基于百度飞桨PaddleOCR的图片文字识别
PaddleOCR项目源码:https://github.com/PaddlePaddle/PaddleOCR
飞桨开源文字识别模型套件PaddleOCR,目标是打造丰富、领先、实用的文本识别模型/工具库。最新开源的超轻量PP-OCRv3模型大小仅为16.2M。同时支持中英文识别;支持倾斜、竖排等多种方向文字识别;支持GPU、CPU预测;用户既可以通过PaddleHub很便捷的直接使用该超轻量模型,也可以使用PaddleOCR开源套件训练自己的超轻量模型。
本文基于上述源码,先下下来,主要用来学习,使用PaddleOCR模型,进行测试。
一、编译环境
电脑上装了Anaconda3 + Pycharm + python3.8的环境。就基于此环境。
新建项目时,选择Anaconda3 下的python.exe(python3.8)
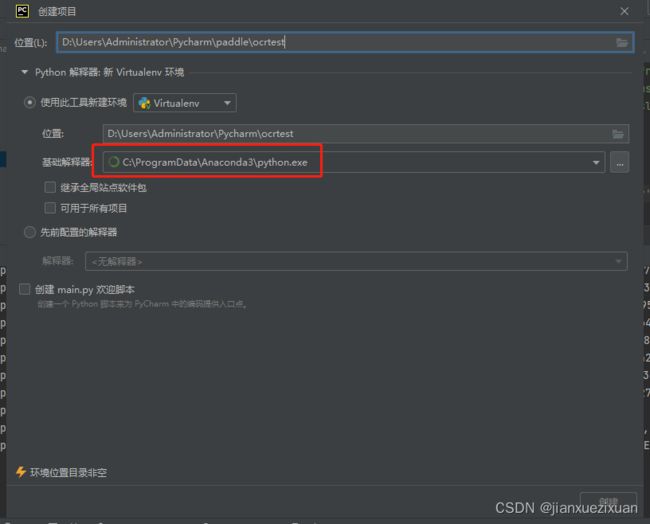
二、安装库
因为使用Anaconda3,直接通过其命令终端来安装,加上百度源,速度还是蛮快的。
1、安装安装PaddlePaddle
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
2、安装PaddleOCR whl包
pip install "paddleocr>=2.0.1" # 推荐使用2.0.1+版本
安装paddleocr过程中,会出现一些模块安装失败的提示,可以先通过 pip install 模块,安装完了再安装paddleocr。
3、查看安装库的版本:
python -c "import paddle; print(paddle.__version__)"

三、新建项目
注意解释器的选择,见第一步。
1、将Github下载的源码PaddleOCR-release-2.6中的文件夹ppocr、ppstructure、tools拷贝到ocrtest文件夹下;
2、下载PaddleOCR提供的测试图片https://paddleocr.bj.bcebos.com/dygraph_v2.1/ppocr_img.zip,解压后,将fonts文件夹拷贝到ocrtest文件夹下;
3、ocrtest文件夹下新建img文件夹,里面存放“test.jpg”;test.jpg图片可以从2中下载的测试图片里找。
4、新建python文件paddleocr.py,项目结构如下:
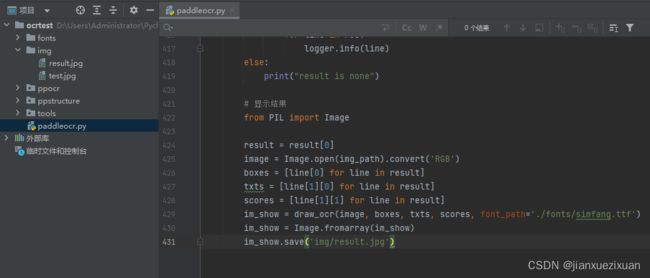
代码如下:
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import sys
import importlib
__dir__ = os.path.dirname(__file__)
from types import ModuleType
import paddle
sys.path.append(os.path.join(__dir__, ''))
import cv2
import logging
import numpy as np
from pathlib import Path
tools = importlib.import_module('.', 'tools')
ppocr = importlib.import_module('.', 'ppocr')
ppstructure = importlib.import_module('.', 'ppstructure')
from tools.infer import predict_system
from ppocr.utils.logging import get_logger
logger = get_logger()
from ppocr.utils.utility import check_and_read, get_image_file_list
from ppocr.utils.network import maybe_download, download_with_progressbar, is_link, confirm_model_dir_url
from tools.infer.utility import draw_ocr, str2bool, check_gpu
from ppstructure.utility import init_args, draw_structure_result
from ppstructure.predict_system import StructureSystem, save_structure_res, to_excel
SUPPORT_DET_MODEL = ['DB']
VERSION = '2.6.1.0'
SUPPORT_REC_MODEL = ['CRNN', 'SVTR_LCNet']
BASE_DIR = os.path.expanduser("~/.paddleocr/")
DEFAULT_OCR_MODEL_VERSION = 'PP-OCRv3'
SUPPORT_OCR_MODEL_VERSION = ['PP-OCRv3']
MODEL_URLS = {
'OCR': {
'PP-OCRv3': {
'det': {
'ch': {
'url':
'https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar',
},
'en': {
'url':
'https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar',
},
'ml': {
'url':
'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/Multilingual_PP-OCRv3_det_infer.tar'
}
},
'rec': {
'ch': {
'url':
'https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar',
