单目深度估计总结
目录
- 监督的方法
- 单目视频序列深度估计
-
- 引言
- 方法
- 实验
- 单目深度估计(单图)
深度图能估计真实的距离吗?如果标签是真实的那么估计的就是真实的,(如果标签是相对的那么估计的就是相对的。) 目前大部分都是用真实的估计
监督的方法
数据集KITTI所提供的的标注来源于激光雷达点云,是离散的,不能获得深度的梯度。如果深度估计方法中用到梯度loss则用KITTI不太好。
四类方向
计算机视觉里的深度是指物体离相机的距离,表示为相机坐标系下的Z坐标值。
相对深度和绝对深度估计
自监督存在尺度不确定性,预测的一般是相对深度。用真值深度图进行训练的监督模型 得到的是绝对深度
为何不用立体视觉估计深度的方法进行单目深度估计?
因为我们针对特定场合使用深度估计需要自己制作数据集,考虑成本等问题使用的是单个相机而不是双相机,就算双目方法可以用于单目深度估计但是训练还是需要双目的数据集。
单目视频序列深度估计
自监督,需要知道时间图像对之间的帧间运动,估计相机的姿态变化或者是否固定【首先找到相邻图像对应点的组合,根据这些匹配的点对计算出相机的位姿(相对初始位置,相机的旋转和平移)】。
论文:MonoDepth2《Digging Into Self-Supervised Monocular Depth Estimation》

本文贡献:提出了
- 一个最小重投影误差,用来提升算法处理遮挡场景的鲁棒性
- 一种全分辨率多尺度采样方法,可以减少视觉伪影
- 一种auto-masking loss,用来忽略训练像素中违反相机运动假设的像素点
引言
我们提出了 三种架构 和一些可以用来组合的损失项,使得单目深度估计的性能得到大大提升,三种架构分别可以使用 单目视频序列(M),立体双目图像对(S),或者两者结合的方式(MS) 进行训练:
- 一种新颖的外观表面匹配损失,以解决在使用单目监督时出现的像素遮挡问题
- 一种新颖而简单的auto-masking方法,可以忽略在单目训练图像中没有发生相对相机运动的像素点
- 在输入分辨率下执行所有图像采样的多尺度外观匹配损失,导致深度伪影的减少

基于单目视频训练是一种有吸引力的替代立体图像监督的方法,但它也带来了一系列挑战。除了估计深度外,模型还需要估计训练过程中时间图像对之间的帧间运动。这通常涉及到训练一个以有限帧序列作为输入,并输出相应的摄像机变换的位姿估计网络。
有监督深度估计(可能有单图训练的)
1. 全监督(需要ground-truth depth训练)
代表论文:《Deep Ordinal Regression Network for Monocular Depth Estimation》
数据集:NYU Depth v2(室内,RGB-D)
2.弱监督
论文代表:《Single-Image Depth Perception in the Wild》
数据集:DIW
介绍:这里用的是相对深度标注
论文代表:《Learning Single-View Depth Prediction from Internet Photos》
数据集:Megadepth(合成数据)
介绍:传统的从结构中恢复运动(SfM)管道可以生成摄像机姿态和深度的稀疏训练信号,这里的SFM作为与学习阶段解耦(就是用数学方法将两种运动分离开来处理问题)的预处理。
自监督深度估计
通过对给定图像预测深度,并将其投影到附近的视图中,通过最小化图像重构误差来训练模型。
实验过程:训练时以有限帧序列作为输入,测试时以一个单一的彩色图像作为输入,并预测每个像素的深度作为输出。
自监督单目训练范式
网络包括两方面:1.预测深度;2.相邻帧之间摄像机位姿估计。(这个估计的摄像机位姿只需要在训练中帮助约束深度估计网络。)
Appearance Based Losses(基于外观的损失)
自监督训练通常依赖于对物体表面的外观(即亮度稳定性)和材料属性(如朗伯坦面)做出的假设。xx表明,与简单的两两像素差相比,包含基于局部结构的外观损失显著提高了深度估计性能。xxx扩展了这种方法,使其包含一个误差拟合项,并且xxxx探索了将其与基于对抗性损失相结合,以鼓励逼真的合成图像。最后,受到xxxxx的启发,xxxxxxx使用ground truth深度来训练一个外貌匹配项。

方法
自监督训练
每个像素可能有非常多的不正确深度(因为投影原因,世界坐标上不同的点对应图像上同一个像素),在给定两个视图之间的相对位姿的情况下,这些不正确的深度可以正确地重建新视图(想象射线的空间变换)

