架其实在引言的部分已经大致介绍过了,在原文方法部分的图中,作者将更为详细的流程画了出来。下图在原文的基础上将一个典型的 3 × 800 × 1066 3\times 800\times 1066 3×800×1066 尺寸的图像输入在整个 DETR 框架后,整个数据流中各个张量的尺寸画了出来,方便大家理解。
- backbone 部分就是用 CNN 去提取图像特征,得到 2048 × 25 × 34 2048\times 25\times34 2048×25×34 大小的特征图,然后经过一个 1x1 Conv 降低一下通道数,得到特征尺寸为 256 × 25 × 34 256\times25\times34 256×25×34
- 然后要将 CNN 特征送入 Transformer,而 Transformer 本身是没有位置信息的,因此需要加上一个同尺寸的位置编码(positional encoding)。然后将带有位置编码的特征图拉直为 850 × 256 850\times256 850×256 ,送入 Transformer Encoder,Transformer Block 的输入输出特征尺寸是不变的,经过几层之后,得到原尺寸 850 × 256 850\times256 850×256 的特征;
- 然后将得到的全局图像特征送入 Transformer Decoder,这里还要同时输入的是 learned object query,它的尺寸是 100 × 256 100\times 256 100×256 ,256 是为了对应特征尺寸,100 则是要出框的个数 N = 100 N=100 N=100 。learned object query 是可学习的,与模型参数一起根据梯度进行更新。在 Decoder 中,图像全局特征与 learned object query 做交叉注意力 (cross attention),最终得到的特征尺寸的为 100 × 256 100\times 256 100×256 ;
- 最后,就要拿 100 × 256 100\times 256 100×256 特征通过检测头输出最终的预测,这里的检测头是比较常规的,就是通过一些全连接层输出分类结果和边框坐标。
再然后,就是按照之前介绍的二分图匹配的方式找到匹配的框,然后计算损失,梯度反传,更新参数即可。
为了说明端到端的 DETR 框架的简洁性,作者在论文末尾给出了 DETR 模型定义、推理的 “伪代码”,总共不到 50 行。之所以这里的伪代码要加引号,是因为其实这已经不算是伪代码了,而是直接可运行的 PyTorch 代码。当然这个版本缺少了一些细节,但也完全能够展现出 DETR 的流程了。该版本直接用来训练,最终也能达到 40 的 AP。读者可以对应伪代码再过一遍刚才介绍的 DETR 完成流程,体会一下一个端到端的目标检测框架有多么简洁。
import torch
from torch import nn
from torchvision.models import resnet50
class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads,
num_encoder_layers, num_decoder_layers):
super().__init__()
# We take only convolutional layers from ResNet-50 model
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2])
self.conv = nn.Conv2d(2048, hidden_dim, 1)
self.transformer = nn.Transformer(hidden_dim, nheads, num_encoder_layers, num_decoder_layers)
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
self.linear_bbox = nn.Linear(hidden_dim, 4)
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
x = self.backbone(inputs)
h = self.conv(x)
H, W = h.shape[-2:]
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1)
h = self.transformer(pos + h.flatten(2).permute(2, 0, 1),
self.query_pos.unsqueeze(1))
return self.linear_class(h), self.linear_bbox(h).sigmoid()
detr = DETR(num_classes=91, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6)
detr.eval()
inputs = torch.randn(1, 3, 800, 1200)
logits, bboxes = detr(inputs)
实验
定量性能对比
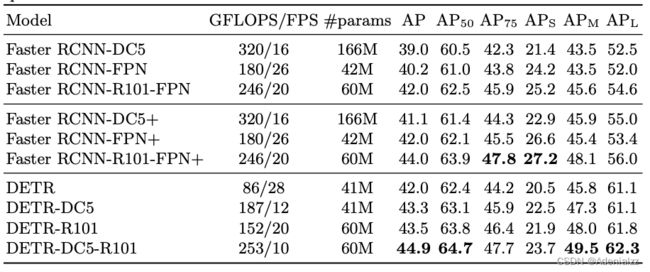
下面的表格给出了 DETR 与基线 Faster RCNN 的定量性能对比。最上面一部分的 Faster RCNN 的性能结果是 Detectron2 的实现,之所以将 Faster RCNN 分成两部分,是因为 DETR 中使用了近年来很多新的训练 trick,如 GIoU loss、更强的数据增强策略、更长的训练时间,因此作者团队添加这些策略重新训练了 Faster RCNN,以作公平的对比。
通过观察实验结果表格,有以下结论:
-
近年来的新的训练策略对于目标检测模型的提升非常明显。
对比表格的第一、第二部分,完全相同的模型,只是用了更优的训练策略,基本能稳定涨两个点。
-
在同样的训练策略、网络规模大小的情况下,DETR 比 Faster RCNN 高 1-2 个点。
对比表格的后两部分可以观察到这一点,DETR 对比基线的 Faster RCNN 还是还是有提升的。
-
DETR 在大物体的检测上远超 Faster RCNN,但是在小物体的检测上却也低了不少。
表格的后三列分别是小、中、大物体的检测性能,可以观察到 DETR 在大物体的检测上更出色,但是对于小物体的检测甚至远不如 Faster RCNN。大物体检测性能的提升得益于 Transformer 结构的全局建模能力,且没有预置的固定 anchor 的限制,因此预测框想多大就多大。而 DETR 在小物体上表现不佳,是因为本文中 DETR 的模型还是一个比较简单的模型,没有做很多针对目标检测的优化设计,比如针对小物体、多尺度的 FPN 设计。DETR 的网络结构还有待后续工作来改进。
-
参数量、计算量和推理速度之间并没有必然的关系。
#params、GFLOPS、FPS 分别表示了模型了参数量、计算量和推理速度,从表中可以观察到,有的模型参数量更小、计算量也更小,但是推理速度却慢很多,这种差异在跨结构之间的对比时格外明显(Transformers v.s. CNNs)。可能是由于硬件对于不同结构的优化程度有差异。目前来看, CNN 在同样网络规模甚至更大网络规模下,推理速度比 Transformer 更快。
可视化
编码器自注意力图可视化
首先我们来看对于 Encoder 的可视化,下图展示了对于一组参考点(图中红点)的 Encoder 注意力热力图的可视化,即参考点对于图像中所有其他点自注意力值的大小。
可以观察到,Transformer Encoder 基本已经能够非常清晰地区分开各个物体了,甚至热力图已经有一点实例分割的 mask 图的意思了。在有一定遮挡的情况下(左侧两头牛),也能够清楚地分开哪个是哪个。这种效果正是 Transformer Encoder 的全局建模能力所带来的,每个位置能够感知到图像中所有的其他位置。因此能够区分出图像中的不同物体,从而对于一个物体,尽量只出一个预测框。