'dict_path': './ppocr/utils/ppocr_keys_v1.txt'
},
'en': {
'url':
'https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar',
'dict_path': './ppocr/utils/en_dict.txt'
},
'korean': {
'url':
'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/korean_PP-OCRv3_rec_infer.tar',
'dict_path': './ppocr/utils/dict/korean_dict.txt'
},
'japan': {
'url':
'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/japan_PP-OCRv3_rec_infer.tar',
'dict_path': './ppocr/utils/dict/japan_dict.txt'
},
'chinese_cht': {
'url':
'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/chinese_cht_PP-OCRv3_rec_infer.tar',
'dict_path': './ppocr/utils/dict/chinese_cht_dict.txt'
},
'ta': {
'url':
'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/ta_PP-OCRv3_rec_infer.tar',
'dict_path': './ppocr/utils/dict/ta_dict.txt'
},
'te': {
'url':
'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/te_PP-OCRv3_rec_infer.tar',
'dict_path': './ppocr/utils/dict/te_dict.txt'
},
'ka': {
'url':
'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/ka_PP-OCRv3_rec_infer.tar',
'dict_path': './ppocr/utils/dict/ka_dict.txt'
},
'latin': {
'url':
'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/latin_PP-OCRv3_rec_infer.tar',
'dict_path': './ppocr/utils/dict/latin_dict.txt'
},
'arabic': {
'url':
'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/arabic_PP-OCRv3_rec_infer.tar',
'dict_path': './ppocr/utils/dict/arabic_dict.txt'
},
'cyrillic': {
'url':
'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/cyrillic_PP-OCRv3_rec_infer.tar',
'dict_path': './ppocr/utils/dict/cyrillic_dict.txt'
},
'devanagari': {
'url':
'https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/devanagari_PP-OCRv3_rec_infer.tar',
'dict_path': './ppocr/utils/dict/devanagari_dict.txt'
},
},
'cls': {
'ch': {
'url':
'https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar',
}
},
}
}
}
def parse_args(mMain=True):
import argparse
parser = init_args()
parser.add_help = mMain
parser.add_argument("--lang", type=str, default='ch')
parser.add_argument("--det", type=str2bool, default=True)
parser.add_argument("--rec", type=str2bool, default=True)
parser.add_argument("--type", type=str, default='ocr')
parser.add_argument(
"--ocr_version",
type=str,
choices=SUPPORT_OCR_MODEL_VERSION,
default='PP-OCRv3',
help='OCR Model version, the current model support list is as follows: '
'1. PP-OCRv3 Support Chinese and English detection and recognition model, and direction classifier model'
'2. PP-OCRv2 Support Chinese detection and recognition model. '
'3. PP-OCR support Chinese detection, recognition and direction classifier and multilingual recognition model.'
