MixFormer(论文解读与代码讲解)2
for i, blk in enumerate(self.blocks):
#输入拼接的x(8, 8448, 64)还有原始的模板们和搜索的h和w
x = blk(x, t_H, t_W, s_H, s_W)
#blocks就是N个block的合计,N=depth
blocks = []
for j in range(depth):
blocks.append(
Block(
dim_in=embed_dim,
dim_out=embed_dim,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[j],
act_layer=act_layer,
norm_layer=norm_layer,
freeze_bn=freeze_bn,
**kwargs
)
)
self.blocks = nn.ModuleList(blocks)进入block
class Block(nn.Module):
def __init__(self,
dim_in,
dim_out,
num_heads,
mlp_ratio=4.,
qkv_bias=False,
drop=0.,
attn_drop=0.,
drop_path=0.,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm,
freeze_bn=False,
**kwargs):
super().__init__()
self.with_cls_token = kwargs['with_cls_token']
self.norm1 = norm_layer(dim_in)
self.attn = Attention(
dim_in, dim_out, num_heads, qkv_bias, attn_drop, drop, freeze_bn=freeze_bn,
**kwargs
)
self.drop_path = DropPath(drop_path) \
if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim_out)
dim_mlp_hidden = int(dim_out * mlp_ratio)
self.mlp = Mlp(
in_features=dim_out,
hidden_features=dim_mlp_hidden,
act_layer=act_layer,
drop=drop
)
def forward(self, x, t_h, t_w, s_h, s_w):
res = x #res = x (8, 8448, 64)
x = self.norm1(x) #一个layernorm的归一化
attn = self.attn(x, t_h, t_w, s_h, s_w) #进入注意力模块
x = res + self.drop_path(attn)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return xself.attn = Attention(
dim_in, dim_out, num_heads, qkv_bias, attn_drop, drop, freeze_bn=freeze_bn,
**kwargs
)Attention模块
def forward(self, x, t_h, t_w, s_h, s_w):
"""
Asymmetric mixed attention.
"""
if (
self.conv_proj_q is not None
or self.conv_proj_k is not None
or self.conv_proj_v is not None
):
q, k, v = self.forward_conv(x, t_h, t_w, s_h, s_w)
q = rearrange(self.proj_q(q), 'b t (h d) -> b h t d',
h=self.num_heads).contiguous()
k = rearrange(self.proj_k(k), 'b t (h d) -> b h t d',
h=self.num_heads).contiguous()
v = rearrange(self.proj_v(v), 'b t (h d) -> b h t d',
h=self.num_heads).contiguous()
### Attention!: k/v compression,1/4 of q_size(conv_stride=2)
q_mt, q_s = torch.split(q, [t_h * t_w * 2, s_h * s_w], dim=2)
# k_t, k_ot, k_s = torch.split(k, [t_h*t_w//4, t_h*t_w//4, s_h*s_w//4], dim=2)
# v_t, v_ot, v_s = torch.split(v, [t_h * t_w // 4, t_h * t_w // 4, s_h * s_w //
4], dim=2)
k_mt, k_s = torch.split(k, [((t_h + 1) // 2) ** 2 * 2, s_h * s_w // 4], dim=2)
v_mt, v_s = torch.split(v, [((t_h + 1) // 2) ** 2 * 2, s_h * s_w // 4], dim=2)
# template attention
attn_score = torch.einsum('bhlk,bhtk->bhlt', [q_mt, k_mt]) * self.scale
attn = F.softmax(attn_score, dim=-1)
attn = self.attn_drop(attn)