问题表述为训练时光度重投影误差的最小化
我们将每个源图 I t ’ \mathbf{I}_{t}^{\text {'}} It’相对于目标图像 I t \mathbf{I}_{t}^{\text {}} It的相对位姿记 T t → t ′ \mathbf{T}_{t\rightarrow t{'}} Tt→t′我们预测一个稠密的深度图 D t \mathbf{D}_{t}^{\text {}} Dt ,通过最小化光度重投影误差 L p \mathbf{L}_{p}^{\text {}} Lp :

pe是光度重建误差, proj ( ) \operatorname{proj}() proj()是利用 D t \mathbf{D}_{t}^{\text {}} Dt, T t → t ′ \mathbf{T}_{t\rightarrow t{'}} Tt→t′和K冲投影到 I t ’ \mathbf{I}_{t}^{\text {'}} It’的2D像素坐标,< >采样符。
在立体图像训练中,原图与第二视图的相对位姿是已知的。虽然单目序列的相对位姿不能提前知道但是可以通过位姿估计网络进行估计。
提升的自监督深度估计

逐像素最小重投影误差损失
在从多个源图像来计算重投影误差时,现有的自监督深度估计方法,对于多源图像的重投影误差取平均。这可能会导致在目标图像中可见但在某些源图像中不可见的像素出现问题,见图 3c。如果网络预测了一个像素的正确深度,那么被遮挡的源图像中的相应颜色很可能与目标不匹配,从而产生一个很高的光度误差。这些有问题的像素主要来自两个类别:一种是处在图像边界,并且由于帧间运动而导致越界(跑出视图外)的像素,另一种是被遮挡的像素。通过在重投影损失中对相应像素进行掩蔽,可以减小视场外像素的影响[40,61],但这并不能处理(去)遮挡情况,平均重投影可能导致模糊的深度不连续。
我们提出了一种改进策略,来处理这两种情况。在每个像素处,我们不是对所有源图像的光度误差进行平均,而是简单地使用最小值。因此,我们最终的每像素光度损失是:

如图4所展示的,是这使用该损失的一个例子。使用我们的最小重投影误差能有效的减少图像边界上的缺陷,提升遮挡边界的尖锐度,从而产生更高的精度。

自动过滤平稳像素
自监督单目训练通常建立在移动摄像机和静态场景的假设下进行。当这些假设失效时,例如当摄像机静止或场景中有物体运动时,性能会受到很大的影响。这个问题表现在,在测试时的预测深度图中产生无限深度的“孔”,对于在训练[38]期间通常观察到正在移动的对象(如图2)
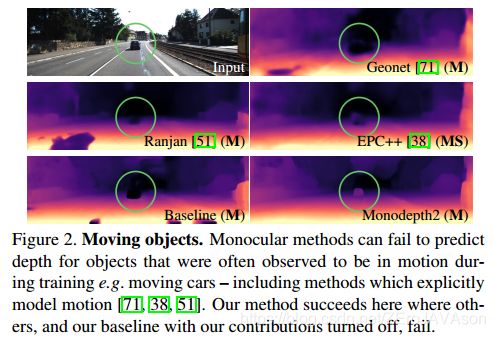
这激发了我们的第二个贡献:一个简单的自动屏蔽方法,它过滤掉那些不会在序列中从一帧到下一帧改变外观的像素。这样做的效果是让网络忽略与摄像机以相同速度移动的对象,甚至当摄像机停止移动时忽略单目视频中的整个帧。
像其他工作[76、61、38]一样,我们也应用逐像素的mask u u u损失,有选择地加权像素。然而,与之前的工作相比,我们的掩码是二进制的,所以 u ∈ 0 , 1 u\in\mathbb {0,1} u∈0,1,并且是在神经网络前向传播过程中自动计算的,而不是通过物体运动来学习或估计。 我们观察到,在序列中相邻帧之间保持相同的像素通常表示是静态相机情形{SP4:弯曲车道线空洞},或者是与相机相对静止的运动物体,或一个低纹理区域。因此,我们设置μ值只包含那些在变换后图像 I t → t ′ \mathbf{I}_{t\rightarrow t{'}} It→t′ 上的重投影误差小于在原始图像 I t ′ \mathbf{I}_{t'}^{\text { }} It′ 上的重投影误差的像素点{SP5:???},如下式:
![]()
这里的[]在式子逻辑为真取1。 当相机和另一个物体都以相似的速度移动时, u u u会过滤点这些静止像素,防止他们被计算在loss中。同样,当相机处于静止状态时,mask会滤除图像中的所有像素(如图 5)。

多尺度估计
我们首先对低分辨率图像(从中间层)到输入图像分辨率的低分辨率深度图进行上采样,而不是对模糊的低分辨率图像进行光度误差计算,然后重投影,重新取样,并在更高的输入分辨率下计算误差pe(如图 3d)。这个过程类似于匹配图像块,因为低分辨率视差值将负责在高分辨率图像中扭曲整个像素快。这有效地约束了深度图在每个尺度上都朝着同一个目标努力,即尽可能精确地重建高分辨率输入目标图像。
最终的训练Loss
我们结合逐像素平滑和掩膜光度损失
![]()
并在每个像素,尺度,和批下取平均。
其他考虑项
我们的深度估计网络是基于一般的U-Net架构的[53],即一个编码-解码器网络,具有跳转连接,使我们能够表示深层抽象特征以及局部信息。