)
for action in parser._actions:
if action.dest in [
'rec_char_dict_path', 'table_char_dict_path', 'layout_dict_path'
]:
action.default = None
if mMain:
return parser.parse_args()
else:
inference_args_dict = {}
for action in parser._actions:
inference_args_dict[action.dest] = action.default
return argparse.Namespace(**inference_args_dict)
def parse_lang(lang):
latin_lang = [
'af', 'az', 'bs', 'cs', 'cy', 'da', 'de', 'es', 'et', 'fr', 'ga', 'hr',
'hu', 'id', 'is', 'it', 'ku', 'la', 'lt', 'lv', 'mi', 'ms', 'mt', 'nl',
'no', 'oc', 'pi', 'pl', 'pt', 'ro', 'rs_latin', 'sk', 'sl', 'sq', 'sv',
'sw', 'tl', 'tr', 'uz', 'vi', 'french', 'german'
]
arabic_lang = ['ar', 'fa', 'ug', 'ur']
cyrillic_lang = [
'ru', 'rs_cyrillic', 'be', 'bg', 'uk', 'mn', 'abq', 'ady', 'kbd', 'ava',
'dar', 'inh', 'che', 'lbe', 'lez', 'tab'
]
devanagari_lang = [
'hi', 'mr', 'ne', 'bh', 'mai', 'ang', 'bho', 'mah', 'sck', 'new', 'gom',
'sa', 'bgc'
]
if lang in latin_lang:
lang = "latin"
elif lang in arabic_lang:
lang = "arabic"
elif lang in cyrillic_lang:
lang = "cyrillic"
elif lang in devanagari_lang:
lang = "devanagari"
assert lang in MODEL_URLS['OCR'][DEFAULT_OCR_MODEL_VERSION][
'rec'], 'param lang must in {}, but got {}'.format(
MODEL_URLS['OCR'][DEFAULT_OCR_MODEL_VERSION]['rec'].keys(), lang)
if lang == "ch":
det_lang = "ch"
elif lang == 'structure':
det_lang = 'structure'
elif lang in ["en", "latin"]:
det_lang = "en"
else:
det_lang = "ml"
return lang, det_lang
def get_model_config(type, version, model_type, lang):
if type == 'OCR':
DEFAULT_MODEL_VERSION = DEFAULT_OCR_MODEL_VERSION
else:
raise NotImplementedError
model_urls = MODEL_URLS[type]
if version not in model_urls:
version = DEFAULT_MODEL_VERSION
if model_type not in model_urls[version]:
if model_type in model_urls[DEFAULT_MODEL_VERSION]:
version = DEFAULT_MODEL_VERSION
else:
logger.error('{} models is not support, we only support {}'.format(
model_type, model_urls[DEFAULT_MODEL_VERSION].keys()))
sys.exit(-1)
if lang not in model_urls[version][model_type]:
if lang in model_urls[DEFAULT_MODEL_VERSION][model_type]:
version = DEFAULT_MODEL_VERSION
else:
logger.error(
'lang {} is not support, we only support {} for {} models'.
format(lang, model_urls[DEFAULT_MODEL_VERSION][model_type].keys(
), model_type))
sys.exit(-1)
return model_urls[version][model_type][lang]
def img_decode(content: bytes):
np_arr = np.frombuffer(content, dtype=np.uint8)
return cv2.imdecode(np_arr, cv2.IMREAD_COLOR)
def check_img(img):
if isinstance(img, bytes):
img = img_decode(img)
if isinstance(img, str):
# download net image
if is_link(img):
download_with_progressbar(img, 'tmp.jpg')
img = 'tmp.jpg'
image_file = img
img, flag_gif, flag_pdf = check_and_read(image_file)
if not flag_gif and not flag_pdf:
with open(image_file, 'rb') as f:
img = img_decode(f.read())
if img is None:
logger.error("error in loading image:{}".format(image_file))
return None
if isinstance(img, np.ndarray) and len(img.shape) == 2:
img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
return img
class PaddleOCR(predict_system.TextSystem):
def __init__(self, **kwargs):
"""
paddleocr package
args:
**kwargs: other params show in paddleocr --help
"""
params = parse_args(mMain=False)
params.__dict__.update(**kwargs)
assert params.ocr_version in SUPPORT_OCR_MODEL_VERSION, "ocr_version must in {}, but get {}".format(
SUPPORT_OCR_MODEL_VERSION, params.ocr_version)
params.use_gpu = check_gpu(params.use_gpu)
if not params.show_log:
logger.setLevel(logging.INFO)
self.use_angle_cls = params.use_angle_cls
lang, det_lang = parse_lang(params.lang)
# init model dir
det_model_config = get_model_config('OCR', params.ocr_version, 'det',
det_lang)
params.det_model_dir, det_url = confirm_model_dir_url(
params.det_model_dir,
os.path.join(BASE_DIR, 'whl', 'det', det_lang),
det_model_config['url'])
rec_model_config = get_model_config('OCR', params.ocr_version, 'rec',
lang)
params.rec_model_dir, rec_url = confirm_model_dir_url(
params.rec_model_dir,