x_mt = torch.einsum('bhlt,bhtv->bhlv', [attn, v_mt])
x_mt = rearrange(x_mt, 'b h t d -> b t (h d)')
# search region attention
attn_score = torch.einsum('bhlk,bhtk->bhlt', [q_s, k]) * self.scale
attn = F.softmax(attn_score, dim=-1)
attn = self.attn_drop(attn)
x_s = torch.einsum('bhlt,bhtv->bhlv', [attn, v])
x_s = rearrange(x_s, 'b h t d -> b t (h d)')
x = torch.cat([x_mt, x_s], dim=1)
x = self.proj(x)
x = self.proj_drop(x)
return x进入self.forward_conv获得qkv
def forward_conv(self, x, t_h, t_w, s_h, s_w):
template, online_template, search = torch.split(x, [t_h * t_w, t_h * t_w, s_h *
s_w], dim=1)
template = rearrange(template, 'b (h w) c -> b c h w', h=t_h, w=t_w).contiguous()
online_template = rearrange(online_template, 'b (h w) c -> b c h w', h=t_h,
w=t_w).contiguous()
search = rearrange(search, 'b (h w) c -> b c h w', h=s_h, w=s_w).contiguous()
if self.conv_proj_q is not None:
t_q = self.conv_proj_q(template)
ot_q = self.conv_proj_q(online_template)
s_q = self.conv_proj_q(search)
q = torch.cat([t_q, ot_q, s_q], dim=1)
else:
t_q = rearrange(template, 'b c h w -> b (h w) c').contiguous()
ot_q = rearrange(online_template, 'b c h w -> b (h w) c').contiguous()
s_q = rearrange(search, 'b c h w -> b (h w) c').contiguous()
q = torch.cat([t_q, ot_q, s_q], dim=1)
if self.conv_proj_k is not None:
t_k = self.conv_proj_k(template)
ot_k = self.conv_proj_k(online_template)
s_k = self.conv_proj_k(search)
k = torch.cat([t_k, ot_k, s_k], dim=1)
else:
t_k = rearrange(template, 'b c h w -> b (h w) c').contiguous()
ot_k = rearrange(online_template, 'b c h w -> b (h w) c').contiguous()
s_k = rearrange(search, 'b c h w -> b (h w) c').contiguous()
k = torch.cat([t_k, ot_k, s_k], dim=1)
if self.conv_proj_v is not None:
t_v = self.conv_proj_v(template)
ot_v = self.conv_proj_v(online_template)
s_v = self.conv_proj_v(search)
v = torch.cat([t_v, ot_v, s_v], dim=1)
else:
t_v = rearrange(template, 'b c h w -> b (h w) c').contiguous()
ot_v = rearrange(online_template, 'b c h w -> b (h w) c').contiguous()
s_v = rearrange(search, 'b c h w -> b (h w) c').contiguous()
v = torch.cat([t_v, ot_v, s_v], dim=1)
return q, k, v一步一步讲解:
template, online_template, search = torch.split(x, [t_h * t_w, t_h * t_w, s_h * s_w],
dim=1)通过split函数将x重新分割为template, online_template和search
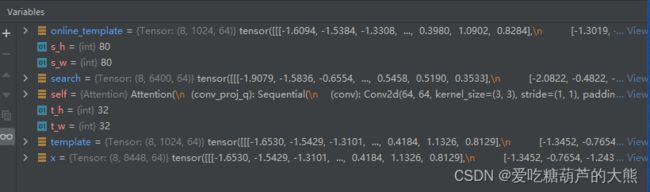
rearrange将template, online_template和search转化为原始形状
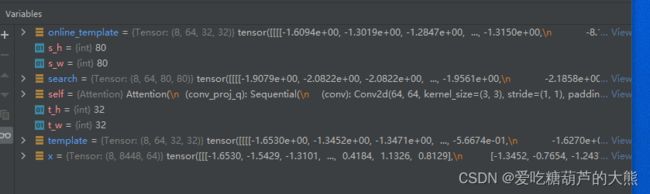
使用self.conv_proj_q,self.conv_proj_k,self.conv_proj_v产生三者的q,k,v值
结构如下:
![]() 其中norm层如下
其中norm层如下
def forward(self, x): #x(8, 64, 32, 32)