解码器注意力图可视化
既然 Encoder 和 Decoder 都是 Transformer 结构,为什么要分成两部分呢?Decoder 和 Encoder 真的有在学习不同的信息吗?
通过前面的可视化,我们已经看到,Encoder 学习了一个全局的特征,基本已经能够区分开图中不同的物体。但是对于目标检测来说,大致地区分开不同的物体是不够的,我们还需要精确的物体的边界框坐标,这部分就由 Decoder 来做。
下图在 Decoder 特征中对每个不同的物体做了注意力的可视化,比如左图中的两头大象分别由蓝色和橙色表示。可以观察到,Decoder 网络中对于每个物体的注意力都集中在物体的边界位置,如大象的鼻子、尾巴、象腿等处。作者认为这是 Decoder 在区分不同物体边界的极值点(extremities),在 Encoder 能够区分开不同的物体之后,Decoder 再来关注不同物体边界的具体位置,最终精准地预测出不同物体的边框位置。因此,Encoder-Decoder 的结构是必要的,它们各司其职,一个都不能少。

learned object query 的可视化
learned object query 也是 DETR 与其他方法做法上一个很大的区别。
下图展示了 COCO2017 验证集中所有的预测框关于 learned object query 的可视化。20 张图分别表示 N = 100 N=100 N=100 个 learned object query 中的一个,每个点表示的是一个预测框的归一化中心坐标。其中绿色的点表示小框、红色的点表示大的横向的框、蓝色的点表示大的纵向的框。
可以看到,每个 learned object query 其实是学习了一种 “查询” 物体的模式。比如第一个 query,就是负责查询图中左下角有没有一个小物体,中间有没有一个大的横向的物体;第二个 query 负责查询中间偏下有没有小物体,以此类推。从这个可视化实验可以看出,其实 learned object query 做的事情与 anchor 是类似的,就是去看某个位置有没有某种物体。但是 anchor 需要先验地手动设置,DETR 中的 learned object query 则是可以与网络一起端到端地进行学习。

总结
总结下来,DETR 用 learned object query 取代了 anchor 的设置,用二分图匹配的方式取代了 NMS 后处理,将之前不可学习的步骤都替换为可以学习的内容,从而实现了一个端到端的目标检测网络。并且借助 Transformer 的全局特征交互能力,使得直接对每个物体“一对一”地输出一个可靠的预测结果成为了可能。虽然 DETR 本身检测性能并不突出,但是由于它切实解决了目标检测领域的一些痛点,提出了一个新的端到端的检测框架,随后就有一系列跟进工作把它的性能提了上来。DETR 完全称得上是目标检测领域,乃至整个视觉领域一篇里程碑式的工作。