os.path.join(BASE_DIR, 'whl', 'rec', lang), rec_model_config['url'])
cls_model_config = get_model_config('OCR', params.ocr_version, 'cls',
'ch')
params.cls_model_dir, cls_url = confirm_model_dir_url(
params.cls_model_dir,
os.path.join(BASE_DIR, 'whl', 'cls'), cls_model_config['url'])
if params.ocr_version == 'PP-OCRv3':
params.rec_image_shape = "3, 48, 320"
else:
params.rec_image_shape = "3, 32, 320"
# download model if using paddle infer
if not params.use_onnx:
maybe_download(params.det_model_dir, det_url)
maybe_download(params.rec_model_dir, rec_url)
maybe_download(params.cls_model_dir, cls_url)
if params.det_algorithm not in SUPPORT_DET_MODEL:
logger.error('det_algorithm must in {}'.format(SUPPORT_DET_MODEL))
sys.exit(0)
if params.rec_algorithm not in SUPPORT_REC_MODEL:
logger.error('rec_algorithm must in {}'.format(SUPPORT_REC_MODEL))
sys.exit(0)
if params.rec_char_dict_path is None:
params.rec_char_dict_path = str(
Path(__file__).parent / rec_model_config['dict_path'])
logger.debug(params)
# init det_model and rec_model
super().__init__(params)
self.page_num = params.page_num
def ocr(self, img, det=True, rec=True, cls=True):
"""
ocr with paddleocr
args:
img: img for ocr, support ndarray, img_path and list or ndarray
det: use text detection or not. If false, only rec will be exec. Default is True
rec: use text recognition or not. If false, only det will be exec. Default is True
cls: use angle classifier or not. Default is True. If true, the text with rotation of 180 degrees can be recognized. If no text is rotated by 180 degrees, use cls=False to get better performance. Text with rotation of 90 or 270 degrees can be recognized even if cls=False.
"""
assert isinstance(img, (np.ndarray, list, str, bytes))
if isinstance(img, list) and det == True:
logger.error('When input a list of images, det must be false')
exit(0)
if cls == True and self.use_angle_cls == False:
logger.warning(
'Since the angle classifier is not initialized, the angle classifier will not be uesd during the forward process'
)
img = check_img(img)
# for infer pdf file
if isinstance(img, list):
if self.page_num > len(img) or self.page_num == 0:
self.page_num = len(img)
imgs = img[:self.page_num]
else:
imgs = [img]
if det and rec:
ocr_res = []
for idx, img in enumerate(imgs):
dt_boxes, rec_res, _ = self.__call__(img, cls)
tmp_res = [[box.tolist(), res]
for box, res in zip(dt_boxes, rec_res)]
ocr_res.append(tmp_res)
return ocr_res
elif det and not rec:
ocr_res = []
for idx, img in enumerate(imgs):
dt_boxes, elapse = self.text_detector(img)
tmp_res = [box.tolist() for box in dt_boxes]
ocr_res.append(tmp_res)
return ocr_res
else:
ocr_res = []
cls_res = []
for idx, img in enumerate(imgs):
if not isinstance(img, list):
img = [img]
if self.use_angle_cls and cls:
img, cls_res_tmp, elapse = self.text_classifier(img)
if not rec:
cls_res.append(cls_res_tmp)
rec_res, elapse = self.text_recognizer(img)
ocr_res.append(rec_res)
if not rec:
return cls_res
return ocr_res
if __name__ == '__main__':
args = parse_args(mMain=True)
image_dir = 'img/test.jpg'
print(image_dir)
image_file_list = get_image_file_list(image_dir)
if len(image_file_list) == 0:
logger.error('no images find in {}'.format(image_dir))
# return
engine = PaddleOCR()
for img_path in image_file_list:
img_name = os.path.basename(img_path).split('.')[0]
logger.info('{}{}{}'.format('*' * 10, img_path, '*' * 10))
result = engine.ocr(img_path,
det=True, #识别
rec=True, #检测
cls=True) #使用方向分类器识别180度旋转文字
if result is not None:
for idx in range(len(result)):
res = result[idx]
for line in res:
logger.info(line)
else:
print("result is none")
# 显示结果
from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='./fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('img/result.jpg')
5、编译调试
中间出现了一些模块未定义的提示,比如

安装相应的库解决:pip install lanms-neo
直到编译完成。
四、测试结果:
运行结果是一个list,每个item包含了文本框,文字和识别置信度

img文件夹中保存的result.jpg如下:

图片开头的“www.997788.com”识别成了“r88.997788.co11”,“中国收藏热线”没识别出来,“G11”识别成了“C11”,有污迹的时间“15:55”没识别出来。