# move reshapes to the beginning
# to make it fuser-friendly
w = self.weight.reshape(1, -1, 1, 1)
b = self.bias.reshape(1, -1, 1, 1)
rv = self.running_var.reshape(1, -1, 1, 1)
rm = self.running_mean.reshape(1, -1, 1, 1)
eps = 1e-5
scale = w * (rv + eps).rsqrt() # rsqrt(x): 1/sqrt(x), r: reciprocal
bias = b - rm * scale
return x * scale + bias原始的weight, bias, running_var和running_mean是全零或全一的一维向量
def __init__(self, n):
super(FrozenBatchNorm2d, self).__init__()
self.register_buffer("weight", torch.ones(n))
self.register_buffer("bias", torch.zeros(n))
self.register_buffer("running_mean", torch.zeros(n))
self.register_buffer("running_var", torch.ones(n))
通过reshape变成(1, 64, 1, 1)

但是以上的forward不知道有什么用,因为输入输出都是一样的内部的值也没有改变,希望有大佬能懂的能够解释一下
a = x * scale + bias
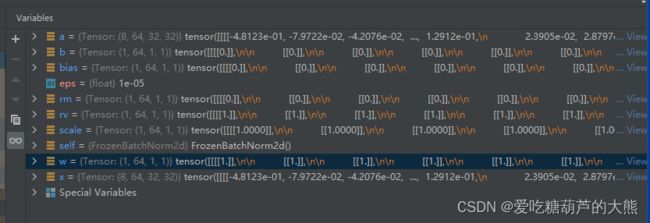
然后通过rearrange将(bach,c,w,h)改为(bach,(w*h),c)
随后处理q,k,v
q = rearrange(self.proj_q(q), 'b t (h d) -> b h t d', h=self.num_heads).contiguous()
k = rearrange(self.proj_k(k), 'b t (h d) -> b h t d', h=self.num_heads).contiguous()
v = rearrange(self.proj_v(v), 'b t (h d) -> b h t d', h=self.num_heads).contiguous()这里rearrange感觉作者想用多头注意力的不过num_heads为1就没有多头了

proj_q/k/v就是一个线性层,输入输出不变
q_mt, q_s = torch.split(q, [t_h * t_w * 2, s_h * s_w], dim=2)
k_mt, k_s = torch.split(k, [((t_h + 1) // 2) ** 2 * 2, s_h * s_w // 4], dim=2)
v_mt, v_s = torch.split(v, [((t_h + 1) // 2) ** 2 * 2, s_h * s_w // 4], dim=2)将模板,在线模板分为一组,搜索分为一组
模板组进行transformer
# template attention
attn_score = torch.einsum('bhlk,bhtk->bhlt', [q_mt, k_mt]) * self.scale
attn = F.softmax(attn_score, dim=-1)
attn = self.attn_drop(attn)
x_mt = torch.einsum('bhlt,bhtv->bhlv', [attn, v_mt])
x_mt = rearrange(x_mt, 'b h t d -> b t (h d)')搜索组,以搜索部分的q和所有(包括模板,在线模板和搜索的k,v)做互注意力
# search region attention
attn_score = torch.einsum('bhlk,bhtk->bhlt', [q_s, k]) * self.scale
attn = F.softmax(attn_score, dim=-1)
attn = self.attn_drop(attn)
x_s = torch.einsum('bhlt,bhtv->bhlv', [attn, v])
x_s = rearrange(x_s, 'b h t d -> b t (h d)')
然后再将两组重新拼接在一起,过个线性层,将所得的注意力结果与block的原始输入相加,如下图
x = res + self.drop_path(attn)
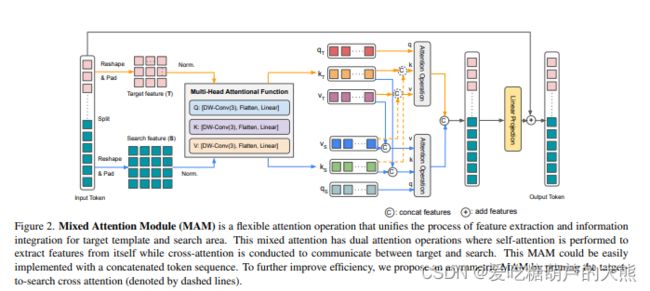
这里有个操作图上没有呈现,就是最后的输出还过了一个MLP结构并和自身相加
x = x + self.drop_path(self.mlp(self.norm2(x)))输出为具有模板,在线模板,搜索共同特征的x
然后从x将模板,在线模板,搜索图像分开
template, online_template, search = torch.split(x, [t_H*t_W, t_H*t_W, s_H*s_W], dim=1)
template = rearrange(template, 'b (h w) c -> b c h w', h=t_H, w=t_W).contiguous()
online_template = rearrange(online_template, 'b (h w) c -> b c h w', h=t_H,
w=t_W).contiguous()
search = rearrange(search, 'b (h w) c -> b c h w', h=s_H, w=s_W).contiguous()到此stage1结束了
MixFormer(论文解读与代码讲解)1
MixFormer(论文解读与代码讲解)3