实验
KITTI Eigen Split
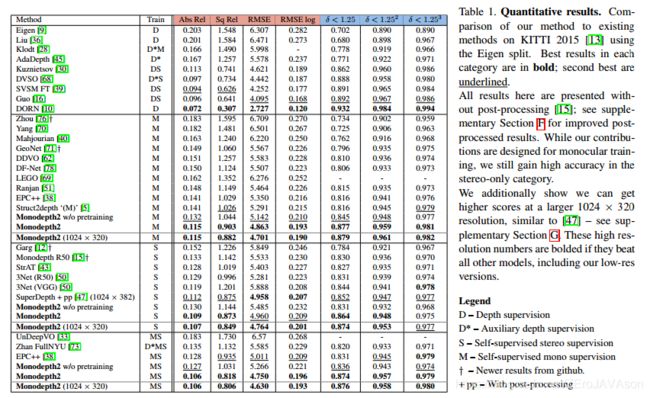
表1定量结果。我们的方法与KITTI 2015 [13]中使用Eigen split的现有方法的比较。每个类别中的最佳结果以粗体显示;第二好的用下划线标出。
这里给出的所有结果都没有后处理[15];关于改进的后处理结果,见补充的第六节。虽然我们的贡献是为单目训练设计的,但我们在纯立体类别中仍然获得了高精度。
此外,我们还表明,在更大的1024 × 320分辨率下,我们可以获得更高的分数,类似于[47]–请参见补充章节G。如果这些高分辨率数字超过所有其他型号,包括我们的低分辨率版本,它们会以粗体显示。
D-深度监督
D-辅助深度监控
S-立体自监督
M-单目自监督
†-github的更新结果
+pp-带有后处理
定性结果见图7
然而,与所有基于深度估计的图像重建方法一样,当场景包含违反我们的Lambertian假设的对象{SP6}时,我们的模型就会崩溃(图8)。

补充:
结构

论文:《Toward Hierarchical Self-Supervised Monocular Absolute Depth Estimation for Autonomous Driving Applications》
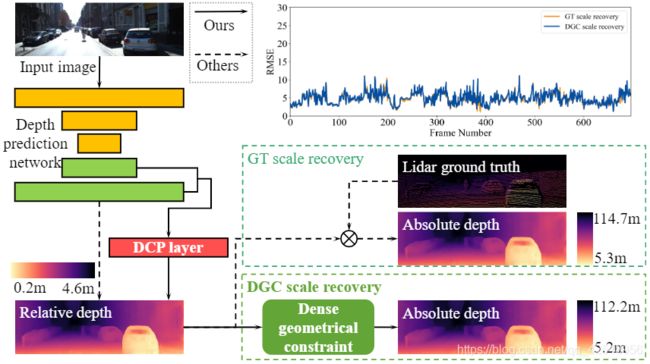
图1:DNet与其他自监督单目深度估计的结构区别,实线是本网络流程图,需显示其他方法。DCP生成结构特征来获取更好的物体级的深度,DGC直接从单目图像中估计绝对深度。基于尺度恢复的DGC与ground-truth的对比在右上角

基础模型:Monodepth2 w/o全分辨率:
架构:单目自监督架构需要两个网络,分别是深度网络和位姿网络。第 t \ t\, t帧的单幅图像 I t \ It\, It作为深度网络的输入。深度网络输出密集的相对深度图 D t rel \mathbf{D}_{t}^{\text {rel }} Dtrel ,位姿网络依次将[外链图片转存失败,源站可能有防盗链机制,建议将 { I t − 1 , I t } \left\{\mathbf{I}_{t-1}, \mathbf{I}_{t}\right\} {It−1,It}和 { I t , I t + 1 } \left\{\mathbf{I}_{t}, \mathbf{I}_{t+1}\right\} {It,It+1}作为输入,然后输出第t幅图像相对于第(t-1)和第(t+1)幅图像的相机姿态,即 { T t → t − 1 r e l , T t → t + 1 r e l } \left\{\mathbf{T}_{t \rightarrow t-1}^{r e l}, \mathbf{T}_{t \rightarrow t+1}^{r e l}\right\} {Tt→t−1rel,Tt→t+1rel}.
单目深度估计(单图)
1.需要ground truth depth map的深度图的估计(运用到地铁上时需要自己制作数据集,显然不合适,自己只能制作像kitti这样的数据集)
2.不需要 真实值,由深度线索生成深度图。
(就是 完全监督 和 弱监督 )